项目初期的审核机制
在之前公司的时候,我被调到另外一个项目组,负责一个刚上线的社交项目。 在熟悉项目、体验功能的过程中,我发现了一个比较严重的问题:项目里的朋友圈功能体验非常差。
当时我随手发一条动态,竟然要等 好几分钟 才能展示出来。 对于社交类产品来说,这几乎是致命的。做过产品的都知道,圈子/动态是用户活跃度的核心指标,这种体验会大大降低用户的留存。
我去找老板聊了下,才知道问题出在审核机制上:
- 项目刚上线时,只有 2 个客服负责所有审核,包括头像、昵称、朋友圈动态等。
- 审核时间只到下班,晚上没人审核。
- 但偏偏,晚上才是用户最活跃的时间段。
很显然,这样的体验非常不友好。 于是我提了一个改进方案:引入轮班制。
- 每班 2 个客服,同时负责审核头像、昵称、圈子内容;
- 一班从早上到下午;
- 另一班从下午到晚上 12 点,并且允许居家审核。
轮班制上线后,朋友圈的审核延迟问题明显改善,用户体验提升非常大。
用户量暴增后的新问题
随着老板不要命地烧钱买量、打广告,用户就像潮水一样涌进来。 朋友圈的发布量、评论量、私信量一夜之间翻了几倍,审核压力瞬间爆表。
虽然我们已经在轮班制的基础上 加派了客服人手 ,但依旧完全跟不上节奏。 总不能要求客服 "1 秒 10 审核" ,这显然不太现实。
更麻烦的是,随着监管越来越严格,我们不得不接入机器审核。于是上线了数美天网的机审服务,但很快就踩了坑:
- 成本高得吓人 ------ 每一条内容调用机审都要钱,用户量一上来,费用飙得飞快。
- 误判不少 ------ 正常的内容也会被误伤。比如"恐龙"被判成涉恐,"黄子韬"被判成涉黄,用户投诉直接爆。
- 不减反增 ------ 本来机审是为了减轻人工压力,结果误判太多,反而让客服需要二次处理,工作量不降反升。
老板看到账单后直接拍板:
"成本太高了,必须给我想办法降下来!"
我们也去和合作方谈,希望拿到点大客户折扣。结果对方很淡定:
"能便宜点,但差不多就这样了。"
至于误判问题,对方轻描淡写地说:"你们多调调模型阈值就行。"
但我们都懂,这根本不是一时半会能解决的。
于是我们就陷入了一个死循环:
- 全靠机审 → 成本爆炸,还带来一堆客诉;
- 全靠人工 → 人手不够,效率跟不上;
- 审核标准 → 又不可能降低,毕竟监管要求越来越严。
老板又不愿意加客服,只剩下一条路:
用技术来破局,既要省钱,又要保证体验和准确性。
所以我们只能从 技术手段 上想办法: 既要降低机审调用量,节省成本, 又要保证用户体验和敏感词拦截的准确性。
梳理最终的核心目标
前面聊到的几个问题,其实归结起来就是:
- 人工审核不够用
- 机审成本太高
- 误判导致客诉增加,客服还要二次处理
- 老板要求降本增效,但不能影响用户体验
基于这些现状,我们重新审视了整个内容审核体系,最终梳理出以下几个核心目标:
- 降低机审调用量 ------ 尽量把能本地拦截的都拦截掉,只在必要时才调用机审。
- 保证用户体验 ------ 内容审核要快,朋友圈/评论必须秒级展示,不能再出现"发条动态等好几分钟"的情况。
- 减少误判带来的客诉 ------ 允许后台随时加白/加黑,策略能快速调整,避免一错再错。
- 动态可控 ------ 敏感词库支持实时更新,Redis Pub/Sub 秒级生效,保证新策略能立刻落地。
- 成本可控 ------ 第三方机审作为兜底,而不是主力,保证整体审核成本可控。
第一步:先建立自己的"黑名单"体系
最开始,我们发现如果每一条用户内容都直接丢给机审平台(比如数美、天网),成本会非常高,而且很多敏感词本身是高度确定的 ,根本不需要调用机审。比如涉黄、涉政、涉恐、赌博、广告等,这些词没有争议,一旦出现就是必拦。
所以第一步,我们决定先建立一套自己的本地黑名单体系 。自己先维护一份"核心高危敏感词库 ",把确定要拦截的词都本地化存储并匹配,做到本地优先拦截 ,减少外部机审调用。我们设计了一张专门的敏感词表 api_sensitive_words,表结构大概如下:
sql
