VideoMaker:零样本定制化视频生成,依托于视频扩散模型的内在力量
paper title:VideoMaker: Zero-shot Customized Video Generation with the Inherent Force
of Video Diffusion Models
paper是ZJU发布在Arxiv 2024的工作
Code:链接

图1. 我们的 VideoMaker 可视化结果。我们的方法基于 AnimateDiff 26,实现了高保真零样本定制化人物和物体视频生成。
Abstract
零样本定制化视频生成因其巨大的应用潜力而备受关注。现有方法依赖于额外的模型来提取和注入参考主体特征,假设仅凭视频扩散模型(VDM)不足以实现零样本定制化视频生成。然而,这些方法由于特征提取和注入技术不够理想,往往难以保持主体外观的一致性。在本文中,我们揭示了 VDM 本身就具备提取和注入主体特征的内在能力。不同于以往的启发式方法,我们提出了一种新颖的框架,利用 VDM 的内在力量来实现高质量的零样本定制化视频生成。具体而言,在特征提取方面,我们直接将参考图像输入 VDM,并利用其内在的特征提取过程,这不仅提供了细粒度的特征,还能显著契合 VDM 的预训练知识。在特征注入方面,我们设计了一种创新的双向交互机制,通过 VDM 内部的空间自注意力在主体特征与生成内容之间建立联系,从而保证 VDM 在保持生成视频多样性的同时具有更好的主体保真度。在人物和物体定制化视频生成上的实验结果验证了我们框架的有效性。
1. Introduction
视频扩散模型(VDMs)5, 9, 19, 57, 70 可以根据给定的文本提示生成高质量视频。然而,这些预训练模型无法从特定主体生成对应视频,因为这种定制化主体仅通过文本提示难以准确描述。这个问题被称为定制化生成,已有研究通过个性化微调 6, 53, 65, 67 进行探索。然而,耗时的主体特定微调限制了其在现实中的应用。最近,一些基于 58, 71 的方法 23, 32 开始探索零样本定制化视频生成,但这些方法仍未能保持与参考主体一致的外观。
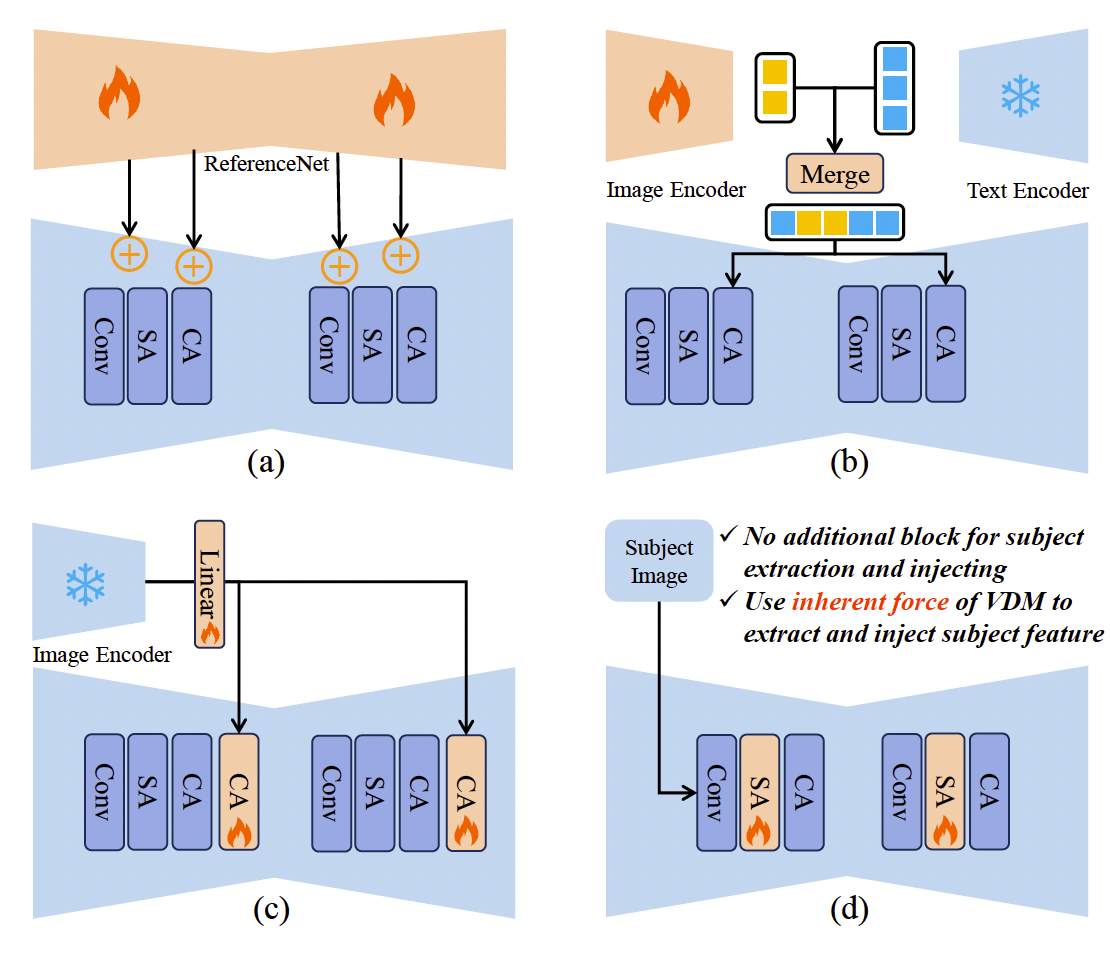
图2. 与现有零样本定制化生成框架相比,我们的框架无需任何额外模块来提取或注入主体特征。它只需要将参考图像与生成视频进行简单拼接,并利用 VDM 的内在能力生成定制化视频。
定制化视频生成的两个关键在于主体特征提取与主体特征注入。当前方法依赖额外的模型进行特征提取和注入,往往忽视了 VDM 的内在能力。例如,一些方法 26, 58, 68 受到 79 启发,采用额外的 ReferenceNet 进行特征提取,并将主体特征直接加入 VDM 中进行注入(图2 (a))。然而,这些方法引入了大量额外训练参数,并且这种像素级注入方式显著限制了生成视频的多样性。其他方法 23, 32, 38, 71 则采用预训练的跨模态对齐模型 43, 45, 50, 69 作为特征提取器,并通过跨注意力层注入主体特征(图2 (b,c))。然而,这些方法从预训练提取器中获得的仅是粗粒度的语义级特征,难以捕捉主体的细节。因此,这些精心设计的启发式方法并未在定制化视频生成中取得令人满意的效果。一个自然的问题是:或许 VDM 本身就具备提取和注入主体特征的能力,我们只需通过一种简单方式激活并利用这种力量,就能实现定制化生成?
重新审视 VDM,我们发现了一些潜在的内在能力。在主体特征提取方面,由于输入无噪声的参考图像可以视为时间步 t = 0 t=0 t=0 的特殊情况,预训练的 VDM 已经能够在无需额外训练的情况下提取其特征。在主体特征注入方面,VDM 的空间自注意力主要建模帧内不同像素之间的关系,因此更适合注入与生成内容紧密相关的主体参考特征。此外,空间自注意力的自适应特性使其能够选择性地与这些特征交互,从而避免过拟合并促进生成视频的多样性。因此,如果我们利用 VDM 本身作为细粒度的主体特征提取器,并通过空间自注意力机制将主体特征与生成内容交互,就能利用 VDM 的内在力量实现定制化生成。
基于上述动机,我们提出了 VideoMaker,一个新颖的框架,利用 VDM 的内在能力实现高质量的零样本定制化生成。我们将参考图像作为模型输入的一部分,直接使用 VDM 进行特征提取。所提取的特征不仅细粒度,而且与 VDM 的内在知识高度契合,避免了额外的对齐过程。在主体特征注入方面,我们利用 VDM 的空间自注意力,在逐帧生成内容时显式地将主体特征与生成内容进行交互,使其与 VDM 的内在知识保持紧密联系。此外,为了确保模型在训练过程中能够有效区分参考信息与生成内容,我们设计了一种简单的学习策略以进一步提升性能。我们的框架采用原生方法完成主体特征的提取与注入,无需增加额外模块,仅需对预训练的 VDM 进行轻量微调以激活其内在力量。通过大量实验,我们在定性与定量结果上均验证了方法在零样本定制化视频生成中的优越性。
我们的贡献总结如下:
- 我们利用视频扩散模型的内在力量提取主体的细粒度外观特征,这些外观信息对视频扩散模型的学习更为友好。
- 我们革新了以往的信息注入方式,创新性地利用视频扩散模型中原生的空间自注意力计算机制完成主体特征注入。
- 我们的框架优于现有方法,仅通过微调部分参数就实现了高质量的零样本定制化视频生成。
2. Related Work
2.1. Text-to-video diffusion models
随着扩散模型和图像生成 12, 28, 29, 46--49, 51, 52, 66, 76, 82 的进展,文本生成视频(T2V)取得了显著突破。由于高质量视频-文本数据集 4, 33 的有限性,许多研究者尝试基于已有的文本生成图像(T2I)框架来开发 T2V 模型。一些研究 3, 13, 20, 60, 61, 75, 77, 80, 83 专注于改进传统 T2I 模型,通过引入时序模块并训练这些新组件,将 T2I 模型转化为 T2V 模型。具有代表性的例子包括 AnimateDiff 19、Emu Video 17、PYoCo 16 和 Align your Latents 4。此外,LVDM 24、VideoCrafter 7, 9、ModelScope 57、LAVIE 62 和 VideoFactory 59 等方法采用了类似的架构,利用 T2I 模型进行初始化,并在空间和时序模块上进行微调,从而获得更优的视觉效果。除此之外,Sora 5、CogVideoX 70、Latte 44 和 Allegro 84 通过融合基于 Transformer 的骨干网络 44, 73 并结合 3D-VAE 技术,在视频生成方面也取得了重要进展。这些基础模型的发展为定制化视频生成奠定了坚实的基础。
2.2. Customized Image/Video Generation
与基础模型的发展历程类似,文本生成图像技术的快速进步也推动了图像领域中定制化生成的显著发展。能够适应用户偏好的定制化图像生成,正受到越来越多的关注 8, 10, 21, 22, 27, 30, 37, 39, 41, 42, 54, 55, 58, 64。这些工作大体可以分为两类,依据在更换主体时是否需要对整个模型进行重新训练。第一类方法包括 Textual Inversion 14、DreamBooth 53、Custom Diffusion 35 和 Mix-of-Show 18。这类方法通过学习一个文本 token 或直接微调模型的全部或部分参数,实现完全定制化。尽管这些方法通常能生成与指定主体高度一致的高保真内容,但在主体变化时仍需重新训练。第二类方法包括 IP-Adapter 71、InstantID 58 和 PhotoMaker 38。这些方法采用不同的信息注入技术,并利用大规模训练,从而在主体更换时无需参数重训。在这些方法的基础上,定制化视频生成也随着基础模型的进展而发展起来。DreamVideo 65、CustomVideo 63、Animate-A-Story 25、Still-Moving 6、CustomCrafter 67 和 VideoAssembler 81 通过微调视频扩散模型的部分参数实现定制化。然而,这相较于图像定制化生成带来了更高的训练成本,对用户而言造成了显著的不便。一些研究,如 VideoBooth 32 和 ID-Animator 23,尝试采用类似 IP-Adapter 的训练方法,但尚未达到与定制化图像生成相同的成功水平。
3. Preliminary
视频扩散模型(VDMs)9, 19, 24, 57 旨在通过扩展图像扩散模型以适应视频数据,从而完成视频生成任务。VDMs 通过对从高斯分布采样的变量逐步去噪来学习视频数据分布。首先,一个可学习的自编码器(由编码器 E \mathcal{E} E 和解码器 D \mathcal{D} D 组成)被训练用于将视频压缩到一个更小的潜在空间表示。然后,潜在表示 z = E ( x ) z = \mathcal{E}(x) z=E(x) 被训练替代视频 x x x。具体来说,扩散模型 ϵ θ \epsilon_\theta ϵθ 旨在根据文本条件 c t e x t c_{text} ctext 在每个时间步 t t t 预测加入的噪声 ϵ \epsilon ϵ,其中 t ∈ U ( 0 , 1 ) t \in \mathcal{U}(0,1) t∈U(0,1)。训练目标可以简化为一个重建损失:
L v i d e o = E z , c , ϵ ∼ N ( 0 , I ) , t ∥ ϵ − ϵ θ ( z t , c t e x t , t ) ∥ 2 2 , (1) \mathcal{L}{video} = \mathbb{E}{z, c, \epsilon \sim \mathcal{N}(0, I), t} \Big \\lVert \\epsilon - \\epsilon_\\theta (z_t, c_{text}, t) \\rVert_2\^2 \\Big, \tag{1} Lvideo=Ez,c,ϵ∼N(0,I),t∥ϵ−ϵθ(zt,ctext,t)∥22,(1)
其中 z ∈ R F × H × W × C z \in \mathbb{R}^{F \times H \times W \times C} z∈RF×H×W×C 是视频数据的潜在编码, F , H , W , C F, H, W, C F,H,W,C 分别表示帧数、高度、宽度和通道。 c t e x t c_{text} ctext 是输入视频的文本提示。一个带噪潜在编码 z t z_t zt 由真实潜在编码 z 0 z_0 z0 生成,形式为 z t = λ t z 0 + σ t ϵ z_t = \lambda_t z_0 + \sigma_t \epsilon zt=λtz0+σtϵ,其中 σ t = 1 − λ t 2 \sigma_t = \sqrt{1 - \lambda_t^2} σt=1−λt2 , λ t \lambda_t λt 和 σ t \sigma_t σt 是控制扩散过程的超参数。在本文中,我们选择 AnimateDiff 19 作为基础视频扩散模型。
4. Method
给定一张主体的照片,我们的目标是训练一个模型,该模型能够提取主体的外观并生成相同主体的视频。此外,在更换主体时,该模型不需要重新训练。我们在第 4.1 节讨论了方法的关键思想,并在第 4.2 节详细说明了如何利用 VDM 的内在能力来提取主体特征并使 VDM 学习主体。在第 4.3 节中,我们介绍了所提出的训练策略,以更好地区分参考信息与生成内容。此外,我们在第 4.4 节中补充了有关训练和推理的细节。
4.1. Explore Video Diffusion Model
为了实现定制化视频生成,需要解决两个核心问题:主体特征提取和特征注入。在主体特征提取方面,一些工作采用跨模态对齐模型,例如 CLIP 50。然而,由于其训练任务的限制,这些模型仅能生成粗粒度特征,无法细致地捕捉主体的外观。一些研究尝试训练 ReferenceNet,但这显著增加了训练开销。我们提出了一种新方法,利用预训练的 VDM 进行主体特征提取。当将主体参考图像直接输入 VDM 且不添加噪声时,可以将其视为 t = 0 t=0 t=0 时 VDM 的特殊情况。因此,VDM 能够准确地处理并提取无噪声参考图像的特征。这种方法不仅能够在不增加额外训练开销的情况下提取细粒度主体特征,还能减少所提取特征与 VDM 内在知识之间的域差异。
在特征注入方面,空间交叉注意力通常用于 VDM 在图像和文本之间的跨模态交互。受这种设计的影响,现有方法启发式地采用交叉注意力来注入主体特征。然而,VDM 中的空间自注意力主要用于建模帧内像素之间的关系。在定制化视频生成中,一个关键目标是确保主体"出现在"帧中。因此,在构建帧内像素关系时注入主体特征是一种更直接的方法。此外,空间自注意力能够选择性地与这些特征交互,从而有助于提升生成视频的多样性。受益于 VDM 自身执行的特征提取,我们可以直接利用 VDM 的内在空间自注意力建模能力来实现更直接的信息交互。
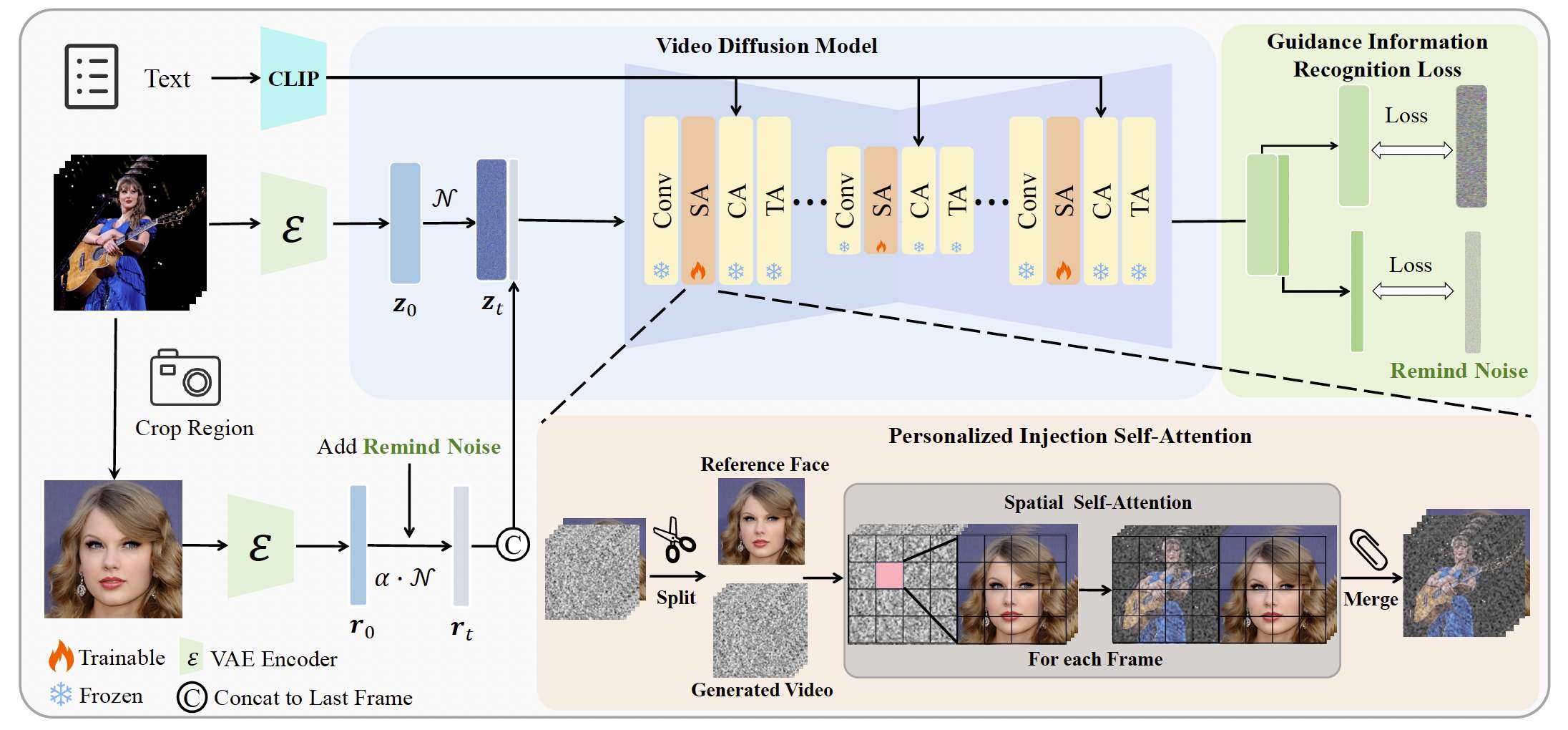
图3. VideoMaker 的整体流程。我们将参考图像直接输入 VDM,并利用 VDM 的模块进行细粒度特征提取。同时,我们修改了空间自注意力的计算方式以实现特征注入。此外,为了区分参考特征与生成内容,我们设计了引导信息识别损失(Guidance Information Recognition Loss)来优化训练策略。
4.2. Personalized Injection Self Attention
主体特征提取。与以往的方法不同,我们利用 VDM 的现有网络结构来实现这一点,即基于单元的 VDM 中的 Resblock。如图3所示,给定一个视频 x x x,它被编码到潜在空间中并加噪得到 z t ∈ R F × H × W × C z_t \in \mathbb{R}^{F \times H \times W \times C} zt∈RF×H×W×C。同时,对于特定主体的参考图像 R R R,我们首先通过 VAE 编码参考图像 R R R,在不添加噪声的情况下获得 r r r。然后我们将编码后的参考图像潜在空间 r r r 与 z t z_t zt 沿帧维度进行拼接,得到 z t ′ ∈ R ( F + 1 ) × H × W × C z_t' \in \mathbb{R}^{(F+1) \times H \times W \times C} zt′∈R(F+1)×H×W×C,作为模型的实际输入。接下来,我们使用 Resblock 作为特征提取器,从 z t ′ z_t' zt′ 中提取特征,得到输入 f ∈ R ( F + 1 ) × h × w × c f \in \mathbb{R}^{(F+1) \times h \times w \times c} f∈R(F+1)×h×w×c,供空间自注意力层使用。然后我们将特征 f f f 分离,得到对应于生成视频的噪声部分 f z ∈ R F × h × w × c f_z \in \mathbb{R}^{F \times h \times w \times c} fz∈RF×h×w×c,以及对应于参考信息的部分 f r ∈ R 1 × h × w × c f_r \in \mathbb{R}^{1 \times h \times w \times c} fr∈R1×h×w×c。至此,我们完成了针对特定主体的特征提取。
主体特征注入。在提取到特定主体特征后,接下来需要将这些特征注入到 VDM 中。对于 f z f_z fz 中的每一帧 f z i f_z^i fzi,在计算空间自注意力之前,它会被转换为 h × w h \times w h×w 个 tokens。我们将 f r f_r fr 与 f z i f_z^i fzi 拼接,使得每帧的空间自注意力输入变为 2 × h × w 2 \times h \times w 2×h×w 个 tokens。我们将这些 tokens 记为 X X X。然后,我们通过空间自注意力来融合这些信息:
X ′ = Attention ( Q , K , V ) = Softmax ( Q K ⊤ d ) V (2) X' = \text{Attention}(Q,K,V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V \tag{2} X′=Attention(Q,K,V)=Softmax(d QK⊤)V(2)
其中 X ′ X' X′ 表示输出的注意力特征, Q , K , V Q, K, V Q,K,V 分别表示查询、键和值矩阵。具体来说, Q = X W Q , K = X W K , V = X W V Q = XW_Q, K = XW_K, V = XW_V Q=XWQ,K=XWK,V=XWV。 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 分别是对应的投影矩阵, d d d 是键特征的维度。在计算注意力后,我们将输出注意力特征 X ′ X' X′ 分离为 f z ′ f_z' fz′ 和 f r ′ f_r' fr′。由于 f r ′ f_r' fr′ 被重复 F F F 次,我们对 F F F 个对应结果取平均,作为最终的 f r ′ f_r' fr′。最后,我们将得到的 f r ′ f_r' fr′ 与 f z ′ f_z' fz′ 拼接,得到更新后的 f ′ f' f′,并将其输入到后续的模型层进行进一步处理。
4.3. Guidance Information Recognition Loss
由于我们框架的实际输入 z t ′ z_t' zt′ 相比于公式 (1) 的输入多了一帧,因此输出 ϵ θ ∈ R ( F + 1 ) × H × W × C \epsilon_\theta \in \mathbb{R}^{(F+1)\times H \times W \times C} ϵθ∈R(F+1)×H×W×C 也相对于公式 (1) 的输出多了一帧。一个直接的训练目标是去掉对应参考信息 r r r 的输出,只对剩余帧计算损失。这种方法鼓励模型专注于学习带有指定主体的定制化视频生成。然而,我们在实验中发现,如果对参考信息没有监督,模型会难以准确识别参考信息 r r r 是一张未加噪声的图像,从而导致生成结果不稳定。为了解决这个问题,我们引入了引导信息识别损失(Guidance Information Recognition Loss),用于对参考信息进行监督,使模型能够准确区分参考信息与生成内容,从而提升定制化生成的质量。具体来说,在训练过程的时间步 t t t,我们为参考信息 r r r 添加一个提醒噪声:
r t = λ t ′ r + 1 − λ t ′ 2 ϵ , (3) r_t = \lambda_{t'} r + \sqrt{1 - \lambda_{t'}^2}\,\epsilon, \tag{3} rt=λt′r+1−λt′2 ϵ,(3)
其中 t ′ = α ⋅ t t' = \alpha \cdot t t′=α⋅t, α \alpha α 是一个手动设置的超参数。
为了防止加入的噪声严重破坏参考信息, α \alpha α 被设置为一个较小的值,以确保提醒噪声保持在最小水平。在计算损失函数时,我们还会像公式 (1) 那样对参考信息 r r r 计算损失:
L r e g = E r , c , ϵ ∼ N ( 0 , I ) , t ∥ ϵ − ϵ θ ( r t , c t e x t , t ) ∥ 2 2 . (4) \mathcal{L}{reg} = \mathbb{E}{r,c,\epsilon \sim \mathcal{N}(0,I),t} \Big \\lVert \\epsilon - \\epsilon_\\theta(r_t, c_{text}, t) \\rVert_2\^2 \\Big. \tag{4} Lreg=Er,c,ϵ∼N(0,I),t∥ϵ−ϵθ(rt,ctext,t)∥22.(4)
我们将 L r e g \mathcal{L}_{reg} Lreg 作为辅助优化目标,与主要目标结合起来,引导模型的训练:
L = L v i d e o + β ⋅ L r e g , (5) \mathcal{L} = \mathcal{L}{video} + \beta \cdot \mathcal{L}{reg}, \tag{5} L=Lvideo+β⋅Lreg,(5)
其中 β \beta β 是一个超参数。为了避免干扰主要的定制化视频生成任务的优化, β \beta β 被选择为一个相对较小的值。
4.4. Training and Inference Paradigm
训练。我们框架的简洁设计使得在训练过程中无需额外的主体特征提取器。由于我们只是调整了输入 tokens 的数量到模型原有的空间自注意力层,将主体信息注入 VDM 并不会增加参数量。我们假设预训练 VDM 中的 ResBlock 已经足够提取参考图像中的特征信息。因此,我们的模型只需要在训练过程中微调原始 VDM 的空间自注意力层,同时冻结其余部分的参数。此外,为了使时序注意力能够更好地区分参考信息与生成视频,我们建议在训练时同步微调 motion block 的参数。即使不微调 motion block,该方法也能实现定制化视频生成。我们还会在训练阶段随机丢弃图像条件,以便在推理阶段实现无分类器引导(classifier-free guidance):
ϵ ^ θ ( z t , c t , r , t ) = w ϵ θ ( z t , c t , r , t ) + ( 1 − w ) ϵ θ ( z t , t ) . (6) \hat{\epsilon}\theta(z_t, c_t, r, t) = w \epsilon\theta(z_t, c_t, r, t) + (1-w)\epsilon_\theta(z_t, t). \tag{6} ϵ^θ(zt,ct,r,t)=wϵθ(zt,ct,r,t)+(1−w)ϵθ(zt,t).(6)
推理。在推理过程中,对于模型的输出,对应参考信息的输出会被直接丢弃。此外,虽然我们在训练时对主体参考图像添加了轻微噪声,以显式帮助模型区分引导信息,但在推理过程中我们选择去除参考图像的噪声添加。这保证了生成的视频不会受到噪声影响,从而保持输出的质量与稳定性。