文章目录
检索模型与RAG
检索模型
- 布尔模型(Boolean Model)
- 基本思想: 使用布尔逻辑算符(and,or,not)来连接检索查询中的关键词,从而筛选出匹配的文档
- 特点:检索结果是二元的,即文档要么匹配查询,要么不匹配。没有考虑文档和查询之间的相关性,只关注关键词的存在与否
- 向量空间模型(Vector Space Model)
- 基本思想: 将文档和查询表示为向量,其中的向量的维度是词汇表中的词汇,每个维度上的值表示对应词汇在文档或查询中的权重
- 特点:考虑了文档和查询之间的相关性,通过计算向量之间的相似度来排序检索结果。常用的相似度计算方法包括余弦相似度
- 概率检索模型(Probabilistic Model)
- 基本思想:假设检索过程涉及到概率模型,其中文档和查询之间存在概率分布。
- 特点: 考虑了文档和查询之间的概率关系,能够更灵活地处理相关性 。典型的概率检索模型包括Okapi BM25
全文检索与布尔检索
全文索引 (Full-Text Indexing) 是一种数据结构,它 记录了文档集合中所有词项的位置信息,目的是为了支 持高效的 全文检索。可以把它想象成一本书的索引, 但这个索引不是按章节或主题分类,而是包含了书中出 现的每一个有意义的词,并指明了这些词在哪些页码 (文档)的什么位置出现。
布尔检索 是一种 信息检索模型,它基于布尔逻辑 (AND, OR, NOT)来处理用户查询并返回结果。纯粹 的布尔检索模型不会对返回的文档进行相关性排序。所 有匹配查询的文档都被视为同样相关
稀疏检索模型(Sparse Retrieval):
-
核心定义 :基于关键词匹配的传统检索方法,文档和查询被表示为高维稀疏向量(大部分元素为0),通过词频统计评估相关性。
-
主流算法 :TF-IDF(词频-逆文档频率)、BM25(优化的关键词匹配算法)。
-
特点 :
-
优点:计算速度快、易于实现、大规模文档集上性能稳定。
-
缺点:仅依赖字面匹配,无法捕捉语义关系(如"苹果"与"水果"的关联)。
-
-
用途 :适用于需要快速响应的场景,如搜索引擎的初步召回阶段,或对计算资源有限的应用。
稠密检索模型(Dense Retrieval)
- 优点:能理解语义关系,处理同义词、近义词,提高检索准确性和召回率。
- 缺点:计算复杂度高,对硬件资源要求高。
- 用途 :适用于需要精准语义匹配的场景,如智能问答系统、个性化推荐、RAG(检索增强生成)等。
全文检索 是基础框架,稀疏检索和稠密检索是其具体实现方式:
- 稀疏检索是全文检索的传统实现(基于关键词);
- 稠密检索是全文检索的现代升级(基于语义)。
- 混合检索 (结合稀疏与稠密)是当前主流趋势,兼顾效率与准确性(如RAG系统中常采用"稀疏召回+稠密精排"的架构)。
反向索引 (也称为 倒排索引)是全文检索最核心、最 基础的数据结构。它的名称"反向"或"倒排"源于它与传 统数据库"正向索引"的对比。
- 正向索引:传统数据库通常维护一个从"文档ID(或 记录ID)"到"文档内容"的映射。当你查找特定内容 时,需要遍历文档,检查其内容是否匹配。
- 反向索引:恰好相反,它维护一个从"词项"到"包含 该词项的文档列表"的映射。当你查找某个词时,可 以直接从这个列表中找到所有相关的文档
TFIDF和BM25
TF-IDF(Term Frequency-Inverse Document Frequency)和BM25(Best Matching 25)都是基于词频(TF)的方法。

bm25 是tfidf 的优化版本,主要是优化了tfidf 对长文档打分权重过高
bm25 中,在IDF 的计算中,使用了饱和函数,避免在极端情况(词项出现评率极低/极高的情况)下 IDF值 过于极端
在权重计算情况下,加了一个文档长度规划,优化了长文档中的评分过高的情况
绝大数情况下,搜索引擎中,都使用的bm25 打分算法

k1 取值 1.2, 2.0 :默认值为1.2 控制词频(TF)增长的饱和速度,平衡高频词的影响。
b 取值 0, 1 :默认值为0.75 控制文档长度对得分的影响程度,平衡长文档和短文档的权重。
大模型应用RAG
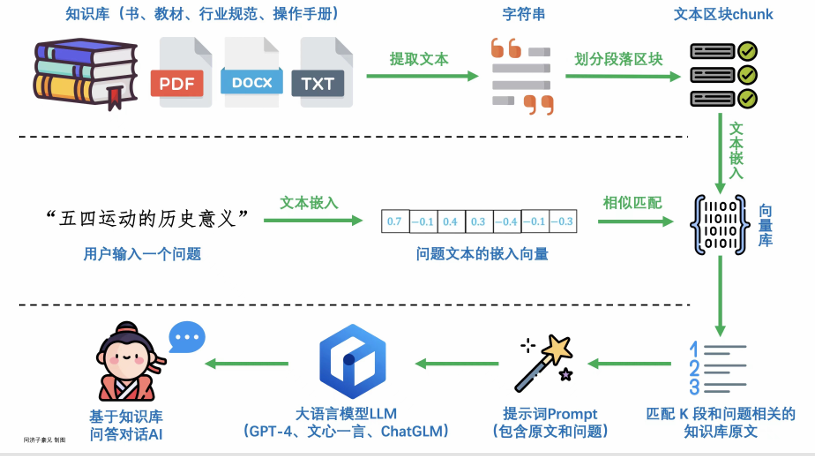
在RAG(检索增强生成)系统中, 文本分块(Chunking) 是将原始长文本分割成更小、更易于处理的文本片段的过程,这些片段被称为 Chunk 。以下是对其的详细介绍:
1. 分块的核心目的
- 提升检索效率 :大文本直接检索会增加计算成本,分块后可缩小检索范围。
- 优化上下文相关性 :模型(如LLM)的上下文窗口有限,分块能确保输入的文本片段与查询高度相关。
- 提高生成质量 :精准的分块可减少无关信息干扰,使生成内容更准确。
2. 常见分块策略
- 固定长度分块 :按字符数或token数均匀分割(如每200-500token一块),简单但可能破坏语义完整性。
- 语义分块 :基于文本语义边界(如段落、章节、句子)分割,保留逻辑完整性(常用方法包括NLTK分句、spaCy语义分析等)。
- 滑动窗口分块 :设置重叠区域(如50token),避免关键信息被分割到不同块中。
- 层次化分块 :先粗分(如章节),再细分(如段落),支持多粒度检索。
3. 分块大小的影响
- 过小的块 :可能丢失上下文关联,导致检索结果碎片化。
- 过大的块 :包含冗余信息,增加模型处理负担,降低检索精度。
- 经验值 :通常根据嵌入模型(如BERT、Sentence-BERT)的最大输入长度调整,常见范围为256-1024token。
文本嵌入向量数据库相似度计算 是 稠密检索模型(Dense Retrieval)------ 这一块也可以采用全文检索的方案,通常是两者混用, 文本库过大,先通过稀疏检索,然后在采用稠密检索
提示词工程
提示词工程(prompt工程),通过传递给语言模型的指令 和上下文来增强大模型对知识库内容的检索和问答,实现用户期望模型任务
- Prompt Engineering(提示工程)是开发和优化Prompt,让大模型输出更加有效的结果。
- Prompt Engineering 并不设计修改和训练模型,只关注模型的输入和输出
输入内容一般包括
- 任务提示:核心任务
- 上下文:任务描述 / 背景
- 输入数据:输入的自定义文本
- 输出格式
上下文学习 (In-context Learning) 是大语言模型的一个关键能力。它指的是模型能够仅根据输入中提供的上下文 信息 (比如一些示例)来完成任务,而无需更新模型的参数。例如,你给模型一个"翻译:你好 -> Hello"的例子, 然后给它一个"翻译:再见 ->"的输入,模型就能理解并完成任务。这种学习方式是GPT-3等模型的强大之处。
prompt 注意事项:
- 明确表达任务的目的,建议直接提到具体任务的名字。如情感分类、文本翻译等。
- 给出正确的少量参考案例,包括输入和输出。增加模型对少样本 或 临界情况的建模能力