目录
[决策树 Decision Tree](#决策树 Decision Tree)
[随机森林 Random Forest](#随机森林 Random Forest)
[梯度提升决策树 Gradient Boosting Decision Trees](#梯度提升决策树 Gradient Boosting Decision Trees)
[Softmax Regression](#Softmax Regression)
决策树模型
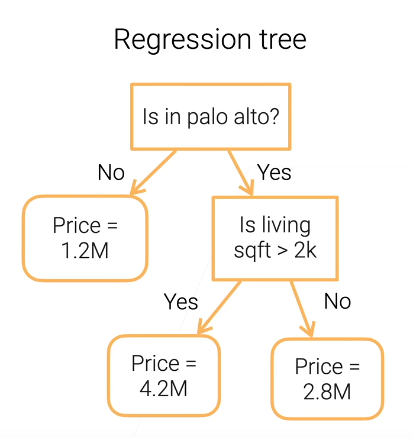
决策树 Decision Tree
用于分类和回归,通过一系列判断得到最终的结果。
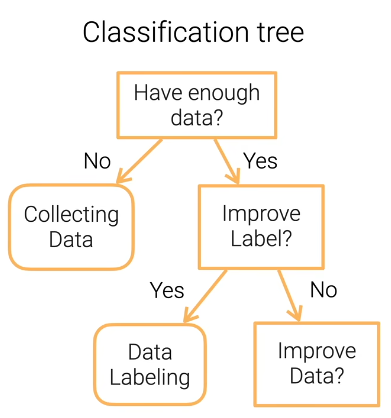
优点:可解释;既能处理数值也能处理特征分类
缺点:不稳定,噪声的影响大(集成学习可以改进);过拟合;不易并行计算;
随机森林 Random Forest
森林:独立地训练几棵决策树,综合几棵决策树的结果来提高结果的稳定性。
随机:1.训练集使用随机采样的方法,如数据集D={1,2,3},训练集A={1,2,3},B={1,1,3};
2.随机选取部分特征,比如确定一个西瓜好不好吃需要10个特征,我只随机拿5个特征用来训练决策树,从这5个特征中找最优划分特征。
梯度提升决策树 Gradient Boosting Decision Trees
按照顺序来训练多棵决策树;首先训练一棵树,然后用这棵树的结果和实际结果之间的残差来训练下一棵树,相当于一直训练新的树来修正之前的树的结果,最后所有树的结果相加得到最终结果。
线性模型
回归
目标:学习使得均方误差最小。
分类
使用得到一系列类别的置信度,结果取置信度最大的类别。
目标:使均方误差最小。
问题:我们使结果能够足够明显的被识别出来就行了,不必过于关注别的类别,而这个方法让均方误差最小,相当于想训练一个模型使得正确结果的预测结果就是1,错误结果的预测结果就是0,没必要。
Softmax Regression
标签向量,其中
表示真实的类别是第i类,否则为0。
设模型的输出是分数,用表示,softmax函数把这些分数转化为概率
。
目标:最小化,
是指模型预测出的正确的类别的概率。正确类别的概率越接近一越好。
小批量随机梯度下降
几乎可以求解除决策树之外所有的算法模型。