-
随着互联网迈入到了 AI 时代、在 AI 时代下互联网的内容生产流程都发生了显著的转变,这对基础设施(Infra)也提出了新的诉求,相比于传统的 Web 应用,LLM 应用的内容生成时间会更长,对话连续性对用户体验至关重要,互联网内容的生产机制也从 UGC(User Generate Content) 转变为 AIGC(Artificial Intelligence Generate Content)。
-
网关最基础的作用:网关是所有流量的统一入口、网关负责接收所有外部请求、并将请求转发给具体的后端服务,顺便做鉴权、限流等。
-
最早的网关它就是一个简单的反向代理:把客户端请求转发给后端服务器、再把后端服务器的响应返回给客户端。
网关的演进历程
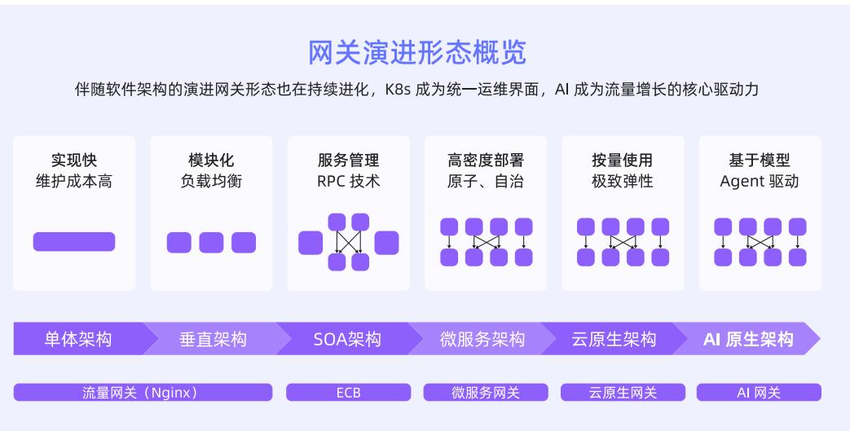
-
以 Nginx 为代表的流量网关: 那流量网关的核心目的、主要是为了解决多业务节点之间的流量负载均衡问题、从而避免单点故障,以此来确保服务的稳定性和连续性。
-
ESB网关: ESB - 企业服务总线是一个集中式的业务网关,ESB 网关的核心目的是为了标准化不同系统和服务之间的通信问题。
-
微服务网关: 微服务网关是微服务架构当中的核心组件,它可以实现负载均衡、限流、风控、用户认证以及权限校验,比如 Spring Cloud Gateway 就是一个广泛应用的微服务网关。
-
云原生网关: 云原生网关是伴随着 Kubernetes 而广泛应用的一种网关,那云原生网关最大的特点就是提供了弹性扩缩容、来帮助用户解决应用容量调度的问题。
-
AI 网关 **:**AI 网关主要处理以 SSE/WebSocket 为主的 AI 流量,也就是处理长连接,相比于传统 HTTP 协议的 request- response 模式,Server 可以主动发送数据给 Client。
AI 场景下的新场景和新需求
相较于传统的 Web 应用,LLM 应用在网关层的流量有以下三大特征:
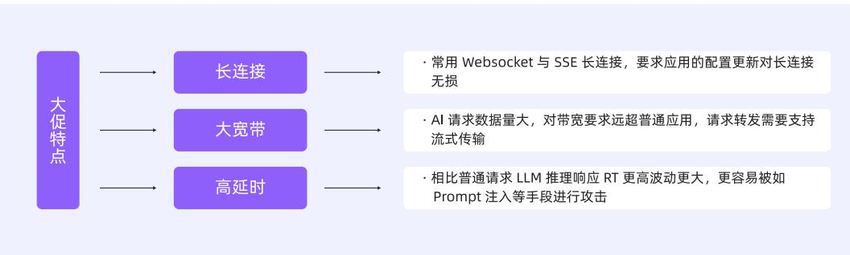
-
长连接 **:**由 AI 场景常见的 Websocket 和 SSE 协议决定(用于服务端实时推送数据到客户端浏览器),长连接的比例很高,要求网关在更新配置操作时、对长连接无影响,不影响业务。
-
**高延时:**LLM 推理的响应延时(RT)比普通应用要高出很多,使得 AI 应用面向恶意攻击会很脆弱,容易被构造慢请求进行异步并发攻击,攻击者的成本低,但服务端的开销很高。
-
**大带宽:**在 AI 场景下、对于带宽的消耗要远超于普通应用,网关如果没有实现较好的流式处理能力和内存回收机制,那就会很容易导致内存快速上涨。
传统 Web 应用当中普遍使用的 Nginx 网关、难以应对以上新需求,例如配置变更时需要 Reload、导致连接断开,不具备安全防护能力等,因此国内外均出现了大量基于 Envoy 为内核的新一代开源的 AI 网关,AI 网关作为新一代 API 网关,承载多模型流量调度等关键能力,比如阿里巴巴开源的 Higress 网关,在阿里巴巴的内部实践当中、Higress 已经作为了千问 App 的流量网关,Higress 提供了 AI 业务下的网关流量接入。
那 Higress 是如何实现网关配置的热更新呢?
