一、 前言
得物近年来发展迅猛,平台商品类目覆盖越来越广,商品量级越来越大。而以往得物的上新动作更多依赖于传统方式,效率较低,无法满足现有的上新诉求。那么如何能实现更加快速的上新、更加高效的上新,就成为了一个至关重要的命题。
近两年AI大模型技术的发展,使得发布和审核逐渐向AI驱动的方式转变成为可能。因此,我们可以探索利用算法能力和大模型能力,结合业务自身规则,构建更加全面和精准的规则审核点,以实现更高效的工作流程,最终达到我们的目标。
本文围绕AI审核,介绍机审链路建设思想、规则审核点实现快速接入等核心逻辑。
二、如何实现高效审核
对于高效审核的理解,主要可以拆解成"高质量"、"高效率"。目前对于"高质量"的动作包括,基于不同的类目建设对应的机审规则、机审能力,再通过人工抽查、问题Case分析的方式,优化算法能力,逐步推进"高质量"的效果。
而"高效率",核心又可以分成业务高效与技术高效。
业务高效
- 逐步通过机器审核能力优化审核流程,以解决资源不足导致上新审核时出现进展阻碍的问题。
- 通过建设机审配置业务,产品、业务可以直观的维护类目-机审规则-白名单配置,从而高效的调整机审策略。
技术高效
- 通过建设动态配置能力,实现快速接入新的机审规则、调整机审规则等,无需代码发布,即配即生效。
Q2在搭建了动态配置能力之后,算法相关的机审规则接入效率提升了70%左右。
三、动态配置实现思路
建设新版机审链路前的调研中,我们对于老机审链路的规则以及新机审规则进行了分析,发现算法类机审规则占比超过70%以上,而算法类的机审规则接入的流程比较固化,核心分成三步:
- 与算法同学沟通定义好接口协议
- 基于商品信息构建请求参数,通过HTTP请求算法提供的URL,从而获取到算法结果。
- 解析算法返回的结果,与自身商品信息结合,输出最终的机审结果。
而算法协议所需要的信息通常都可以从商品中获取到,因此通过引入"反射机制"、"HTTP泛化调用"、"规则引擎"等能力,实现算法规则通过JSON配置即可实现算法接入。
四、商品审核方式演进介绍
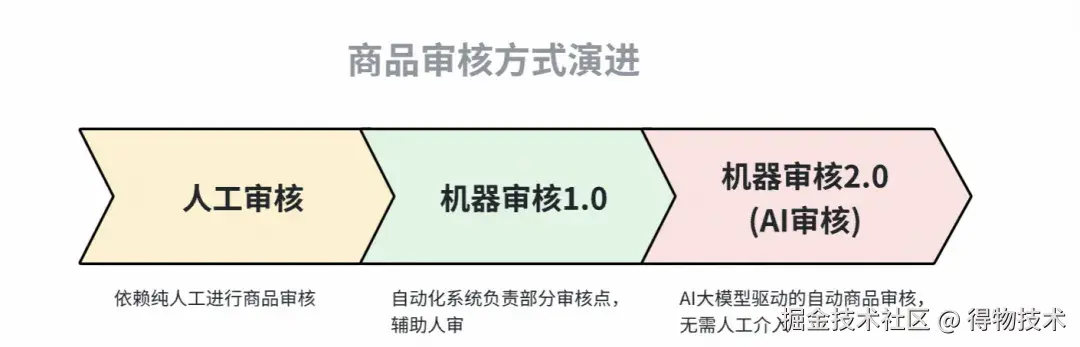
商品审核方式的演进
人审
依赖商管、运营,对商品上架各字段是否符合得物上新标准进行人工核查。
机审
对于部分明确的业务规则,比如白底图、图片清晰度、是否重复品、是否同质品等,机审做前置校验并输出机审结果,辅助人工审核,降低审核成本,提升审核效率。
AI审核
通过丰富算法能力、强化AI大模型能力、雷达技术等,建设越来越多的商品审核点,并推动召回率、准确率的提升,达标的审核点可通过自动驳回、自动修改等action接管商品审核,降低人工审核的占比,降低人工成本。
五、现状问题分析
产品层面
- 机审能力不足,部分字段没覆盖,部分规则不合理:
-
- 机审字段覆盖度待提升
- 机审规则采纳率不足
- 部分机审规则不合理
- 缺少产品配置化能力,配置黑盒化,需求迭代费力度较高:
-
- 规则配置黑盒
- 规则执行结果缺乏trace和透传
- 调整规则依赖开发和发布
- 缺少规则执行数据埋点
技术层面
- 系统可扩展性不足,研发效率低:
-
- 业务链路(AI发品、审核、预检等)不支持配置化和复用
- 规则节点不支持配置化和复用
六、流程介绍
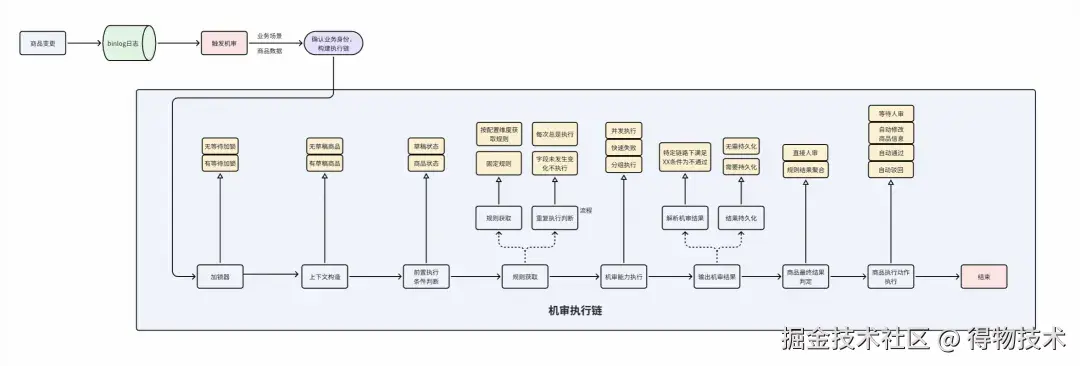
搭建机审配置后台,可以通过配置应用场景+业务身份+商品维度配置来确定所需执行的全量规则,规则可复用。
其中应用场景代表业务场景,如商品上新审核、商家发品预检、AI发品预检等;业务身份则表示不同业务场景下不同方式,如常规渠道商品上新的业务场景下,AI发布、常规商品上新(商家后台、交易后台等)、FSPU同款发布品等。
当商品变更,通过Binlog日志触发机审,根据当前的应用场景+业务身份+商品信息,构建对应的机审执行链(ProcessChain)完成机审执行,不同的机审规则不通过支持不同的action,如自动修正、自动驳回、自动通过等。
链路执行流程图如下:
七、详细设计
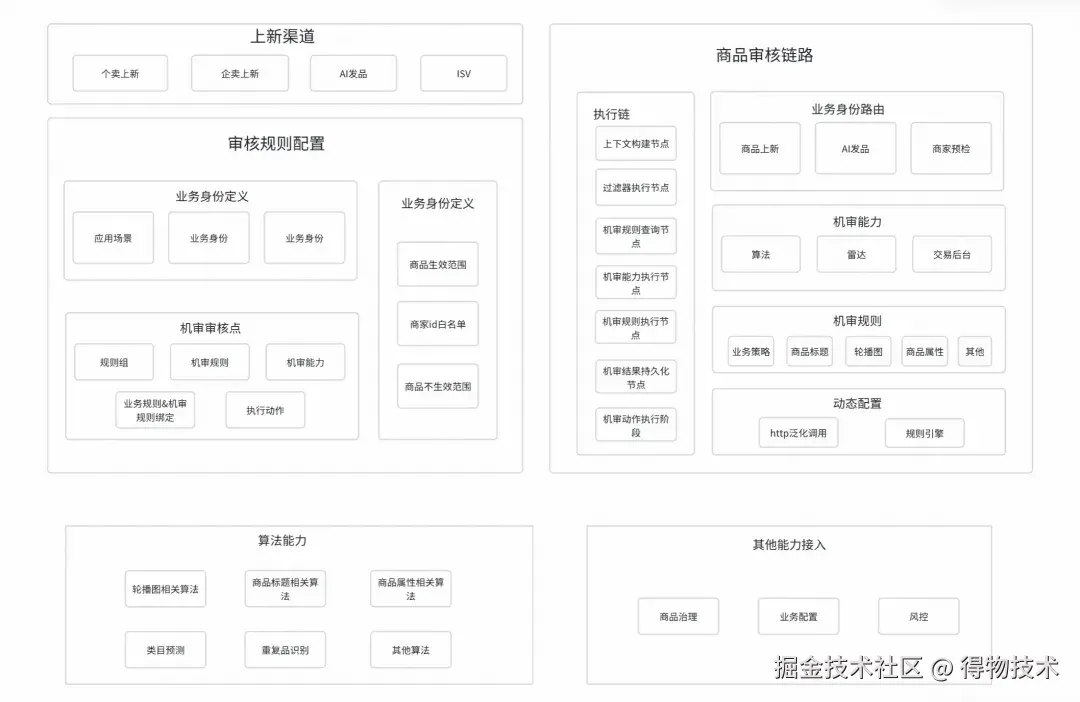
整体架构图
业务实体
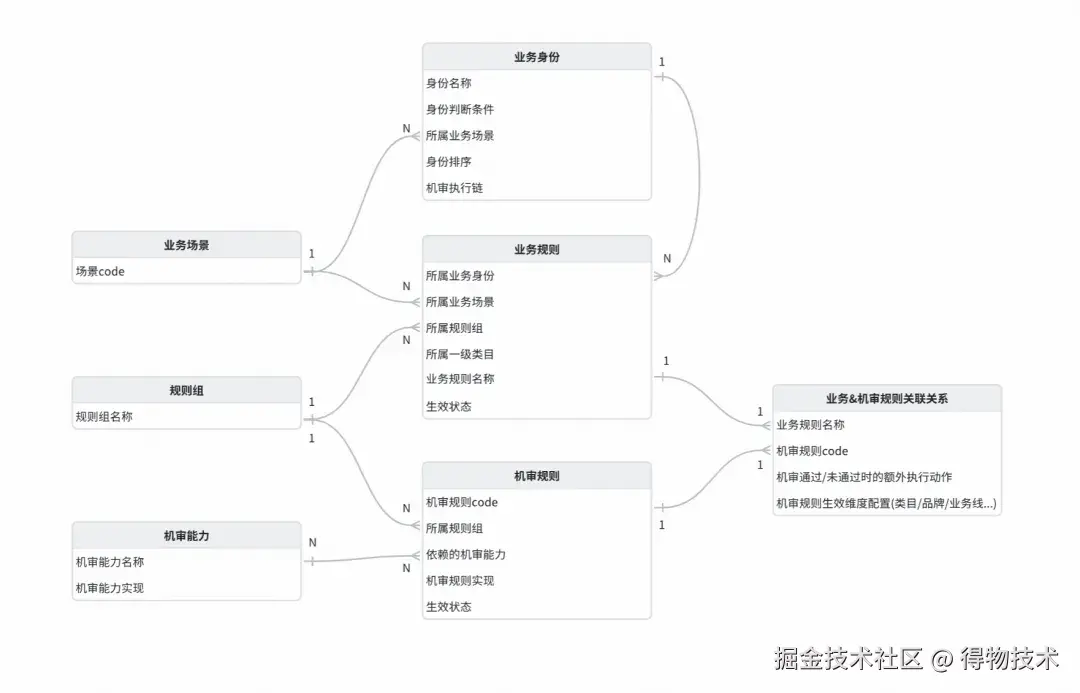
ER图
含义解释
※ 业务场景
触发机审的应用场景,如新品发布、商家新品预检等。
※ 业务身份
对于某个应用场景,进一步区分业务场景,如新品发布的场景下,又有AI发品、常规发品、FSPU同款发品等。
※ 业务规则
各行业线对于商品的审核规则,如校验图片是否是白底图、结构化标题中的类目需与商品类目一致、发售日期不能超过60天等。同一个业务规则可以因为业务线不同,配置不同的机审规则。
※ 规则组
对规则的分类,通常是商品字段模块的名称,一个规则组下可以有多个业务规则,如商品轮播图作为规则组,可以有校验图片是否白底图、校验图片是否清晰、校验模特姿势是否合规等。
※ 机审规则
对商品某个商品字段模块的识别并给出审核结果,数据依赖机审能力以及spu本身。
※ 机审能力
商品信息(一个或多个商品字段模块)的审核数据获取,通常需要调用外部接口,用于机审规则审核识别。
※ 业务&机审规则关联关系
描述业务规则和机审规则的关联关系,同一个业务规则可以根据不同业务线,给予不同的机审规则,如轮播图校验正背面,部分业务线要求校验全量轮播图,部分业务线只需要校验轮播图首图/规格首图。
机审执行流程框架
流程框架
通过责任链、策略模式等设计模式实现流程框架。
触发机审后会根据当前的业务场景、业务身份、商品信息等,获取到对应的业务身份执行链(不同业务身份绑定不同的执行节点,最终构建出来一个执行链)并启动机审流程执行。
由于机审规则中存在数据获取rt较长的情况,如部分依赖大模型的算法能力、雷达获取三方数据等,我们通过异步回调的方式解决这种场景,也因此衍生出了"异步结果更新机审触发"。
※ 完整机审触发
完整机审触发是指商品变更后,通过Binlog日志校验当前商品是否满足触发机审,命中的机审规则中如果依赖异步回调的能力,则会生成pendingId,并记录对应的机审结果为"pending"(其他规则不受该pending结果的影响),并监听对应的topic。
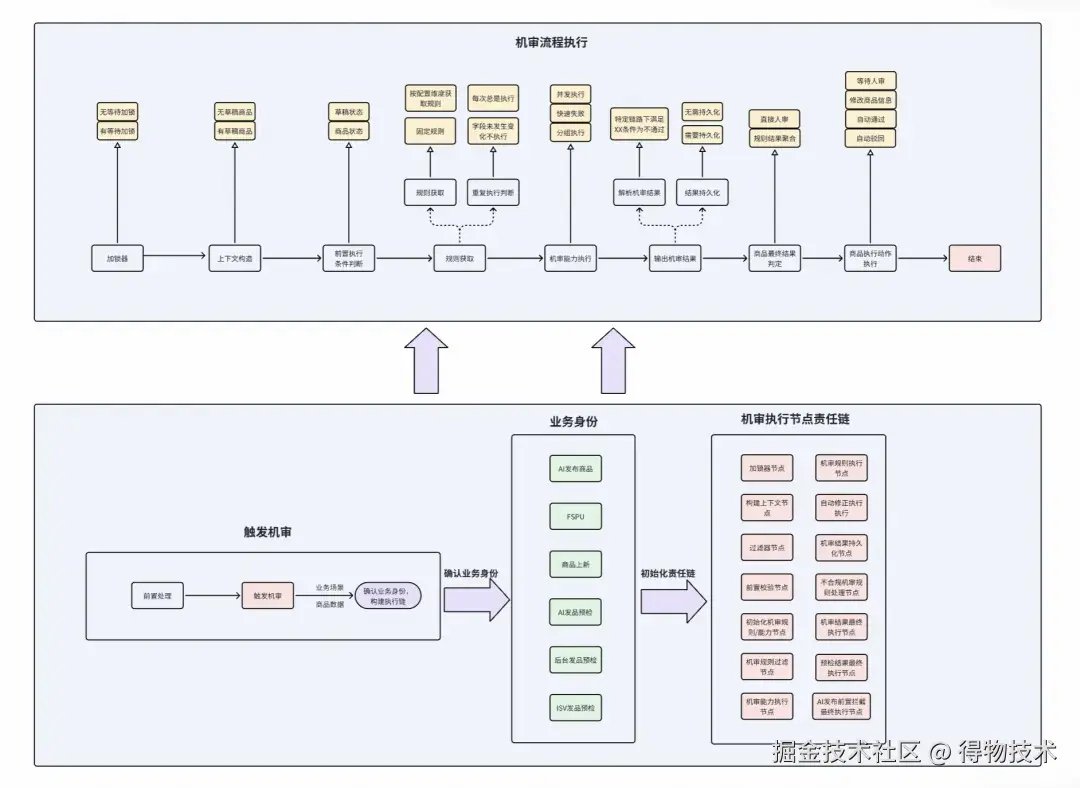
※ 异步结果更新机审触发
部分pending规则产出结果后发送消息到机审场景,通过pendingId以及对应的商品信息确认业务身份,获取异步结果更新责任链(与完整机审的责任链不同)再次执行机审执行责任链。
动态配置能力建设
调研
新机审链路建设不仅要支持机审规则复用,支持不同业务身份配置接入,还要支持新机审规则快速接入,降低开发投入的同时,还能快速响应业务的诉求。
经过分析,机审规则绝大部分下游为算法链路,并且算法的接入方式较为固化,即"构建请求参数" -> "发起请求" -> "结果解析",并且数据模型通常较为简单。因此技术调研之后,通过HTTP泛化调用 实现构建请求参数 、发起请求 ,利用规则引擎(规则表达式) 实现结果解析。
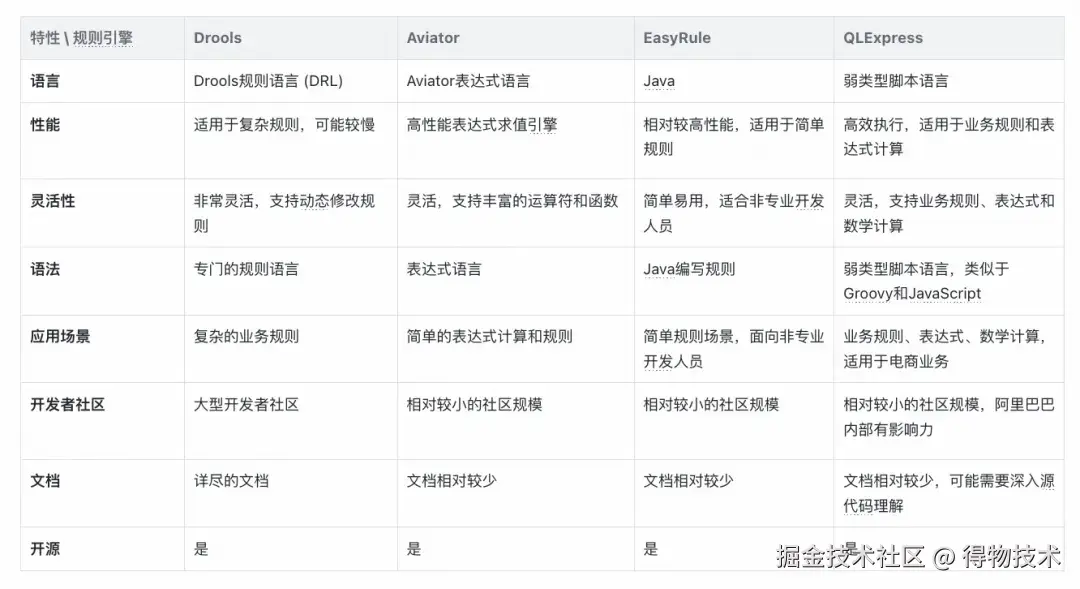
规则引擎技术选型
调研市面上的几种常用规则引擎,基于历史使用经验、上手难度、文档阅读难度、性能等方面综合考虑,最终决定选用QLExpress。
HTTP泛化调用能力建设
※ 实现逻辑
- 定义MachineAuditAbilityEnum统一的动态配置枚举,并基于MachineAuditAbilityProcess实现其实现类。
- 统一入参为Map结构,通过反射机制、动态Function等方式,实现商品信息映射成算法请求参数;另外为了提升反射的效率,利用预编译缓存的方式,将字段转成MethodHandle,后续对同一个字段做反射时,可直接获取对应的MethodHandle,提升效率。
typescript
/**
* 缓存类字段的MethodHandle(Key: Class+FieldName, Value: MethodHandle)
*/
private static final Map<String, MethodHandle> FIELD_HANDLE_CACHE = new ConcurrentHashMap<>();
/**
* 根据配置从对象中提取字段值到Map
* @return 提取后的Map
*/
public Map<String, Object> fieldValueMapping(AutoMachineAlgoRequestConfig requestConfig, Object spuResDTO) {
AutoMachineAlgoRequestConfig.RequestMappingConfig requestMappingConfig = requestConfig.getRequestMappingConfig();
Map<String, Object> targetMap = Maps.newHashMap();
//1.简单映射关系,直接将obj里的信息映射到resultMap当中
//2.遍历复杂映射关系,value是基础类型
//3.遍历复杂映射关系,value是对象
return targetMap;
}
/**
* 预编译FieldMapping
*/
private List<AutoMachineAlgoRequestConfig.FieldMapping> compileConfig(List<AutoMachineAlgoRequestConfig.FieldMapping> fieldMappingList, Object obj) {
List<AutoMachineAlgoRequestConfig.FieldMapping> mappings = new ArrayList<>(fieldMappingList.size());
//缓存反射mapping
return mappings;
}
private Object getFieldValue(Object request, String fieldName) throws Throwable {
String cacheKey = request.getClass().getName() + "#" + fieldName;
MethodHandle handle = FIELD_HANDLE_CACHE.get(cacheKey);
return handle != null ? handle.invoke(request) : null;
}- 基于实现@FeignClient注解,实现HTTP调用的执行器,其中@FeignClient中的URL表示域名,autoMachineAuditAlgo方法中的path表示具体的URL,requestBody是请求体,另外还包含headers,不同算法需要不同headers也可动态配置。
- 返回结果均为String,而后解析成Map<String,Object>用于规则解析。
less
@FeignClient(
name = "xxx",
url = "${}"
)
public interface GenericAlgoFeignClient {
@PostMapping(value = "/{path}")
String autoMachineAuditAlgo(
@PathVariable("path") String path,
@RequestBody Object requestBody,
@RequestHeader Map<String, String> headers
);
@GetMapping("/{path}")
String autoMachineAuditAlgoGet(
@PathVariable("path") String path,
@RequestParam Map<String, Object> queryParams,
@RequestHeader Map<String, String> headers
);
}- 动态配置JSON。
json
{
"url": "/ai-check/demo1",
"requestMappingConfig": {
"fieldMappingList": [
{
"sourceFieldName": "categoryId",
"targetKey": "categoryId"
},
{
"sourceFieldName": "brandId",
"targetKey": "brandId"
}
],
"perItemMapping": {
"mappingFunctionCode": "firstAndFirstGroundPic",
"fieldMappingList": [
{
"sourceFieldName": "imgId",
"targetKey": "imgId"
},
{
"sourceFieldName": "imgUrl",
"targetKey": "imgUrl"
}
]
}
}
}机审规则动态解析建设
※ 实现逻辑
- 定义MachineAuditRuleEnum统一的动态配置枚举,并基于MachineAuditRuleProcess实现其统一实现类。
- 搭建QLExpress规则引擎,为了提升QLExpress规则引擎的效率,同样引入了缓存机制,在机审规则配置表达式时,则触发loadRuleFromJson,将表达式转换成规则引擎并注入到缓存当中,真正机审流程执行时会直接从缓存里获取规则引擎并执行,效率上有很大提升。
typescript
// 规则引擎实例缓存
private static final Map<String, ExpressRunner> runnerCache = new ConcurrentHashMap<>();
// 规则配置缓存
private static final Map<String, GenericEngineRule> ruleConfigCache = new ConcurrentHashMap<>();
// 规则版本信息
private static final Map<String, Integer> ruleVersionCache = new ConcurrentHashMap<>();
/**
* 加载JSON规则配置
* @param jsonConfig 规则JSON配置
*/
public GenericEngineRule loadRuleFromJson(String ruleCode, String jsonConfig) {
//如果缓存里已经有并且是最新版本,则直接返回
if(machineAuditCache.isSameRuleConfigVersion(ruleCode) && machineAuditCache.getRuleConfigCache(ruleCode) != null) {
return machineAuditCache.getRuleConfigCache(ruleCode);
}
// 如果是可缓存的规则,预加载
return rule;
}- 机审规则执行时,通过配置中的规则名称,获取对应的规则引擎进行执行。
typescript
/**
* 根据规则名称执行规则
* @param ruleCode 规则名称
* @param context 上下文数据
* @return 规则执行结果
*/
public MachineAuditRuleResult executeRuleByCode(String ruleCode, Map<String, Object> context, MachineAuditRuleProcessData ruleProcessData) {
if (StringUtils.isBlank(ruleCode)) {
throw new IllegalArgumentException("机审-通用协议-规则-规则名称不能为空");
}
//从缓存中获取规则引擎
//基于规则引擎执行condition
//统一日志
}※ 配置demo
- 动态配置JSON。
json
{
"ruleCode": "demo1",
"name": "规则demo1",
"ruleType": 1,
"priority": 100,
"functions": [
],
"conditions": [
{
"expression": "result.code == null || result.code != 0",
"action": {
"type": "NO_RESULT",
"messageExpression": "'无结果'"
}
},
{
"expression": "result.data == 0",
"action": {
"type": "PASS",
"messageExpression": "'机审通过"
}
},
{
"expression": "result.data == 1",
"action": {
"type": "REJECT",
"messageExpression": "'异常结果1'",
"suggestType": 2,
"suggestKey": "imgId",
"preAuditSuggestKey": "imgUrl"
}
},
{
"expression": "result.data == 2",
"action": {
"type": "REJECT",
"messageExpression": "'异常结果2'",
"suggestType": 2,
"suggestKey": "imgId",
"preAuditSuggestKey": "imgUrl"
}
}
],
"defaultAction": {
"type": "PASS"
}
}八、关于数据分析&指标提升
在经历了2-3个版本搭建完新机审链路 + 数据埋点之后,指标一直没有得到很好的提升,曾经一度只是维持在20%以内,甚至有部分时间降低到了10%以下;经过大量的数据分析之后,识别出了部分规则产品逻辑存在漏洞、算法存在误识别等情况,并较为有效的通过数据推动了产品优化逻辑、部分类目规则调整、算法迭代优化等,在一系列的动作做完之后,指标提升了50%+。
在持续了比较长的一段时间的50%+覆盖率之后,对数据进行了进一步的剖析,发现这50%+在那个时间点应该是到了瓶颈,原因是像"标题描述包含颜色相关字样"、"标题存在重复文案"以及部分轮播图规则,实际就是会存在不符合预期的情况,因此紧急与产品沟通,后续的非紧急需求停止,先考虑将这部分天然不符合预期的情况进行处理。
之后指标提升的动作主要围绕:
- 算法侧产出各算法能力的召回率、准确率,达标的算法由产品与业务拉齐,是否配置自动驳回的能力。
- 部分缺乏自动修改能力的机审规则,补充临时需求建设对应的能力。
经过产研业务各方的配合,以最快速度将这些动作进行落地,指标也得到了较大的提升。
往期回顾
1.营销会场预览直通车实践|得物技术
2.基于TinyMce富文本编辑器的客服自研知识库的技术探索和实践|得物技术
3.AI质量专项报告自动分析生成|得物技术
4.社区搜索离线回溯系统设计:架构、挑战与性能优化|得物技术
5.eBPF 助力 NAS 分钟级别 Pod 实例溯源|得物技术
文 / 沃克
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。