GraphRAG------v0.3.5版本
理论部分
安装
python
## 创建虚拟环境
conda create -n GraphRAG_0_3_6 python=3.11
# 激活虚拟环境
source activate GraphRAG_0_3_6
# 安装相关依赖包
# 我安装的版本是graphrag==0.3.5
pip install graphrag==0.3.5 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install future --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.112.0 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple uvicorn==0.30.6知识图谱生成
python
# 创建文件目录
mkdir -p ./ragtest/input
#下载测试txt文档
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt -o ./ragtest/input/book.txt
# 设置你的工作区变量
"""
要初始化你的工作区,首先运行 graphrag init 命令。由于我们在上一步已经配置了一个名为 ./ragtest 的目录,运行以下命令:
"""
# 初始化配置(首次)
python -m graphrag.index --init --root ./ragtest其会生成相关的文件如下所示:
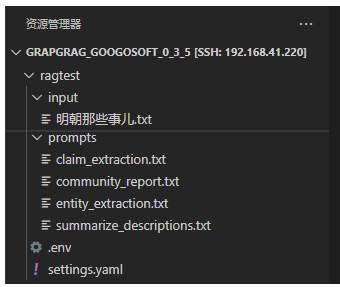
修改相关的配置文件settings.yaml,内容如下:
python
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # or azure_openai_chat
model: gpt-3.5-turbo
model_supports_json: true # recommended if this is available for your model.
# max_tokens: 4000
# request_timeout: 180.0
api_base: http://192.168.41.216:8082/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
concurrent_requests: 25 # the number of parallel inflight requests that may be made
# temperature: 0 # temperature for sampling
# top_p: 1 # top-p sampling
# n: 1 # Number of completions to generate
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: gpt-4
api_base: http://192.168.41.216:8080/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional
chunks:
size: 1200
overlap: 100
group_by_columns: [id] # by default, we don't allow chunks to cross documents
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # or blob
base_dir: "cache"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # or blob
base_dir: "output/${timestamp}/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # or console, blob
base_dir: "output/${timestamp}/reports"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 1
summarize_descriptions:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
enabled: true
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 1
community_reports:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: false # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: false
raw_entities: false
top_level_nodes: false
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
global_search:
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32注意:
python
claim_extraction:
enabled: true # 一定要将其改成true,否则不会生成create_final_covariates.parquet文件经过上述配置文件修改后
我在生成过程中,当所处理的文本较短时,可以正常生成如下所需文件
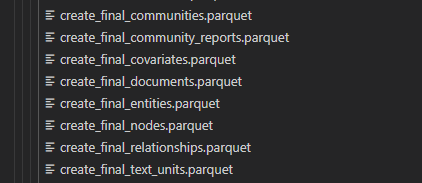
当时当文本文件较大时,create_final_community_reports.parquet文件会没有生成,解决的方案如下所示:
进入到以下目录下:
python
miniconda3/envs/GraphRAG_0_3_6/lib/python3.11/site-packages/graphrag/index/emit修改parquet_table_emitter.py 文件:
由:
python
# Copyright (c) 2024 Microsoft Corporation.
# Licensed under the MIT License
"""ParquetTableEmitter module."""
import logging
import traceback
import pandas as pd
from pyarrow.lib import ArrowInvalid, ArrowTypeError
from graphrag.index.storage import PipelineStorage
from graphrag.index.typing import ErrorHandlerFn
from .table_emitter import TableEmitter
log = logging.getLogger(__name__)
class ParquetTableEmitter(TableEmitter):
"""ParquetTableEmitter class."""
_storage: PipelineStorage
_on_error: ErrorHandlerFn
def __init__(
self,
storage: PipelineStorage,
on_error: ErrorHandlerFn,
):
"""Create a new Parquet Table Emitter."""
self._storage = storage
self._on_error = on_error
async def emit(self, name: str, data: pd.DataFrame) -> None:
"""Emit a dataframe to storage."""
filename = f"{name}.parquet"
log.info("emitting parquet table %s", filename)
try:
await self._storage.set(filename, data.to_parquet())
except ArrowTypeError as e:
log.exception("Error while emitting parquet table")
self._on_error(
e,
traceback.format_exc(),
None,
)
except ArrowInvalid as e:
log.exception("Error while emitting parquet table")
self._on_error(
e,
traceback.format_exc(),
None,
)改为如下:
python
# Copyright (c) 2024 Microsoft Corporation.
# Licensed under the MIT License
"""ParquetTableEmitter module."""
import logging,shutil
import traceback
import pandas as pd
from pyarrow.lib import ArrowInvalid, ArrowTypeError
from graphrag.index.storage import PipelineStorage
from graphrag.index.typing import ErrorHandlerFn
from .table_emitter import TableEmitter
log = logging.getLogger(__name__)
class ParquetTableEmitter(TableEmitter):
"""ParquetTableEmitter class."""
_storage: PipelineStorage
_on_error: ErrorHandlerFn
def __init__(
self,
storage: PipelineStorage,
on_error: ErrorHandlerFn,
):
"""Create a new Parquet Table Emitter."""
self._storage = storage
self._on_error = on_error
async def emit(self, name: str, data: pd.DataFrame) -> None:
"""Emit a dataframe to storage."""
filename = f"{name}.parquet"
log.info("emitting parquet table %s", filename)
try:
open('./buf.csv','w+',encoding='UTF-8')
data.to_csv('./buf.csv',encoding='UTF-8')
data=pd.read_csv('./buf.csv',encoding='UTF-8')
data['community']=data['community'].astype(str)
await self._storage.set(filename, data.to_parquet())
shutil.rmtree('./buf.csv')
except ArrowTypeError as e:
log.exception("Error while emitting parquet table")
self._on_error(
e,
traceback.format_exc(),
None,
)
except ArrowInvalid as e:
log.exception("Error while emitting parquet table")
self._on_error(
e,
traceback.format_exc(),
None,
)上述修改完毕后,在项目根目录下执行以下语句:
python
# 开始索引生成
python -m graphrag.index --root ./ragtest