5.1 数据介绍
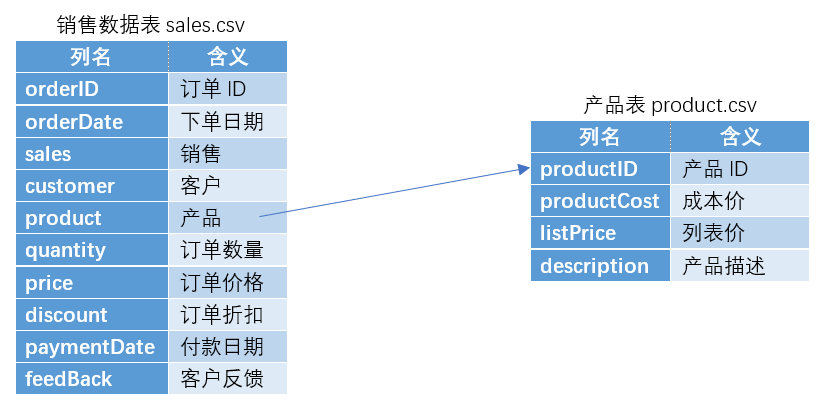
有产品信息表 product.csv,其字段为:
| 列名 | 含义 |
|---|---|
| productID | 产品 ID |
| productCost | 成本价 |
| listPrice | 列表价 |
| description | 产品描述 |
product.csv 和前面章节介绍过的销售数据表 sales.csv 的关系图:
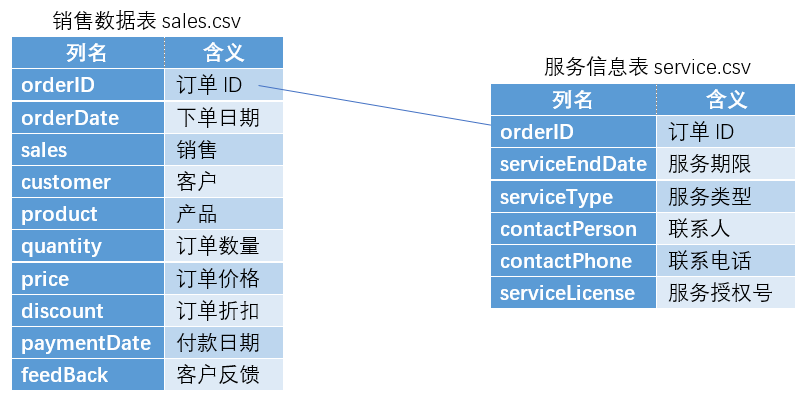
有服务信息表 service.csv,其字段为:
| 列名 | 含义 |
|---|---|
| orderID | 订单 ID |
| serviceEndDate | 服务期限 |
| serviceType | 服务类型 |
| contactPerson | 联系人 |
| contactPhone | 联系电话 |
| serviceLicense | 服务授权号 |
service.csv 和前面章节介绍过的销售数据表 sales.csv 的关系图:
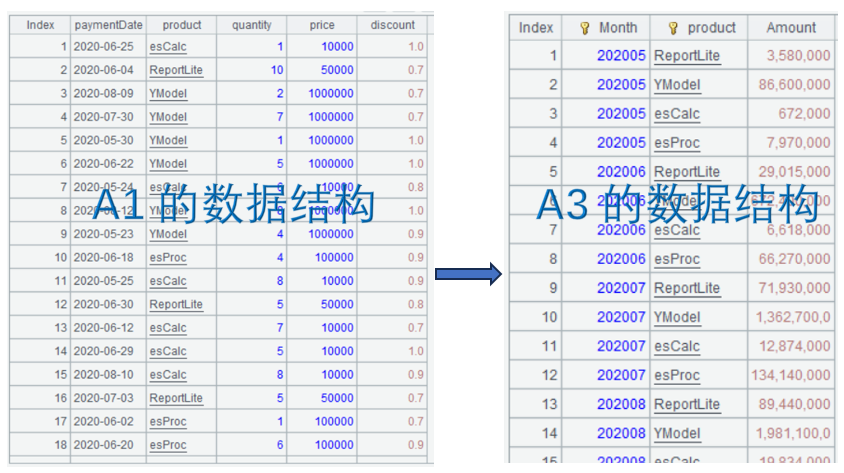
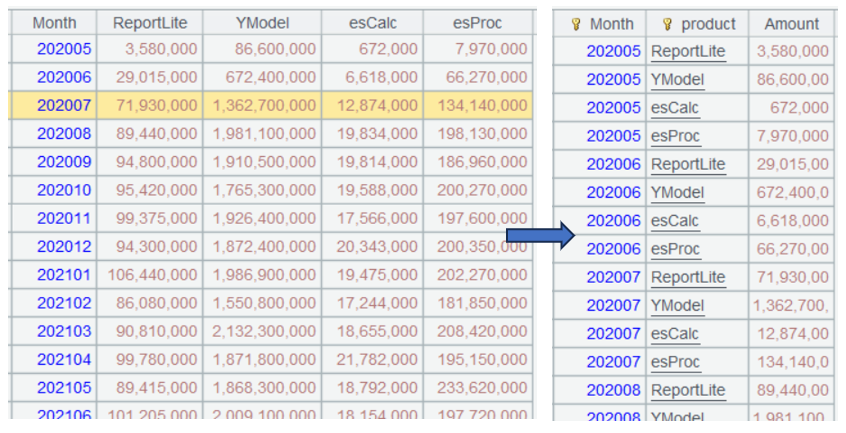
5.2 按月统计每种产品的总销售额 (分组汇总)
采用前面章节介绍过的分组算法,可以获得每月每种产品的总销售额:
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(paymentDate,product,quantity,price,discount) |
| 2 | =A1.select(paymentDate) |
| 3 | =A2.groups(month@y(paymentDate):Month,product;sum(quantity*price*discount):Amount) |
