Wan2.1文生视频实战部署-Gradio篇
-
- [一、Wan2.1 初体验](#一、Wan2.1 初体验)
- 二、Wan2.1文生视频实战
-
- [1 WebUI界面部署](#1 WebUI界面部署)
- [2 LoRA模型的应用](#2 LoRA模型的应用)
- [3 脚本中各项参数的使用](#3 脚本中各项参数的使用)
一、Wan2.1 初体验
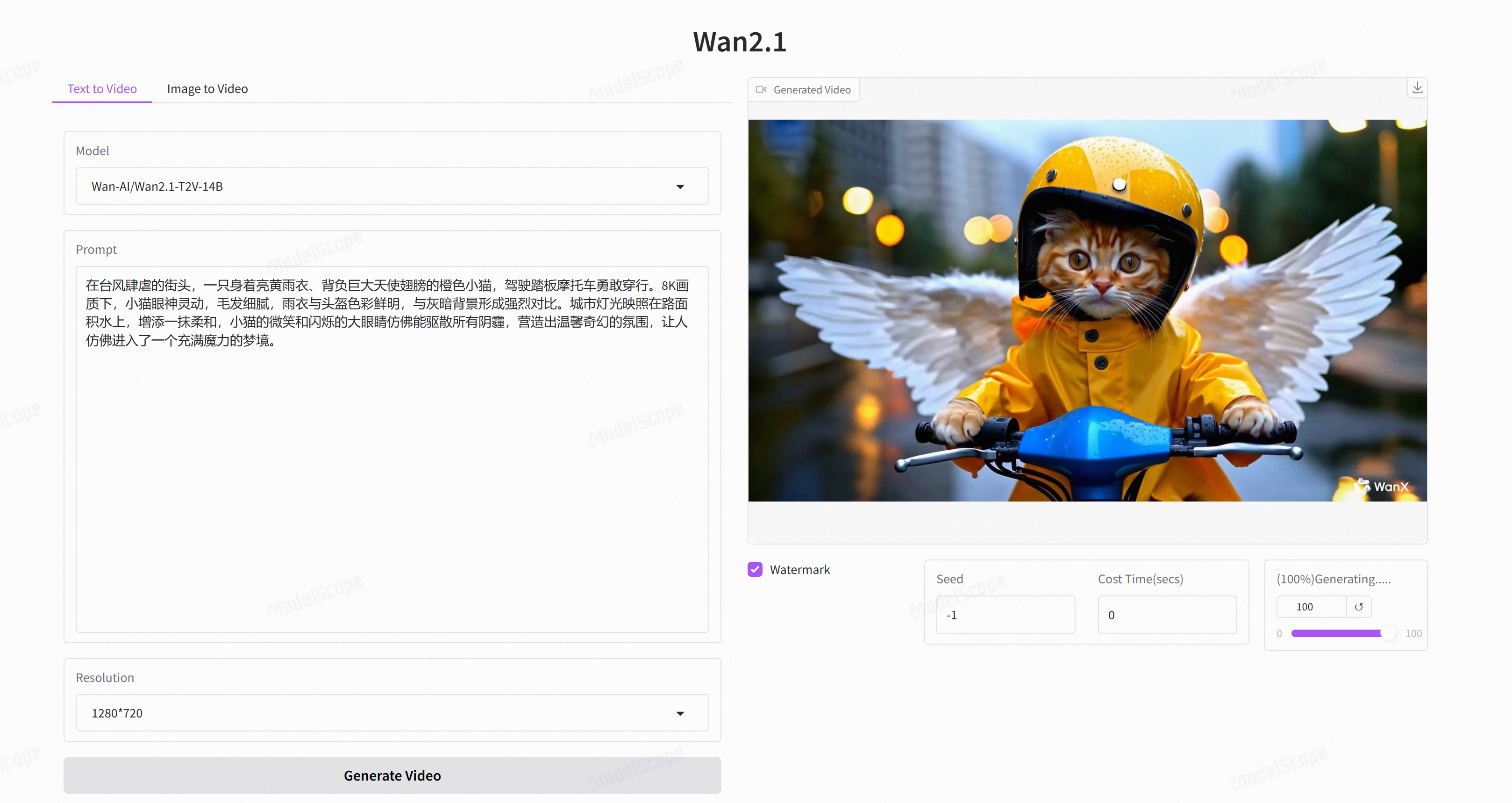
魔搭社区创空间的体验Demo:https://modelscope.cn/studios/ybh618/Wan-2.1
二、Wan2.1文生视频实战
1 WebUI界面部署
为了提供更好的体验,本文介绍如何使用魔搭社区的免费GPU给自己部署一个独占算力通道的WebUI界面玩转Wan2.1文生视频模型。
-
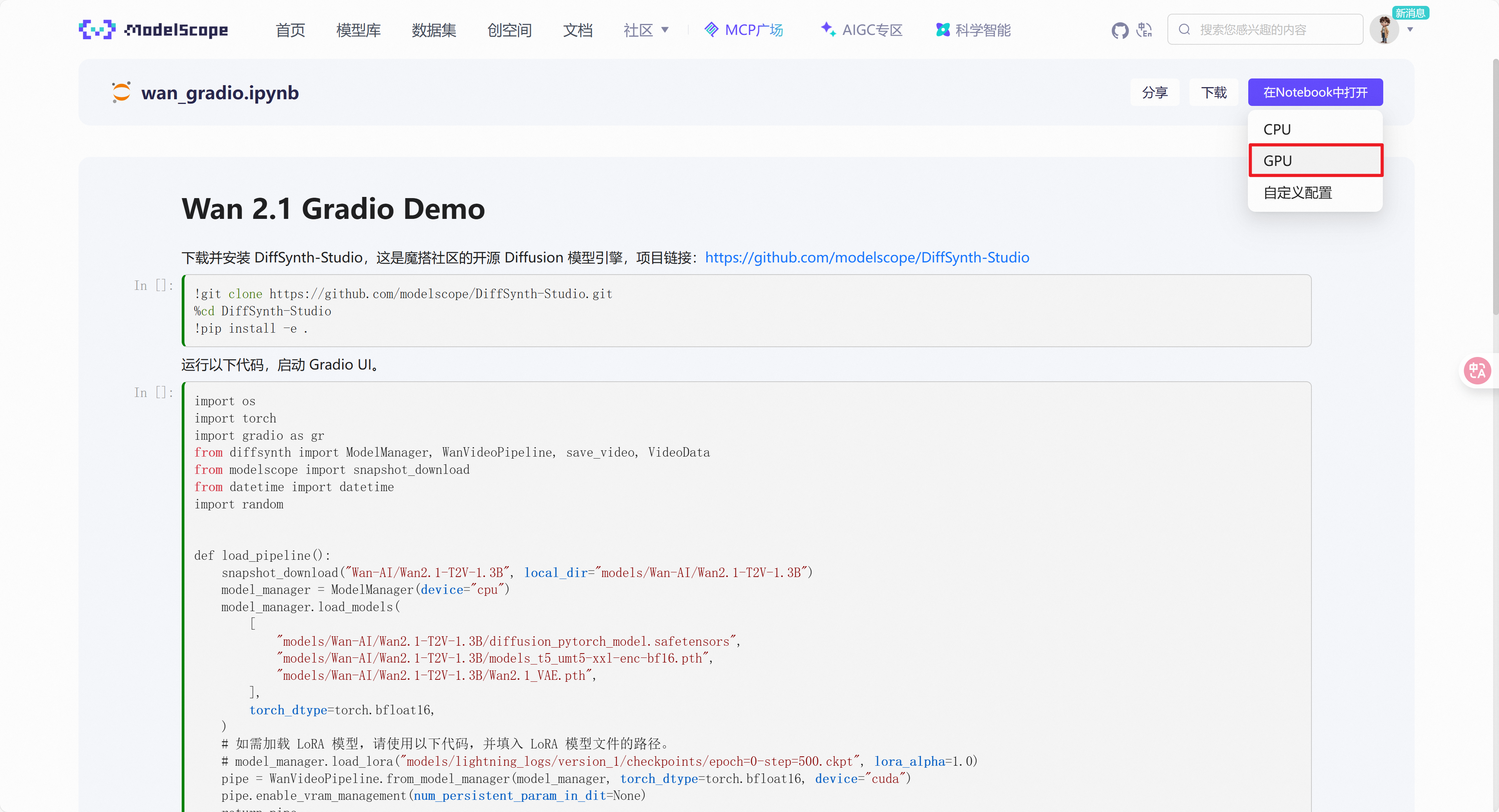
以下链接直达脚本教程:https://modelscope.cn/notebook/share/ipynb/f548cee3/wan_gradio.ipynb
-
在Notebook中打开,选择使用GPU打开
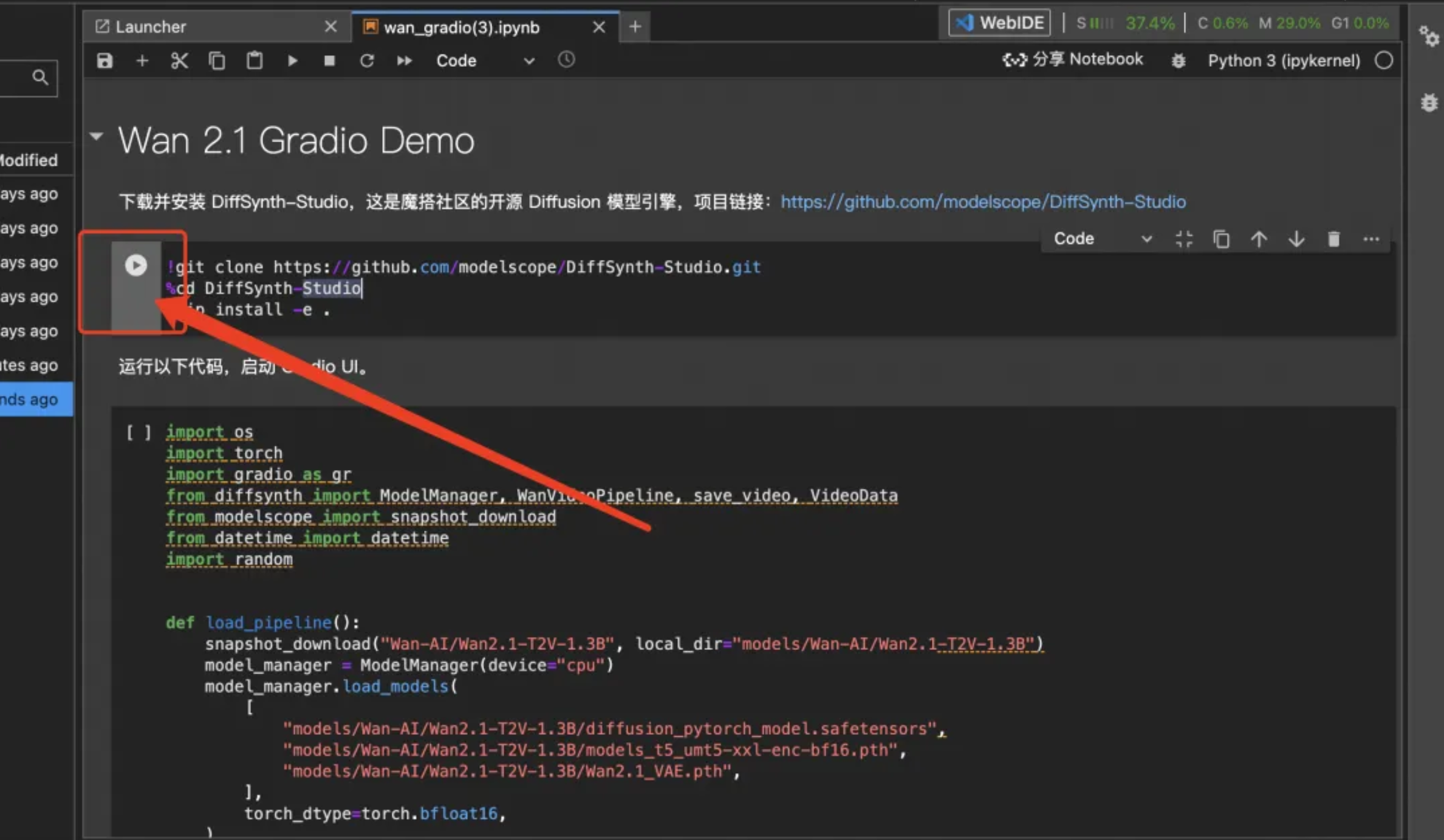
3.进入到notebook页面,按顺序执行提供的脚本教程
- 点击链接进入网站(建议使用谷歌浏览器,兼容性较好)
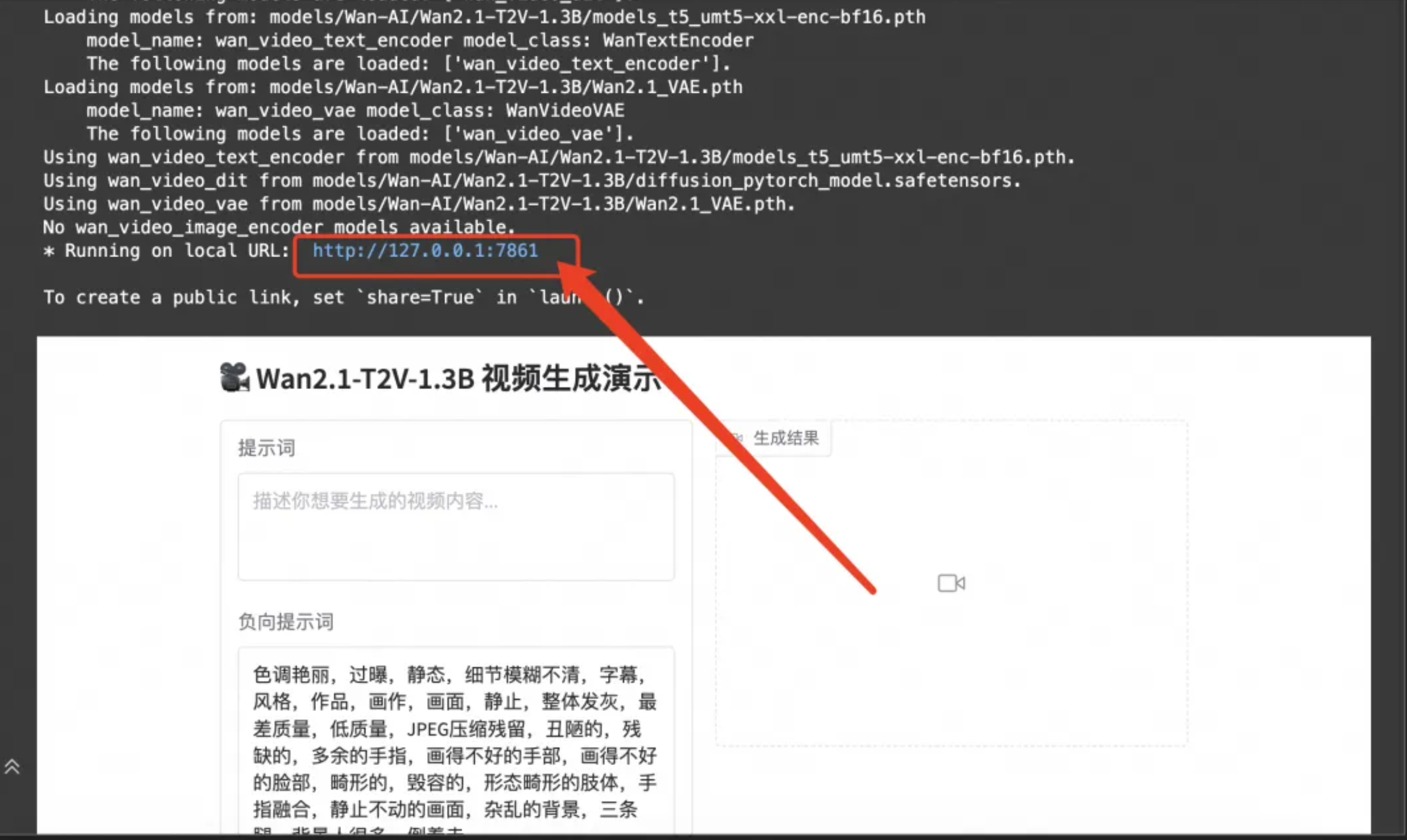
- 这就完成了在魔搭免费GPU算力中部署一个WebUI,独享算力通道玩转Wan2.1 文生视频模型啦!
2 LoRA模型的应用
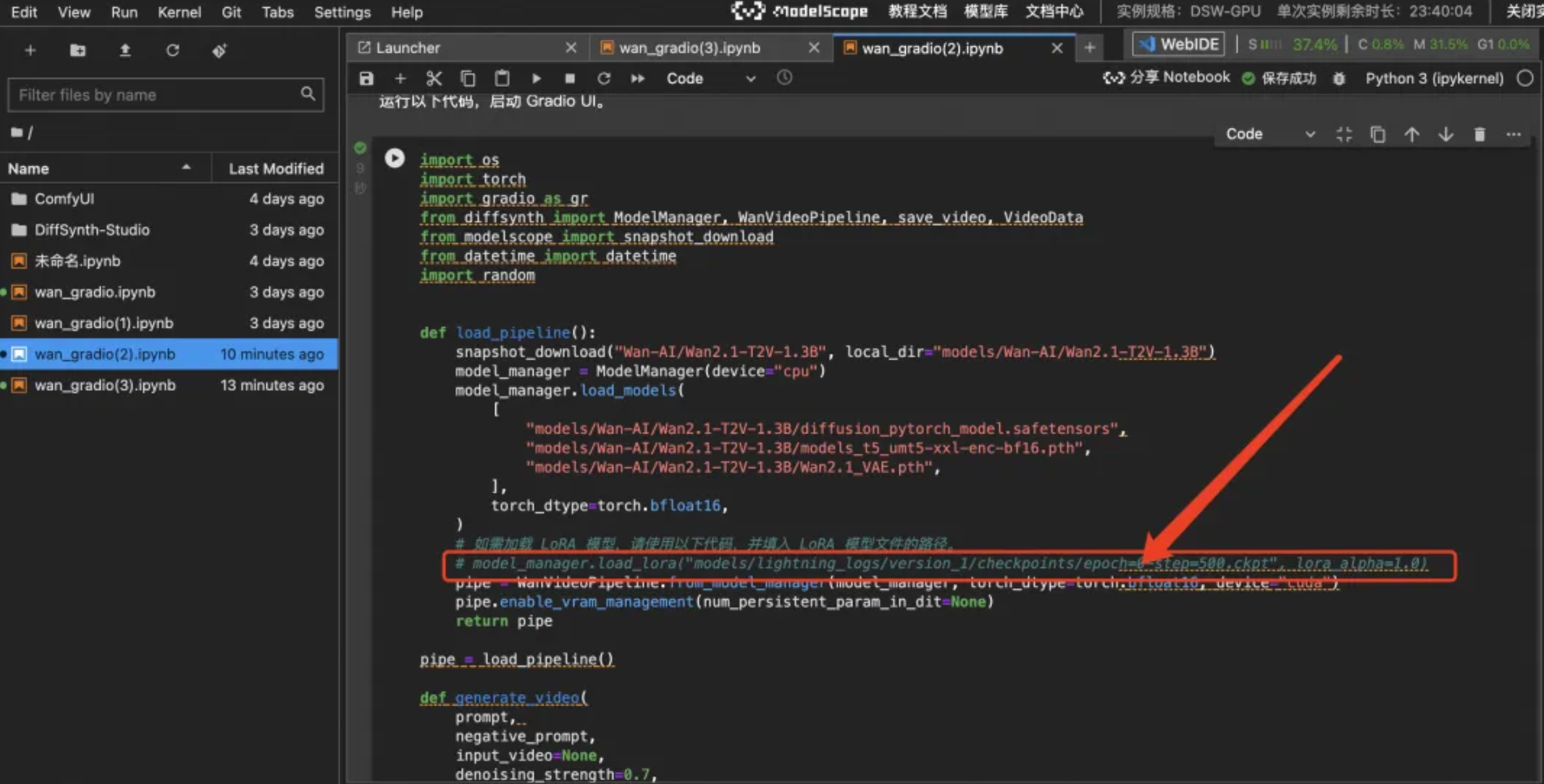
- 如果已有LoRA文件,将其放在
DiffSynth-Studio/models/lora/文件夹里。 - 再次点击运行。
- 重复文生视频的操作。
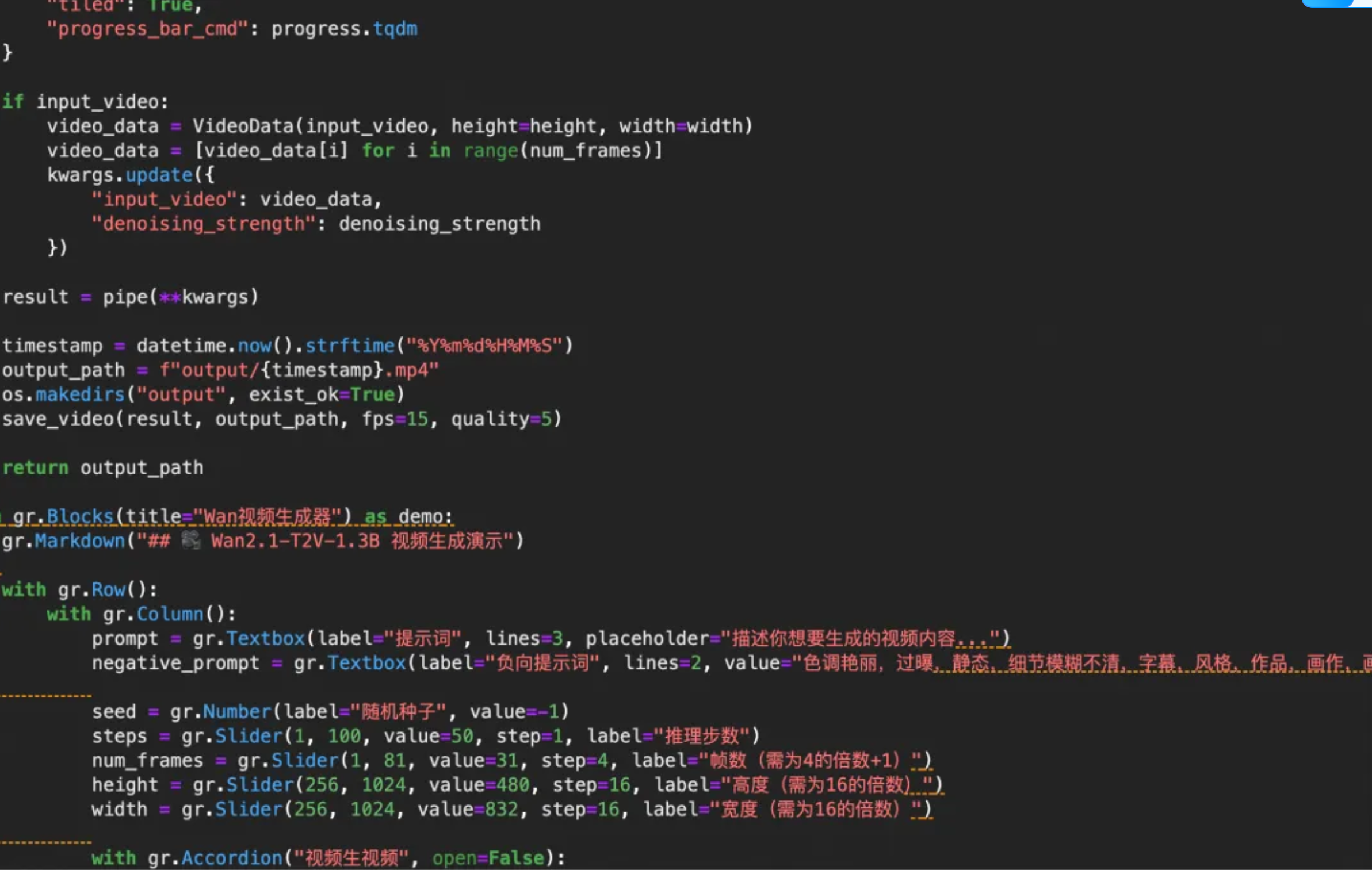
3 脚本中各项参数的使用
-
下载并安装
DiffSynth-Studio,这是魔搭社区的开源Diffusion模型引擎项目链接: https://github.com/modelscope/DiffSynth-Studio
bashgit clone https://github.com/modelscope/DiffSynth-Studio.git cd DiffSynth-Studio pip install -e .
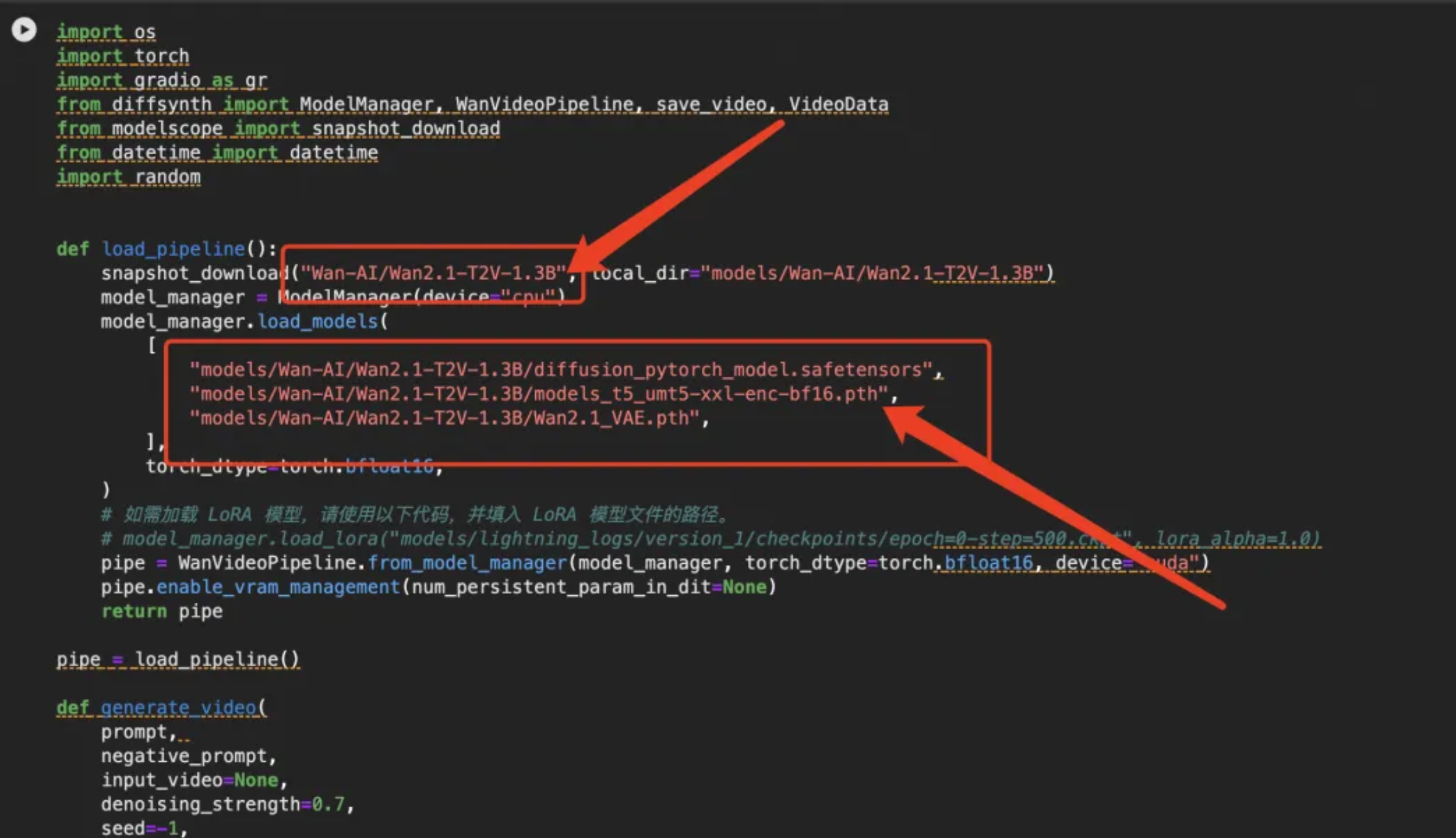
2. wan2.1-t2v-1.3b文生视频模型包含3个组件:文本编码器、扩散模型和视频解码器。需要从魔搭模型库中下载3个组件对应的模型文件,并将这些模型文件放置到对应文件夹:
- 文本编码器:
models/Wan-AI/Wan2.1-T2V-1.3B/diffusion_pytorch_model.safetensors - 扩散模型:
models/Wan-AI/Wan2.1-T2V-1.3B/models_t5_umt5-xxl-enc-bf16.pth - 视频解码器:
models/Wan-AI/Wan2.1-T2V-1.3B/Wan2.1_VAE.pth
如果需要更换14b的模型,在截图下更改模型即可
下面就是一些gradio界面代码了,大家可以对照界面参考一下