CREATE TABLE `api_sensitive_words` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`keyword` VARCHAR(255) NOT NULL COMMENT '敏感词',
`type` ENUM('BLACK','WHITE','NORMAL') DEFAULT 'NORMAL' COMMENT '类型: 黑名单/白名单/普通',
`category` ENUM('PORN','POLITICS','TERROR','AD','INSULT','OTHER') DEFAULT 'OTHER' COMMENT '分类: 色情/涉政/涉恐/广告/辱骂等',
`source` ENUM('HUMAN','VENDOR','AUDIT') DEFAULT 'HUMAN' COMMENT '来源: 人工录入/机审回流/客服审核回流',
`status` TINYINT(1) DEFAULT 1 COMMENT '状态: 1启用 0停用',
`hit_count` BIGINT DEFAULT 0 COMMENT '命中次数(统计用)',
`updated_by` VARCHAR(64) DEFAULT NULL COMMENT '最后操作人',
`updated_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_keyword` (`keyword`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='敏感词表';-
keyword需要建索引,因为 Trie 初始化和后台搜索都依赖它。 -
type预留三种:BLACK→ 必拦词WHITE→ 误判词,机审命中但人工确认是正常的NORMAL→ 低风险词,比如"红包""裸聊"这种,看业务需求决定是否提示或拦截
-
category用于统计和调优,比如我们可以知道涉黄类词汇占比多少,优化策略时更有针对性。 -
source标记词的来源:- 人工运营导入的
- 机审平台回流的
- 客服审核回流的 这样可以后续做精准策略,比如只清理机审回流的低置信度词。
-
hit_count统计命中次数,用于评估词的"热度",如果命中率很低可能考虑降级或移除。
这样设计的好处是:
- 后台可以灵活维护词库,客服、运营、算法、机审回流的数据都能统一管理
- 本地维护的"必拦词"能直接走 Trie 匹配,不用浪费一次外部机审请求
- 后续可以在此基础上继续扩展"白名单""热更新""误判回流"能力
这一部分做好了,就相当于为整个敏感词体系打下了地基。
第二步:引入 Trie + Aho-Corasick 自动机,实现高性能敏感词匹配
建立了自己的黑名单体系后,接下来就遇到了一个问题:怎么高效地做敏感词匹配 ? 我们有了 api_sensitive_words 表,里面可能会有几万甚至几十万条敏感词,如果每次用户发朋友圈、评论、昵称、签名都要去查数据库,那基本上等于自杀。
1. 直接 MySQL 模糊匹配的痛点
我们最开始考虑过直接用 MySQL,比如这样:
sql
SELECT keyword FROM api_sensitive_words WHERE INSTR(:content, keyword) > 0;或者用 LIKE:
sql
SELECT keyword FROM api_sensitive_words WHERE :content LIKE CONCAT('%', keyword, '%');这种做法有几个致命问题:
- 性能差 一旦词库过万,SQL 就会非常慢,
LIKE和INSTR都没法走索引。 如果并发上来,整个 DB 直接被拖垮。 - 匹配不全 比如用户发了"爆🍉新闻",词库里是"爆料新闻",MySQL 的匹配是基于字符串的,根本识别不出来。
- 更新不及时 敏感词库经常在更新,每次都要走数据库,缓存起来又不方便做模糊匹配。
所以很快我们就放弃了这种方案。
2. 那用 ES(Elasticsearch)能解决吗?
有同事提出过用 Elasticsearch 做全文检索来解决匹配效率问题。 理论上,ES 的倒排索引确实比 MySQL 快很多,但我们分析后觉得并不合适:
- 部署和运维成本高 引入 ES 就意味着多一套集群、多一套运维,单独维护压力大。
- 场景不适配 我们只是做"是否包含敏感词"的二值判断,不需要复杂的相关性计算。
- 依旧难搞谐音和模糊匹配 ES 虽然有拼音分词器,但实现复杂,而且更新敏感词库的延迟依然存在。
所以 ES 对我们来说有点"杀鸡用牛刀",最后也被否掉了。
3. Trie + Aho-Corasick 自动机
最终我们选择了基于 Trie 树 + Aho-Corasick 自动机 的方案。
Trie 树的优势
- Trie 是一棵"前缀树",非常适合敏感词这种固定词库 + 高频匹配的场景。
- 词库更新后只需重新构建 Trie,一次加载到内存即可。
- 匹配效率高,时间复杂度是
O(文本长度),跟词库大小几乎无关。
Aho-Corasick(AC 自动机)的增强
如果只用 Trie,匹配效率还行,但每次遇到不匹配字符时需要回溯,性能会有瓶颈。 AC 自动机在 Trie 的基础上引入了 "失败指针" ,让匹配可以"平移"而不是回溯,效率更高。 这样即便有几万条敏感词,也能在毫秒级完成匹配。
为什么比 MySQL 和 ES 更合适
- 全量内存匹配 → 无需查库
- 支持模糊匹配 → 可以针对同音字、变体词做归一化,比如"黄赌毒"、"黄🌸毒"都能识别
- 支持秒级热更新 → 后台改了词库,Trie 直接重建,几秒内所有应用生效
- 低成本高性能 → 既避免了机审全量调用,又不需要引入额外的 ES 集群
第三步:基于 Trie + AC 自动机落地高性能审核体系
我们对比了 MySQL、ES 和 Trie + AC 自动机的业务场景区别,最终我们选择了基于 Trie 树 + Aho-Corasick 自动机 的方案。
接下来,我们就简单实现,构建一套高性能、低延迟、可动态更新的敏感词审核体系,确保在海量用户请求下也能稳定高效地工作。
3.1 架构设计
核心架构围绕「MySQL 持久存储 + Redis 缓存 + Go 内存引擎 + 秒级热更新 + 机审兜底」:
sql
┌────────────────────────┐
│ api_sensitive_words │ ← MySQL 持久存储敏感词
└──────────┬─────────────┘
│
后台管理系统增删改词
│
┌──────────▼─────────────┐
│ Redis缓存 │ ← 存储最新词表
└──────────┬─────────────┘
│
Redis 发布订阅 (sensitive:update)
│
┌──────────▼─────────────┐
│ Go 服务内存中的 Trie │
│ + Aho-Corasick 自动机 │
└──────────┬─────────────┘
│
用户请求 → 本地匹配
│ 命中 │ 未命中
▼ ▼
拦截 / 标记 / 上报 调用第三方机审核心思路
- MySQL --- 敏感词的最终存储 所有敏感词、黑名单、白名单的权威数据源,保证数据完整性与可追溯性。
- Redis --- 高速缓存层 缓存最新的敏感词表,避免频繁查 MySQL,支撑高并发低延迟。
- Trie + AC 自动机 --- 高性能内存匹配引擎 在 Go 内存中一次性加载所有敏感词,基于 Trie 构建 Aho-Corasick 自动机,实现 O(文本长度) 的高效匹配。 同时支持模糊匹配、黑白名单、归一化处理("黄赌毒"、"黄🌸毒"都能识别)。
- 后台管理系统 --- 人工可控 提供增删改词、添加黑白名单、风险词分类等操作,变更后立即推送到 Redis,通过发布订阅机制触发内存引擎自动热更新。
- 秒级热更新机制 当后台修改敏感词时,会向 Redis 发布一个
sensitive:update事件,Go 服务订阅该事件后会立即重建 Trie + AC 自动机,整个过程通常在 100ms~1s 内完成。 - 机审兜底 --- 降低成本 对于内存引擎未命中的文本,请求会进入第三方机审(如数美天网)。 这样大幅降低了机审的调用量和成本,同时仍然保留了机审对复杂文本、图片、视频的检测能力。
这样设计的效果总结
- 高性能 → 绝大多数请求走本地内存匹配,毫秒级返回结果
- 低成本 → 通过 Trie + AC 自动机拦截大部分敏感词,极少命中机审
- 高可控 → 黑白名单、误判复核、秒级热更新,运营可以灵活调整
- 高扩展性 → 后续可以无缝接入图片、视频机审,形成多模态内容安全体系
在这种架构下,用户在发朋友圈、评论、私信时,99% 的请求只需走内存匹配;只有极少数复杂或新型敏感词才会触发机审,既保证了性能,又有效控制了成本。
3.2 基于 Trie + AC 自动机构建高性能敏感词检测引擎
