点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到: Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Kafka集群监控方案
- JConsole
- Kafka Eagle
- JavaAPI获取集群指标

简单介绍
在技术的不断迭代中,一路发展,三代技术引擎:
- MapReduce 昨天
- Spark 今天
- Flink 未来
MapReduce和Spark都是类MR的处理引擎,底层原理非常相似。
什么是Spark
Spark的发展历程如下图: 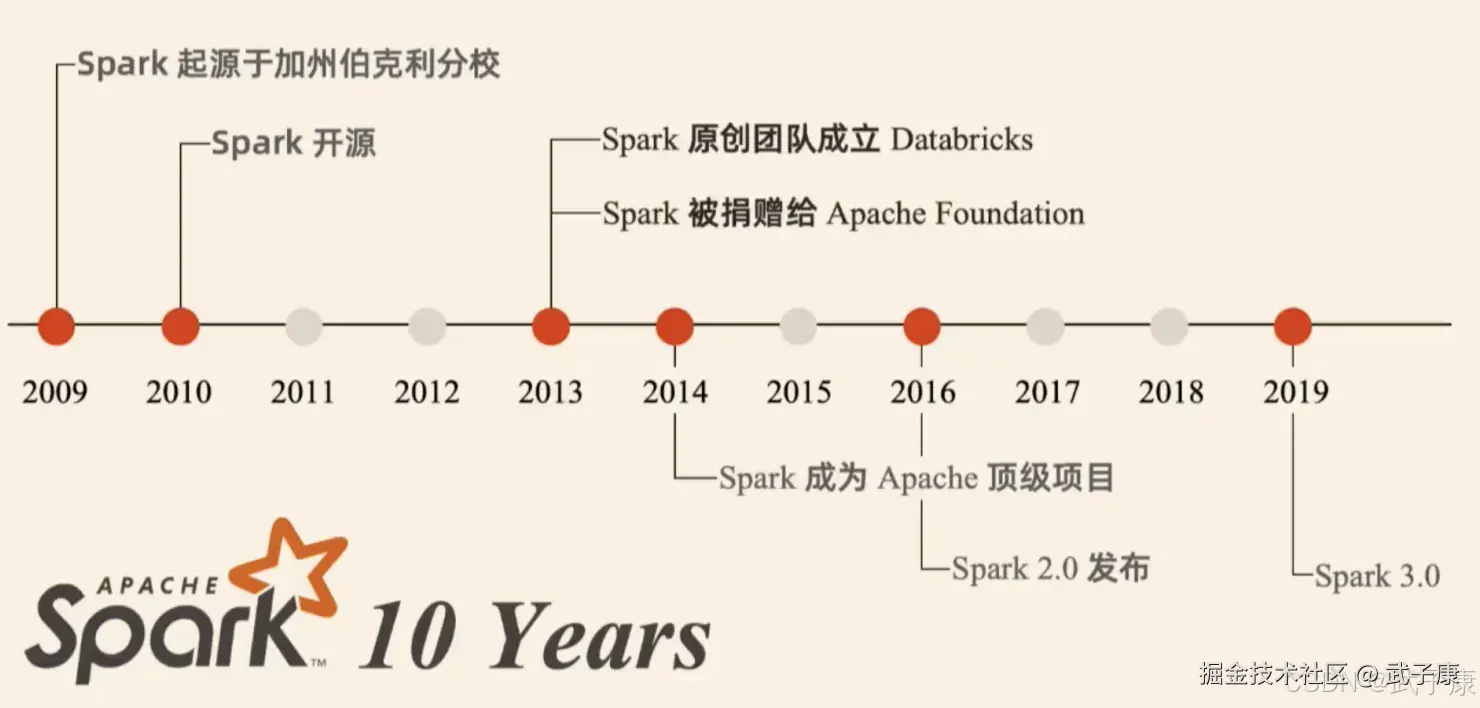
Spark核心特点详解
1. 卓越的性能优势
执行速度:Spark通过内存计算(In-Memory Computing)实现了惊人的性能提升。在内存充足的情况下,Spark比传统MapReduce快100倍以上;即使基于磁盘的运算,速度也能快10倍左右。例如,在100GB数据排序测试中,Spark仅需23分钟,而Hadoop需要72分钟。
执行引擎:Spark采用先进的DAG(有向无环图)执行引擎,通过以下方式优化计算:
- 自动优化任务调度
- 减少不必要的中间结果写入磁盘
- 支持流水线式操作(pipelining)
- 实现内存缓存机制(RDD persistence)
特别适合迭代式算法(如机器学习)和交互式数据分析场景。
2. 极佳的易用性
多语言支持:
- Scala(原生语言,API最完整)
- Java(适合企业级开发)
- Python(通过PySpark提供完整支持)
- R(通过SparkR提供支持)
丰富的算法库:内置超过80个高级算法,包括:
- 机器学习算法(分类、回归、聚类等)
- 图算法(PageRank、连通分量等)
- 统计分析工具
- SQL查询功能
交互式Shell:提供REPL(Read-Eval-Print Loop)环境:
- Spark-shell(Scala)
- PySpark(Python)
- SparkR(R语言) 用户可以直接在命令行与集群交互,快速验证想法。
3. 统一的生态系统
一站式解决方案:
- Spark Core:基础计算引擎
- Spark SQL:结构化数据处理(兼容HiveQL)
- Spark Streaming:微批处理的实时计算
- MLlib:分布式机器学习库
- GraphX:图计算框架
应用场景示例:
-
电商平台可以同时实现:
- 用户行为分析(批处理)
- 实时推荐系统(流处理)
- 用户画像建模(机器学习)
- 社交网络分析(图计算)
-
金融风控系统可以:
- 处理历史交易数据(批处理)
- 监控实时交易(流处理)
- 训练反欺诈模型(机器学习)
4. 出色的兼容性
资源管理支持:
- Hadoop YARN(最常用)
- Apache Mesos
- Standalone模式(内置调度器)
数据源兼容:
- Hadoop生态系统:HDFS、HBase、Hive等
- NoSQL数据库:Cassandra、MongoDB等
- 云存储:AWS S3、Azure Blob Storage等
- 消息队列:Kafka、Flume等
部署优势:
- 无需数据迁移即可使用现有Hadoop集群
- Standalone模式只需在机器上安装Spark即可运行
- 支持Kubernetes调度(Spark 2.3+)
- 与现有BI工具(Tableau、PowerBI等)无缝集成
特别是在混合云环境中,Spark可以统一处理:
- 本地HDFS数据
- 云端对象存储数据
- 实时流数据源
Spark与Hadoop
狭义上
从狭义上看:Hadoop是一个分布式框架,由存储、资源调度、计算三部分组成 Spark是一个分布式计算引擎,是由Scala编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎。
广义上
从广义上看:Spark是Hadoop生态中不可或缺的一部分。
MapReduce不足
- 表达能力有限
- 磁盘IO开销大
- 延迟高:任务之间有IO开销,在前一个任务完成之前,另一个任务无法开始。
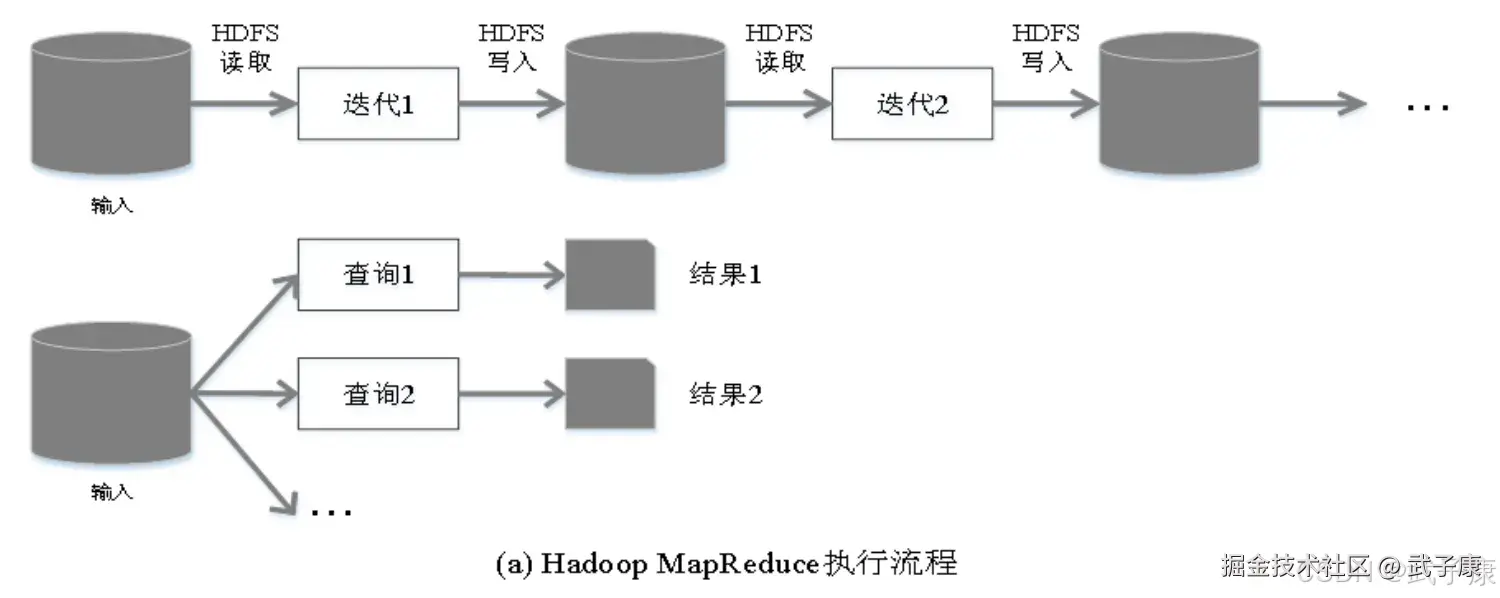 相对于Spark,Spark的设计要更高效,Spark在借鉴MapReduce优点的同时,很好的解决了MapReduce所面临的问题:
相对于Spark,Spark的设计要更高效,Spark在借鉴MapReduce优点的同时,很好的解决了MapReduce所面临的问题: 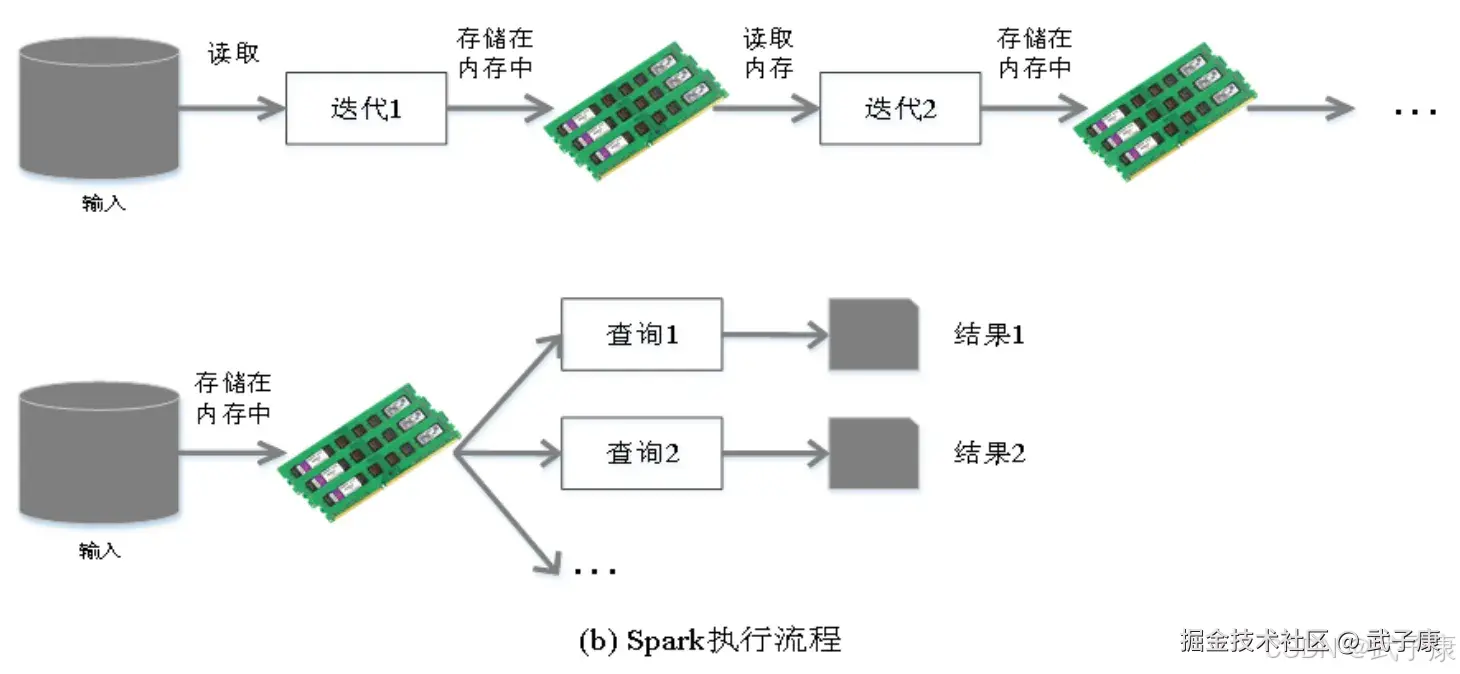
两者对比
Spark的计算模式也属于MapReduce,是对MR框架的优化。
- 数据存储结构:MapReduce是磁盘HDFS,Spark是内存构建的弹性分布式数据集RDD
- 编程范式:Map+Reduce表达力欠缺,Spark提供了丰富操作使数据处理代码很短
- 运行速度:MapReduce计算中间结果存磁盘,Spark中间结果在内存中
- 任务速度:MapReduce任务以进程,需要数秒启动,Spark是小数据集读取在亚秒级
大数据处理技术的实际应用与挑战
数据处理场景分类
1. 批量处理(离线处理)
时间跨度:通常在几分钟到数小时之间 典型特征:
- 处理大规模历史数据
- 对实时性要求不高
- 高吞吐量优先 应用示例:
- 电商平台每日销售报表生成
- 银行夜间批量结算处理
- 社交媒体月度用户行为分析
2. 交互式查询
时间跨度:通常在十秒到数十分钟之间 典型特征:
- 需要快速响应查询请求
- 支持复杂分析查询
- 数据量中等规模 应用示例:
- 商业智能仪表盘数据查询
- 客户行为实时分析
- 运营数据即时统计
3. 流处理(实时处理)
时间跨度:通常在数百毫秒到数秒之间 典型特征:
- 持续不断的数据流输入
- 低延迟处理要求
- 事件驱动处理模式 应用示例:
- 金融交易实时监控
- 物联网设备数据处理
- 网站点击流实时分析
主流技术解决方案
批量处理方案
- MapReduce :经典的分布式计算框架
- 运行在Hadoop生态系统中
- 采用分而治之的思想
- 适用于大规模数据并行处理
- 示例:日志分析、ETL处理
交互式查询方案
- Hive :基于Hadoop的数据仓库工具
- 提供类SQL查询接口(HQL)
- 适合结构化数据分析
- 示例:数据仓库查询、报表生成
- Impala :实时查询引擎
- 比Hive更快的查询响应
- 直接访问HDFS数据
- 示例:即席查询、交互式分析
流处理方案
- Storm :分布式实时计算系统
- 处理无界数据流
- 支持多种编程语言
- 示例:实时推荐系统、异常检测
现有技术架构的挑战
1. 数据共享障碍
- 不同系统使用不同的数据存储格式
- MapReduce通常使用SequenceFile
- Hive使用列式存储格式(如ORC, Parquet)
- Storm处理原始数据流
- 数据转换带来的开销
- 需要额外的ETL处理步骤
- 转换过程可能造成数据丢失或失真
- 增加存储空间需求
2. 系统维护复杂性
- 多技术栈并存
- 需要掌握MapReduce、HiveQL、Storm等多种编程模式
- 不同系统的配置和管理方式各异
- 团队协作成本高
- 需要专门的批量处理团队、查询团队和流处理团队
- 团队间沟通协调成本增加
3. 资源管理难题
- 资源分配不均衡
- 流处理需要保证低延迟,占用固定资源
- 批量处理可以容忍资源波动
- 难以实现动态资源调配
- 集群利用率低
- 不同系统资源需求高峰不同
- 难以实现资源共享和负载均衡
- 常出现部分资源闲置而其他资源紧张的情况
这些挑战促使了新一代统一数据处理框架(如Spark、Flink)的发展,它们试图在一个平台上解决上述所有问题。
系统架构
Spark运行包括如下:
- Cluster Manager
- Worker Node
- Driver
- Executor
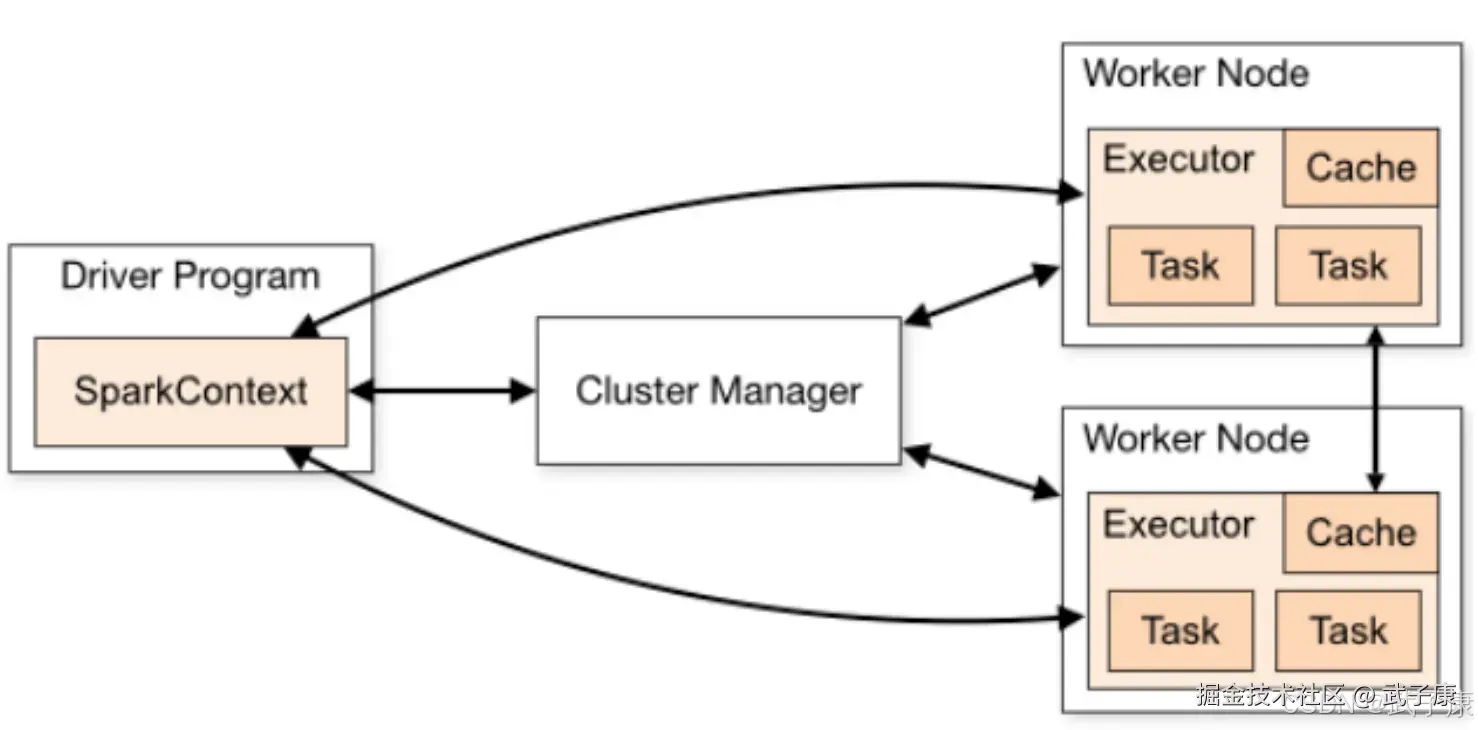
ClusterManager
ClusterManager 是集群资源的管理者,Spark支持3中集群部署模式:
- Standalone
- YARN
- Mesos
WorkerNode
WorkerNode是工作节点,负责管理本地资源。
Driver Program
运行应用的 main() 方法并且创建了 SparkContext。由ClusterManager分配资源,SparkContext发送Task到Executor上执行。
Executor
Executor在工作节点上运行,执行Driver发送的Task,并向Driver汇报计算结果。
部署模式
Standalone
- 独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖其他任何的资源管理系统,从一定程度上说,该模式是其他模式的基础
- Cluster Manager: Master
- WorkerNode:Worker
- 仅支持粗粒度的资源分配方式
SparkOnYARN
- YARN拥有强大的社区支持,且逐步成为大数据集群资源管理系统的标准
- 在国内生产环境中运用最广泛的部署模式
- SparkOnYARN 支持的两种模式:yarn-cluster(生产环境),yarn-client(交互和调试)
- Cluster Manager:ResourceManager
- WorkNode:NodeManager
- 仅支持粗粒度的资源分配方式
SparkOnMesos
- 官方推荐模式,Spark开发之初就考虑到了支持Mesos
- Spark运行在Mesos上会更加的灵活,更加自然
- ClusterManager:MesosMaster
- WorkNode: MesosSlave
- 支持粗粒度、细粒度的资源分配方式
粗粒度模式
Coarse-grained Mode:每个程序的运行由一个Driver和若干个Executor组成,其中每个Executor占用若干资源,内部可以运行多个Task。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中需要一直占用着这些资源,即使不用,最后程序运行结束后,自动回收这些资源。
细粒度模式
鉴于粗粒度模式造成的大量资源的浪费,SparkOnMesos还提供了另一个调度模式就是细粒度模式。 这种模式类似于现在的云计算思想,核心是按需分配。
如何选择
- 生产环境中原则YARN,国内使用最广的模式
- Spark的初学者,Standalone模式,简单
- 开发测试环境可选Standalone
- 数据量不太大、应用不复杂,可使用Standalone
相关术语详解
Application
Application是指用户提交的Spark应用程序,它由集群中的一个Driver程序和多个Executor组成。一个完整的Spark应用通常包括:
- 数据输入(如HDFS、Kafka等)
- 数据处理逻辑
- 数据输出(如数据库、文件系统等)
示例场景:一个电商网站的实时推荐系统就是一个Spark Application,它从用户行为日志中读取数据,进行实时分析处理,最后输出推荐结果。
ApplicationJAR
ApplicationJAR是包含用户Spark应用程序代码的JAR包,需要注意:
- 必须包含所有用户自定义的类和依赖
- 不应包含Spark或Hadoop的相关JAR(这些由集群提供)
- 通常通过
spark-submit命令的--jars参数提交
最佳实践:使用Maven或SBT构建工具来正确管理依赖关系,避免JAR包冲突。
DriverProgram
Driver程序是Spark应用的控制中心,负责:
- 解析用户代码
- 创建SparkContext(Spark应用的入口点)
- 将用户程序转换为DAG(有向无环图)
- 调度任务到Executor执行
- 收集计算结果
ClusterManager
ClusterManager负责管理集群资源,主流类型包括:
- Standalone模式:Spark自带的简单集群管理器
- YARN:Hadoop的资源管理器
- 适用于已部署Hadoop的环境
- 支持动态资源分配
- Mesos:通用的集群资源管理器
- 可以同时运行多种框架
- 提供细粒度和粗粒度两种调度模式
DeployMode
部署模式决定了Driver运行的位置:
- Cluster模式 :
- Driver在集群内部运行(由某个Worker节点托管)
- 适合长时间运行的作业
- 客户端可以断开连接而不影响作业运行
- Client模式 :
- Driver在提交应用的客户端机器上运行
- 适合交互式调试
- 客户端必须保持连接状态
Worker Node
Worker节点是集群中的工作机器,主要职责:
- 运行Executor进程
- 向Master汇报心跳
- 执行分配的任务
- 管理本地存储
Executor
Executor是运行在Worker节点上的进程,每个应用都有独立的Executor,主要功能:
- 执行分配给它的Task
- 缓存数据(通过BlockManager)
- 通过心跳向Driver汇报状态
- 每个Executor有固定的CPU核心和内存资源
最佳实践:通常建议配置多个Executor而不是单个大型Executor,以提高容错能力。
Task
Task是Spark中最小的执行单元,特点包括:
- 对应RDD的一个分区
- 由Executor执行
- 包含用户定义的操作(如map、filter等)
- 执行结果会返回给Driver或写入外部存储
Job
Job由Spark中的Action操作触发产生,特点:
- 每个Action(如collect、count、save等)都会产生一个Job
- 一个应用可能包含多个Job
- 按顺序执行(除非使用异步API)
示例:rdd.count()会触发一个Job来计算RDD中的元素数量。
Stage
Stage是Job的组成部分,划分依据:
- 根据shuffle操作划分边界
- 每个Stage包含一组可以并行执行的Task
- 分为两种类型:
- ShuffleMapStage(中间结果需要shuffle)
- ResultStage(最终结果)
例如:一个包含map和reduceByKey操作的Job会被划分为两个Stage,map操作在第一个Stage,reduceByKey在第二个Stage。