
#从零开发一个Agent TOC
AgentRAG概述
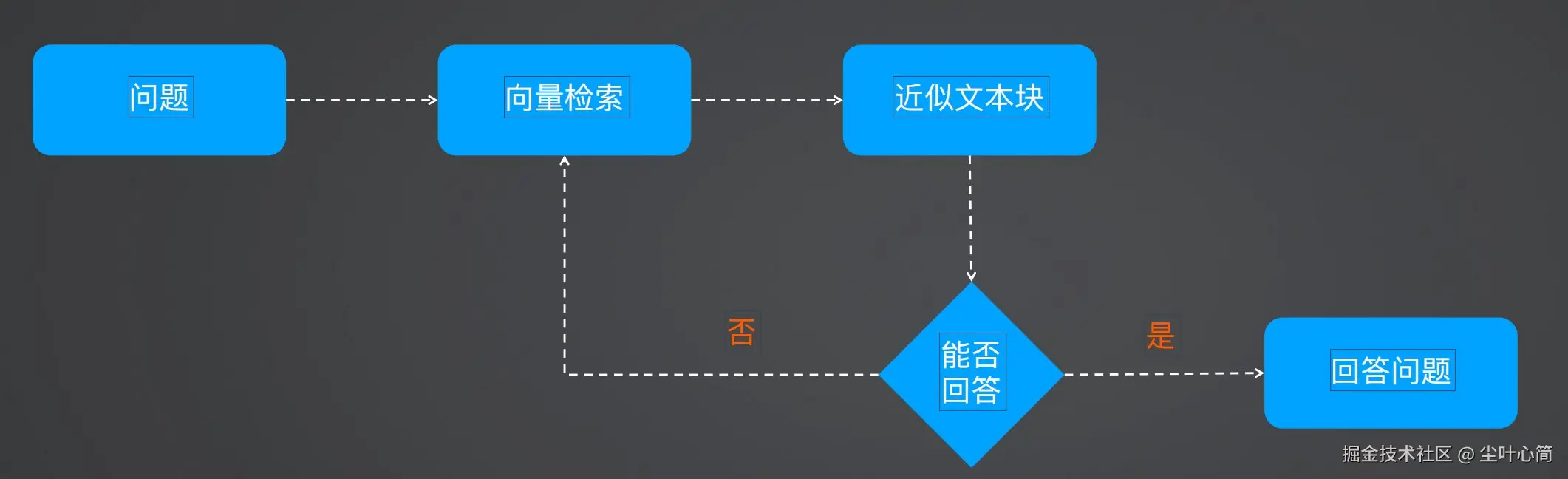
检索向量后,判断文本块是否包含问题答案 如包含则进行回答 如不包含则重新进入向量检索,匹配+1块 最大循环次数15
核心代码
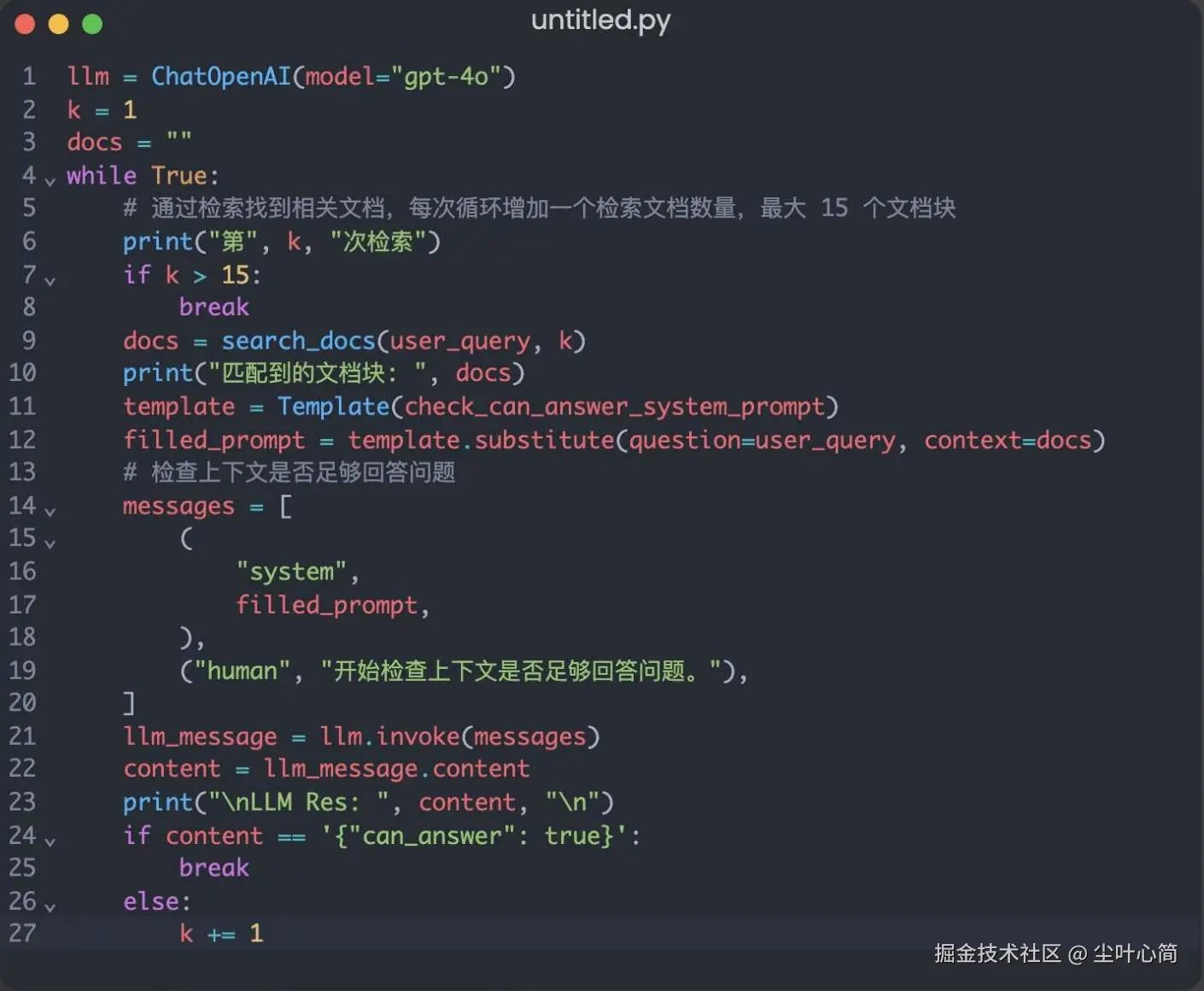
从向量数据库匹配文档,并让大模型反思 每次循环增加一个文档块,直到能回答问题 文档块数量超过15个仍无法回答问题则放弃
代码示例
首先安装相关依赖
bash
! pip install -qU langchain-openai langchain langchain_community langchainhub
! pip install chromadb==0.5.3
导入相关包,把上次传统的RAG代码给粘贴过来。
python
from langchain import hub as langchain_hub
from langchain.schema import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain_openai import OpenAIEmbeddings
import os
#from langchain_chroma import Chroma
from langchain_community.vectorstores.chroma import Chroma
from langchain_core.prompts import PromptTemplate
from string import Template
import uuid
python
# 读取 ./data/data.md 文件作为运维知识库
file_path = os.path.join('data', 'data.md')
with open(file_path, 'r', encoding='utf-8') as file:
docs_string = file.read()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
splits = text_splitter.split_text(docs_string)
print("Length of splits: " + str(len(splits)))
print(splits)
这里输出了一下分片,接下来我们将运维知识库的每一块文本向量化(Embedding)
python
# 保存到随机目录里
random_directory = "./" + str(uuid.uuid4())
embedding = OpenAIEmbeddings(
model="text-embedding-3-small",
openai_api_key="你的api key"
)
vectorstore = Chroma.from_documents(documents=splits, embedding=embedding, persist_directory=random_directory)
# vectorstore.persist()接着我们使用代码实现了一个传统的检索增强生成(RAG)流程,其中通过向量数据库检索相关文档、使用模板生成提示、并利用 GPT-4 模型生成答案,最后输出简洁回答。
python
# 传统 RAG 流程
retriever = vectorstore.as_retriever()
# 提示语模板
template = """使用以下上下文来回答最后的问题。
如果你不知道答案,就说不知道,不要试图编造答案。
最多使用三句话,并尽可能简洁地回答。
在答案的最后一定要说"谢谢询问!"。
{context}
Question: {question}
Helpful Answer:"""
custom_rag_prompt = PromptTemplate.from_template(template)
def format_docs(docs):
print("匹配到的运维知识库片段:\n", "\n\n".join(doc.page_content for doc in docs))
return "\n\n".join(doc.page_content for doc in docs)
llm = ChatOpenAI(model="gpt-4o",api_key="你的key")
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)
# 传统 RAG 无法回答的问题
res = rag_chain.invoke("谁管的系统最多?")