-
在 AI 时代的互联网下、以 LLM 为驱动的对话式场景,大量采用 SSE/WebSocket/gRPC 等长连接协议来维持会话,那网关除了要解决并发连接的问题之外,还需要解决配置变更导致的连接断开问题、因为连接一旦断开、就会导致用户的会话断开,从而影响用户体验,并且在高并发的场景下,断开后的并发重连很有可能将网关和后端服务同时打挂。
-
而类似于 Nginx 这样的 Web 2.0 时代所诞生的流量 网关 ,并不能解决该问题,因为 Nginx 的整体配置文件发生任意变更,都需要重启 Worker 进程,这会同时导致客户端连接(Downstream)和服务端连接(Upstream)断开:
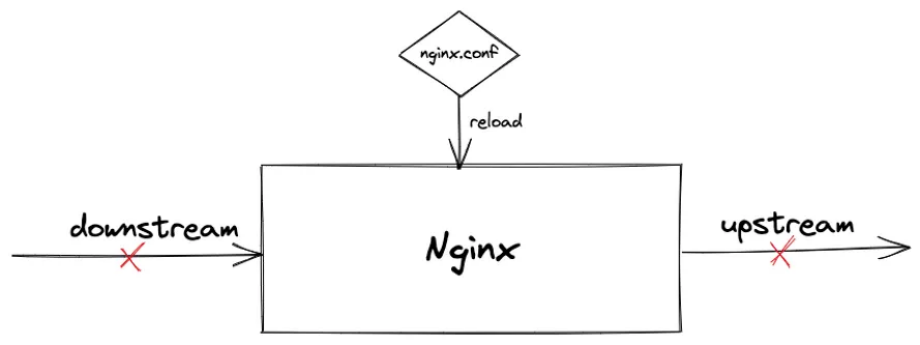
-
而 Higress 这样的开源网关,使用 Envoy 作为数据面来解决这一问题,这也就意味着、在 Higress 这个网关内部,真正负责接收请求、转发流量的是 Envoy。
-
在云原生 / Service Mesh / 网关的体系里面,经常会把组件分成两块,一块儿叫做控制面、一块儿叫做数据面:
-
Control Plane - 控制面负责配置管理
-
Data Plane - 数据面负责转发请求、处理流量
-
-
-
Envoy 对网关配置做了更合理的抽象,Envoy 在设计之初就考虑配置要能够支持在线动态更新,而这个支持配置在线动态更新的能力是靠一个叫做 xDS 的协议来实现的。
-
Higress 能够针对 Token 进行限流(也就是它提供了 Token 级别的精细化流量管控)、而 Token 就能够量化 LLM 处理的数据量,这样就能够更好的做好安全和流量防护,基于 Token 的完整可观测能力,也是 AI Infra 中不可或缺的。
-
Higress 能够对请求/响应进行真正的流式处理。
在 AI 场景下的网关架构
- AI 网关用于统一接入和调度 LLM 服务的系统。
-
负载均衡 : 由于在 AI 场景下,网关的后端通常是模型服务本身,那这就对网关的负载均衡能力提出了特殊要求,由于 LLM 场景具有高延时、且不同请求之间的差异大,传统的 RoundRobin、也就是轮询负载均衡、无法平衡其负载,而Higress 采用了基于最小请求数的负载均衡策略,也就是它会将请求分发给给当前请求数最少的后端节点。
-
流量灰度和可观测:
-
所谓灰度就是不是一次性全量发布,而是先让一小部分用户先去试用新版本、没问题之后再逐步放开,灰度的目的就是为了安全发布。
-
而可观测性是指系统出问题时,你能不能知道哪里出了问题?为什么出问题?可观测性有三大支柱:
-
**指标:**比如系统的 QPS、TPS
-
**日志:**所谓日志就记录了某个请求的完整处理过程
-
**链路追踪:**也就是一个请求都经过了哪些服务?
-
-