在完成了 敏感词表设计 和 架构方案分析 后,我们就需要落地一个高性能、可热更新的敏感词检测引擎。
核心目标是:
- 毫秒级检测 → 高频场景下用户无感
- 秒级热更新 → 后台改词立刻生效
- 机审兜底 → 未命中本地词库再调用机审,降低成本
3.2.1 设计思路
我们在设计这套敏感词检测引擎时,有几个关键考量:
-
词库加载策略
- 所有敏感词存 MySQL,启动时全量加载到内存
- 后台变更敏感词 → 写 MySQL → 写 Redis → Redis 发布更新通知
- Go 服务收到通知 → 重新构建 Trie + AC 自动机 → 秒级热更新
-
检测流程
- 用户请求 → 本地内存检测
- 命中 → 返回结果 & 上报
- 未命中 → 走第三方机审
-
高并发优化
- 敏感词检测走内存,无需查库
- Trie + AC 自动机构建在启动时一次性完成
- AC 匹配是单次扫描,复杂度 O(N),无论几万词都能控制在毫秒级
这样,99% 的请求在 Go 内存中毫秒级返回,只对剩余 1% 的高风险内容调用机审。
3.2.2 代码实现:Go + Trie + AC 自动机 + Redis 热更新
这一节我们落地完整方案,做三件事:
- 敏感词本地检测 → Trie + AC 自动机,毫秒级匹配
- Redis 热更新 → 后台改词 → 发布事件 → 内存引擎秒级重建
- 未命中兜底调用机审 → 降低调用量 + 保证高风险内容兜底拦截。
我们来实现一个非常简单的demo示例。
1. 敏感词检测引擎(ACTrie.go)
用 Trie + Aho-Corasick 自动机实现,支持并发检测 + 秒级热更新。
go
package trie
import (
"container/list"
"sync"
)
type TrieNode struct {
children map[rune]*TrieNode
fail *TrieNode
isEnd bool
word string
}
type ACTrie struct {
root *TrieNode
mu sync.RWMutex
}
func NewACTrie() *ACTrie {
return &ACTrie{
root: &TrieNode{children: make(map[rune]*TrieNode)},
}
}
// 构建 Trie 树 + AC 自动机
func (ac *ACTrie) Build(words []string) {
ac.mu.Lock()
defer ac.mu.Unlock()
// 重新初始化
ac.root = &TrieNode{children: make(map[rune]*TrieNode)}
// 构建 Trie
for _, word := range words {
node := ac.root
for _, ch := range []rune(word) {
if node.children[ch] == nil {
node.children[ch] = &TrieNode{children: make(map[rune]*TrieNode)}
}
node = node.children[ch]
}
node.isEnd = true
node.word = word
}
// 构建 AC 自动机失败指针
ac.buildFailPointers()
}
func (ac *ACTrie) buildFailPointers() {
queue := list.New()
for _, node := range ac.root.children {
node.fail = ac.root
queue.PushBack(node)
}
for queue.Len() > 0 {
e := queue.Front()
queue.Remove(e)
current := e.Value.(*TrieNode)
for ch, child := range current.children {
failNode := current.fail
for failNode != nil && failNode.children[ch] == nil {
failNode = failNode.fail
}
if failNode == nil {
child.fail = ac.root
} else {
child.fail = failNode.children[ch]
}
queue.PushBack(child)
}
}
}
// 匹配文本
func (ac *ACTrie) Match(text string) []string {
ac.mu.RLock()
defer ac.mu.RUnlock()
var result []string
node := ac.root
for _, ch := range []rune(text) {
for node != ac.root && node.children[ch] == nil {
node = node.fail
}
if node.children[ch] != nil {
node = node.children[ch]
}
// 收集所有可能的命中
temp := node
for temp != ac.root {
if temp.isEnd {
result = append(result, temp.word)
}
temp = temp.fail
}
}
return result
}2. Redis 热更新 + 检测逻辑(service.go)
后台添加/删除敏感词 → 发布
sensitive:update→ 内存 Trie 自动重建。
go
package service
import (
"context"
"log"
"time"
"sensitive/trie"
"github.com/redis/go-redis/v9"
)
// 从 Redis 拉取最新词库
func fetchWordsFromRedis(rdb *redis.Client) []string {
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
words, err := rdb.SMembers(ctx, "sensitive:words").Result()
if err != nil {
log.Println("获取敏感词失败:", err)
return nil
}
return words
}
// 监听热更新
func ListenUpdate(ac *trie.ACTrie, rdb *redis.Client) {
sub := rdb.Subscribe(context.Background(), "sensitive:update")
for msg := range sub.Channel() {
log.Println("接收到词库更新事件:", msg.Payload)
words := fetchWordsFromRedis(rdb)
ac.Build(words)
log.Println("Trie + AC 引擎已完成热更新")
}
}3. 兜底调用第三方机审(audit.go)
这里我们实现
callVendorAudit方法,模拟调用第三方机审平台(例如数美、天网),并支持异步回调。
go
package service
import (
"bytes"
"encoding/json"
"io/ioutil"
"log"
"net/http"
)
type VendorAuditRequest struct {
Text string `json:"text"`
UserID int `json:"user_id"`
}
type VendorAuditResponse struct {
Code int `json:"code"`
Message string `json:"message"`
Risk bool `json:"risk"`
}
// 兜底调用第三方机审
func callVendorAudit(text string, userID int) (bool, error) {
payload := VendorAuditRequest{
Text: text,
UserID: userID,
}
body, _ := json.Marshal(payload)
resp, err := http.Post("https://vendor.example.com/audit", "application/json", bytes.NewReader(body))
if err != nil {
log.Println("调用机审失败:", err)
return false, err
}
defer resp.Body.Close()
data, _ := ioutil.ReadAll(resp.Body)
var result VendorAuditResponse
if err := json.Unmarshal(data, &result); err != nil {
log.Println("解析机审响应失败:", err)
return false, err
}
return result.Risk, nil
}4. 敏感词检测入口
go
func CheckContent(ac *trie.ACTrie, text string, userID int) (bool, []string) {
matches := ac.Match(text)
if len(matches) > 0 {
// 本地命中敏感词,直接拦截
return true, matches
}
// 本地未命中 → 调用第三方机审
risk, err := callVendorAudit(text, userID)
if err != nil {
log.Println("调用机审异常:", err)
return false, nil
}
// 如果机审返回高风险 → 拦截
if risk {
return true, []string{"[机审命中]"}
}
// 否则允许通过
return false, nil
}我们这样设计思路
-
为什么本地检测优先?
- 内存中 Trie + AC 自动机 → 毫秒级响应
- 机审 QPS 成本高且延迟大,本地检测可拦截绝大多数内容
-
为什么机审兜底?
- 有些谐音、变体、图文混排等复杂场景,本地 Trie 难以覆盖
- 我们不放弃机审,而是"只用在必要场景",降低调用量
-
为什么热更新用 Redis 发布订阅?
- 后台添加/删除敏感词 → 发布更新事件
- Go 服务感知 → 重建 AC 引擎,秒级生效
第四步:引入机审回流机制,减少误判率
在上线基于 Trie + AC 自动机 的本地高性能检测引擎后,我们在未命中的情况下会调用第三方机审(例如数美、天网)兜底拦截。
但是很快,我们遇到了一个新的问题:机审的误判率偏高。
4.1 为什么需要机审回流
一开始,我们和数美平台的同学沟通过,他们建议我们在数美后台调整模型阈值 ,并多喂数据让平台模型更适应我们的业务。但实践证明:
- 模型调优需要时间
数美的后台虽然可以微调大模型,但这通常需要几周甚至几个月,短期内无法解决。 - 误判直接影响用户体验
大量正常用户的评论、昵称、动态会被错误拦截,造成投诉率上升。 - 过度依赖机审,成本偏高
即便我们用 Trie + AC 自动机拦了一部分,剩下的"边缘内容"仍然大量送到机审,每次都要消耗调用额度,且返回的结果未必可靠。
所以我们决定引入一层 机审回流机制:
机审命中的内容不再直接信任,而是进入我们的本地回流队列,由运营/算法标注后再落地到敏感词库或白名单。
这样,我们既降低了机审误杀用户的风险,又能持续"喂养"我们自己的本地引擎,让检测效果越来越精准。
4.2 核心思路
整个机审回流机制的核心是 "引入人工二次确认" :
-
用户发内容 → 本地 Trie + AC 检测;
-
如果命中敏感词 → 直接拦截,无需机审;
-
如果未命中 → 调用第三方机审;
-
根据机审返回的状态:
- PASS → 暂时放行,但如果机审返回了疑似高风险候选词,写入候选表,供客服确认;
- REVIEW → 机器认为可疑,直接写入候选表,由人工复核;
- REJECT → 机器判定违规,直接拦截,但仍写入候选表等待人工确认;
-
后台运营审核候选表,确认结果后:
- 如果确认违规 → 加入黑名单,Trie 热更新;
- 如果确认误判 → 加入白名单,避免重复拦截。
4.3 第三方机审返回状态
以数美为例,常见返回状态有三种:
| 状态 | 含义 | 我们的处理 |
|---|---|---|
| PASS (通过) | 内容安全,无违规 | 暂时放行,但记录可疑词,供运营复核 |
| REVIEW (可疑) | 机器检测到风险,需人工确认 | 写入候选表,运营二次审核 |
| REJECT (拒绝) | 明确违规,不允许放行 | 直接拦截,同时写入候选表,等待人工确认 |
这种分级机制让我们在业务层面更加灵活,既不盲目信任机审,又不会因为误判直接影响用户。
4.4 新增候选敏感词表
我们新增了 api_sensitive_candidates 表,用来记录第三方机审命中的可疑词:
sql
CREATE TABLE `api_sensitive_candidates` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`keyword` VARCHAR(255) NOT NULL COMMENT '候选敏感词',
`vendor` VARCHAR(64) DEFAULT NULL COMMENT '机审来源,例如数美、天网',
`risk_level` TINYINT DEFAULT 1 COMMENT '1低风险 2中风险 3高风险',
`status` ENUM('PENDING','CONFIRMED','REJECTED') DEFAULT 'PENDING' COMMENT '状态',
`created_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='机审候选敏感词';- PENDING → 默认状态,待运营人工审核
- CONFIRMED → 确认违规,加入黑名单,Trie 热更新
- REJECTED → 确认误判,加入白名单,避免误拦
4.5 处理流程示例
go
func auditContent(userID int64, content string) (bool, error) {
// 1. 先走本地 Trie + AC 自动机
if acEngine.Match(content) {
return false, errors.New("命中本地敏感词,拦截")
}
// 2. 调用第三方机审
resp, err := callShumeiAPI(content)
if err != nil {
log.Printf("[ERROR] 调用机审失败: %v", err)
return true, nil // 容错策略:机审挂了就先放行
}
switch resp.RiskLevel {
case "PASS":
// 暂时放行,但写入候选表供人工复核
saveCandidates(resp.HitWords, "数美", 1)
return true, nil
case "REVIEW":
// 写入候选表,等待客服确认
saveCandidates(resp.HitWords, "数美", 2)
return false, errors.New("内容可疑,等待人工复核")
case "REJECT":
// 直接拦截,同时写入候选表
saveCandidates(resp.HitWords, "数美", 3)
return false, errors.New("内容违规,已拦截")
default:
return true, nil
}
}
func saveCandidates(words []string, vendor string, risk int) {
for _, word := range words {
_, err := db.Exec(`
INSERT INTO api_sensitive_candidates (keyword, vendor, risk_level)
VALUES (?, ?, ?)
`, word, vendor, risk)
if err != nil {
log.Printf("[WARN] 保存候选词失败: %v", err)
}
}
}4.6 这样设计的机制优势
- 减少误判 → 不盲目信任机审,用户体验更好
- 词库自动进化 → 命中新词可回流,Trie 引擎实时热更新
- 降低成本 → 随着词库完善,机审调用量显著下降
- 可控性更强 → 运营、算法可以在后台快速干预
第五步:智能化词库演进,让系统越用越准
在引入 机审回流机制 之后,我们的敏感词检测体系已经形成了一个"人机协同"的闭环:
- 本地 Trie + AC 自动机 → 毫秒级检测
- 机审兜底 → 保证高风险内容不漏网
- 机审回流 → 候选词进入二次审核,减少误判
但是,光靠人工去不断确认候选词,仍然有几个问题:
- 人工压力依然存在
机审每天可能返回上千条候选词,如果全部依赖客服逐条确认,工作量依然巨大。 - 词库维护效率不高
敏感词的热词更新非常快,比如某些热点事件、网络流行词,一旦被用户恶意利用,如果没有及时补充到词库,就会产生"窗口期"。 - 重复误判问题
某些词一旦被误判,如果没有白名单兜底,可能会反复影响不同用户。
所以我们在第四步的基础上,进一步做了一个 智能化词库演进机制,让系统能"越用越准"。
5.1 核心思路
我们把候选词的流转分成三个阶段:
-
机审 → 候选词表
第三方机审命中的内容不直接生效,而是进入
api_sensitive_candidates。 -
二次确认 → 黑白名单
- 人工确认违规 → 写入黑名单,进入
api_sensitive_words表; - 人工确认误判 → 写入白名单,避免后续重复拦截。
- 人工确认违规 → 写入黑名单,进入
-
自动学习 → 热更新引擎
- 黑名单 / 白名单更新后 → Redis 发布
sensitive:update→ Go 内存引擎秒级热更新; - 下次用户再发同类内容时,系统直接在本地完成判定,无需机审。
- 黑名单 / 白名单更新后 → Redis 发布
5.2 处理流程图
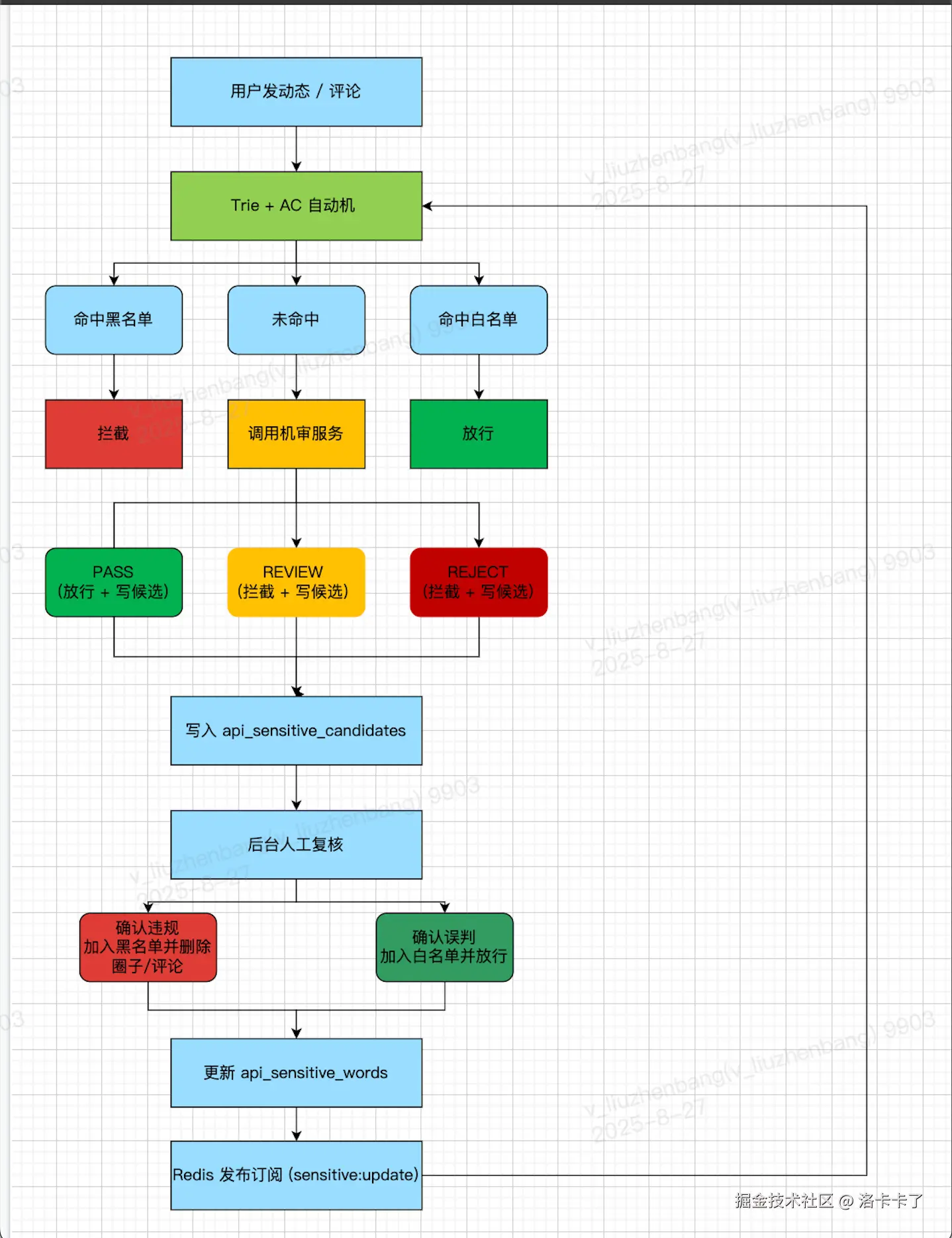
5.3 表设计优化
在第四步中,我们有两个关键表:
-
机审候选敏感词表(待审核池)
sqlCREATE TABLE `api_sensitive_candidates` ( `id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT, `keyword` VARCHAR(255) NOT NULL, `vendor` VARCHAR(64) DEFAULT NULL COMMENT '机审来源', `risk_level` TINYINT DEFAULT 1 COMMENT '1低风险 2中风险 3高风险', `status` ENUM('PENDING','CONFIRMED','REJECTED') DEFAULT 'PENDING', `created_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='机审候选敏感词'; -
敏感词主表(黑名单 / 白名单)
sqlCREATE TABLE `api_sensitive_words` ( `id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT, `keyword` VARCHAR(255) NOT NULL, `type` ENUM('BLACK','WHITE','NORMAL') DEFAULT 'NORMAL' COMMENT '黑名单/白名单/普通', `category` enum('PORN','POLITICS','TERROR','AD','INSULT','OTHER') DEFAULT 'OTHER' COMMENT '分类', `source` enum('HUMAN','VENDOR','AUDIT') DEFAULT 'HUMAN' COMMENT '来源: 人工/机审/审核回流', `status` TINYINT(1) DEFAULT 1 COMMENT '1=启用 0=停用', `hit_count` bigint(20) DEFAULT '0' COMMENT '命中次数', `updated_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='敏感词表';
5.4 智能化优化点
在人工复核的基础上,我们还做了几层优化:
- 高频候选词自动标记
如果某个词连续多次出现在api_sensitive_candidates,即使还没人工确认,也可以先标记为"高优先级",提醒运营重点关注。 - 白名单优先级
如果某个词已被确认进入白名单,即使机审再次判定为违规,也会优先放行,避免反复误判。 - 规则兜底
对于某些常见的变体(比如 Emoji、拼音替代),我们在检测层加了一层归一化处理,让"黄🌸毒"这种形式也能被映射到"黄赌毒"。
5.5 初步运行效果
经过这一层机制迭代,我们的系统表现明显改善:
- 机审调用量下降 70%+
因为更多的新词被回流到本地引擎,减少了依赖机审。 - 误判率降低到 <1%
白名单机制避免了大规模误拦,用户体验显著提升。 - 客服压力减少 50%
只有真正疑难的词才需要人工二次确认,重复问题被系统自动兜底。 - 系统自我进化
每次机审命中 → 候选池 → 人工确认 → 黑白名单 → 热更新 → 下次直接拦截 / 放行,形成闭环。
做到这一步,我们的敏感词检测体系从 纯人工 → 机审兜底 → 回流机制 → 智能演进 ,形成了一条完整的进化链路。
可以说,这时候的系统已经具备了简单的 自我学习、自我修复 的能力。
一路走到这,我们的内容安全体系长这样
回头看这套敏感词检测,基本就是一路"打补丁 → 优化 → 再进化"的过程:
- 一开始,全靠人工盯,效率低不说,用户体验还特别差;
- 后来上了 Trie + AC 自动机,本地内存里就能解决大部分情况;
- 再后来,为了防止遗漏,就接了机审兜底;
- 但机审的误判实在多,于是加了回流机制,让客服二次确认,把结果再喂回系统。
整条链路其实就一句话:
"能自己搞定的就自己搞定,搞不定的交给机审,机审再回流回来让自己更聪明。"
我们这样做的好处
- 快:用户发评论、朋友圈、聊天消息,检测全在内存里走,几乎是秒回。
- 省钱:以前所有请求都丢机审,花钱像流水;现在绝大多数在本地解决,机审调用量直接砍掉一大半。
- 准:有了回流机制,误判能拉白,新违规词能拉黑,检测效果越来越准。
- 灵活:后台一加黑/加白,Redis 一推送,所有服务立刻热更新,不用重启。
那这套方案还能怎么玩
这套机制并不是只能用在评论和朋友圈。
像 用户昵称、群聊名字、私信聊天 都能走同样流程。
再往后拓展,图片可以先 OCR 把文字识别出来,视频可以先转语音文本,然后也能丢进检测引擎里。
甚至还能做 风险分级 :比如评论可以稍微宽松点,私信要严格点。
或者 智能提示:某些候选词老是出现,就自动标记高优先级,提醒运营重点盯一下。
最后
说实话,如果单看业务需求,靠人工 + 机审也能凑合把内容审核跑起来。
但身为技术,我们需要考虑的不光是能不能用,还要考虑能不能撑得住规模、能不能压下成本 。
人工再加人就是烧钱,机审再开额度也是烧钱,最后账一算,公司运营成本根本顶不住。
所以我们才决定用技术来改造这一块:把能在本地搞定的尽量留在本地,把复杂的丢给机审兜底,再通过回流机制让系统自己进化。这样做下来,不光用户体验提升了,公司在成本上也真正省下了一大块。
回头看,这套内容安全体系已经不只是一个"审核工具",而是一个能跟着业务规模一起成长的系统。它能抗住流量高峰,也能帮公司省钱,更重要的是,它让我切身感受到------用技术解决问题,能直接改变运营成本。