A1 从 sales.csv 中读取用到的字段,由于本例针对销售额做统计,所以日期字段读的是付款日期而非下单日期,以实际付款日期来统计销售额更加合理。
A2 过滤出付款日期不为空的记录,这里paymentDate在布尔表达式中等价于 paymentDate!=null,是 paymentDate!=null 的简写形式。
A3 按月、产品分组统计销售额,month@y(paymentDate) 中@y选项表示返回 yyyyMM 格式的整数,如果没有 @y,将只返回 MM。
分组汇总是数据结构变换的最常见操作:
5.3 按产品分别计算环比 (交叉汇总)
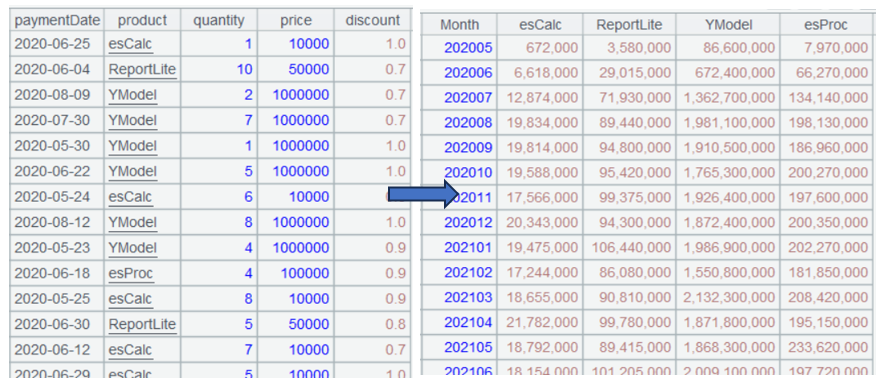
将 A3 单元格中的数据,转变成如下的格式:
| Month | esProc | esCalc | ReportLite | YModel |
|---|---|---|---|---|
| 202005 | . | |||
| 202006 | . | |||
| 202007 | . | |||
| ...... | . |
之后按产品计算环比:
| Month | esProc | Proc_MoM | esCalc | Calc_MoM | ReportLite | Report_MoM | YModel | YM_MoM |
|---|---|---|---|---|---|---|---|---|
| 202005 | ... | . | ||||||
| 202006 | . | |||||||
| 202007 | . | |||||||
| ...... | . |
第一步:交叉运算
| A | |
|---|---|
| 4 | =A3.pivot(Month;product,Amount) |
A4 将 A3 中的数据交叉运算,第一个参数 Month 表示左边按 Month 分组;第二个参数 product 表示将 product 字段作为列标题,product 字段有几种取值则产生几列;第三个参数 Amount 表示交叉点为 Amount 字段值。其中第一个参数和第二个参数之间是分号分隔,第二个参数和第三个参数之间是逗号分隔。
A4 的运行结果如下:
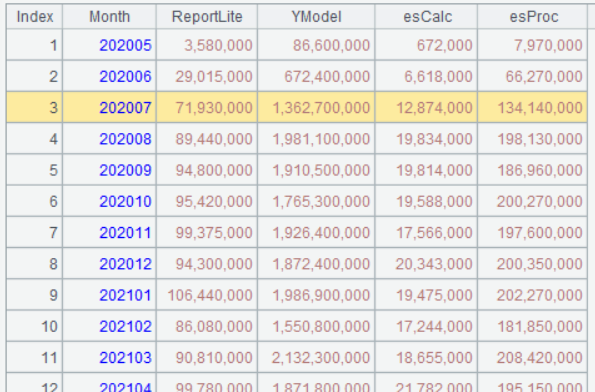
第二步:按产品计算环比,有了上一步交叉结果的数据结构,这里用前面介绍过的 -1 运算符可以很轻松实现:
| A | |
|---|---|
| 5 | =A4.new(Month,esProc,(esProc-esProc-1)/esProc-1:Proc_MoM,esCalc,(esCalc-esCalc-1)/esCalc-1:Calc_MoM,ReportLite,(ReportLite-ReportLite-1)/ReportLite-1:Report_MoM,YModel,(YModel-YModel-1)/YModel-1:YM_MoM) |
A5 的运行结果如下:
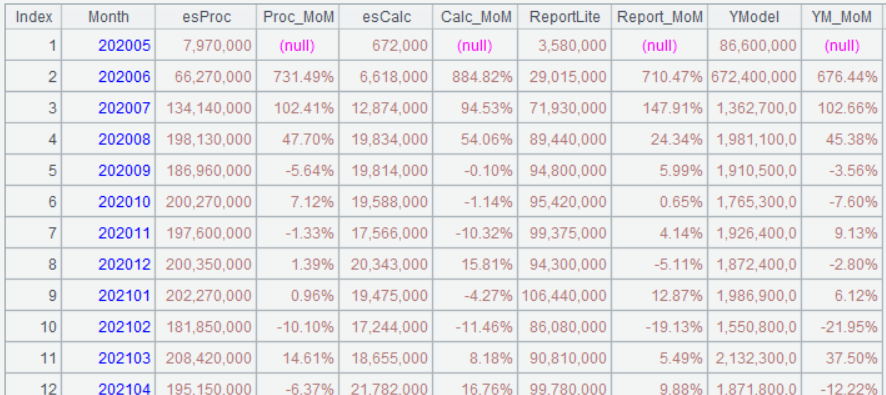
如果想把交叉格式的数据变回分组格式,可以用 pivot@r,比如把 A4 中的结果变回 A3 的样子,可以这样写:
| A | |
|---|---|
| 6 | =A4.pivot@r(Month;product,Amount) |
A6 的运行结果如下:
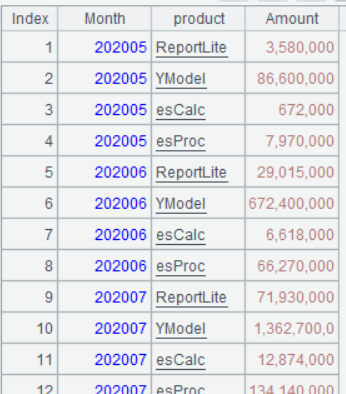
知识点:pivot 函数
pivot 函数是集算器 (SPL) 中用于数据透视的强大功能,它可以将 序表 / 排列 进行 行列转换 操作,实现类似 Excel 数据透视表的功能。
基本语法:
A.pivot(g:G,...;F,V;Ni:N′i,...)A.pivot(g:G,...;F,V;Ni:N′i,...)
参数:
|-------|-----------------------------|
| A | 序表 / 排列。 |
| g | 分组字段 / 表达式。 |
| G | 结果集中的字段名,缺省为 g。 |
| F | A 中的字段名称。 |
| V | A 中的字段名称。 |
| Ni | F 的字段值,可省略,缺省为 F 中所有不重复字段值。 |
| N'i | 新列字段名,缺省为 Ni。 |
选项:
|---------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------|
| @r | 将序表 / 排列进行列转行操作。 其中Ni 为字段名,转换后作为字段 F 的值,有参数N'i 时,N'i 将代替Ni 作为 F 的字段值;原Ni 字段的值作为新列 V 的列数据。 Ni 缺省值为A 中除g,...以外的所有字段名称。 |
| @s(g:G ,...;F,f(V);Ni :N'i,...) | f 可以为聚合函数:sum/count/max/min/avg,支持 ~.f() 的写法,~ 表示引用当前组;有N'i 且Ni 省略时表示聚合其它未进行聚合的Ni 中的V 。 |
返回值:
序表
功能图示:
A3.pivot(Month;product,Amount)
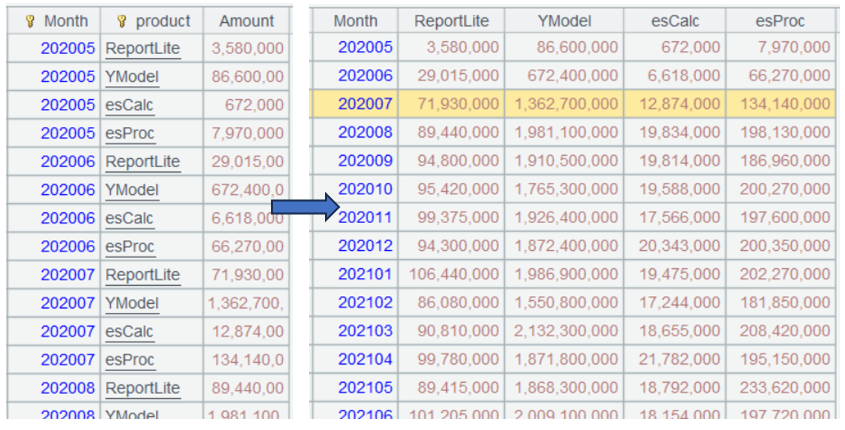
A4.pivot@r(Month;product,Amount)
A2.pivot@s(month@y(paymentDate):Month;product,sum(quantity*price*discount)) 等价于前面的 A3 和 A4 的组合功能,相当于把分组汇总和交叉合并到一个表达式中
5.4 毛利润追踪 (外键关联)
有销售月毛利润完成目标为:1000000,请选出 2024 年 10 月的销售订单,追踪日累计毛利润完成度。
毛利润的计算公式:产品的实际销售价 - 产品的成本价
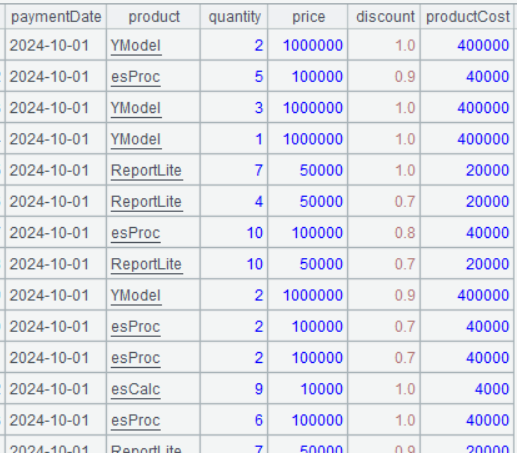
第一步:将销售数据表和产品信息表关联:
由于产品的成本价在产品表里,产品的实际销售价在销售表里,所以要计算毛利润,第一步就是要把两张表关联起来:
| A | |
|---|---|
| 1 | =file("product.csv").import@tc(productID,productCost) |
| 2 | =file("sales.csv").import@tc(paymentDate,product,quantity,price,discount) |
| 3 | =A2.select(month@y(paymentDate)==202410).sort(paymentDate) |
| 4 | =A3.join(product,A1:productID,productCost) |
A4 A3.join(product,A1:productID,productCost)的含义是:将 A3 和 A1 关联,关联字段分别是 A3 的 product 和 A1 的 productID,关联后在 A3 中添加 A1 的 productCost 字段。这里要注意:A1 和 productID 之间是冒号,表示 productID 是 A1 的字段。
A4 的运行结果如下:
第二步:按日分组统计毛利润
| A | |
|---|---|
| 5 | =A4.groups(paymentDate;sum(quantity*(price*discount-productCost)):profit) |
A5 表达式 quantity*(price*discount-productCost) 可以直接写在 sum 中,不需要添加计算列
A5 的运行结果如下:
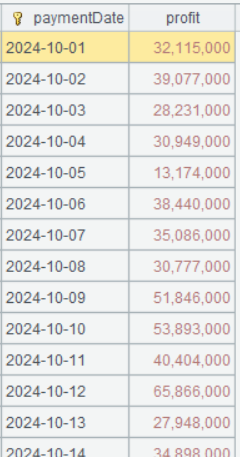
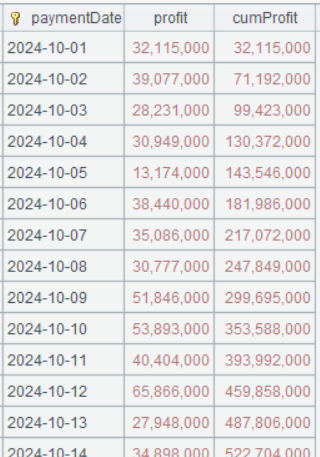
第三步:累计算毛利润
| A | |
|---|---|
| 6 | =A5.derive(cum(profit):cumProfit) |
A6 cum()是累积函数,cum(profit) 等价于前面章节介绍的 cumProfit-1+profit
A6 的运算结果如下:
知识点:什么是外键维表?
外键维表是关系型数据库中的一种维度表(Dimension Table),它通过外键(Foreign Key, FK)与事实表(Fact Table)关联,用于存储描述性、分类性或参考性的数据。这类表通常包含静态或缓慢变化的数据 (如产品信息、客户资料、地区信息等),而事实表则存储可度量的业务数据 (如销售金额、订单数量等)。外键维表的主要作用是提供查询和分析所需的上下文信息,使事实数据更具业务意义。
图示:外键维表与事实表的关系
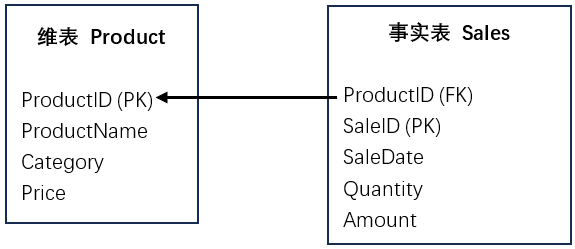
- 维表(Product) :存储产品详细信息(如名称、类别、价格),ProductID是主键(PK)。
- 事实表(Sales) :存储销售交易数据(如销售日期、数量、金额),ProductID是外键(FK),关联到维表。
外键维表的特点
- 存储描述性数据(如产品名称、客户信息、地区等)。
- 通常比事实表小,因为事实表存储大量交易数据。
- 用于数据分析(如 OLAP、BI 报表),提供业务上下文。
- 可缓慢变化(Slowly Changing Dimension, SCD),例如客户地址更新。
总结
外键维表通过外键与事实表关联,为数值型业务数据(如销售额、订单量)提供可读性强的描述信息,是数据仓库和商业智能(BI)分析的核心组成部分。
5.5 查询尚在服务期的客户信息 (主键一对一关联)
选出尚在服务期的客户信息,包括客户名称、产品名称、最迟服务期限、服务授权号
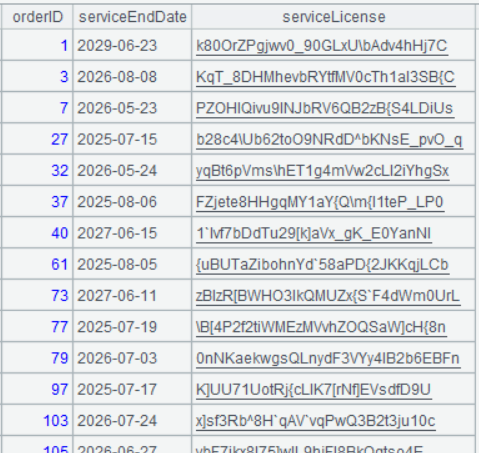
第一步:过滤服务表 service.csv
由于一个订单可能对应多个服务单,所以先将服务单按订单号和服务期限排序,选出服务期限最迟的服务单,然后再从中选出尚在服务期限的服务单。这样在后面关联的时候,需要关联的记录数能少点,可以提高关联效率
| A | |
|---|---|
| 1 | =file("service.csv").import@tc(orderID,serviceEndDate,serviceLicense) |
| 2 | =A1.sort(orderID,-serviceEndDate).group@o1(orderID).select(serviceEndDate>now()) |
A2 的运行结果:
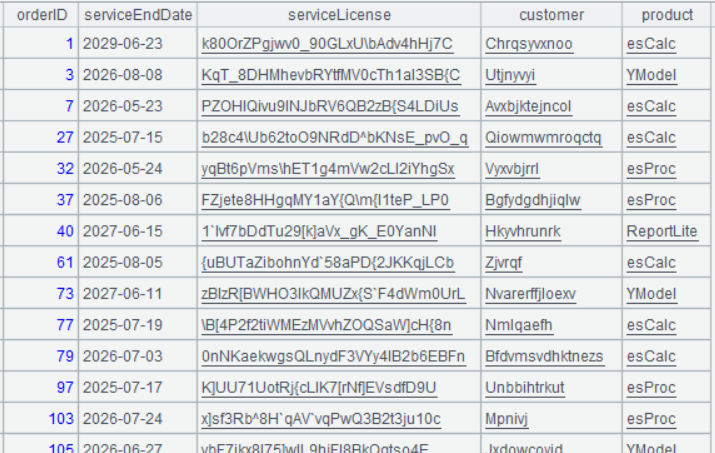
第二步:关联 A2 和销售数据表 sales.csv,获得对应的客户名称和产品名称
根据前面章节对 sales.csv 文件的数据介绍可知,orderID 的取值是自然数列,和记录序号等同,所以可以用 A3 的记录序号和 A2 的 orderID 字段关联
| A | |
|---|---|
| 3 | =file("sales.csv").import@tc(orderID,customer,product) |
| 4 | =A2.join(orderID,A3:#,customer,product) |
A4 将 A2 和 A3 关联,关联字段分别是 A2 的 orderID 和 A3 的记录序号 (# 在循环函数中表示当前记录的序号 ),并在 A2 中添加 A3 对应的 customer 和 product 字段
A4 的运行结果是:
知识点:# 是什么?
# 是 SPL 语言中的内置系统变量,表示当前记录在序列中的行号(从 1 开始的整数序号)。该符号在迭代计算、记录定位和序表操作中具有基础性作用,为数据遍历和位置感知计算提供了简洁的引用方式。行号 # 具有以下核心特性:
- 自动生成:系统自动维护的连续整数序列
- 只读属性:不可通过赋值修改
- 动态上下文:在每次迭代中自动更新
- 稳定排序:始终反映原始序列的物理存储顺序
技术特性说明
| 特性 | 说明 |
|---|---|
| 取值范围 | 从 1 开始到序表记录总数 |
| 引用场景 | 可用于derive 、new 、run等所有需要位置感知的计算上下文 |
| 特殊取值 | 在序表头 / 尾边界外访问时返回null |
| 组合使用 | 常与 ~ (当前成员引用符) 配合使用,如 ~.# 表示当前记录的行号 |
典型应用示例
- 创建示例序表
| A | |
|---|---|
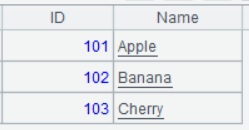
| 1 | =create(ID,Name).record(101,"Apple",102,"Banana",103,"Cherry") |
- 显示行号与记录内容
| A | |
|---|---|
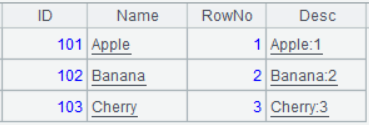
| 2 | =A1.derive(#:RowNo, Name+":"+string(#):Desc) |
- 条件过滤 (选择偶数行)
| A | |
|---|---|
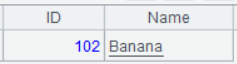
| 3 | =A1.select(#%2==0) |
- 按行号区间提取记录
| A | |
|---|---|
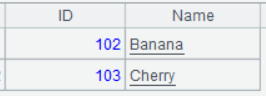
| 4 | =A1.to(2,3) |
执行结果示例:
A1 的运行结果:
A2 的运行结果:
A3 的运行结果:
A4 的运行结果:
特殊用法说明
- 跨组分引用 :在分组计算中,# 会在每个分组内重新从 1 开始计数
- 与 ~ 配合 :~.# 等效于单独的 #,强调当前记录的行号属性
- 性能优化:行号访问是 O(1) 时间复杂度操作,不影响计算性能
该设计使得 SPL 在进行数据遍历、位置相关计算时,既能保持代码简洁性,又能获得明确的顺序控制能力。
5.6 服务单统计 (主子表一对多内连接)
选出每个订单的客户名称、产品名称、对应的服务单个数、最迟服务期限
| A | |
|---|---|
| 1 | =file("service.csv").import@tc(orderID,serviceEndDate,serviceLicense) |
| 2 | =file("sales.csv").import@tc(orderID,customer,product) |
| 3 | =join(A2:sales,orderID; A1:service,orderID) |
| 4 | =A3.groups(sales.orderID;sales.customer,sales.product,count(1):serviceNum, max(service.serviceEndDate):serviceEndDate) |
A3 join函数和 SQL 中的 join 功能类似,无选项时缺省为内连接。本单元格表达式的含义是:将主表 A2 和子表 A1 内连接,关联字段是 A2 的 orderID 和 A1 的 orderID。对应的 SQL 大致为:
select sales.*,service.*
from sales.csv sales
inner join service.csv service on sales.orderID==service.orderIDselect sales.*,service.* from sales.csv sales inner join service.csv service on sales.orderID==service.orderID
A3 的运行结果为:
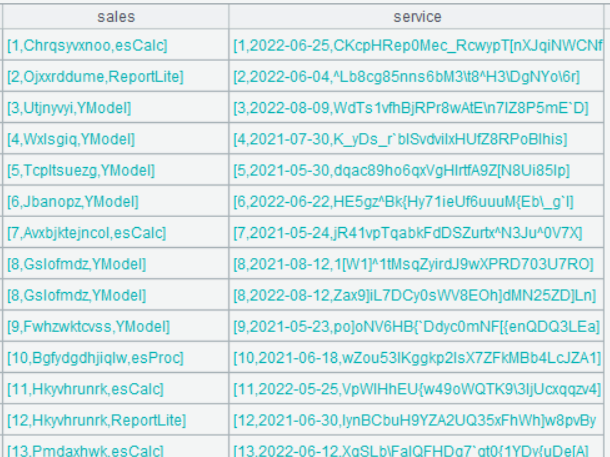
从图上可以看出,结果集只有两个字段,分别是 sales(存储 A2 的记录) 和 service(存储 A1 的记录),双击 sales 字段任意一行的字段值,可以看到:
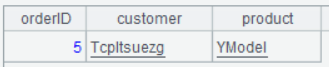
双击 service 字段任意一行的字段值,可以看到:

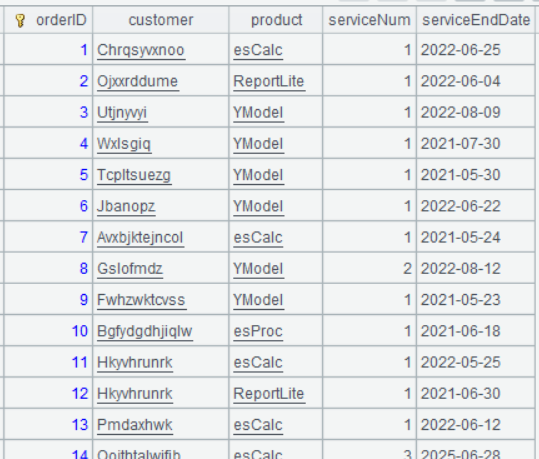
A4 将 A3 进行分组汇总,由于 sales 和 service 两个字段存储的都是记录,访问里面记录的字段值可以用点操作符,比如sales.customer,表示访问 sales 字段里的记录的 customer 字段的值。对于不参与分组,但是由分组字段唯一决定的字段值,可以写在分号后面,而不需要聚合函数,比如此例中的sales.customer,sales.product,均由 orderID 唯一决定,不参与分组,因此不需要写聚合函数。
A4 的运行结果为:
知识点:A.join()和 join() 的区别
两个函数均用于表间关联,主要区别如下:
应用场景:
A.join(C:.,T:K,x:F,...; ...;...) 主要用于事实表和外键维表的关联,A 为事实表,T 为外键维表,T 的关联字段一定是唯一的,大部分时候是 T 的主键。
join(Ai:Fi,xj,..;...) 主要用于主键关联,和 SQL 中的关联类似,支持内连接、左连接、全连接
参数结构:
A.join(C:.,T:K,x:F,...; ...;...)的参数除了指定关联表和关联字段,还可以指定需要追加到 A 中的字段或表达式,比 join() 更加复杂
join(Ai:Fi,xj,..;...) 的参数只指定关联表和关联字段
结果集:
A.join(C:.,T:K,x:F,...; ...;...) 返回的结果集直接就是序表,可以直接输出展示
join(Ai:Fi,xj,..;...) 返回的结果集是指引字段,需要进一步 new 或者 groups 运算,才能获得最终可展示的结果。
知识点:什么是主子表?
主子表是数据库设计中表示一对多关系的经典模式,由主表(Master)和子表(Detail)组成。主表存储核心实体信息(如订单、学生、文章),子表存储与主表记录相关联的详细信息(如订单商品、学生成绩、文章评论)。每个主表记录可以对应多个子表记录,但子表记录必须且只能属于一个主表记录。这种关系通过外键约束实现,确保数据完整性,通常表现为:删除主表记录时会级联删除其所有子表记录。
图示
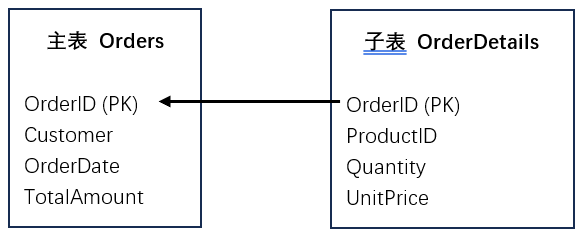
实例说明
以电商系统为例:
主表 Orders记录订单概要(订单号 1001,客户张三,2023-01-01)
子表 OrderDetails记录该订单下的所有商品:
记录 1:订单号 1001(关联字段),商品 A,2 件,单价 50 元
记录 2:订单号 1001(关联字段),商品 B,1 件,单价 200 元
这种结构既避免了主表数据冗余(不需要把所有商品挤在一个订单记录中),又能完整保存交易细节,是关系型数据库的标准设计范式。
5.7 10 月下单的客户,10 月、11 月下单的个数(左连接)
第一步:先选出 24 年 10 月、11 月的订单
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(orderDate,customer) |
| 2 | =A1.select(month@y(orderDate)==202410) |
| 3 | =A1.select(month@y(orderDate)==202411) |
第二步:分别统计客户下单个数
| A | |
|---|---|
| 4 | =A2.groups(customer;count(1):octNum) |
| 5 | =A3.groups(customer;count(1):novNum) |
第三步:左连接
| A | |
|---|---|
| 6 | =join@1m(A4:oct,customer; A5:nov,customer) |
| 7 | =A6.new(oct.customer,oct.octNum, nov.novNum) |
A6 A4 和 A5 左连接,关联字段为 A4 的 customer 和 A5 的 customer。选项 @1 表示左连接,注意这里是数字 1 不是字母 l;选项 @m 表示同序关联,即当 A4 和 A5 均按关联字段有序时,可以用 @m 同序关联,使用归并算法,效率更高。两个选项 @1 和 @m 合并起来可以写成 @1m
A6 的运行结果为:
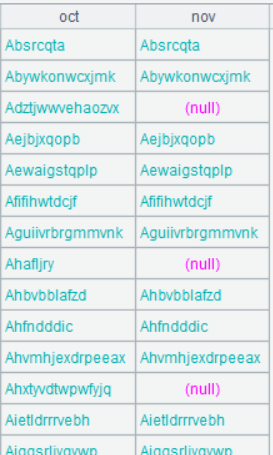
A7 对 A6 产生新序表,读出指引字段中需要输出的字段,作为最终结果输出
A7 的运行结果为:
5.8 统计客户 10 月、11 月、12 月下单的个数(全连接)
第一步:分别选出 10 月、11 月、12 月的订单
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(orderDate,customer) |
| 2 | =A1.select(month@y(orderDate)==202410) |
| 3 | =A1.select(month@y(orderDate)==202411) |
| 4 | =A1.select(month@y(orderDate)==202412) |
第二步:分别汇总客户的下单个数
| A | |
|---|---|
| 5 | =A2.groups(customer;count(1):octNum) |
| 6 | =A3.groups(customer;count(1):novNum) |
| 7 | =A4.groups(customer;count(1):decNum) |
第三步:全连接
| A | |
|---|---|
| 8 | =join@fm(A5:oct,customer; A6:nov,customer; A7:dec,customer) |
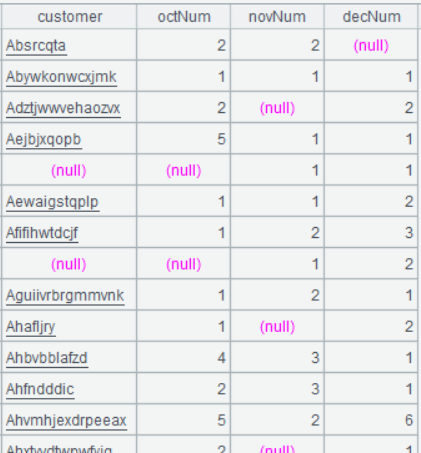
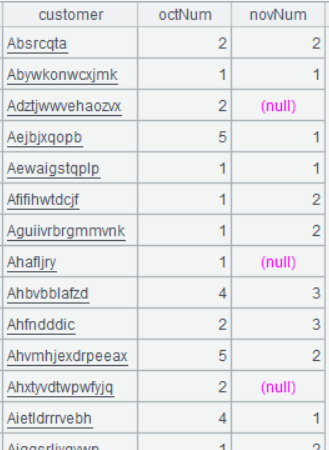
| 9 | =A8.new(oct.customer,oct.octNum, nov.novNum,dec.decNum) |
A8 @f 表示全连接
A8 的运行结果:
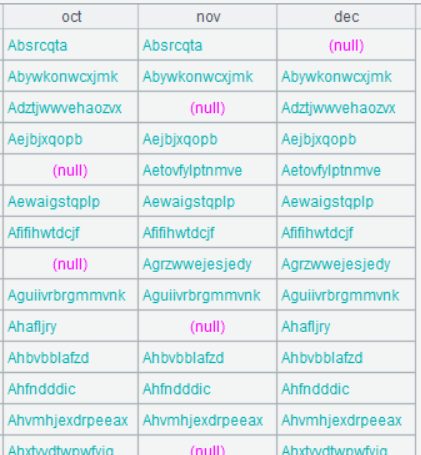
A9 的运行结果: