文章目录
- 数据预处理
- 简单模型构建
-
-
- [步骤 1:模型初始化](#步骤 1:模型初始化)
- [步骤 2:词嵌入转换](#步骤 2:词嵌入转换)
- [步骤 3:双向 LSTM 特征提取](#步骤 3:双向 LSTM 特征提取)
- [步骤 4:分类输出](#步骤 4:分类输出)
- [步骤 5:模型测试](#步骤 5:模型测试)
- 完整代码
-
- 完整训练与评估
-
-
- 一、初始化模型、损失函数与优化器
- [二、训练循环(多轮 Epoch 迭代)](#二、训练循环(多轮 Epoch 迭代))
- 完整代码
-
- 模型评估与性能分析
- 情感分析推理(预测)脚本
-
-
-
- [1. 接收用户输入的评论](#1. 接收用户输入的评论)
- [2. 文本转索引](#2. 文本转索引)
- [3. 填充 / 截断:统一文本长度](#3. 填充 / 截断:统一文本长度)
- [4. 转换为 PyTorch 张量并调整维度](#4. 转换为 PyTorch 张量并调整维度)
- [5. 加载模型并进行预测](#5. 加载模型并进行预测)
- 完整代码
-
-
- [双分支特征融合的 LSTM 文本分类模型](#双分支特征融合的 LSTM 文本分类模型)
-
-
- 一、模型核心结构(__init__方法)
- [二、前向传播(forward 方法)](#二、前向传播(forward 方法))
- 完整代码
-
围绕酒店评论情感分析任务,从0构建了一套从数据预处理到模型训练、评估及实际应用的完整流程。
数据预处理
首先需要一个文本数据预处理,针对酒店评论数据(hotel_discuss2.csv)进行处理,最终生成可直接用于深度学习模型(如 RNN、CNN 等)训练的数据加载器。
一、导入依赖库
python
import numpy as np # 用于数值计算(主要处理数组)
import torch # PyTorch深度学习框架(处理张量、构建模型)
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from torch.utils.data import TensorDataset, DataLoader # PyTorch的数据加载工具这些库是数据预处理和模型训练的基础:numpy处理数组,torch处理张量和数据加载,sklearn辅助数据集划分。
二、定义路径和基础参数
注意自己的文件位置
python
data_path = '第三部分/data/hotel_discuss2.csv' # 原始文本数据路径(酒店评论)
dict_file = '第三部分/data/dict.txt' # 词表字典保存路径(字符→索引映射)
encoding_file = '第三部分/data/encoding.txt' # 文本转索引后的保存路径
# 筛选不需要的符号:处理时会过滤掉这些符号(这里只过滤句号"。")
filter_symbols = ["。"]
# 设备选择:优先使用GPU(cuda),没有则用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")三、构建词表字典(data_deal函数)
python
# 数据处理:核心是构建词表(字符→数字索引的映射)
def data_deal(data_path):
mydict = {}
# 特殊符号<PAD>:用于填充短文本,索引固定为0
mydict['<PAD>'] = 0
code = 1 # 从1开始分配索引(0留给<PAD>)
# 读取原始数据文件
with open(data_path, 'r', encoding='utf-8') as f:
# 遍历每一行文本
for line in f.readlines():
line = line.strip() # 移除首尾空白(如换行符、空格)
# 按字符遍历(这里是字符级分词,每个字符作为一个单位)
for word in line:
# 过滤掉不需要的符号(如"。")
if word in filter_symbols:
continue
# 遇到新字符时,分配一个唯一索引
if word not in mydict:
mydict[word] = code
code += 1 # 索引自增
# 特殊符号<UNK>:用于表示词表中未出现的字符(未知字符),索引为最后一个
mydict['<UNK>'] = code
return mydict # 返回构建好的词表
# 调用函数,基于原始数据构建词表
mydict = data_deal(data_path)将文本中所有出现过的字符(过滤掉指定符号后)映射为唯一的数字索引,方便后续将文本转为数字序列。
<PAD>:用于统一文本长度(短文本补 0);<UNK>:处理测试时遇到的未见过的字符(避免索引错误)。
四、文本转索引
运行一次后注释
python
with open(data_path, 'r', encoding='utf-8') as f:
with open(encoding_file, 'w', encoding='utf-8') as fw:
for line in f.readlines():
each_line = line.strip() # 移除首尾空白
label = each_line[0] # 假设每行第一个字符是标签(如"1"表示正面,"0"表示负面)
context = each_line[2:] # 假设标签后有一个分隔符(如空格),从索引2开始是文本内容
# 遍历文本内容的每个字符,转换为索引
for word in context:
if word in filter_symbols: # 过滤不需要的符号
continue
else:
# 写入当前字符的索引,用逗号分隔
fw.write(str(mydict[word]) + ',')
# 每行最后用制表符\t分隔索引序列和标签(1或0)
if label == '1':
fw.write('\t'+'1'+'\n')
else:
fw.write('\t'+'0'+'\n')
print('索引转换完成')核心作用:将原始文本(字符串)转为数字索引序列(如 "好"→5,"差"→3),并与标签绑定保存。
- 格式:
索引1,索引2,索引3,...\t标签(如5,3,7,...\t1); - 注释原因:可能已经执行过并生成了
encoding_file,无需重复执行。
五、词表长度统计
python
# 计算词表中包含的字符总数(包括<PAD>和<UNK>)
dict_len = len(mydict)后续构建模型的嵌入层(Embedding)时,需要用到词表长度作为参数(嵌入层输入维度 = 词表大小)。
六、填充数据(统一文本长度)
python
# 存储处理后的特征(索引序列)和标签
values = []
labels = []
max_lens = 256 # 统一后的文本长度(不足补0,超过截断)
# 读取之前生成的索引文件(encoding_file)
with open(encoding_file, 'r', encoding='utf-8') as f:
lines = f.readlines() # 读取所有行
for line in lines:
# 按制表符分割,得到索引序列(context)和标签(label)
context, label = line.strip().split('\t')
# 将索引序列(字符串,如"5,3,7")转换为整数列表
content = [int(i) for i in context.split(',') if i.isdigit()] # 过滤非数字(避免空字符)
# 填充:如果文本长度小于max_lens,用0(<PAD>)补全
for i in range(max_lens - len(content)):
content.append(0)
# 截断:如果文本长度大于max_lens,只保留前max_lens个索引
content = content[:max_lens]
# 加入列表
values.append(content) # 特征(索引序列)
labels.append(int(label)) # 标签(转为整数)
# 将列表转为numpy数组(便于后续划分数据集和转换为张量)
values = np.array(values, dtype=np.int64) # 特征数组(shape: [样本数, 256])
labels = np.array(labels, dtype=np.int64) # 标签数组(shape: [样本数])
# print(values.shape, labels.shape) # 可选:打印数组形状,验证是否正确核心作用:深度学习模型要求输入维度固定,因此需要将不同长度的文本调整为相同长度(256)。
- 短文本:用
<PAD>(索引 0)填充; - 长文本:截断为前 256 个字符;
- 最终得到规整的二维特征数组和一维标签数组。
七、划分训练集和测试集
python
# 划分训练集(80%)和测试集(20%)
x_train, x_test, y_train, y_test = train_test_split(
values, labels,
test_size=0.2, # 测试集占比20%
random_state=42, # 随机种子(固定后结果可复现)
stratify=labels # 按标签分布分层抽样(保证训练集和测试集的类别比例与原始数据一致)
)将数据分为两部分:
- 训练集(
x_train, y_train):用于模型学习参数; - 测试集(
x_test, y_test):用于评估模型泛化能力(未见过的数据上的表现)。
八、批量加载数据
python
# 将numpy数组转换为PyTorch张量(模型只能处理张量),并组合为数据集(特征+标签)
train_data = TensorDataset(torch.from_numpy(x_train), torch.from_numpy(y_train)) # 训练数据集
test_data = TensorDataset(torch.from_numpy(x_test), torch.from_numpy(y_test)) # 测试数据集
# 构建数据加载器(按批次加载数据,提高训练效率)
train_loader = DataLoader(
train_data,
batch_size=64, # 每个批次包含64个样本
shuffle=True # 训练时打乱样本顺序(避免模型学习到顺序规律)
)
test_loader = DataLoader(
test_data,
batch_size=32, # 测试时批次可小一些(不影响模型参数,仅评估)
shuffle=True # 测试时也打乱(非必须,但不影响结果)
)TensorDataset:将特征和标签绑定为一个数据集(方便按样本索引对应);DataLoader:按批次加载数据(避免一次性加载全部数据导致内存溢出),并支持打乱顺序(提升训练效果)。
完整代码
py
"""
数据预处理
标签文本分离
划分训练集和测试集
分词
词表字典
文本转索引
填充数据 统一大小
批量加载数据
结果:返回一个数据加载器 【批次,词数【索引形式】】
"""
import numpy as np
import torch
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset,DataLoader
data_path = '第三部分/data/hotel_discuss2.csv'
dict_file = '第三部分/data/dict.txt'
encoding_file = '第三部分/data/encoding.txt'
# 筛选不需要的符号
filter_symbols = ["。"]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据处理:核心是构建词表(字符→数字索引的映射)
def data_deal(data_path):
mydict = {}
# 特殊符号<PAD>:用于填充短文本,索引固定为0
mydict['<PAD>'] = 0
# 从1开始分配索引(0留给<PAD>)
code = 1
with open(data_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
line = line.strip() # 移除首尾空白(如换行符、空格)
for word in line:
if word in filter_symbols:
continue
if word not in mydict:
mydict[word] = code
code += 1
# 特殊符号<UNK>:用于表示词表中未出现的字符(未知字符),索引为最后一个
mydict['<UNK>'] = code
return mydict
mydict = data_deal(data_path)
# 将构建好的词表写入文件
# with open(dict_file, 'w', encoding='utf-8') as f:
# f.write(str(mydict))
# 文本转索引,保存到encoding_file
# with open(data_path, 'r', encoding='utf-8') as f:
# with open(encoding_file, 'w', encoding='utf-8') as fw:
# for line in f.readlines():
# each_line = line.strip()
# label = each_line[0] # 标签
# context = each_line[2:] # 文本内容
#
# for word in context:
# if word in filter_symbols:
# continue
# else:
# fw.write(str(mydict[word]) + ',')
# if label == '1':
# fw.write('\t'+'1'+'\n')
# else:
# fw.write('\t'+'0'+'\n')
# print('索引转换完成')
# 字典长度统计
dict_len = len(mydict)
# 填充:第一种 设一个最大的词数 第二种 max 找到最大的句子
values = []
labels = []
max_lens =256 # 统一后的文本长度(不足补0,超过截断)
with open(encoding_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
context , label = line.strip().split('\t')
content = [int(i) for i in context.split(',') if i.isdigit()]
# 填充:如果文本长度小于max_lens,用0(<PAD>)补全
for i in range(max_lens - len(content)):
content.append(0)
content = content[:max_lens]
values.append(content)
labels.append(int(label))
values = np.array(values, dtype=np.int64)
labels = np.array(labels, dtype=np.int64)
# print(values.shape, labels.shape)
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(values, labels, test_size=0.2, random_state=42, stratify=labels)
# 批量加载 数组转换张量
train_data = TensorDataset(torch.from_numpy(x_train), torch.from_numpy(y_train))
test_data = TensorDataset(torch.from_numpy(x_test), torch.from_numpy(y_test))
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=True)
if __name__ == '__main__':
for i, (x, y) in enumerate(train_loader):
