关于作者:
一个深耕自己,不内耗的长期主义者。一个对技术充满激情,对工作对生活充满热情的热血青年。坚持用通俗易懂的大白话写技术博文,并会持续更新。
和之前一样,今天还是用通俗易懂的大白话来写点我自己的理解和总结,今天聊一下数据结构中最基础最常用的两种:数组和链表。看完如果有什么疑问的地方,可以留言讨论,也可以私信。我坚信,真正能让大家看懂的技术文章才是好文章,这也是我最初决定写文章最主要的目标和动力,希望这篇文章对你有所帮助。
一、线性结构和非线性结构
首先了解一下数据结构里的线性结构和非线性结构的概念。
线性结构
线性结构:是数据按照顺序排列,每个元素只有一个前驱和一个后继,数据排列就像一条线。以下是线性结构的几个特点:
- 一对一关系:每个元素(除首尾)仅与前后相邻元素直接关联。
- 顺序存储或链式存储:顺序存储(如数组),元素在内存中连续存放。链式存储(如链表),元素通过指针/引用连接。
- 遍历方式单一:只能从头到尾或从尾到头依次遍历访问。
常见的线性结构:数组、链表、队列、栈
示例:数组
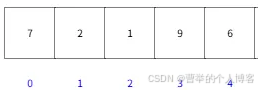
链表

一般常见的线性结构的时间复杂度是O(n),但数组查询时间复杂度是O(1)。
非线性结构
非线性结构:数据元素之间进行关联的时候,不是一对一,而是存在一对多或多对多关系,无法用简单的线性序列表示,数据的组织形式不是单一的一条线,而是更复杂的网状结构。非线性结构的几个特点:
-
一对多或多对多的关系
-
可有多种遍历方式:比如二叉树的遍历方式有前序遍历、中序遍历和后序遍历。
常见的非线性结构:树,二叉树,多叉树,哈希表。
示例:二叉树
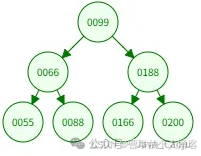
哈希表
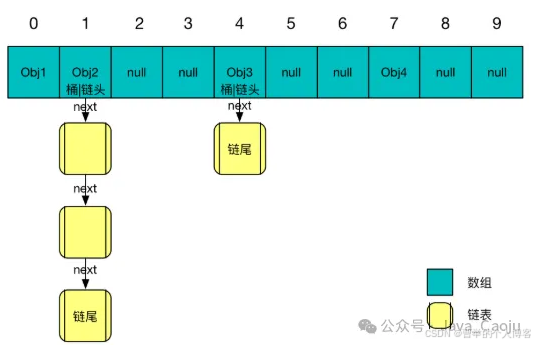
一般常见的非线性结构的时间复杂度是O(logn)。了解了这些后,下面讲一下数据结构中最底层,也是最常用的两种数据结构:数组和链表。
二、数组
数组这种结构大家应该都不陌生,很多结构都可以基于数组来组织维护。
数组这种结构,它是在申请内存的时候,就直接申请一大片连续的内存空间,它存储元素的时候,这些元素都是连续的存在一起的,这里说的连续,指的就是物理上真正的连续。
这种结构上的特性,就决定了它查询的时候特别快,查询的时间复杂度是O(1);但是插入和删除的时候比较慢,尤其是从头或从中间插入和删除会更慢,最坏情况下的时间复杂度是O(n)。下面具体分析一下原因
数组查询为什么那么快?
数组,它之所以那么快,按我的理解总结了两点:
-
第一:你new数组,申请内存的时候,它是直接申请一大片连续的内存空间,它存储元素的时候,这些元素都是连续的存在一起的,物理上就是连续的。
-
第二:你在new数组的时候,数组中每个元素占的空间大小就已经确定了。
如果你new的数组里存的是基本数据类型的话,那数组中的每个元素的大小就是这个基本数据类型的大小。比如Java基本数据类型中的:byte、short、int、long的大小分别是1、2、4、8个字节。
如果数组里存的是对象类型的话,存的并不是对象本身,而是对象的引用。在64位的环境下,每个引用的大小是64bit位(8字节),但是默认会开启指针压缩,压缩后,每个引用的大小是32bit位(4字节)。
压不压缩不是这里的重点,重点是要明白,数组里存的是对象类型的话,每个元素的大小也是固定一样的。
所以总之,在new数组的时候,数组中每个元素占的空间大小就已经确定了,知道了数组中每个元素的大小后,再加上数组中的元素在内存中是连续的,再加上数组申请内存时它的起始内存地址是知道的。
那你根据下标去数组里获取某一个元素的时候,通过每个元素占用的大小乘以这个下标,很容易就能计算出要找的这个下标元素的内存偏移量(也就是内存地址),有了内存地址就可以直接拿到这个元素了。所以数组根据下标查找的时候非常非常快,时间复杂度是O(1)。
数组插入和删除为什么慢?
数组之所以,插入和删除慢,尤其是从头或从中间插入和删除会更慢。是因为从头或从中间插入完之后,后边的每一个元素都要向后移动一个位置。从头或从中间删除完之后,后边的每一个元素都要向前移动一个位置。这个过程,就导致了数组的插入和删除操作会比较慢。
三、链表
链表这种数据结构,它和数组不一样。它不是连续的内存空间,它是靠一个一个的Node节点对象把数据串起来的,这些Node节点在存储的时候,物理上并不需要连续。然后,链表是分为单链表和双链表。
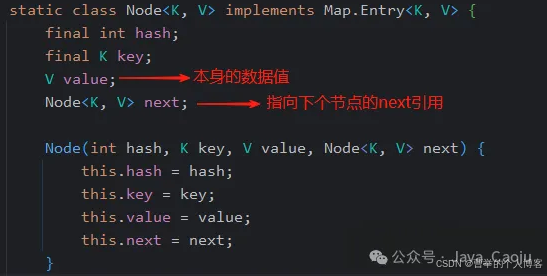
如果是单链表的话,每个Node对象中,除了存储本身的数据值之外,还维护了一个指向下个节点的后继节点(next)引用。HashMap中桶里元素形成的链表结构就是一个典型的单链表结构,如下图,是HashMap里内部Node类的源码。
如果是双链表的话,每个Node对象中,除了存储本身的数据值之外,还维护了两个引用,一个是指向上一个节点的前驱节点(prev)引用,一个是指向下个节点的后继节点(next)引用。LinkedList就是双链表结构来实现的,如下图,是LinkedList里内部Node类的源码。
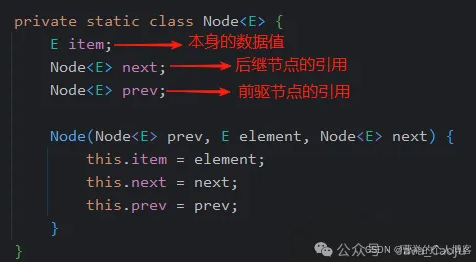
然后链表中,它还会维护头节点的引用和尾节点的引用,用这个引用来作为操作链表的入口,比如遍历链表和向链表中插入数据。
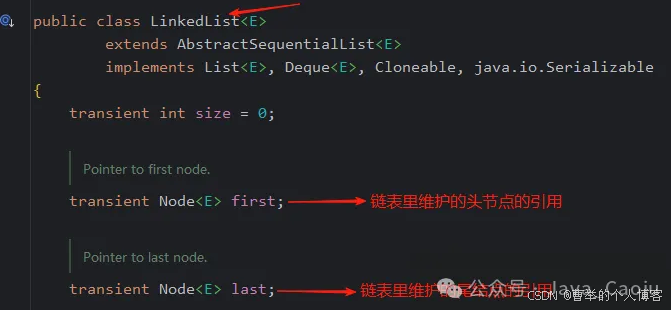
双链表的结构中,是要求可以双向遍历的,所以双链表中头节点的引用和尾结点的引用,这两个都必须维护。
因为只有找到了头节点,才能从头节点开始实现正向遍历;只有找到了尾结点,才能从尾结点开始实现逆向遍历。从而实现双向遍历。
并且,维护了头尾这两个节点的引用后,可以大大提高头部插入和尾部插入的效率
LinkedList就是双链表的结构,它就维护了这两个引用,如下图,看下它的源码
单链表的情况下,只要求单向从头遍历,虽然只维护一个头节点的引用,就能实现数据的单向遍历。
但是,只维护一个头节点的话,从尾部插入的时候,就只能一个一个的去遍历循环,直到循环到next引用为null的节点,就说明这个节点是尾节点,然后把新插入的节点挂到这个尾节点上。
所以,一般情况下,就算是单链表,大概率也是会多维护一个尾节点的引用的,多维护一个尾节点的引用后,尾部插入的时候就不需要去循环遍历了,尾部插入的效率大大提升。
ok,数组和链表这俩最底层的数据结构,今天就写到这里吧。我坚信,真正能让大家看懂的技术文章才是好文章。这也是我最初决定写文章最主要的目标和动力。希望这篇文章对你有所帮助,欢迎留言讨论,后续会更新更多用大白话来讲的内容。
以上写的都是自己的理解和总结,纯手敲,原创不易,如果觉得文章对你有帮助,可以关注一下,感谢。