print("\n\nLLM 回答:", res)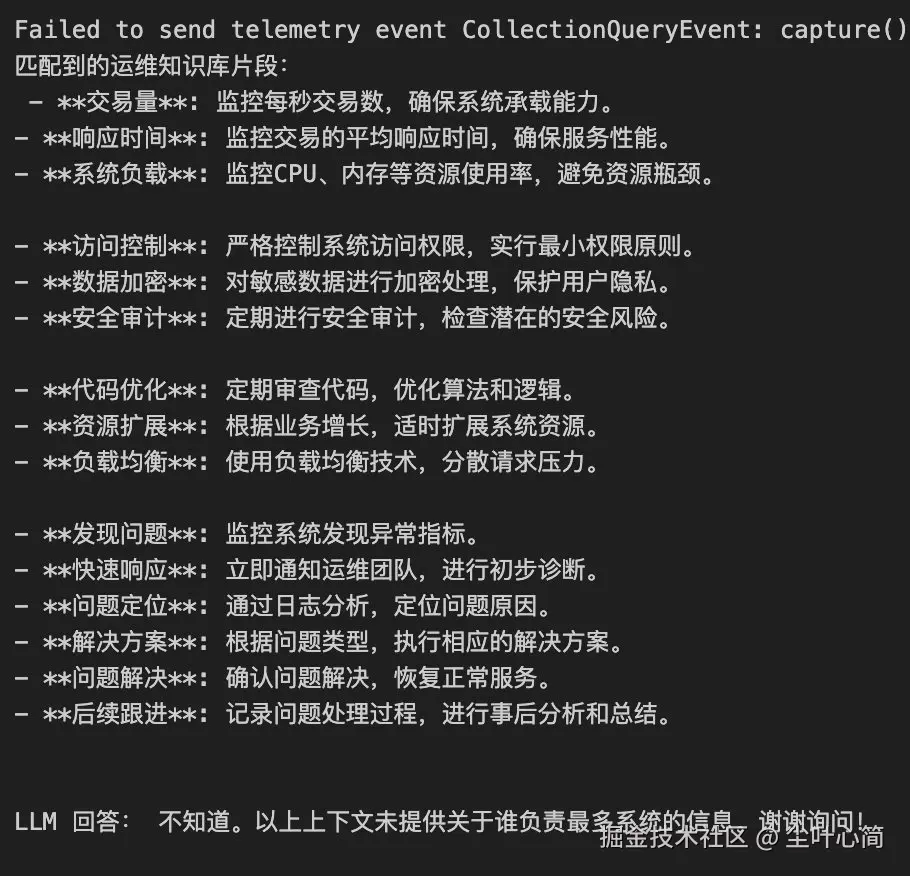
接着我们实现了一个基于 Agent RAG 流程的问答系统,通过逐步增加检索的文档数量来判断是否足够回答问题,最终生成答案。如果上下文不足以回答问题,系统会增加更多文档并重新检查,直到能够回答问题为止。
python
# Agent RAG 流程
# 文本相似性检索
def search_docs(query, k=1):
results = vectorstore.similarity_search_with_score(
query,
k=k,
)
return "\n\n".join(doc.page_content for doc, score in results)
user_query = "谁管的系统最多?"
check_can_answer_system_prompt = """
根据上下文识别是否能够回答问题,如果不能,则返回 JSON 字符串 "{"can_answer": false}",如果可以则返回 "{"can_answer": true}"。
上下文:\n $context
问题:$question
"""
llm = ChatOpenAI(model="gpt-4o",api_key="你的API Key")
k = 1
docs = ""
while True:
# 通过检索找到相关文档,每次循环增加一个检索文档数量,最大 15 个文档块
print("第", k, "次检索")
if k > 15:
break
docs = search_docs(user_query, k)
print("匹配到的文档块: ", docs)
template = Template(check_can_answer_system_prompt)
filled_prompt = template.substitute(question=user_query, context=docs)
# 检查上下文是否足够回答问题
messages = [
(
"system",
filled_prompt,
),
("human", "开始检查上下文是否足够回答问题。"),
]
llm_message = llm.invoke(messages)
content = llm_message.content
print("\nLLM Res: ", content, "\n")
if content == '{"can_answer": true}':
break
else:
k += 1
print("匹配到能够回答问题的知识库,开始进行回答\n")
# 最终推理
final_system_prompt = """
您是问答任务的助手,使用检索到的上下文来回答用户提出的问题。如果你不知道答案,就说不知道。最多使用三句话并保持答案简洁。
"""
final_messages = [
(
"system",
final_system_prompt,
),
("human", "上下文:\n"+ docs +"\n问题:" + user_query),
]
llm_message = llm.invoke(final_messages)
content = llm_message.content
print("\nLLM Final Res: ", content, "\n")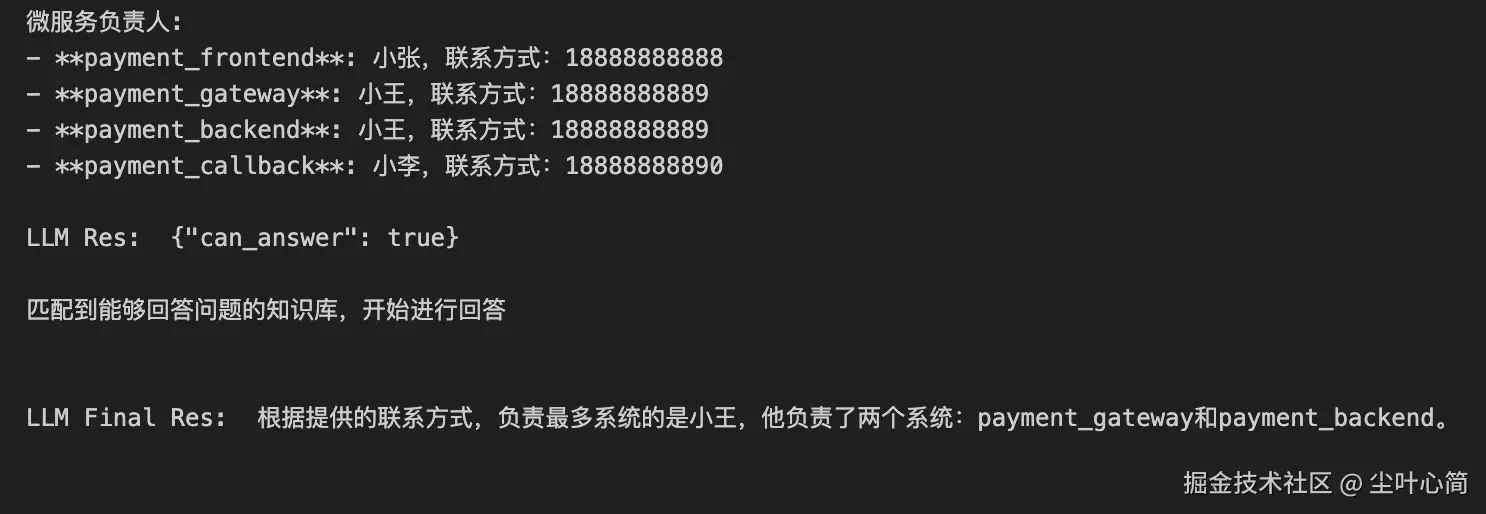
在经历第9次后我们发现它能够回答我们的问题了。
改进方向
判断文本块大小,并使用切片策略,避免上下文超限 改进向量搜索策略,例如通过增加offset参数过滤已验证无法回答问题的文本块 判断能否回答问题环节使用JSONMode获得更稳定的结构化输出