点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到: Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Kafka 集群模式搭建
- Kafka 集群模式的应用场景
- 实机云服务器搭建

Kafka监控度量指标详解
度量指标系统架构
Kafka采用两套度量指标系统来满足不同组件的监控需求:
-
Yammer Metrics:主要应用于Kafka服务器端(broker)和Scala客户端
- 成熟稳定的度量库,提供丰富的度量类型
- 支持多种输出方式,包括JMX、CSV、SLF4J等
-
Kafka Metrics:专为Java客户端设计的内置度量系统
- 减少对外部库的依赖,避免传递依赖问题
- 专门针对Kafka客户端场景优化
指标公开方式
JMX接口
- 所有度量指标都通过JMX(Java Management Extensions)公开
- 可通过标准的JMX客户端(如JConsole、VisualVM)查看
- 指标路径组织为层次结构,例如: kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec
可插拔的报告系统
Kafka支持配置多种统计报告器,包括但不限于:
- JMX报告器(默认启用)
- CSV报告器(定期将指标写入CSV文件)
- Graphite报告器(推送到Graphite监控系统)
- Prometheus报告器(通过HTTP端点暴露指标)
关键监控指标示例
Broker端重要指标
-
消息吞吐量:
- MessagesInPerSec:入站消息速率
- MessagesOutPerSec:出站消息速率
-
请求处理:
- RequestHandlerAvgIdlePercent:请求处理线程空闲率
- ProduceRequestMetrics:生产请求延迟
-
副本同步:
- UnderReplicatedPartitions:未充分复制的分区数
- ReplicaFetcherMetrics:副本同步延迟
客户端重要指标
-
生产者指标:
- record-send-rate:记录发送速率
- request-latency-avg:请求平均延迟
-
消费者指标:
- records-consumed-rate:记录消费速率
- fetch-latency-avg:拉取请求延迟
监控集成实践
典型的监控集成步骤:
- 配置Kafka启用所需的报告器
- 设置报告间隔(通常30秒-1分钟)
- 将报告器连接到监控系统(如Prometheus、Datadog)
- 配置告警规则(如处理延迟超过阈值)
示例配置片段:
properties
# 启用JMX报告
metrics.reporters=jmx
# 配置Graphite报告器
metrics.reporters=com.example.graphite.GraphiteReporter
metrics.graphite.host=graphite.example.com
metrics.graphite.port=2003
metrics.graphite.prefix=kafka.prodJMX
shell
export KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=9999 \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false \
-Djava.rmi.server.hostname=${服务器的IP,尽量写IP,不要hostname或者域名}"接着我们启动Kafka:
shell
kafka-server-start.sh /opt/servers/kafka_2.12-2.7.2/config/server.propertiesJConsole
在本机上启动 jconsole 服务,我们运行如下指令:(本机要有JDK)  启动窗口如下图所示:
启动窗口如下图所示: 
我们输入Kafka的地址和端口:  连接成功之后页面如下图:
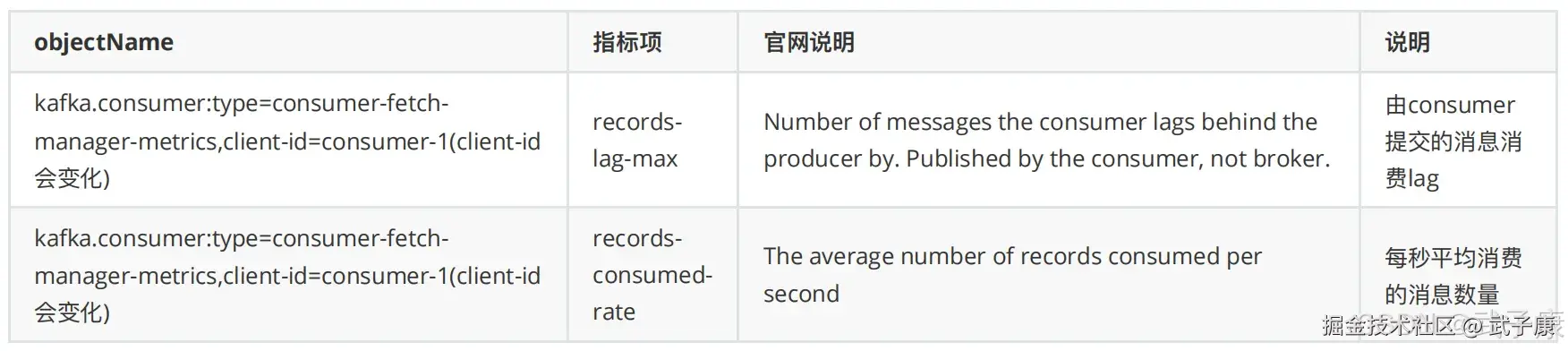
连接成功之后页面如下图: 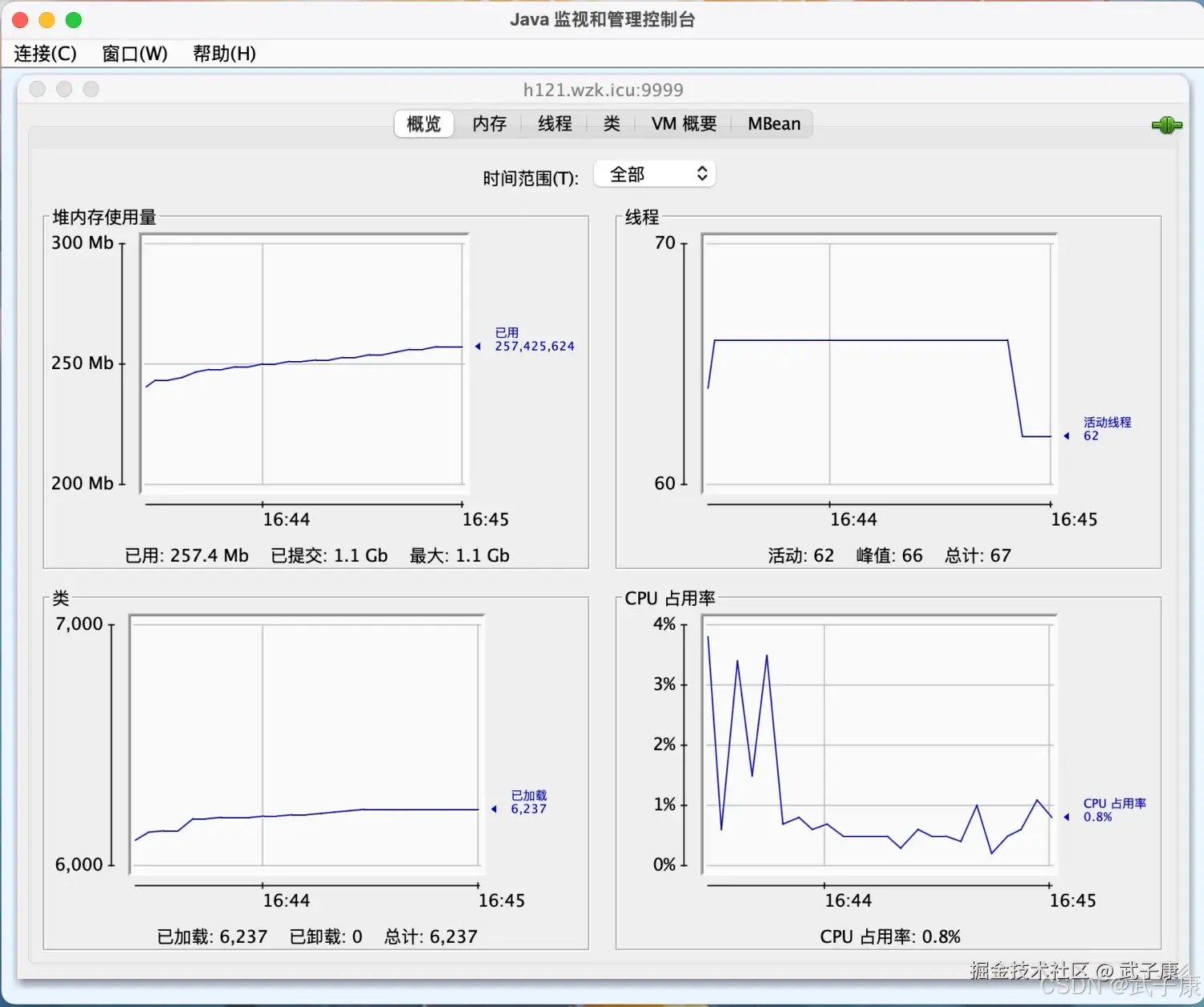 我们选择 MBean 选项卡:
我们选择 MBean 选项卡:  可以看到对应的数据情况:
可以看到对应的数据情况: 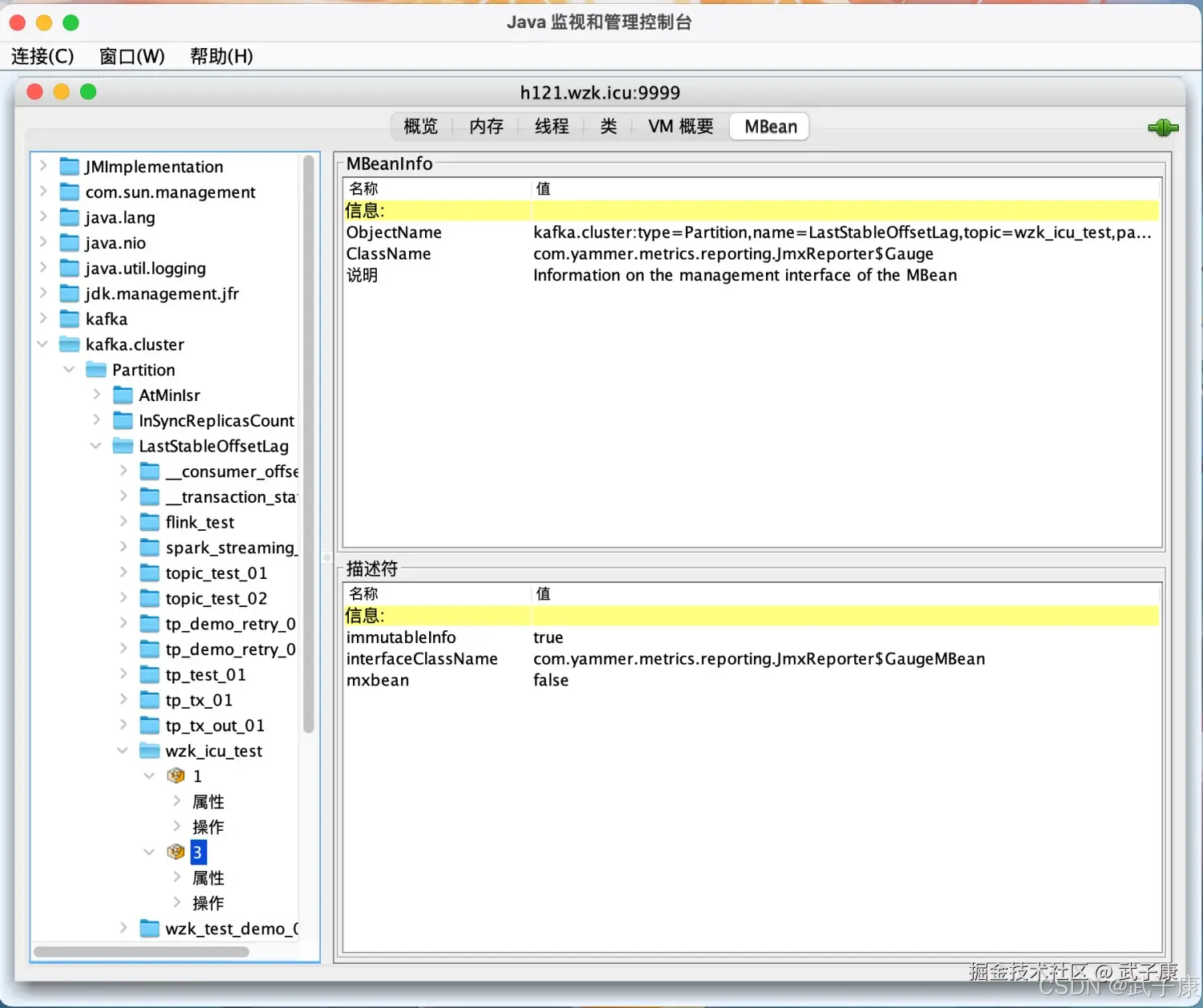
详细监控指标
kafka.apache.org/10/document...
OS监控项
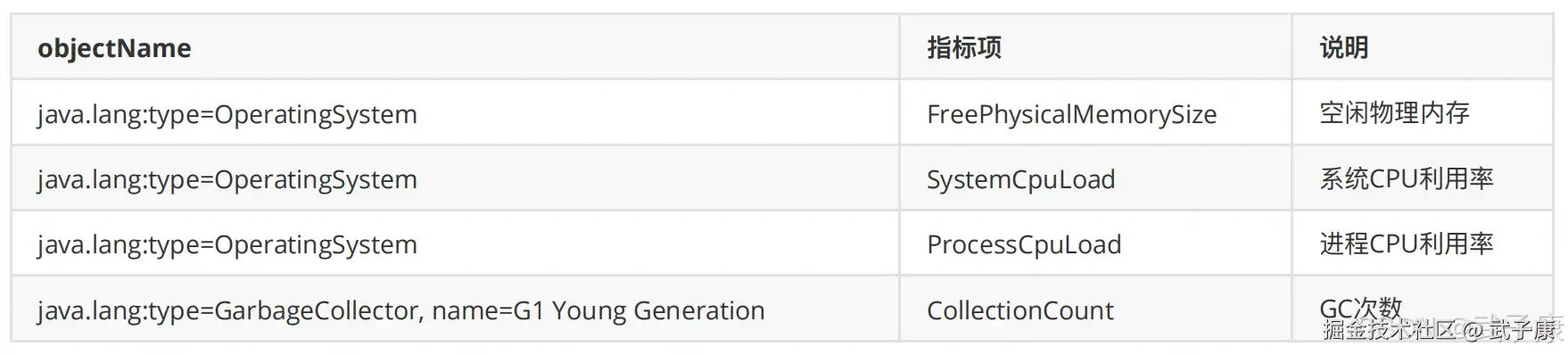
Broker指标
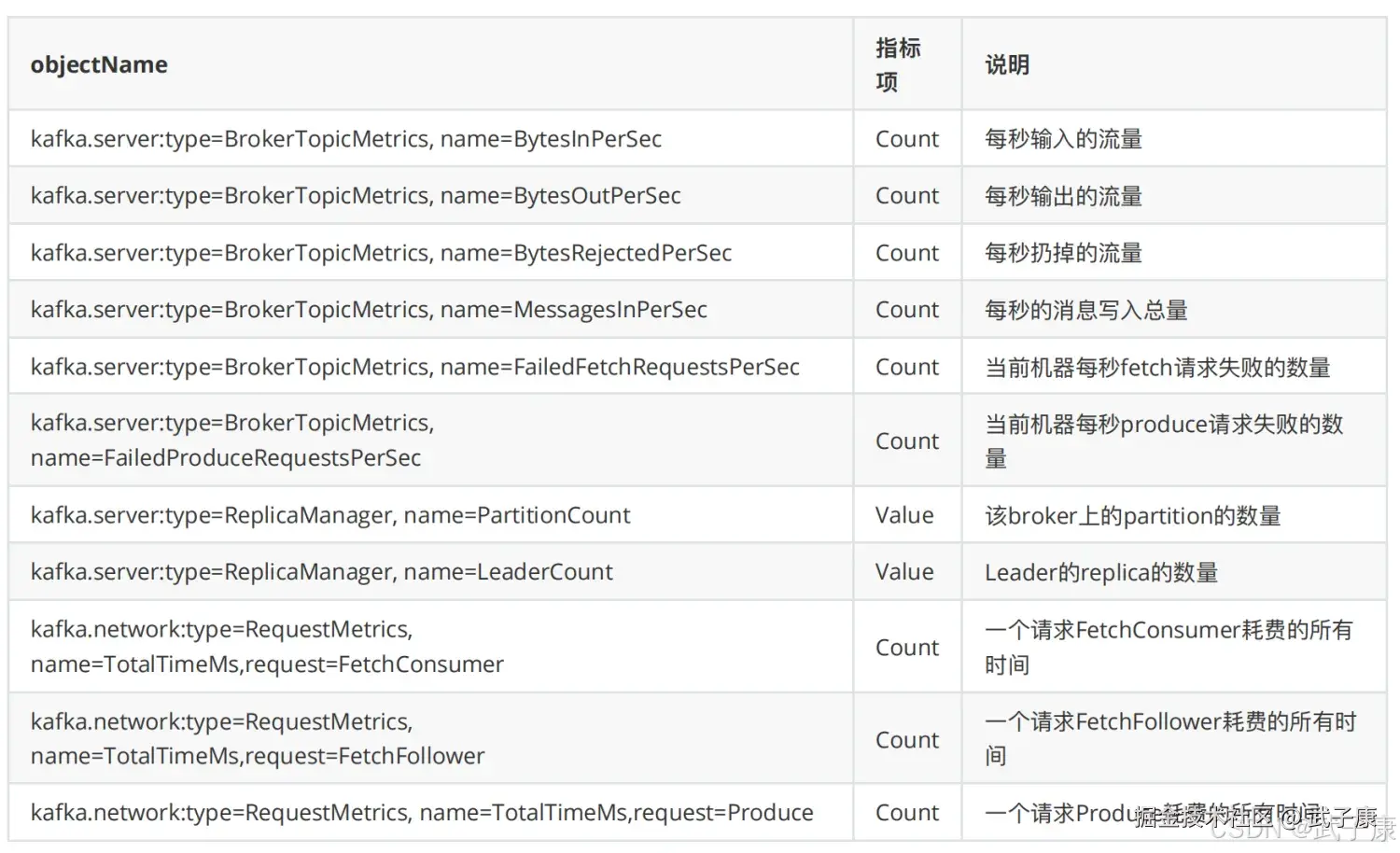
Producer和Topic指标
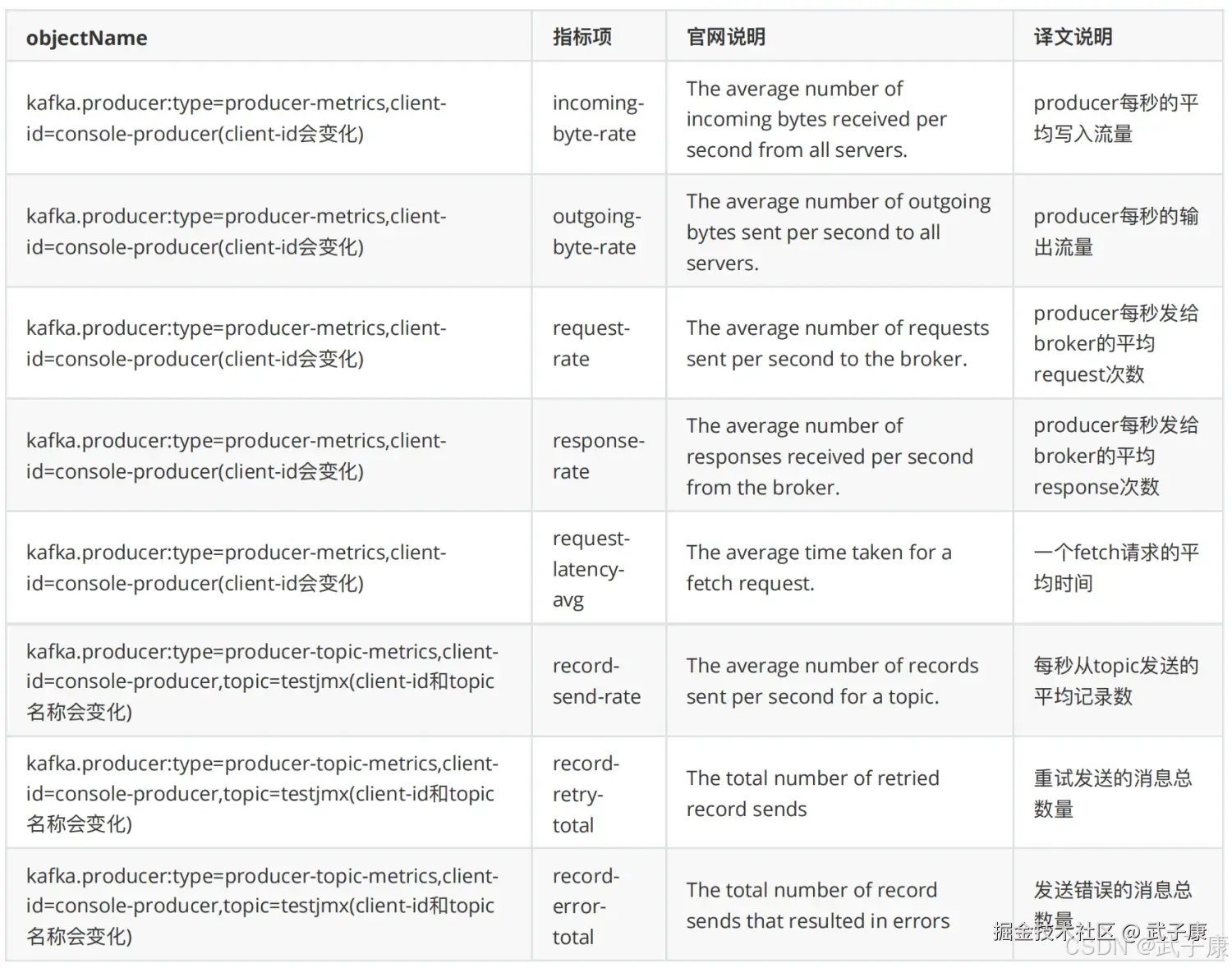
Consumer指标
获取监控指标
我们可以通过编程的方式来获取到Kafka的指标信息: 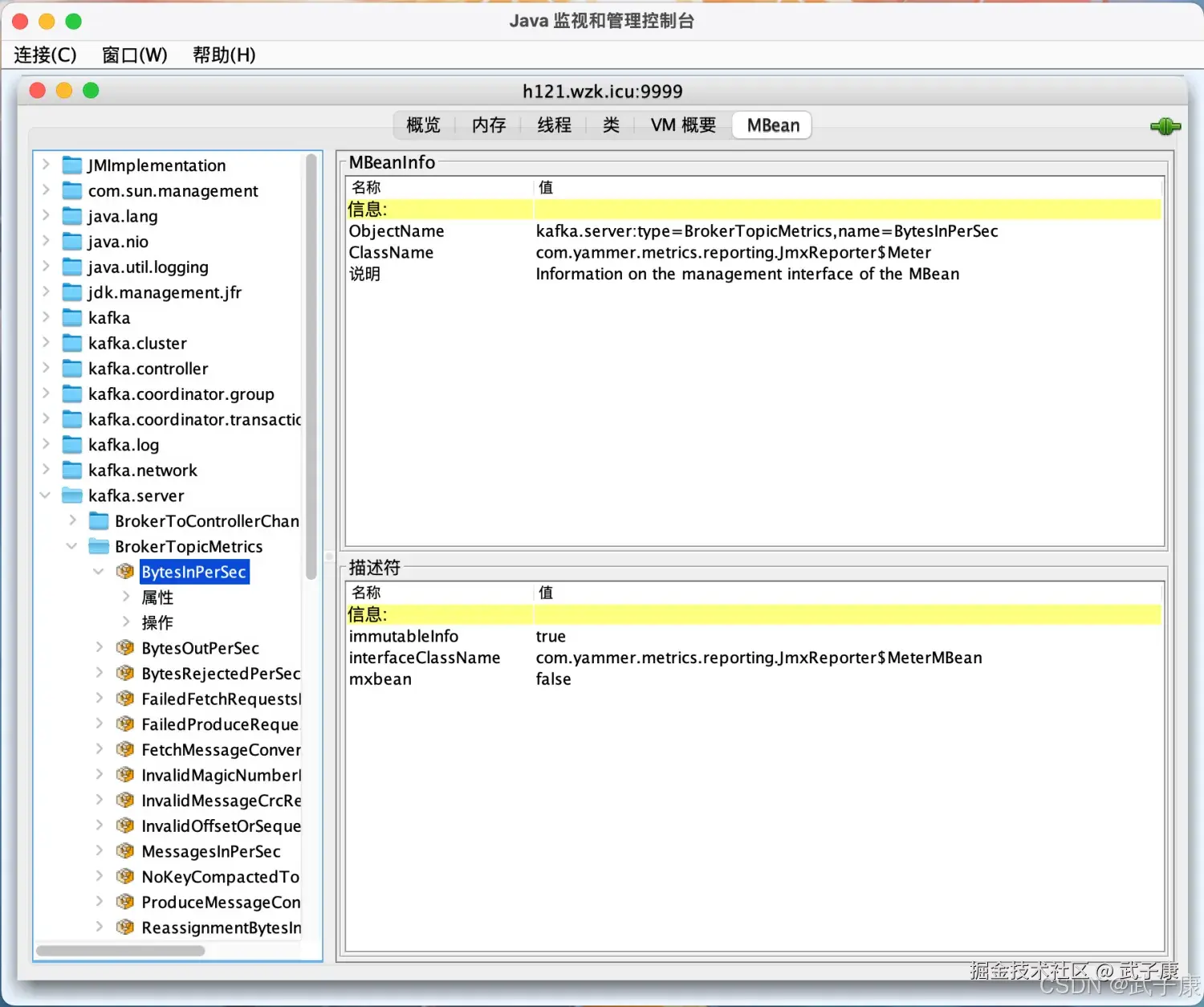
编写代码
java
public class JMXMonitorDemo {
public static void main(String[] args) throws Exception {
String jmxServiceUrl = "service:jmx:rmi:///jndi/rmi://h121.wzk.icu:9999/jmxrmi";
JMXServiceURL jmxUrl = null;
JMXConnector jmxc = null;
MBeanServerConnection jmxs = null;
ObjectName mbeanObjectName = null;
Iterator sampleIter = null;
Set sampleSet = null;
// 创建JMXServiceURL 对象
jmxUrl = new JMXServiceURL(jmxServiceUrl);
// 建立指定的URL服务器的连接
jmxc = JMXConnectorFactory.connect(jmxUrl);
// 返回代表远程MBean服务器的MBeanServiceConnection对象
jmxs = jmxc.getMBeanServerConnection();
// 根据传入的字符串,创建ObjectName对象
mbeanObjectName = new ObjectName("kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec");
// 指定ObjectName对应的MBeans
sampleSet = jmxs.queryMBeans(null, mbeanObjectName);
// 迭代器
sampleIter = sampleSet.iterator();
if (!sampleSet.isEmpty()) {
// 如果返回了 则打印信息
while (sampleIter.hasNext()) {
ObjectInstance sampleObject = (ObjectInstance) sampleIter.next();
ObjectName objectName = sampleObject.getObjectName();
// 查看指定MBean指定属性的值
String count = jmxs.getAttribute(objectName, "Count").toString();
System.out.println("count: " + count);
}
}
// 关闭
jmxc.close();
}
}运行测试
控制台输出结果如下: 
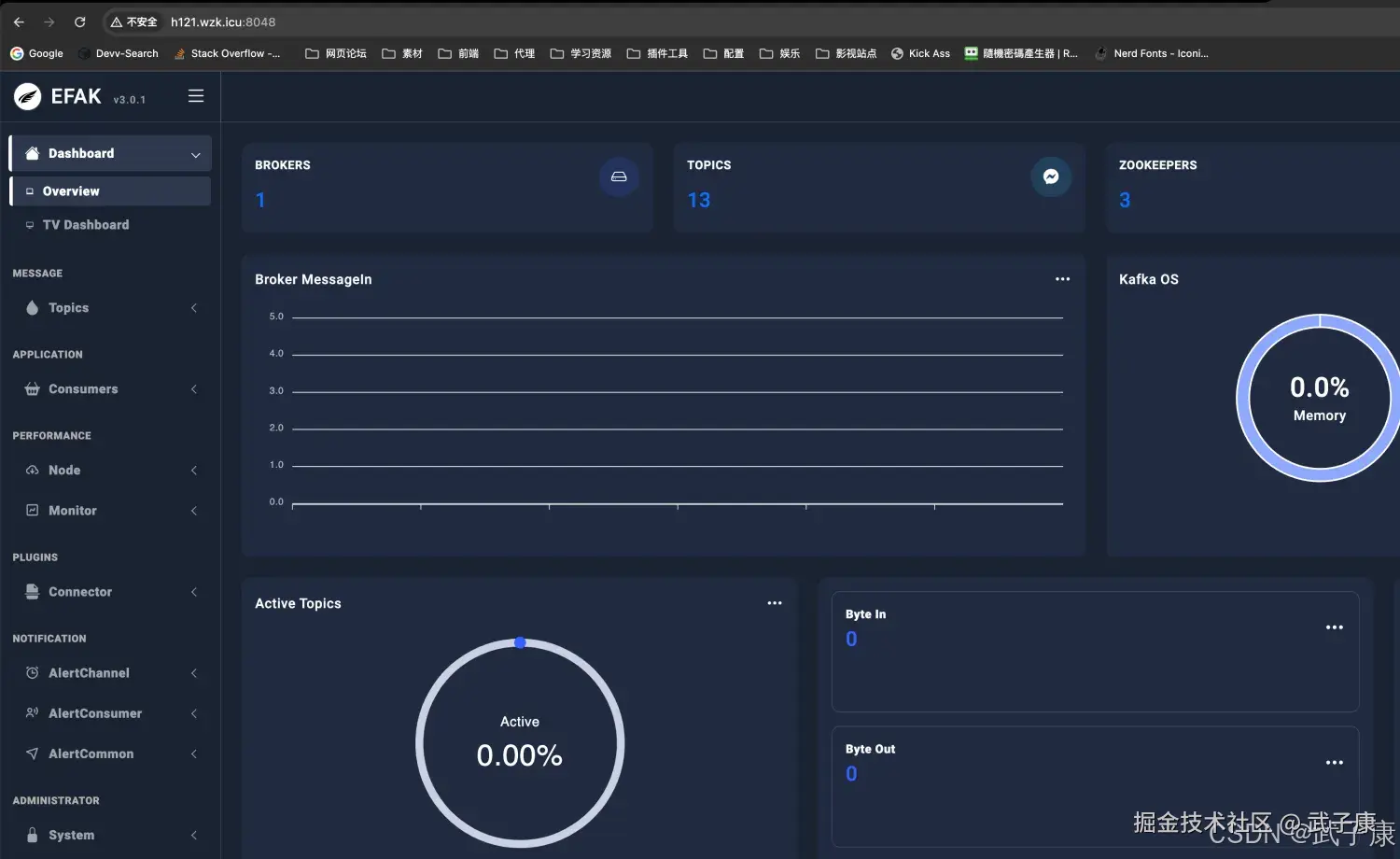
Kafka Eagle
我们可以使用 kafka-eagle 管理 Kafka集群。
核心模块
- 面板可视化
- 主题管理,包含创建主题、删除主题、主题列举、主题配置、主题查询
- 消费者应用:对不同消费者应用进行监控,包含KafkaAPI、FlinkAPI、SparkAPI、StormAPI、FlumeAPI、LogStashAPI等等
- 集群管理:包含对Kafka集群和ZooKeeper集群的详情展示,其内容包含Kafka启动时间、Kafka端口号、ZooKeeperLeader角色等。同时,还有多集群切换管理,ZooKeeperClient操作入口
- 集群监控:包含对Broker、Kafka核心指标、ZooKeeper核心指标进行监控,并绘制历史趋势图
- 告警功能:对消费者应用数据积压情况进行告警,以及对Kafka和ZooKeeper监控度进行告警,同时,支持邮件、微信、钉钉告警通知
- 系统管理:包含用户创建、用户角色分配、资源访问进行管理
整体架构
- 可视化:负责展示主题列表、集群健康、消费应用等
- 采集器:数据采集的来源包含ZooKeeper、Kafka JMX & 内部Topic、KafkaAPI(2.x以后版本)
- 数据存储:目前Kafka Eagle存储采用MySQL或SQLite,数据库和表的创建均是自动完成的,按照官方文档配置好即可,启动Kafka Eagle就会自动创建,用来存储元数据和监控数据
- 监控:负责见消费者应用消费情况,集群健康状态
- 告警:对监控到的异常进行告警通知,支持邮件、微信、钉钉等方式
- 权限管理:对访问用户进行权限管理,对于管理员、开发者、访问者等不同角色的用户,分配不用的访问权限
下载项目
shell
# Github 地址
# https://github.com/smartloli/EFAK
wget https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz
mv v3.0.1.tar.gz kafka-eagle-v3.0.1.tar.gz
tar -zxvf kafka-eagle-v3.0.1.tar.gz
cd kafka-eagle-bin-3.0.1/
tar -zxvf efak-web-3.0.1-bin.tar.gz
mv efak-web-3.0.1/ /opt/servers/下载过程如下图所示:  整理好的项目如下所示:
整理好的项目如下所示: 
配置项目
shell
cd /opt/servers/efak-web-3.0.1修改配置文件
shell
vim conf/system-config.properties文件按照自己的需要修改,我这里修改了部分:
shell
efak.zk.cluster.alias=cluster1
cluster1.zk.list=h121.wzk.icu:2181,h122.wzk.icu:2181,h123.wzk.icu:2181
######################################
# kafka sqlite jdbc driver address
######################################
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org
# 我注释掉了MySQL此时我们需要新建一个文件夹:
shell
mkdir -p /hadoop/kafka-eagle/db/环境变量
shell
vim /etc/profile
# efak
export KE_HOME=/opt/servers/efak-web-3.0.1
export PATH=$PATH:$KE_HOME/bin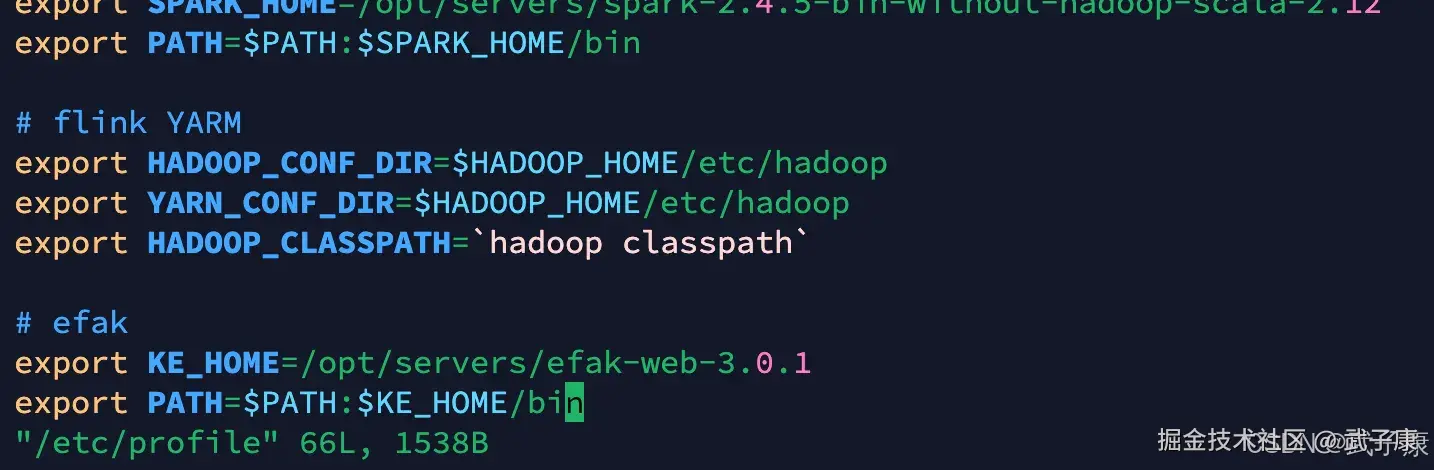
启动服务
shell
./bin/ke.sh start启动我们的服务,如下图所示: 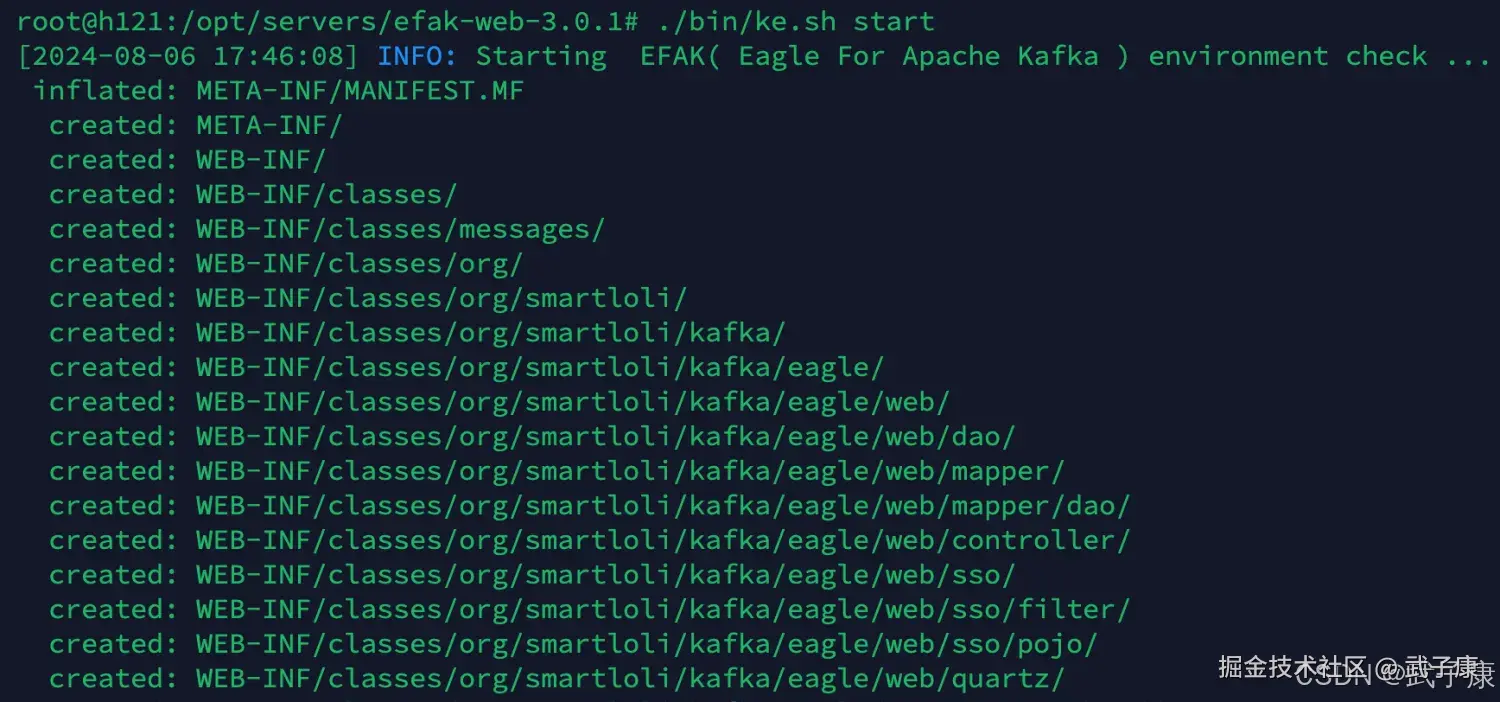
访问服务
shell
http://h121.wzk.icu:8048
admin
123456运行结果如下图所示: 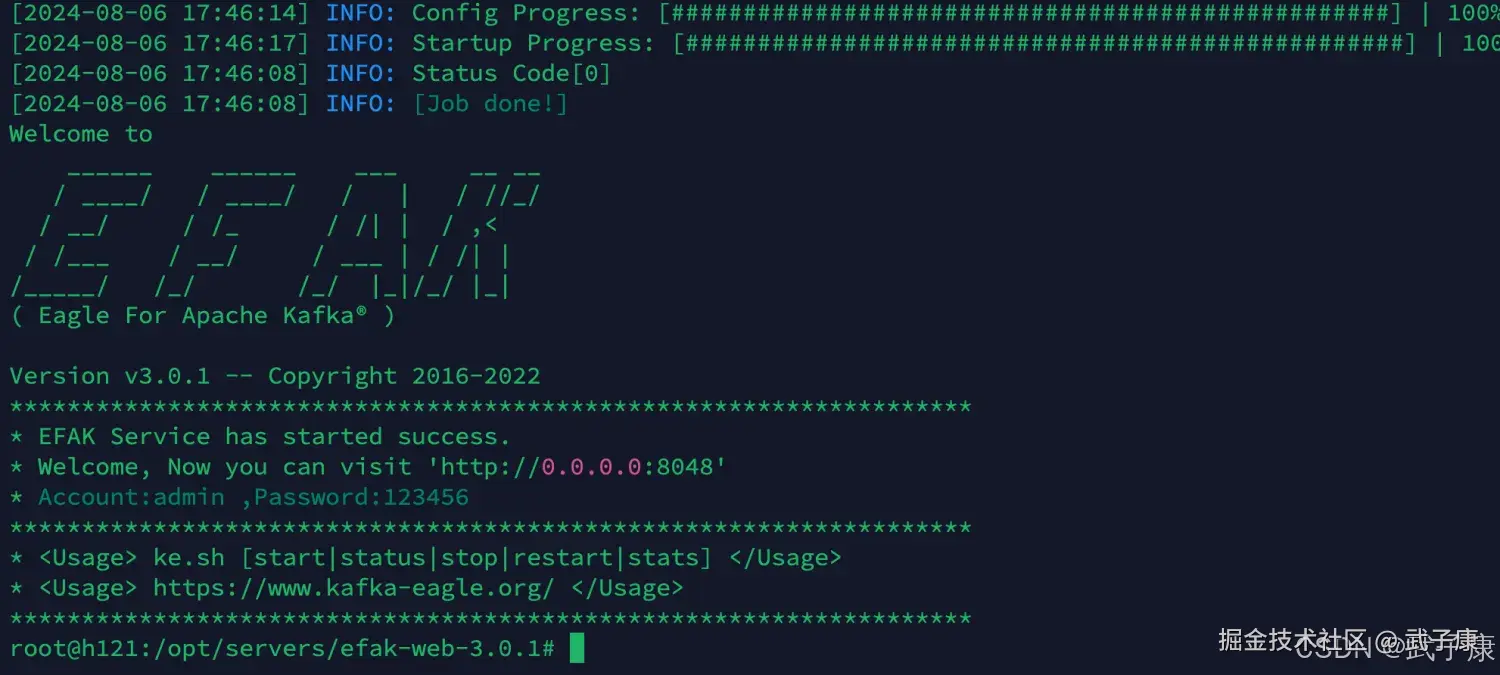 打开之后,填写账号密码:
打开之后,填写账号密码: