第4章:SyncNet唇形同步评判器
在前几章中,我们了解了唇形同步推理流程如何协调生成唇形同步视频,以及音频特征提取器(Whisper)如何为LatentSync UNet提供关键音频线索。
UNet利用这些线索巧妙调整唇部动作。但我们如何判断UNet的生成效果?如果生成的唇形仍有偏差怎么办?这正是SyncNet唇形同步评判器的职责所在。
什么是SyncNet?
想象刚看完一部电影,我们需要专业评审来判断演员的唇形是否与台词完美匹配,还是略显不自然。
SyncNet 就是这样的专业评审,其核心功能是评估视频中人物唇部动作与语音的同步程度。
它如同训练有素的专家,能立即判断视频是否完美同步或存在细微偏差。
为什么需要评判器?
即使如LatentSync UNet这样的强大AI,确保完美唇形同步仍是复杂任务。SyncNet提供客观评估标准:
训练阶段:衡量UNet学习唇形同步的效果生成阶段:评估最终输出视频的唇形同步质量
工作原理
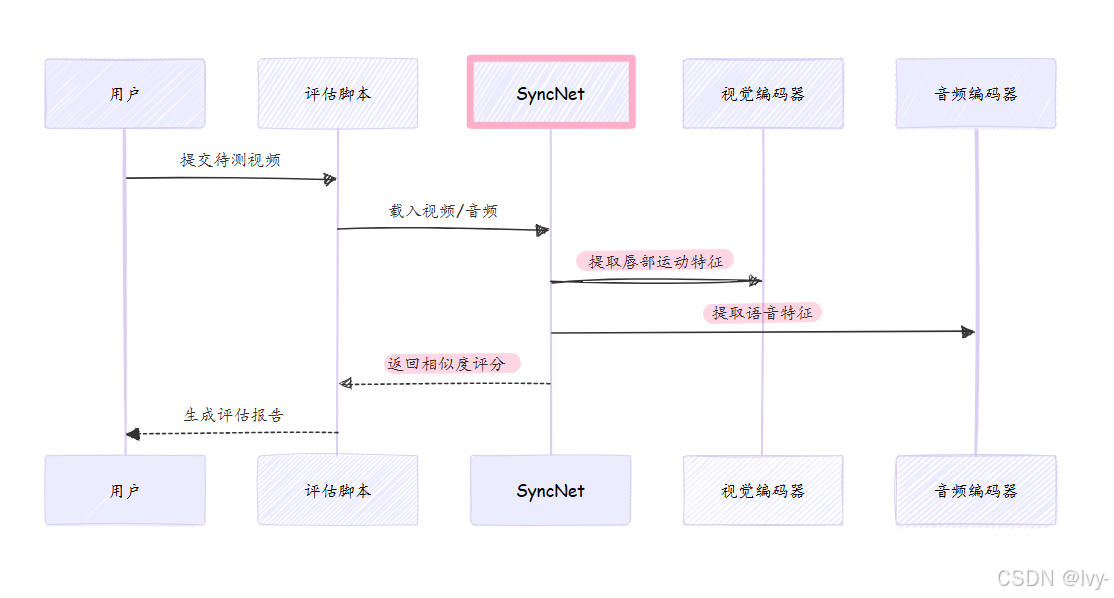
SyncNet同时接收视频帧 (面部/唇部区域)和音频,通过智能比对进行分析:
视觉编码器:处理视频帧,解析唇部动作特征,生成视觉嵌入向量(唇部运动指纹)音频编码器:处理音频,解析理想唇形运动特征,生成音频嵌入向量(理想运动蓝图)比对分析:- 若两组向量高度相似,则唇形与语音完美匹配,SyncNet给出高分
- ==若存在差异,则唇形与语音不同步,SyncNet给出低分
还可计算**"音画偏移量"**,精确量化视频超前或滞后音频的帧数
核心应用场景
-
训练监督(同步损失):- 为UNet训练提供反馈信号
- 高同步损失值促使UNet优化生成效果
- 低同步损失值表明UNet表现良好
-
生成评估(质量检测):- 对最终输出视频进行独立评分
- 例如"SyncNet置信度85%"表示优质唇形同步
- 帮助开发者量化模型效果
技术变体
| 类型 | 特点 |
|---|---|
像素空间 |
直接处理原始图像像素(如256x256面部图像) |
潜在空间 |
处理视频帧的压缩潜在表征,训练过程更高效 |
注意力机制版 |
采用注意力机制聚焦关键音频/视觉特征,提升判断精度 |
使用指南
通过命令行工具进行视频唇形同步评估:
bash
python eval/eval_sync_conf.py \
--video_path "output.mp4" \
--model_path "checkpoints/syncnet_v2.model"输出示例:
css
输入视频: output.mp4
SyncNet置信度: 0.82
音画偏移: +1帧实现解析
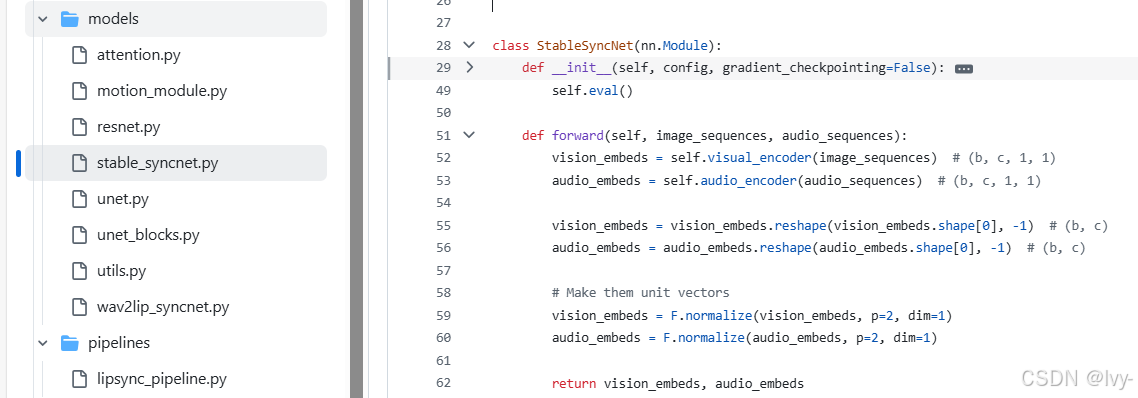
核心组件
python
class StableSyncNet(nn.Module):
def __init__(self):
self.visual_encoder = DownEncoder2D() # 视觉特征编码器
self.audio_encoder = DownEncoder2D() # 音频特征编码器
def forward(self, video_frames, audio_clip):
vis_emb = self.visual_encoder(video_frames) # 生成视觉嵌入
aud_emb = self.audio_encoder(audio_clip) # 生成音频嵌入
return F.cosine_similarity(vis_emb, aud_emb) # 返回相似度评分评估流程
总结
SyncNet通过:
双模态特征编码- 余弦相似度比对
- 多场景应用支持
为LatentSync提供可靠的唇形同步质量评估体系。下一章将介绍图像与视频处理器如何为UNet和SyncNet准备数据。
第5章:图像与视频处理器
在前几章中,我们已经了解了唇形同步推理流程这个总指挥、LatentSync UNet这位创意艺术家、音频特征提取器(Whisper)这位敏锐的听众,以及SyncNet唇形同步评判器这位严格的评论家。这些组件处理的是唇形同步的"智能"部分。
但原始视觉数据本身呢?
在任何AI模型施展魔法之前,视频帧和图像需要大量准备工作。
想象我们有一张人物肖像,但我们的特殊绘图工具(UNet)只会画嘴巴,而且需要嘴巴是特定大小并完美居中。我们需要一个团队来:
- **
定位面部**在大图中 - **
裁剪面部区域**并保留适当边缘 - **
对齐调整**确保面部始终正对 - **
尺寸标准化**调整为工具所需尺寸 - **
区域遮罩**突出嘴部区域 - **
无缝融合**将处理后的面部还原到原图
这正是LatentSync中图像与视频处理器的职责。
它们是专门处理底层视觉数据操作的工具链 ,确保图像和视频帧完美适配AI模型处理,并将结果无缝整合回最终视频。
核心功能
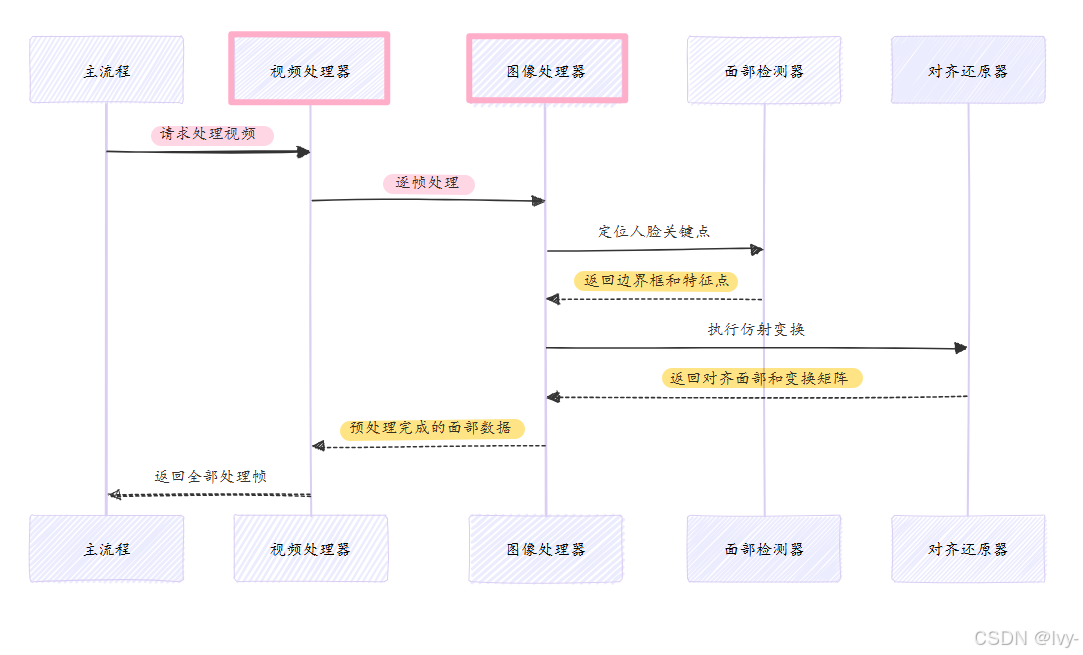
图像与视频处理器如同电影制作中的"场务团队"和"化妆师",完成以下基础但关键的工作:
面部检测:定位每帧视频中的人脸面部对齐:通过仿射变换将人脸居中标准化图像缩放:统一尺寸适配模型输入(如256x256或512x512)遮罩应用:创建特定遮罩(如嘴部遮罩)聚焦处理区域生成还原:将新生成的唇形同步面部无缝融合回原始视频
这些功能对以下环节至关重要:
- 数据预处理:为UNet和SyncNet准备训练数据
- 推理阶段:处理输入视频并整合生成结果
使用示例
开发者可通过以下方式调用视频处理器进行面部对齐:
python
from latentsync.utils.image_processor import VideoProcessor
# 初始化视频处理器(目标分辨率512px,启用GPU加速)
video_processor = VideoProcessor(resolution=512, device="cuda")
# 处理整个视频(自动进行面部检测、对齐和裁剪)
aligned_faces = video_processor.affine_transform_video("input.mp4")
# 保存处理结果
write_video("aligned_output.mp4", aligned_faces, fps=25)技术实现
核心组件协作
关键代码
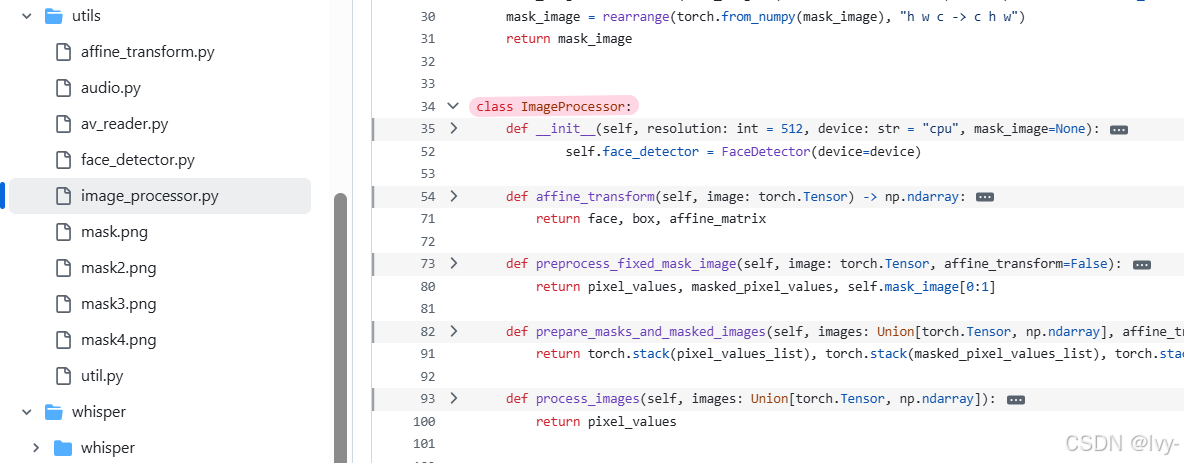
- 图像处理器(
ImageProcessor)
python
class ImageProcessor:
def __init__(self):
self.face_detector = FaceDetector() # 面部检测器
self.restorer = AlignRestore() # 对齐还原器
self.mask_image = load_fixed_mask() # 预载嘴部遮罩
def affine_transform(self, image):
# 检测面部特征点
bbox, landmarks = self.face_detector(image)
# 计算对齐变换
aligned_face, matrix = self.restorer.align_warp_face(image, landmarks)
return aligned_face, matrix- 面部检测器(
FaceDetector)
python
class FaceDetector:
def __call__(self, frame):
# 使用InsightFace模型检测106个人脸关键点
faces = self.app.get(frame)
return best_face.bbox, best_face.landmark_2d_106- 对齐还原器(
AlignRestore)
python
class AlignRestore:
def align_warp_face(self, img, landmarks):
# 计算从实际面部到标准模板的仿射矩阵
affine_matrix = self.transformation_from_points(landmarks)
# 应用变换得到对齐面部
return kornia.warp_affine(img, affine_matrix)总结
图像与视频处理器通过:
- 精准的面部检测与对齐
- 智能的
区域遮罩处理 - 高效的
GPU加速变换
为LatentSync提供可靠的视觉数据处理基础。下一章将介绍数据处理流程如何整合这些组件。
GPU调用
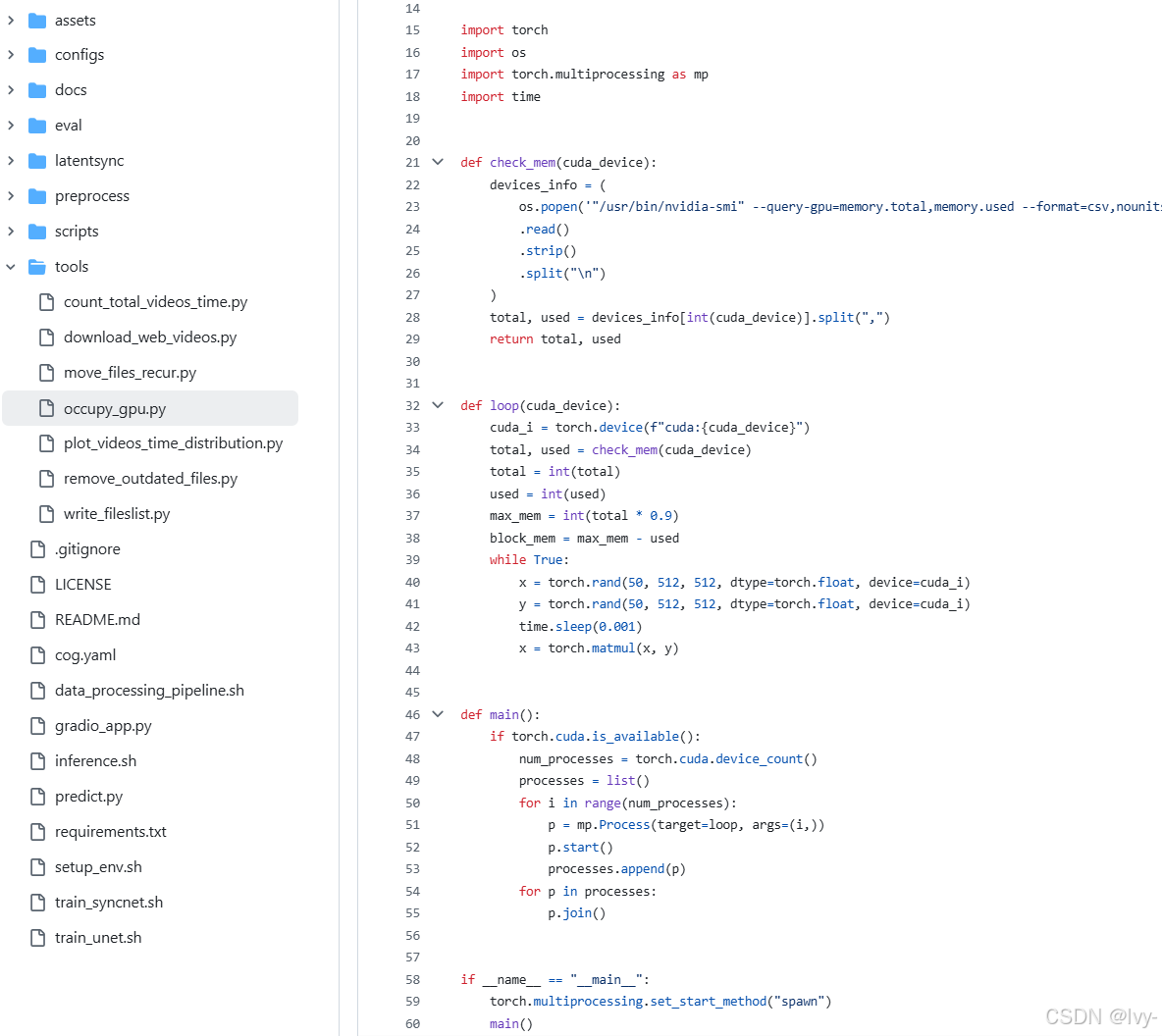
该文件 tools/occupy_gpu.py 的主要作用是占用所有可用的 GPU 显存资源,常用于测试、调试或保证特定 GPU 不被其它进程抢占。
1. 版权声明和依赖
python
# Copyright ...
import torch
import os
import torch.multiprocessing as mp
import time- 引入了
torch(PyTorch)、os、torch.multiprocessing和time库。
2. 检查 GPU 显存
python
def check_mem(cuda_device):
devices_info = (
os.popen('"/usr/bin/nvidia-smi" --query-gpu=memory.total,memory.used --format=csv,nounits,noheader')
.read()
.strip()
.split("\n")
)
total, used = devices_info[int(cuda_device)].split(",")
return total, used- 使用
nvidia-smi命令,查询每块 GPU 的总显存和已用显存。 - 返回某个 GPU(由
cuda_device指定)的显存总量和已用量。
3. 占用显存的循环
python
def loop(cuda_device):
cuda_i = torch.device(f"cuda:{cuda_device}")
total, used = check_mem(cuda_device)
total = int(total)
used = int(used)
max_mem = int(total * 0.9)
block_mem = max_mem - used
while True:
x = torch.rand(50, 512, 512, dtype=torch.float, device=cuda_i)
y = torch.rand(50, 512, 512, dtype=torch.float, device=cuda_i)
time.sleep(0.001)
x = torch.matmul(x, y)- 设定要用的 GPU(
cuda_i)。 - 检查 GPU 的显存情况。
- 计算目标要占用的显存(总量的 90%)。
- 循环中不断创建两个较大的张量
x和y并在 GPU 上做矩阵乘法,持续占用显存。 time.sleep(0.001)控制循环频率。
4. 主函数 (main)
python
def main():
if torch.cuda.is_available():
num_processes = torch.cuda.device_count()
processes = list()
for i in range(num_processes):
p = mp.Process(target=loop, args=(i,))
p.start()
processes.append(p)
for p in processes:
p.join()- 检查是否有可用 GPU。
- 获取 GPU 数量。
- 每个 GPU 启动一个子进程,执行
loop,每个进程独占一块 GPU。 - 等待所有进程结束(理论上这些进程会无限循环,占用显存)。
5. 程序入口
python
if __name__ == "__main__":
torch.multiprocessing.set_start_method("spawn")
main()spawn 模式
- 设置
多进程启动方式为spawn(更安全,兼容性好)。 - (
spawn模式通过完全新建进程来避免资源冲突,兼容所有平台且隔离性强,适合多进程场景) - 执行
main(),开始占用所有 GPU 显存。
总结
- 该脚本会在所有可用 GPU 上分别启动一个进程,每个进程不断分配大张量并进行计算,占用绝大部分显存。
- 常用于测试 GPU 资源的占用情况或防止其它任务抢占 GPU。