
「【新智元导读】Jet-Nemotron 是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块 JetBlock,实现了从预训练 Transformer 出发的高效架构优化。相比 Qwen3、Gemma3、Llama3.2 等模型,Jet-Nemotron 在数学、代码、常识、检索和长上下文等维度上准确率更高,同时在 H100 GPU 上推理吞吐量最高提升至 53 倍。」
英伟达最近真的痴迷上「小模型」了。
刚刚,英伟达发布了一个全新的混合架构语言模型系列,Jet-Nemotron。

项目地址:github.com/NVlabs/Jet-...
Jet-Nemotron 系列有 Jet-Nemotron-2B 和 Jet-Nemotron-4B 大小。
英伟达表示 Jet-Nemotron 系列「小模型」性能超越了 Qwen3、Qwen2.5、Gemma3 和 Llama3.2 等当前最先进的开源全注意力语言模型。
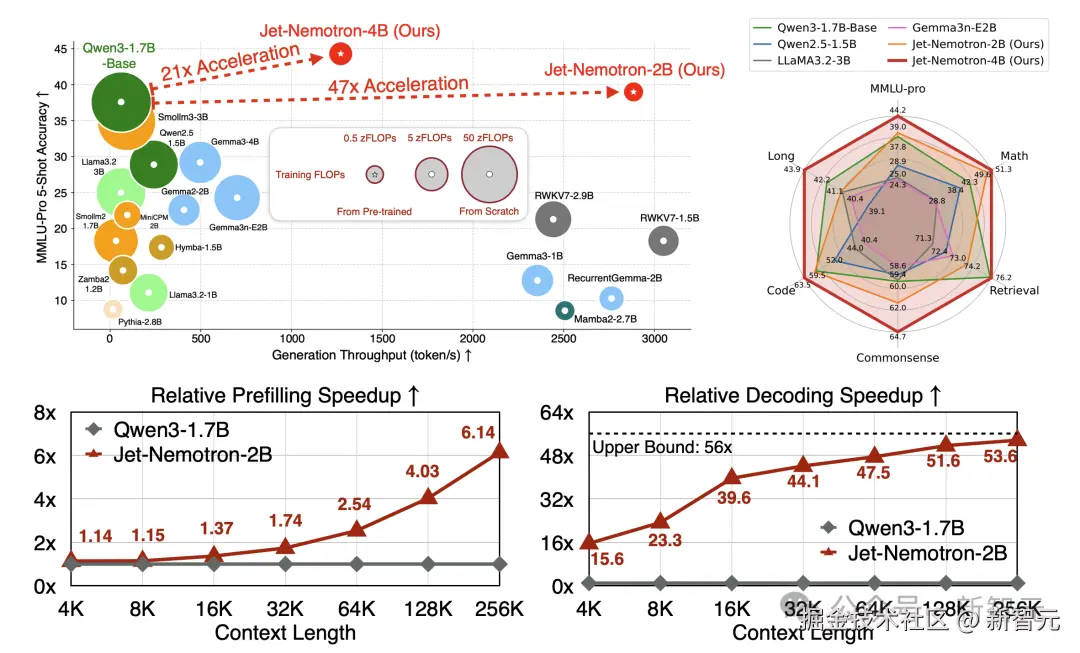
同时实现了显著的效率提升,在 H100 GPU 上生成吞吐量最高可提升 53.6 倍。
在右上角的雷达图中,可以看到 Jet-Nemotron 简直就是六边形战士。
Jet-Nemotron-4B 模型在六个维度 「MMLU-pro、Math、Retrieval、Commonsense、Code、Long 几乎都拉满。」

在预填充和解码阶段,Jet-Nemotron-2B 在上下文越增加的情况下,「相对 Qwen 3-1.7B 优势越夸张」。
一句话总结就是**「同等硬件与评测设置下」,Jet-Nemotron 在「长上下文」**的场景里,把吞吐做到了数量级提升(解码可达 50 倍提升)。
同时在常识 / 数学 / 代码 / 检索 / 长上下文等维度的**「准确率不降反升。」**
相较传统全注意力小模型又快又准。
看来,英伟达盯上了小模型 Small Model 这个领域。
上一周,他们刚刚发布了只有 「9B 大小****的 NVIDIA Nemotron Nano 2 模型。」
在复杂推理基准测试中实现了和 Qwen3-8B 相当或更优的准确率,并且吞吐量**「最高可达其 6 倍」**。
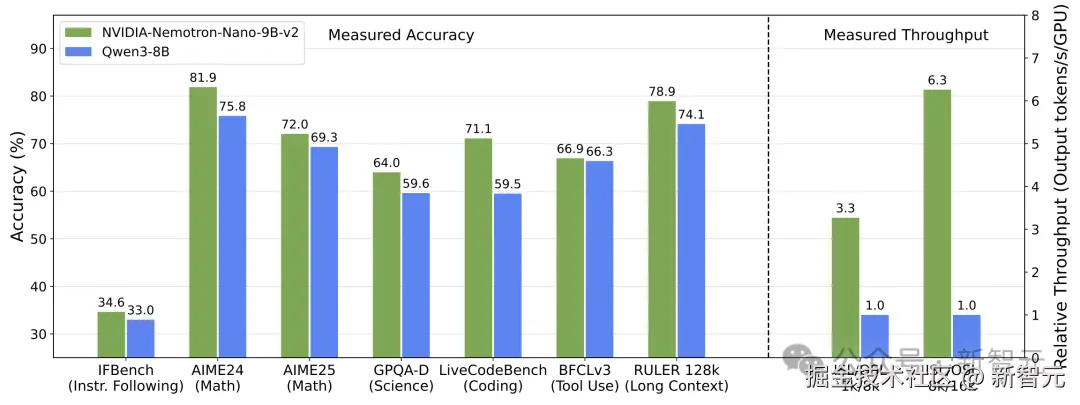
今天就推出了更小的 Jet 系列,体量降到了 2B 和 4B 模型。

「核心创新」
Jet-Nemotron 有两项核心创新。
- 后神经网络架构搜索(Post Neural Architecture Search,PostNAS),这是一个高效的训练后架构探索与适应流程,适用于任意预训练的 Transformer 模型;
- JetBlock,一种新型线性注意力模块,其性能显著优于先前的设计,如 Mamba2。
「 」
」
「PostNAS:训练后架构探索与适配」
与之前从头开始训练以探索新模型架构的方法不同,PostNAS 在预训练的 Transformer 模型基础上进行构建。
同时支持对注意力块设计的灵活探索,从而大大降低了开发新语言模型架构的成本和风险。
PostNAS 首先确定全注意力层的最佳放置位置,然后**「再搜索改进的注意力块设计」**。
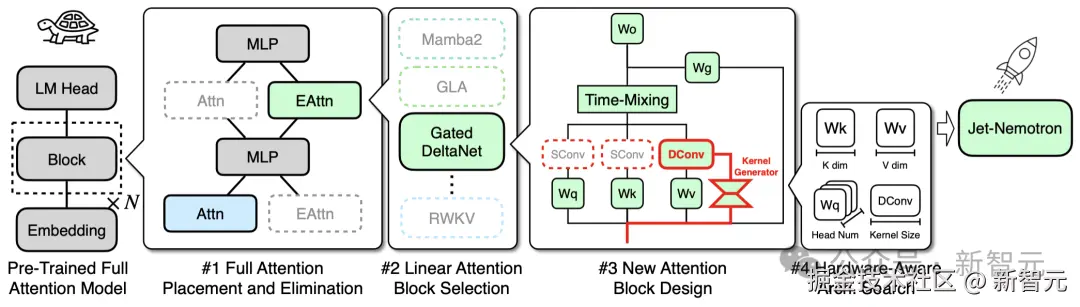
「PostNAS」 从一个**「已预训练的全注意力模型」**出发,并将 「MLP 冻结」。
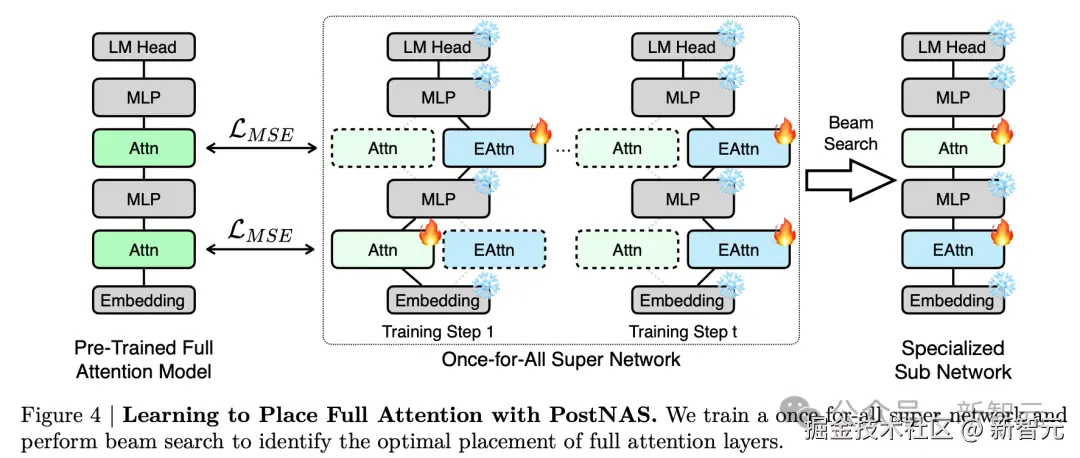
随后对高效注意力块的设计进行**「由粗到细」**的搜索:
先确定**「全注意力层的最优放置位置」,再 「选择最合适的线性注意力块」或 「采用新的线性注意力块」,最后「搜索最优的架构****超参数」**。
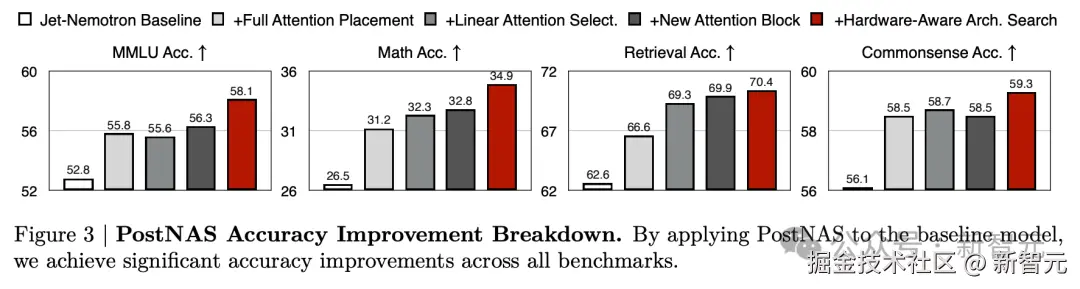
通过将 PostNAS 应用于基线模型后,在**「所有」基准测试上都取得了「显著的准确率提升」**。
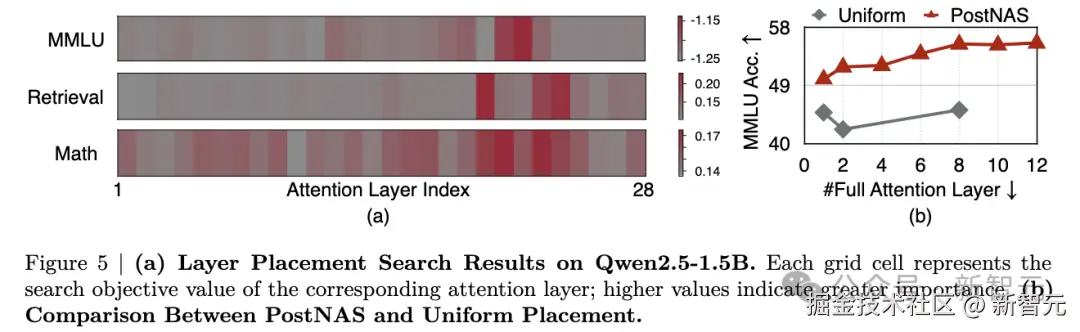
