这个先进的 AI 为何会突然对一个汉字「情有独钟」?DeepSeek 最新的 V3.1 模型上线不到一周,就因一个离奇的 Bug 引发社区热议:无论任务是写代码还是整理物理试卷,模型总会莫名其妙地在文本中插入「极」字,甚至在自我修复时也无法幸免 。
上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。

经过这差不多一周时间的真实用户测试,DeepSeek-V3.1 却被发现存在一个相当让人无语的问题:其某些输出 token 会被随机替换为「极」。
具体来说,据知乎用户 Fun10165 描述,她在调用火山引擎版 DeepSeek V3.1 帮助整理一份物理试卷时发现,该模型的输出中会莫名出现一些「极」字。

图源:知乎 @Fun10165
而后面在 Trae 中测试 DeepSeek-V3.1 时也同样出现了这个问题。
有意思的是,她还尝试了调用官方 API 修复这个问题。结果,在修复的过程中又出现了这个问题。
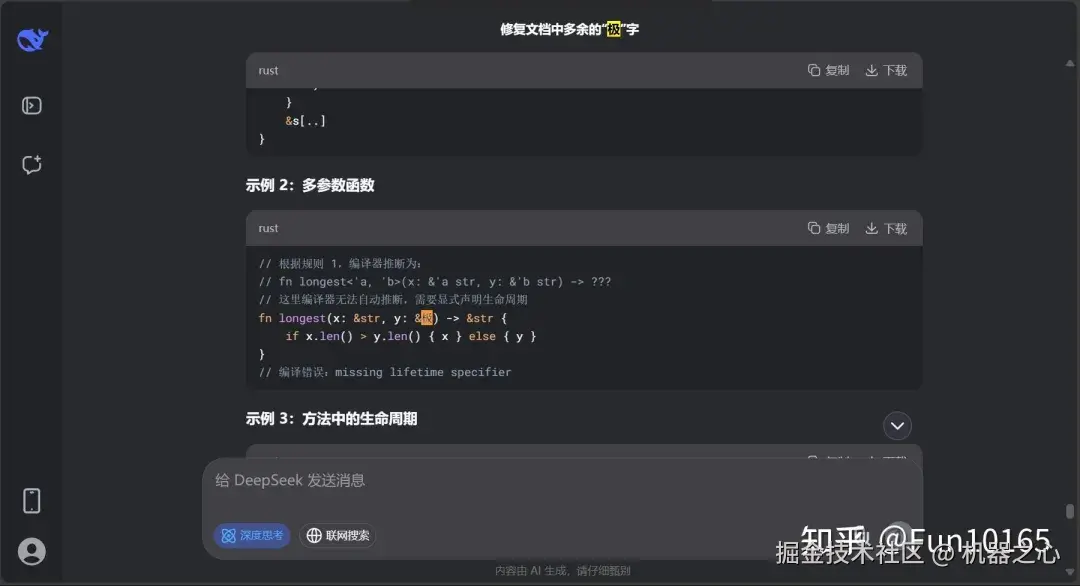
图源:知乎 @Fun10165
她表示:「实测,官方网页 / API 能复现,概率不高,但多试几次就能出来。VolcEngine API 复现概率非常高。」
帖子下方,也有一些其他用户分享了类似的发现。
比如知乎用户「去码头整点薯条」分享说 R1 也存在类似的问题,他还简单猜想了原因:「使用 R1 0528 的时候就遇到了很多次,我观察到的现象更离谱,会在代码里面插入 "极客园",而且遇到不止一次,怀疑是不是学习的时候吃进去了什么电子水印吃坏肚子了。」
知乎用户「琪洛」则发现 V3-0324 也存在类似问题,只不过这一次输出的是「极速赛车开奖直播」字符串。

图源:知乎 @琪洛
她猜想道:「怀疑可能数据没洗干净,即便重新训了 base 这个问题还是留下了,题主和其他回答所述「极」和「极速」可能就是这个词的残余痕迹。」
而在 Reddit 上,相关话题也正被热烈讨论中。
发帖者用户 u/notdba 表示,在测试 DeepSeek V3.1 时,他发现模型会莫名地在某些意料之外的位置输出如下 token:
-
extreme (id:15075)
-
极 (id:2577)
-
極 (id:16411)
很显然,这仨都是同一个词。
他继续描述到,除了这 3 种「极」 token 在贪婪解码中成为首选的情况之外,这些「极」 token 也经常在其他意想不到的地方潜伏为第二或第三选择。
他说:「我已经对所有流行的编码模型都做过同样的评估,这是我第一次遇到这种问题。」
他的猜测是该问题可能会被 MTP(多 token 预测)掩盖,并且当推理堆栈不支持 MTP 时就会变得更加明显,比如 llama.cpp 就还不支持 MTP。这个猜想的合理之处在于支持 MTP 的 DeepSeek 官方 API 更不容易遇到这种情况,而第三方部署的同款模型则更容易出现这个问题。
用户 u/nekofneko 则分享了另一个案例:

图源:Reddit u/nekofneko
他给出的可能解释是:「极」的 token 是 2577,而省略号「...」的 token 是 2576。这两者可能被模型混淆了。
还不只是「极」,也有用户发现 DeepSeek-V3.1 还存在多语言混用的问题,u/Kitano_o 分享说:「我使用 3.1 从中文翻译成俄语时,遇到一些奇怪的行为。它开始混合多种语言 ------ 添加英文词,也留下些中文词。有时这些问题会占到文本的 5%,有时只占 1%,甚至 0%。而且使用 OpenRouter 的不同提供商都会出现这个问题,即使我使用 DeepSeek 作为提供商也会。」

图源:Reddit u/Kitano_o
总体而言,对于 DeepSeek-V3.1 这个可以说相当严重的问题的原因,网友给出的猜测更多还是「数据污染」。
比如阶跃星辰黄哲威表示:「我认为是本身 sft 数据合成甚至是构造预训练数据的时候没洗干净引入了 "极长的数组" 这种怪东西(从 R1 的行为看,似乎大量使用了 RAG 方法来造难题的解答),然后 RL 的时候模型直接把这个字当某种终止符或者语言切换标记使用了。」
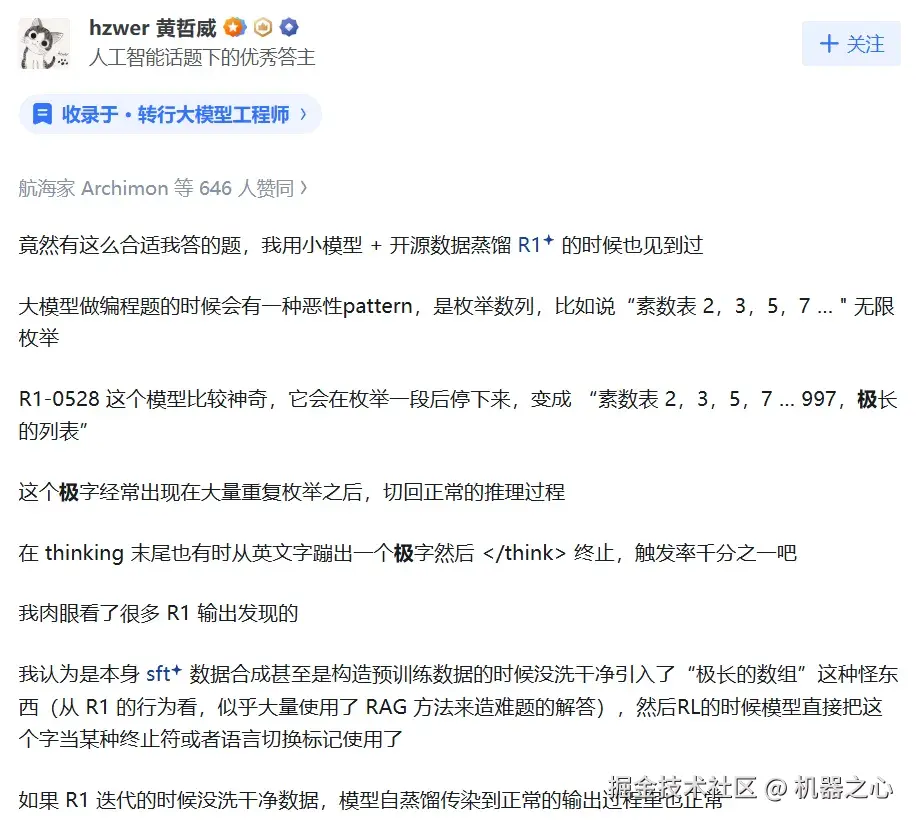
图源:知乎 @hzwer 黄哲威
他还提到:「其实推理出 bug,大概率都是数据问题,很多人都知道。只是 R1 的其它 bug 没有这么高频发生,社区不太关注而已。」
这次事件也给所有模型开发者敲响了警钟:在追求更高性能的 AI 模型时,最基础的数据质量,才是决定 AI 是否会「行为异常」的关键。
我们也把相关事件发送给了 DeepSeek 本尊,让它分析了一下可能的原因:

你遇到过这个问题吗?觉得可能的原因是什么?
参考链接