print(x.shape, y.shape)
print(x, y)
break简单模型构建
步骤 1:模型初始化
python
import torch
from torch import nn
class Model(nn.Module):
def __init__(self, vacab_size, hidden_size=512, num_layers=1, num_classes=2):
# 1. 继承父类nn.Module的初始化方法(必须步骤,确保模型正常注册参数)
super(Model, self).__init__()
# 2. 保存关键参数(后续前向传播可能用到)
self.hidden_size = hidden_size # 隐藏层维度(同时也是词嵌入维度)
self.num_layers = num_layers # LSTM的层数
# 3. 词嵌入层:将"词语索引"转为"语义向量"(替代one-hot编码,避免维度爆炸)
# 输入维度:vacab_size(词表大小,即所有不同词语的总数)
# 输出维度:hidden_size(每个词语对应的向量维度,如128维)
self.embedding = nn.Embedding(vacab_size, hidden_size)
# 4. 双向LSTM层:捕捉文本的"双向上下文"(左→右 + 右→左)
# input_size=hidden_size:输入是词嵌入后的向量,维度与hidden_size一致
# hidden_size:LSTM每一层隐藏状态的维度
# num_layers:LSTM的层数(默认1层,复杂任务可增加)
# batch_first=True:输入/输出张量的第一维是"批次大小"(符合PyTorch数据习惯)
# bidirectional=True:启用双向模式,输出维度会翻倍(hidden_size*2)
self.lstm = nn.LSTM(
hidden_size,
hidden_size,
num_layers,
batch_first=True,
bidirectional=True
)
# 5. 全连接输出层:将LSTM的特征映射到"分类类别"
# 输入维度:hidden_size*2(双向LSTM的输出是两个方向的特征拼接)
# 输出维度:num_classes(分类任务的类别数,如2类情感分类)
self.fc = nn.Linear(hidden_size * 2, num_classes)步骤 2:词嵌入转换
python
def forward(self, x):
# x:输入的文本索引张量,形状为 [batch_size, seq_len]
# 例:x = torch.randint(0, 100, (64, 128)) → 64个样本,每个样本128个词的索引(词表大小100)
# 词嵌入层计算:将索引转为向量
# 输入:[64, 128](批次大小64,序列长度128)
# 输出:[64, 128, hidden_size](如hidden_size=128,则输出[64, 128, 128])
embed = self.embedding(x)步骤 3:双向 LSTM 特征提取
通过 "双向循环" 处理词嵌入向量序列,同时从 "左→右" 和 "右→左" 两个方向捕捉文本的上下文信息
python
def forward(self, x):
embed = self.embedding(x)
# 双向LSTM计算:处理词嵌入序列,提取上下文特征
# 输入:embed → [64, 128, 128]
# 输出1:output → [64, 128, hidden_size*2](如[64, 128, 256],双向特征拼接)
# 输出2:_ → 忽略LSTM的隐藏状态((h_n, c_n)),分类任务用不到
output, _ = self.lstm(embed)
# 序列特征聚合:将"每个词的特征"合并为"整个文本的全局特征"
# 用平均池化(torch.mean)在"序列长度维度(dim=1)"求平均
# 输入:output → [64, 128, 256]
# 输出:output → [64, 256](64个样本,每个样本1个256维全局特征)
output = torch.mean(output, dim=1)步骤 4:分类输出
将 LSTM 输出的 "全局特征向量" 映射到具体的分类类别,得到每个类别的 "预测得分"
python
def forward(self, x):
embed = self.embedding(x)
output, _ = self.lstm(embed)
output = torch.mean(output, dim=1)
# 全连接层计算:将全局特征映射到类别数
# 输入:output → [64, 256]
# 输出:output → [64, num_classes](如num_classes=2,则输出[64, 2])
# 每个位置的值代表"样本属于该类别的得分"(得分越高,置信度越高)
output = self.fc(output)
return output # 返回最终预测得分,用于后续计算损失和准确率步骤 5:模型测试
python
if __name__ == '__main__':
# 1. 实例化模型:词表大小100,隐藏层维度128(其他参数默认)
model = Model(vacab_size=100, hidden_size=128)
print(model) # 打印模型结构,查看各层是否正确
# 2. 构造测试输入:64个样本,每个样本128个词的索引(索引范围0-99,对应词表)
x = torch.randint(0, 100, (64, 128))
# 3. 模型前向传播:得到预测结果
output = model(x)
# 4. 打印输出形状:预期为[64, 2](64个样本,2个类别得分)
print(output.shape) # 实际输出:torch.Size([64, 2]),流程正确完整代码
py
import torch
from torch import nn
class Model(nn.Module):
def __init__(self, vacab_size, hidden_size=512, num_layers=1, num_classes=2):
super(Model, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 词嵌入层
self.embedding = nn.Embedding(vacab_size, hidden_size)
# 隐藏层
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
# 输出层
self.fc = nn.Linear(hidden_size * 2, num_classes)
def forward(self, x):
embed = self.embedding(x)
output, _ = self.lstm(embed)
output = torch.mean(output, dim=1)
output = self.fc(output)
return output
if __name__ == '__main__':
model = Model(vacab_size=100, hidden_size=128)
print(model)
x = torch.randint(0, 100, (64, 128))
output = model(x)
print(output.shape)完整训练与评估
一、初始化模型、损失函数与优化器
1. 初始化模型并指定计算设备
python
model = Model(vacab_size=dict_len).to(device)Model(vacab_size=dict_len):实例化自定义模型。vacab_size=dict_len是传给模型的参数(dict_len是之前统计的词表长度,用于模型的 "嵌入层"------ 将索引映射为向量,嵌入层输入维度必须等于词表大小);.to(device):将模型加载到指定设备(GPU/CPU)。如果device是cuda,模型会在 GPU 上运行(速度更快);如果是cpu,则在 CPU 上运行。
2. 定义损失函数(衡量模型预测与真实标签的差距)
python
loss_fn = nn.CrossEntropyLoss()nn.CrossEntropyLoss():交叉熵损失函数,专门用于多分类任务 (如文本分类中 "正面 / 负面 / 中性" 三类)。
原理:它会先对模型输出做Softmax(将输出转为概率分布),再计算与真实标签(独热编码格式)的交叉熵,值越小表示模型预测越准。
注意:如果是二分类任务,也可用nn.BCELoss()(需配合sigmoid输出),但这里用CrossEntropyLoss说明是多分类(或二分类的另一种实现方式)。
3. 定义优化器(更新模型参数以降低损失)
python
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001, weight_decay=0.01)torch.optim.AdamW:AdamW 优化器(Adam 的改进版,加入权重衰减,防止过拟合),是目前深度学习中最常用的优化器之一;model.parameters():表示优化器需要更新的 "模型参数"(如嵌入层的权重、卷积层的核参数等);lr=0.0001:学习率(控制参数更新的步长,太大易震荡不收敛,太小训练太慢,0.0001 是常见的合理值);weight_decay=0.01:权重衰减(L2 正则化的一种,给参数加一个 "惩罚项",避免参数过大导致过拟合)。
4. 初始化模型保存的判断阈值
python
loss_old = 100 # 保存文件的flag- 作用:记录 "历史最优测试损失",用于判断是否保存当前模型。初始值设为 100(远大于正常损失值),确保第一轮测试后一定会保存第一次模型。
二、训练循环(多轮 Epoch 迭代)
其中添加了tqdm进度条工具
bash
pip install tqdm
python
bpar = tqdm(train_loader, leave=True, position=0)train_loader:需要遍历的可迭代对象(这里是 PyTorch 的DataLoader,每次迭代返回一个批次的数据);leave=True:控制进度条在任务结束后是否保留。设为True时,训练完一个 epoch 后,该 epoch 的进度条会留在终端中,方便查看历史训练记录;若设为False,进度条会在任务结束后自动消失;position=0:指定进度条在终端中的显示位置(数值越小越靠上)。在你的代码中,训练和测试各有一个进度条,设为position=0可让进度条固定在终端第一行,避免多个进度条交叉显示导致混乱。
在进度条上实时显示关键指标(如当前 epoch、平均损失、准确率),这可以通过 tqdm 实例的 set_description() 方法实现:
py
bpar.set_description('train ==> Epoch: %d, Loss_avg: %.4f, Acc_avg: %.4f' % (epoch+1, loss_avg, acc_avg))训练部分完整代码:
python
for epoch in range(10): # 训练10轮(Epoch),每轮遍历一次完整的训练集
# 1. 初始化训练进度条
bpar = tqdm(train_loader, leave=True, position=0)
# - tqdm(train_loader):给训练数据加载器套上进度条,显示"当前批次/总批次、耗时、剩余时间"等;
# - leave=True:训练结束后进度条不消失(便于查看历史记录);
# - position=0:进度条固定在终端第一行(避免多进度条混乱)。
# 2. 设为训练模式
model.train()
# - 作用:开启模型的"训练专属行为",比如 dropout层随机丢弃神经元、batchnorm层更新均值和方差;
# - 注意:测试时必须用model.eval()关闭这些行为,否则会影响测试结果。
# 3. 初始化训练指标容器(记录每轮的总损失、总准确率,用于计算平均值)
loss_all = 0 # 总损失(累加每个批次的损失)
acc_all = 0 # 总准确率(累加每个批次的准确率)
loss_avg = 0 # 平均损失(总损失 / 批次数量)
acc_avg = 0 # 平均准确率(总准确率 / 批次数量)
# 4. 遍历训练集的每个批次(Batch)
for i, (x, y) in enumerate(bpar):
# 4.1 将当前批次的特征和标签加载到指定设备
x, y = x.to(device), y.to(device)
# - x:当前批次的文本索引序列(shape: [batch_size, max_lens],如[64, 256]);
# - y:当前批次的真实标签(shape: [batch_size],如[64]);
# - .to(device):确保数据和模型在同一设备(否则会报错)。
# 4.2 清空优化器的梯度(关键步骤,避免梯度累积)
optimizer.zero_grad()
# - 原理:PyTorch中梯度会默认累积(方便大批次拆分训练),但常规训练中每批次需重新计算梯度,所以必须先清空。
# 4.3 模型前向传播(输入数据,得到预测结果)
output = model(x)
# - model(x):将特征x输入模型,经过嵌入层、隐藏层等计算,输出预测结果output;
# - output的shape:[batch_size, num_classes](num_classes是分类任务的类别数,如2类情感分类则为2),每个值表示"样本属于该类的得分"(未经过概率转换)。
# 4.4 计算当前批次的损失
loss = loss_fn(output, y)
# - loss_fn(output, y):用交叉熵损失函数计算"模型预测(output)"与"真实标签(y)"的差距;
# - loss是一个标量张量(如tensor(0.65)),值越小表示当前批次预测越准。
# 4.5 反向传播(计算梯度)
loss.backward()
# - 原理:从损失值loss出发,反向推导每个模型参数(如权重)对损失的贡献(即梯度),梯度的方向表示"参数如何调整能降低损失"。
# 4.6 优化器更新模型参数(梯度下降)
optimizer.step()
# - 作用:根据反向传播得到的梯度,按优化器的规则(AdamW)更新模型的所有参数(如w = w - lr * 梯度),实现"降低损失"的目的。
# 4.7 累积损失和准确率,计算平均值
loss_all += loss.item() # 将损失张量转为Python数值,累加到总损失(避免张量占用显存)
loss_avg = loss_all / (i + 1) # 平均损失 = 总损失 / 已遍历的批次数量(i从0开始,所以+1)
# 计算当前批次的准确率
# - torch.argmax(output, dim=-1):对output按最后一维(类别维度)取最大值的索引,即"模型预测的类别"(如output为[0.2, 0.8],取索引1);
# - == y:比较预测类别与真实标签,得到布尔张量(如tensor([True, False, True]));
# - .float():将布尔张量转为浮点型(True→1.0,False→0.0);
# - torch.mean():计算平均值,即当前批次的准确率(如3个样本中2个正确,准确率为0.666);
acc = torch.mean((torch.argmax(output, dim=-1) == y).float())
acc_all += acc.item() # 累加准确率(转为Python数值)
acc_avg = acc_all / (i + 1) # 平均准确率 = 总准确率 / 已遍历的批次数量
# 4.8 更新进度条显示信息
bpar.set_description('train ==> Epoch: %d, Loss_avg: %.4f, Acc_avg: %.4f' % (epoch+1, loss_avg, acc_avg))
# - 作用:在进度条前显示当前训练轮次(epoch+1,因为epoch从0开始)、平均损失(保留4位小数)、平均准确率(保留4位小数);
bpar.refresh() # 强制刷新进度条,确保信息实时更新。
# 5. 每轮训练后,在测试集上验证模型效果(避免过拟合)
model.eval() # 设为评估模式
# - 作用:关闭训练专属行为(如dropout停止丢弃、batchnorm使用训练时的均值/方差,不再更新),确保测试结果稳定。
with torch.no_grad(): # 禁用梯度计算(节省显存,加速测试)
# 5.1 初始化测试进度条
test_bpar = tqdm(test_loader, leave=True, position=0)
# 5.2 初始化测试指标容器(逻辑和训练时一致)
loss_all = 0
acc_all = 0
loss_avg = 0
acc_avg = 0
# 5.3 遍历测试集的每个批次
for i, (x, y) in enumerate(test_bpar):
x, y = x.to(device), y.to(device) # 数据加载到指定设备
output = model(x) # 模型前向传播(预测)
loss = loss_fn(output, y) # 计算测试损失
# 累积测试损失和准确率,计算平均值(逻辑和训练时完全一致)
loss_all += loss.item()
loss_avg = loss_all / (i + 1)
acc = torch.mean((torch.argmax(output, dim=-1) == y).float())
acc_all += acc.item()
acc_avg = acc_all / (i + 1)
# 更新测试进度条信息
test_bpar.set_description('test ==> Epoch: %d, Loss_avg: %.4f, Acc_avg: %.4f' % (epoch + 1, loss_avg, acc_avg))
test_bpar.refresh()
# 6. 保存"测试损失更低"的最优模型
if loss_avg < loss_old:
torch.save(model.state_dict(), 'model.pth') # 保存模型的参数(而非整个模型,节省空间)
# - model.state_dict():获取模型的所有可训练参数(如权重、偏置);
# - 'model.pth':保存路径和文件名(.pth是PyTorch模型参数的常用后缀);
loss_old = loss_avg # 更新"历史最优损失",确保下一轮只有损失更低时才会覆盖保存完整代码
py
from torch import nn
import torch
from tqdm import tqdm
from model import Model
from data_deal import *
model = Model(vacab_size=dict_len).to(device)
# 损失函数 和 优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001, weight_decay=0.01)
# 初始值设为 100(远大于正常损失值),确保第一轮测试后一定会保存第一次模型。
loss_old = 100 # 保存文件的flag
for epoch in range(50):
bpar = tqdm(train_loader,leave=True,position=0)
'''
- tqdm(train_loader):给训练数据加载器套上进度条,显示"当前批次/总批次、耗时、剩余时间"等;
- leave=True:训练结束后进度条不消失(便于查看历史记录);
- position=0:进度条固定在终端第一行(避免多进度条混乱)。
'''
model.train()
loss_all = 0 # 总损失(累加每个批次的损失)
acc_all = 0 # 总准确率(累加每个批次的准确率)
loss_avg = 0 # 平均损失(总损失 / 批次数量)
acc_avg = 0 # 平均准确率(总准确率 / 批次数量)
for i, (x, y) in enumerate(bpar):
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = loss_fn(output, y)
loss.backward()
optimizer.step()
loss_all += loss.item()
loss_avg = loss_all / (i+1)
acc = torch.mean((torch.argmax(output, dim=-1) == y).float())
'''
torch.argmax(output, dim=-1):对output按最后一维(类别维度)取最大值的索引,即"模型预测的类别"(如output为[0.2, 0.8],取索引1);
== y:比较预测类别与真实标签,得到布尔张量(如tensor([True, False, True]));
.float():将布尔张量转为浮点型(True→1.0,False→0.0);
torch.mean():计算平均值,即当前批次的准确率(如3个样本中2个正确,准确率为0.666);
'''
acc_all += acc.item()
acc_avg = acc_all / (i+1) # 平均准确率 = 总准确率 / 已遍历的批次数量
# 进度显示
bpar.set_description('train ==> Epoch: %d, Loss_avg: %.4f, Acc_avg: %.4f' % (epoch+1, loss_avg, acc_avg))
bpar.refresh() # 强制刷新进度条,确保信息实时更新
# 测试
model.eval()
with torch.no_grad():
test_bpar = tqdm(test_loader, leave=True, position=0)
loss_all = 0
acc_all = 0
loss_avg = 0
acc_avg = 0
for i, (x, y) in enumerate(test_bpar):
x, y = x.to(device), y.to(device)
output = model(x)
loss = loss_fn(output, y)
loss_all += loss.item()
loss_avg = loss_all / (i + 1)
acc = torch.mean((torch.argmax(output, dim=-1) == y).float())
acc_all += acc.item()
acc_avg = acc_all / (i + 1)
# 进度显示
test_bpar.set_description('test ==> Epoch: %d, Loss_avg: %.4f, Acc_avg: %.4f' % (epoch + 1, loss_avg, acc_avg))
test_bpar.refresh()
if loss_avg < loss_old:
torch.save(model.state_dict(), 'model.pth')
loss_old = loss_avg模型评估与性能分析
一、初始化模型并加载训练好的参数
python
# 1. 实例化模型(与训练时的参数保持一致)
model = Model(vacab_size=dict_len).to(device)
# - 注意:`vacab_size=dict_len`必须与训练时相同(否则模型结构不匹配,无法加载参数);
# - `.to(device)`:将模型加载到指定设备(GPU/CPU),需与训练时的设备逻辑一致。
# 2. 加载训练好的模型参数
model.load_state_dict(torch.load('model.pth')) # 注意:原代码有笔误,应为load_state_dict
# - `torch.load('model.pth')`:从保存的文件中读取模型参数(字典形式,键为参数名,值为参数值);
# - `model.load_state_dict(...)`:将读取的参数加载到模型中,使模型拥有训练好的权重;
# - 作用:复用之前训练好的最优模型,避免重新训练。二、设置模型为评估模式并初始化存储容器
python
# 1. 设为评估模式(关闭训练时的特殊行为)
model.eval()
# - 与训练时的`model.eval()`作用一致:关闭dropout、固定batchnorm等,确保预测结果稳定。
# 2. 初始化两个列表,用于存储所有测试样本的真实标签和预测标签
y_label, y_pred = [], []
# - `y_label`:存储测试集中所有样本的真实标签(如情感分类中的"正面""负面");
# - `y_pred`:存储模型对所有测试样本的预测标签;
# - 用列表存储是因为测试集可能分多个批次加载,需要后续拼接成完整数组。三、在测试集上进行预测并收集结果
逐批次处理测试集,通过模型预测得到所有样本的预测标签,并与真实标签对应存储,为后续评估做准备。
python
with torch.no_grad(): # 禁用梯度计算(节省显存,加速预测)
# 初始化进度条(显示预测进度)
pbar = tqdm(test_loader, leave=True, position=0)
# 遍历测试集的每个批次
for i, (x, y) in enumerate(pbar):
# 1. 将当前批次的特征和真实标签加载到指定设备
x, y = x.to(device), y.to(device)
# - x:测试样本的特征(文本索引序列,shape: [batch_size, max_lens]);
# - y:测试样本的真实标签(shape: [batch_size])。
# 2. 模型前向传播,得到预测结果
output = model(x)
# - output:模型输出的"类别得分"(shape: [batch_size, num_classes]),每个值表示样本属于该类别的分数。
# 3. 收集真实标签:将张量转为numpy数组并加入列表
# - y.cpu().numpy():将设备上的张量(如GPU)转移到CPU,再转为numpy数组(方便后续拼接);
y_label.append(y.cpu().numpy())
# 4. 收集预测标签:取得分最高的类别作为预测结果
# - output.argmax(dim=1):在类别维度(dim=1)上取最大值的索引,即模型预测的类别(shape: [batch_size]);
# - .cpu().numpy():同样转移到CPU并转为numpy数组;
y_pred.append(output.argmax(dim=1).cpu().numpy())五、拼接结果并生成分类报告
分类报告指标说明:
precision(精确率):预测为某类的样本中,真正属于该类的比例(如预测为 "正面" 的样本中,85% 确实是正面);recall(召回率):所有真实属于某类的样本中,被正确预测的比例(如所有真实正面样本中,82% 被预测为正面);f1-score:精确率和召回率的调和平均(综合两者的指标,越接近 1 越好);support:该类别的真实样本数量;accuracy:总体准确率(所有样本中预测正确的比例);macro avg:各类别指标的算术平均(不考虑类别不平衡);weighted avg:按类别样本数量加权的平均(考虑类别不平衡)。
python
# 1. 拼接所有批次的结果,得到完整的标签数组
labels = np.concatenate(y_label) # 真实标签数组(shape: [总测试样本数])
preds = np.concatenate(y_pred) # 预测标签数组(shape: [总测试样本数])
# - 因为之前是按批次存储的(每个元素是一个批次的数组),用`np.concatenate`拼接成一维数组,方便计算指标。
# 2. 生成并打印分类报告
report = classification_report(labels, preds)
print(report)
# - `classification_report`: sklearn提供的工具,用于计算每个类别的精确率(precision)、召回率(recall)、F1分数(F1-score)等关键指标;
# - 输出内容示例(二分类场景):
# precision recall f1-score support
#
# 0 0.85 0.82 0.83 500
# 1 0.81 0.84 0.82 480
#
# accuracy 0.83 980
# macro avg 0.83 0.83 0.83 980
# weighted avg 0.83 0.83 0.83 980完整代码
py
import numpy as np
from sklearn.metrics import classification_report
from tqdm import tqdm
from model import Model
from data_deal import *
model = Model(vacab_size = dict_len).to(device)
y_label,y_pred = [],[]
model.load_state_dict(torch.load('model.pth'))
model.eval()
with torch.no_grad():
pbar = tqdm(test_loader,leave=True,position=0)
for i,(x,y) in enumerate(pbar):
x,y = x.to(device),y.to(device)
output = model(x)
y_label.append(y.cpu().numpy())
y_pred.append(output.argmax(dim=1).cpu().numpy())
# 拼接
labels = np.concatenate(y_label)
preds = np.concatenate(y_pred)
report = classification_report(labels,preds)
print(report)情感分析推理(预测)脚本
1. 接收用户输入的评论
python
def inference():
word = input("请输入评论:") 2. 文本转索引
模型只能处理数字,不能直接处理文字,因此需要用训练时构建的词表(mydict)将每个字符转换为对应的数字索引。例如,用户输入 "好差",可能转换为 [5, 6](假设 "好" 对应 5,"差" 对应 6)。
python
# 初始化一个列表,用于存储转换后的索引
in_seq = []
# 遍历用户输入的每个字符(按字符级处理,与训练时的分词方式保持一致)
for word in word:
# 检查字符是否在词表(mydict)中
if word in mydict:
# 如果存在,直接取对应的索引(如"好"→5)
in_seq.append(mydict[word])
else:
# 如果不存在(未在训练数据中出现过),用<UNK>的索引代替(处理未知字符)
in_seq.append(mydict['<UNK>'])3. 填充 / 截断:统一文本长度
模型训练时接收的输入是固定长度(256)的序列,推理时必须保持输入维度一致,否则会报错。
python
max_len = 256 # 固定长度(必须与训练时的max_lens一致,否则模型输入维度不匹配)
# 填充:如果文本长度小于max_len,用<PAD>的索引(0)补全
for i in range(max_len - len(in_seq)):
in_seq.append(mydict['<PAD>']) # mydict['<PAD>']的值为0
# 截断:如果文本长度大于max_len,只保留前max_len个索引
in_seq = in_seq[:max_len]4. 转换为 PyTorch 张量并调整维度
python
# 将列表转换为张量(PyTorch模型只能处理张量),并增加一个批次维度
in_seq = torch.tensor(in_seq).unsqueeze(0).to(device)torch.tensor(in_seq):将 Python 列表转换为 PyTorch 张量(shape:[256]);.unsqueeze(0):在第 0 维增加一个 "批次维度"(因为模型接收的输入格式是[batch_size, seq_len],这里单条数据的批次大小为 1,所以 shape 变为[1, 256]);.to(device):将张量加载到指定设备(GPU/CPU),需与模型所在设备一致。
5. 加载模型并进行预测
python
# 实例化模型(与训练时的结构和参数一致)
model = Model(vacab_size=dict_len).to(device)
# 加载训练好的模型参数(确保使用的是最优模型)
model.load_state_dict(torch.load('model.pth'))
# 设置为评估模式(关闭dropout等训练时的特殊行为)
model.eval()
# 确保模型在正确的设备上(冗余操作,保险起见)
model.to(device)
# 禁用梯度计算(节省显存,加速推理)
with torch.no_grad():
# 定义情感标签映射(0→差评,1→好评,与训练时的标签定义一致)
flag = ["差评", "好评"]
# 模型前向传播:输入处理好的张量,得到预测结果
output = model(in_seq)
# 取预测结果中概率最高的类别索引(0或1)
index = torch.argmax(output, dim=-1)
# 输出最终结果:根据索引映射到"好评"或"差评"
print("当前用户评价为:", flag[index.item()])完整代码
py
"""
情感分析任务:
用户输入评论
模型生成回复
"""
import torch
from model import Model
from data_deal import *
def inference():
words = input('请输入评论:')
# 文本转索引
in_seq = []
for word in words:
if word in mydict:
in_seq.append(mydict[word])
else:
in_seq.append(mydict['<UNK>'])
max_len = 256
# 填充
for i in range(max_len - len(in_seq)):
in_seq.append(mydict['<PAD>'])
in_seq = in_seq[:max_len]
# 升维度
in_seq = torch.tensor(in_seq).unsqueeze(0).to(device)
model = Model(vacab_size=len(mydict)).to(device)
model.load_state_dict(torch.load('model.pth'))
model.eval()
model.to(device)
with torch.no_grad():
flag = ['差评', '好评']
output = model(in_seq)
index = torch.argmax(output, dim=-1)
print("当前用户评价为:", flag[index.item()])
if __name__ == '__main__':
while True:
if input("输入q退出:") == "q":
break
else:
inference()完成以上内容后,我们可以试着将model模型优化一下,训练后的结果准确率会更高
双分支特征融合的 LSTM 文本分类模型
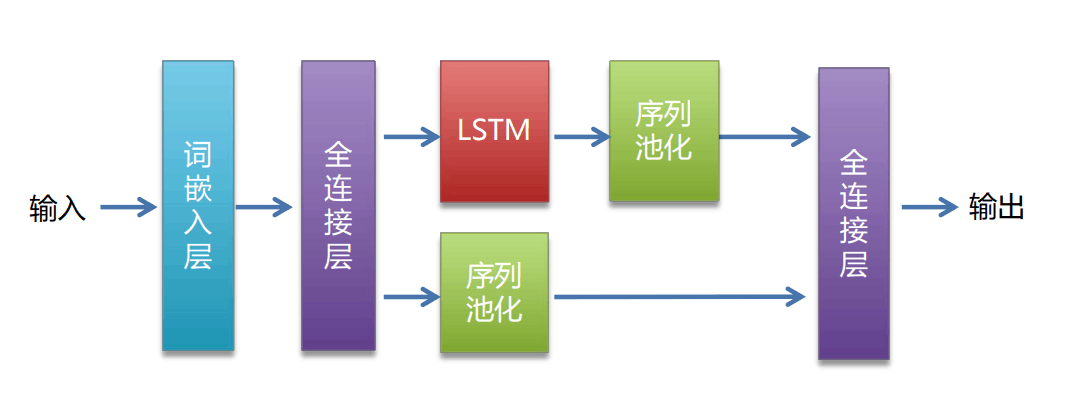
一、模型核心结构(__init__方法)
模型采用 "词嵌入→特征变换→双分支特征提取→融合分类" 的流程,各组件功能如下:
| 组件 | 具体实现 | 核心作用 |
|---|---|---|
| 词嵌入层 | nn.Embedding(input_size, hidden_size) |
将输入的词索引(形状[batch_size, seq_len])映射为连续向量([batch_size, seq_len, hidden_size]),将离散文本转为稠密特征。 |
| 特征变换 MLP | mlp1(2 层线性层 + GELU+Dropout) |
对词嵌入向量进行非线性变换,增强特征表达能力(输入hidden_size→中间2*hidden_size→输出hidden_size)。 |
| 分支 1(LSTM 路径) | lstm(2 层双向 LSTM) + avg1(自适应平均池化) |
捕捉文本的时序依赖关系(LSTM 擅长处理序列信息),再通过池化压缩序列维度,得到时序特征。 |
| 分支 2(直接池化路径) | avg2(自适应平均池化) |
直接对变换后的词特征进行池化,捕捉文本的全局静态特征(不依赖时序关系)。 |
| 融合与分类 MLP | mlp2(线性层 + GELU+LayerNorm + 输出层) |
融合双分支特征,最终输出分类结果(维度为output_size,如 2 分类情感分析)。 |
py
def __init__(self, input_size=512, hidden_size=512, output_size=2):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.input_size = input_size
# 词嵌入
# 重点:input_size是词表的大小 hidden_size 词嵌入之后的大小
self.embedding = nn.Embedding(input_size, hidden_size)
# 多层感知机mlp
self.mlp1 = nn.Sequential(
nn.Linear(hidden_size, hidden_size*2),
nn.GELU(),
nn.Linear(hidden_size*2, hidden_size),
nn.GELU(),
# 丢弃 为了防止过拟合
nn.Dropout(0.2),
)
# 第一个分支
self.lstm = nn.LSTM(hidden_size, hidden_size, batch_first=True, dropout=0.2, num_layers=2)
self.avg1 = nn.AdaptiveAvgPool1d(1)
# 第二个分支
self.avg2 = nn.AdaptiveAvgPool1d(1)
# 输出层
self.mlp2 = nn.Sequential(
nn.Linear(hidden_size*2, hidden_size),
nn.GELU(),
nn.LayerNorm(hidden_size),
nn.Linear(hidden_size, output_size),
)- 分支 1(LSTM + 池化):通过 LSTM 捕捉文本中的时序关系
- 分支 2(直接池化):直接对词特征求平均,捕捉文本的全局主题特征(如 "好""棒" 等正向词的整体占比);
- 融合方式:将两个分支的特征在最后一维拼接(
torch.cat((avg1, avg2), dim=-1)),结合时序特征和全局特征,提升分类鲁棒性。
二、前向传播(forward 方法)
py
def forward(self, x,lengths):
"""
:param x: 二维数据 【批次,词数】
:return: 【批次,分类类别数】
"""
embed = self.embedding(x)
linear1 = self.mlp1(embed)
# 第一个分支
# 打包 目的取非填充部分数据 减少计算量
# 将填充序列打包
packed_embedded = pack_padded_sequence(linear1, lengths, batch_first=True, enforce_sorted=False)
lstm_out, _ = self.lstm(packed_embedded)
# 打包 还原成原本的数据
lstm_out = pad_packed_sequence(lstm_out, batch_first=True)[0]
# print(lstm_out.shape)
avg1 = self.avg1(lstm_out.permute(0, 2, 1)).squeeze(-1)
# 第二个分支
avg2 = self.avg2(linear1.permute(0, 2, 1)).squeeze(-1)
# 融合
out = torch.cat((avg1, avg2), dim=-1)
# 输出层
output = self.mlp2(out)
return output以输入x(形状[batch_size, seq_len],如[64, 256])和lengths(每个样本的实际长度,如[120, 80, ..., 200])为例,数据流向和形状变化如下:
-
词嵌入与特征变换
embed = self.embedding(x):词索引→词向量,形状[64, 256, 512](hidden_size=512);linear1 = self.mlp1(embed):MLP 特征变换,形状保持[64, 256, 512]。
-
分支 1(LSTM 路径)
-
packed_embedded = pack_padded_sequence(linear1, lengths, ...):将已填充(padded)的变长序列 压缩成一个PackedSequence对象,让 LSTM/GRU 只处理有效序列部分(跳过填充值),节省计算和显存。lengths需降序 :PyTorch 要求传入的lengths是降序排列的(即最长序列在前,最短在后),否则会报错。如果你的数据不是降序,需要先排序 + 记录索引,处理完再恢复顺序。batch_first:如果你的input是[batch, seq, feature]格式(NLP 常用),必须设为True;否则 PyTorch 默认是[seq, batch, feature]
-
lstm_out, _ = self.lstm(packed_embedded):LSTM 处理有效序列,输出时序特征; -
lstm_out = pad_packed_sequence(...):将PackedSequence(压缩后的序列)恢复成填充后的常规张量 (Tensor),方便后续操作(如池化、全连接层)。padded_seq:恢复后的填充序列,形状回到[batch_size, max_seq_len, feature_dim]。new_lengths:恢复后的各样本真实长度(通常和输入lengths一致,除非指定了total_length截断 / 补长)。
avg1 = self.avg1(lstm_out.permute(0,2,1)).squeeze(-1)permute(0,2,1):调整维度为[64, 512, 256](适应池化层输入格式[batch, feature, seq_len]);- 自适应平均池化(
AdaptiveAvgPool1d(1)):将序列长度压缩为 1,形状[64, 512, 1]; squeeze(-1):去除最后一维,得到[64, 512]。
-
-
分支 2(直接池化路径)
avg2 = self.avg2(linear1.permute(0,2,1)).squeeze(-1)- 直接对
linear1(未经过 LSTM)进行池化,流程同分支 1,输出形状[64, 512]。
- 直接对
-
融合与分类
out = torch.cat((avg1, avg2), dim=-1):拼接双分支特征,形状[64, 1024](512*2);output = self.mlp2(out):经 MLP 处理后输出分类结果,形状[64, 2](output_size=2)。
完整代码
py
import torch.nn as nn
import torch
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class SentimentAnalysisModel(nn.Module):
def __init__(self, input_size=512, hidden_size=512, output_size=2):
'''
:param input_size: 词表有 512 个不同词汇
:param hidden_size:嵌入后词向量维度(如 512,将离散词索引转为连续向量)
:param output_size: 默认分类类别数(如 2 表示二分类,对应 "好评 / 差评")
'''
super(SentimentAnalysisModel, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.out_size = output_size
# 词嵌入层
# input
self.embed = nn.Embedding(input_size, hidden_size)
'''
第一层线性层将维度从hidden_size扩展到hidden_size*2,目的是让模型有更多参数来学习更复杂的特征表示
第二层再压缩回hidden_size,相当于做了一次特征变换和信息筛选,增强模型的非线性表达能力
'''
self.mlp1 = nn.Sequential(
nn.Linear(hidden_size, hidden_size*2),
nn.GELU(),
nn.Linear(hidden_size*2, hidden_size),
nn.GELU(),
# 丢弃 为了防止过拟
nn.Dropout(0.2)
)
# 第一个分支
self.lstm = nn.LSTM(hidden_size, hidden_size, batch_first=True,dropout=0.2, num_layers=2)
self.avg1 = nn.AdaptiveAvgPool1d(1) #无论输入序列长度多少,都输出长度为 1 的结果
# 第二个分支
self.avg2 = nn.AdaptiveAvgPool1d(1)
# 输出层
self.mlp2 = nn.Sequential(
# 线性层:输入2*hidden_size维(双分支拼接)→输出hidden_size维
nn.Linear(hidden_size * 2, hidden_size),
nn.GELU(),
nn.LayerNorm(hidden_size), # 层归一化:对特征做标准化,稳定训练过程
nn.Linear(hidden_size, output_size),
)
def forward(self, x,lengths):
'''
lengths:每个样本的 "实际长度"
(如某样本填充后长度 256,实际有效长度 100),用于处理变长序列。
'''
embed = self.embed(x)
linear1 = self.mlp1(embed)
#第一个分支
'''
打包:
pack_padded_sequence:将 "填充后的序列" 压缩成PackedSequence对象,只保留 "有效序列部分"(跳过填充的 0);
linear1:输入的填充序列([batch_size, seq_len, hidden_size])
lengths:每个序列的真实长度
batch_first=True:表示输入的第一维是批次(batch),而非序列长度
enforce_sorted=False:允许 lengths 不按降序排列(若为 True,需保证序列按长度从长到短排序)
'''
packed = pack_padded_sequence(linear1, lengths, batch_first=True,enforce_sorted=False)
lstm_out, (h_n, c_n) = self.lstm(packed)
#用 pad_packed_sequence 还原成填充序列格式
#[0]:取返回值的第一个元素(还原后的张量),第二个元素是各样本的实际长度(这里用不到)
lstm_out = pad_packed_sequence(lstm_out, batch_first=True)[0]
avg1 = self.avg1(lstm_out.permute(0,2,1)).squeeze(-1)
# 第二个分支
avg2 = self.avg2(embed.permute(0,2,1)).squeeze(-1)
# 拼接
out = torch.cat([avg1,avg2],dim=-1)
# 输出
output = self.mlp2(out)
return output若想在模型评估以及推理中使用双支LSTM模板需要格外注意:
在传参时需要传入x,lengths
#计算批次中每个文本的真实有效长度
lengths = torch.sum(x != 0, dim=-1).cpu().long()
output = model(x, lengths)