在预训练的 Transformer 模型中,并非所有注意力层的贡献都是相同的。
PostNAS 揭示了预训练 Transformer 模型中重要的注意力层。
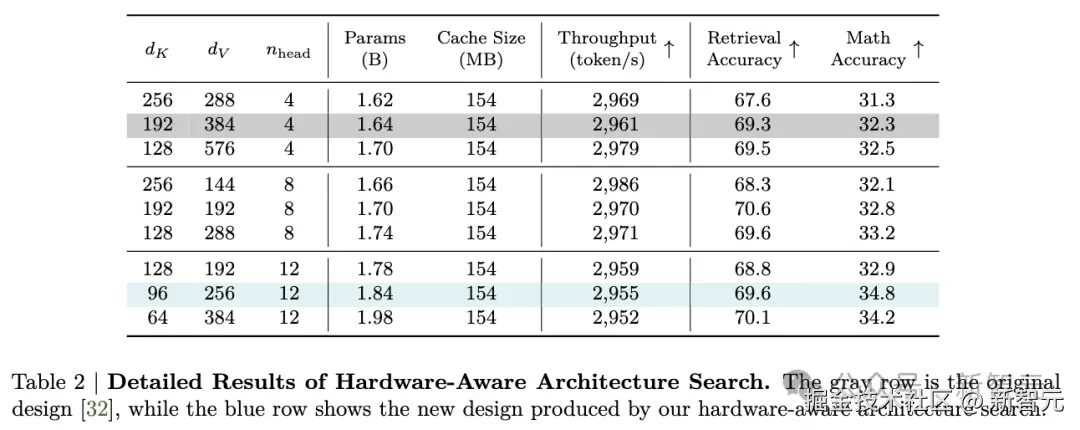
KV 缓存大小是影响长上下文和长生成吞吐量的最关键因素。
PostNAS 硬件感知搜索能够发现一些架构,在保持相似生成吞吐量的同时,拥有更多参数并实现更高的准确性。
「」
「JetBlock: 一种具有 SOTA 准确率的新型线性注意力模块」
通过 PostNAS,引入了 JetBlock:一种新颖的线性注意力模块,它将动态卷积与硬件感知架构搜索相结合,以增强线性注意力,在保持与先前设计相似的训练和推理吞吐量的同时,实现了显著的准确率提升。
下方使用完全相同的训练数据和训练方案,对 Mamba2 Block 与 JetBlock 进行了公平的对比。
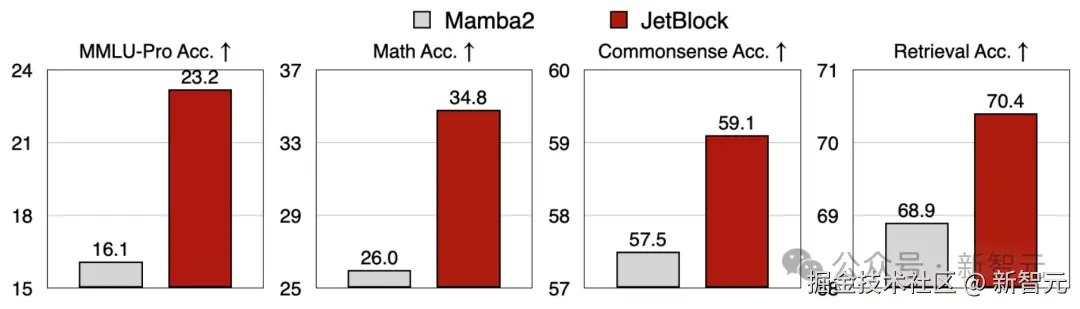
「性能」
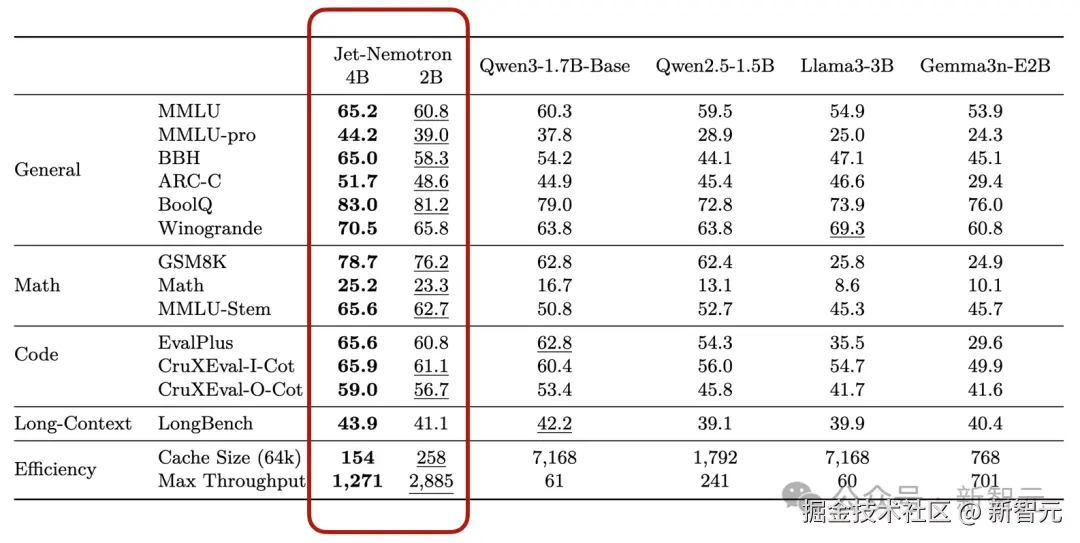
Jet-Nemotron-2B 和 Jet-Nemotron-4B 在全面的基准测试中达到或超过了主流高效语言模型(例如 Qwen3)的准确率。
同时运行速度明显更快------分别比 Qwen3-1.7B-Base 快 21 倍和 47 倍。
参考资料: