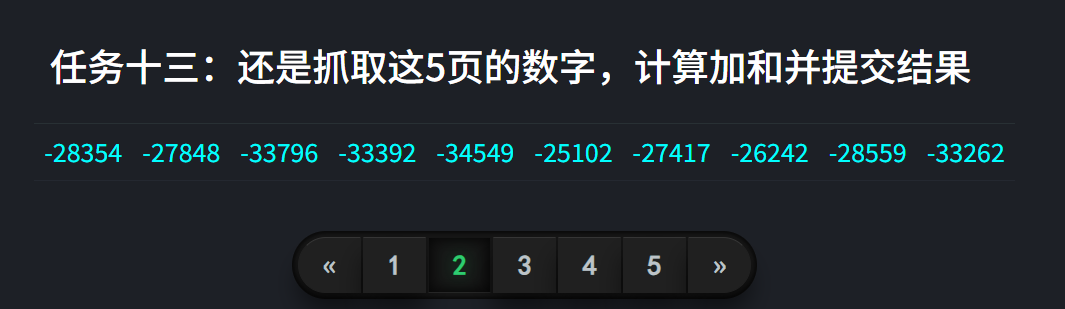
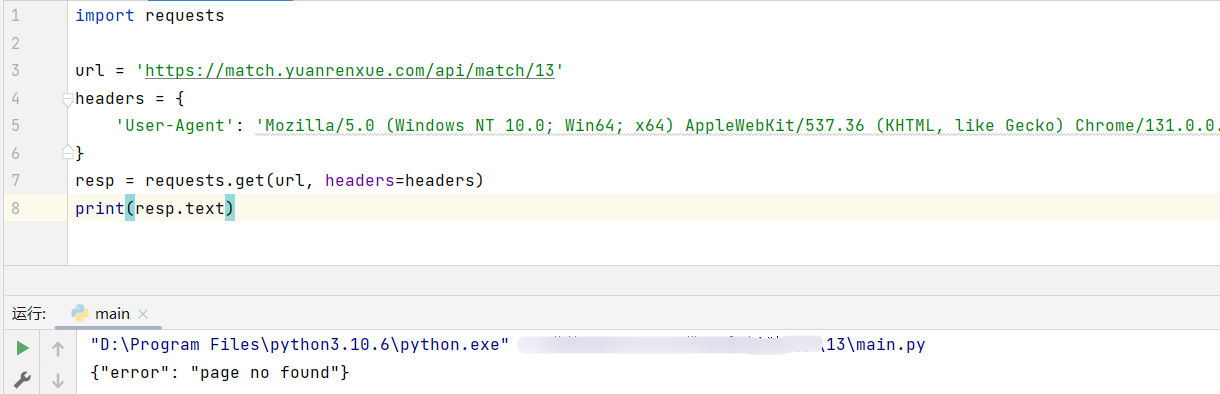
加个cookie:
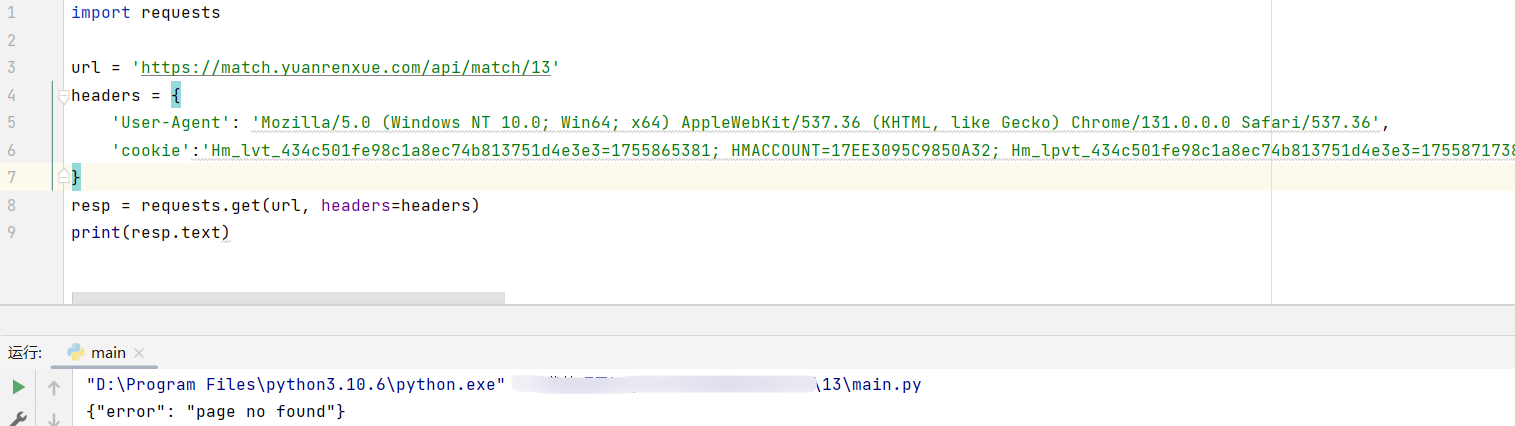
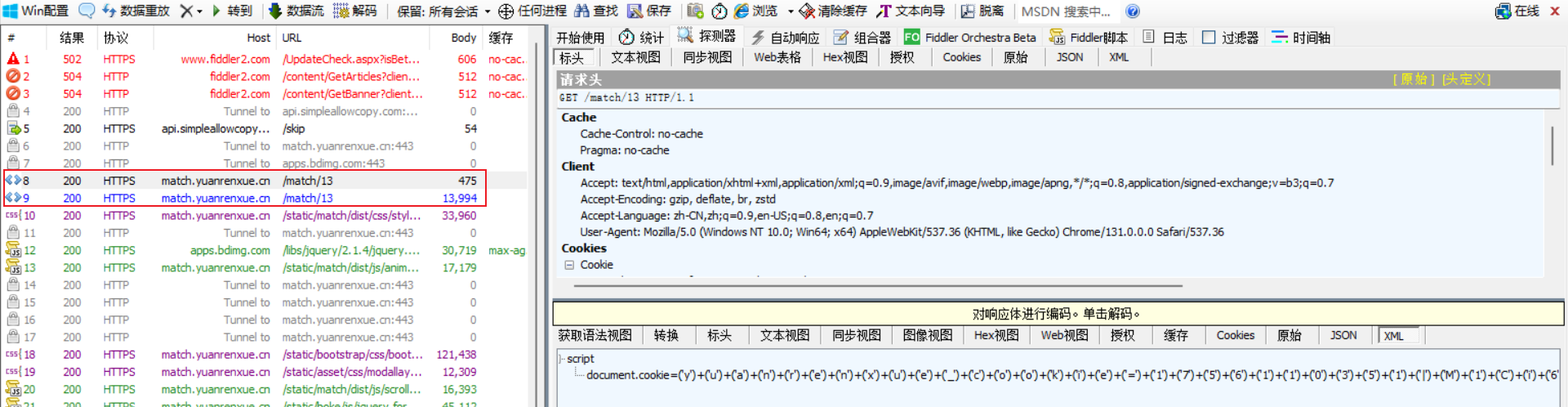
cookie中有个特殊的字段 yuanrenxue_cookie,但是怎么找都找不到,通过fiddler工具看下触发的所有流量包吧:
python代码:
python
import re
import requests
# 创建会话并设置请求头和cookie
obj = requests.session()
obj.headers={
'Referer':'https://match.yuanrenxue.cn/list',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
}
# 设置成自己的sessionid
obj.cookies.set('sessionid','bse1j3p3uluqpc3jod0t5zrjs84ht1hc')
# 获取更新后的yuanrenxue_cookie值
res = obj.get(url='https://match.yuanrenxue.cn/match/13')
print(res.text)
cookie_list = eval(re.findall('\(.*\)',res.text)[0]).split('=')
print(cookie_list)
obj.cookies.update(
{cookie_list[0]:cookie_list[1]}
)
# 访问具体页面时一定要注意先更新请求头信息中的Referer
obj.headers.update({'Referer':'https://match.yuanrenxue.cn/match/13'})
# 向各个页面发送请求并获取数据
total_value = 0
for pid in range(1,6):
res = obj.get(url=f'https://match.yuanrenxue.cn/api/match/13?page={pid}')
data = res.json()['data']
print(f"第{pid}页数据:{data}")
for item in data:
total_value += int(item['value'])
print(f"前5页数字总和:{total_value}")结果:
