本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院
不知道大家在RAG项目实践中,有没有遇到这个问题?用LangChain框架自带的PyPDFLoader加载PDF报告时,虽然流程跑通了,但给出的结果回答质量极低,各种回避问题、事实错误。后来我通过深入的复盘才发现,真正的症结不在于模型本身,而在于上游的数据处理管道。今天,我想就从这个问题出发,系统性地分享我关于RAG数据解析的架构设计、技术选型和一些实践思考。如有遗漏,欢迎补充指正。

一、问题根源:开箱即用工具的"现实鸿沟"
当开发者使用LangChain的PyPDFLoader等默认工具处理企业级PDF时,常遭遇回答质量崩塌。根本原因在于:
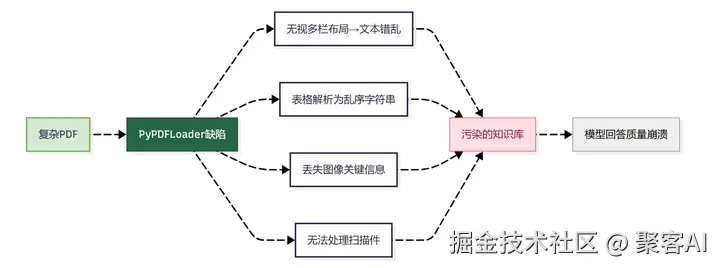
关键认知:原始文档解析质量直接决定RAG系统上限,"垃圾进,垃圾出"(GIGO)原则在此绝对成立
二、架构原则:构建专业级文档处理管道
将RAG系统视为专业知识管理者:
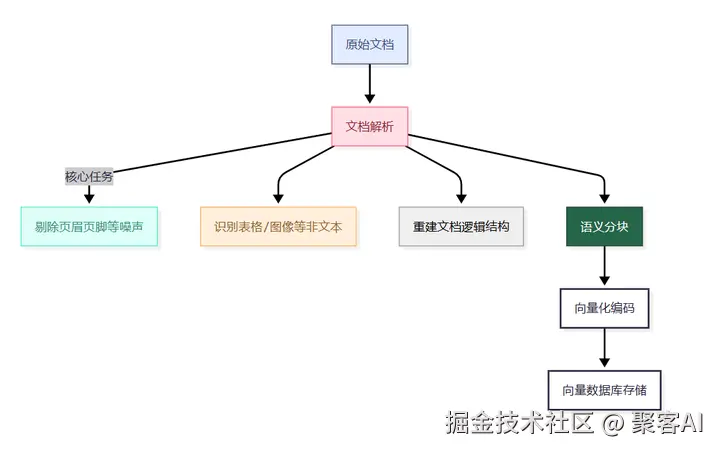
生产级解析需满足:
- 视觉感知能力:理解PDF多栏、表格等复杂布局
- 多模态处理:捕获图像、公式等非文本信息
- 类型自适应:动态选择最优解析策略
三、工具选型矩阵:按场景分层击破
| 工具 | 核心优势 | 适用场景 | 性能代价 |
|---|---|---|---|
| Unstructured.io | 支持50+格式,生态完善 | 多源数据ETL入口 | 处理速度较慢 |
| PyMuPDF4LLM | 解析速度>200页/分钟 | 纯文本/简单PDF批量处理 | 无OCR能力 |
| Marker | 代码/公式支持优秀 | 技术白皮书/学术文献 | 需GPU加速 |
| MinerU | 数学公式识别精准 | 科技/专利类文档 | 高计算负载 |
| DoclingAI | 表格提取精度98%+ | 金融财报/科研报告 | 仅专注表格 |
| DeepDoc | 中文优化+端到端方案 | 中文RAG系统建设 | 需API调用 |
分层策略:
- 基础层:Unstructured.io处理HTML/PPT等通用格式
- 高效层:MarkItDown处理Word,PyMuPDF4LLM处理简单PDF
- 攻坚层:Marker/MinerU处理含公式/图表PDF,DoclingAI专攻表格
四、核心难题突破:表格与图像的工程化处理
(1)表格处理双路径
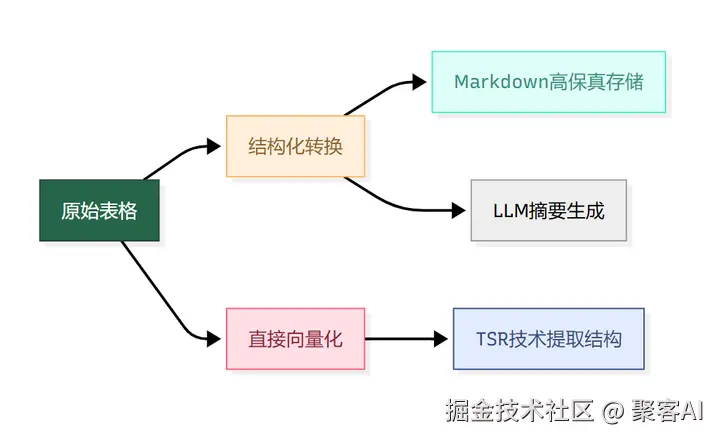
(2)图像混合内容处理范式
json
{
"chunk_id": "doc007_imageblock",
"searchable_content": "系统架构如图... [图片描述:三层微服务架构...]",
"metadata": {
"original_text": "系统架构如下图所示",
"image_uri": "https://oss.example/arch.png"
}
}三重索引机制:
- 检索文本 = 原始文字 + AI图片描述 → 向量化
- LLM输入 = 纯净原始文本 → 避免描述污染
- 图像引用 = URI存储 → 前端渲染
五、可扩展解析管道实现
ini
def process_document(file_path: str, strategy: str = 'modular'):
if strategy == 'deepdoc':
return call_deepdoc_api(file_path) # 一体化方案
file_type = detect_file_type(file_path)
if file_type == '.docx':
return process_with_markitdown(file_path)
elif file_type == '.pdf':
if is_complex_pdf(file_path): # 复杂度检测
return marker.parse(file_path)
return pymupdf.parse(file_path)
else:
return unstructured.parse(file_path)
# 后处理器示例
def process_table(element):
markdown_table = doclingai.convert_to_md(element)
return TableChunk(
content=markdown_table,
summary=llm_generate_summary(markdown_table))六、其他的解析实践方向
- 原生多模态解析 ▸ 直接对PDF渲染截图进行跨模态向量化(CLIP/ViLT)
- 知识图谱增强 ▸ 在解析阶段同步抽取实体关系,构建检索-图谱双通道
- Agentic解析框架 ▸ LLM Agent动态选择解析工具:
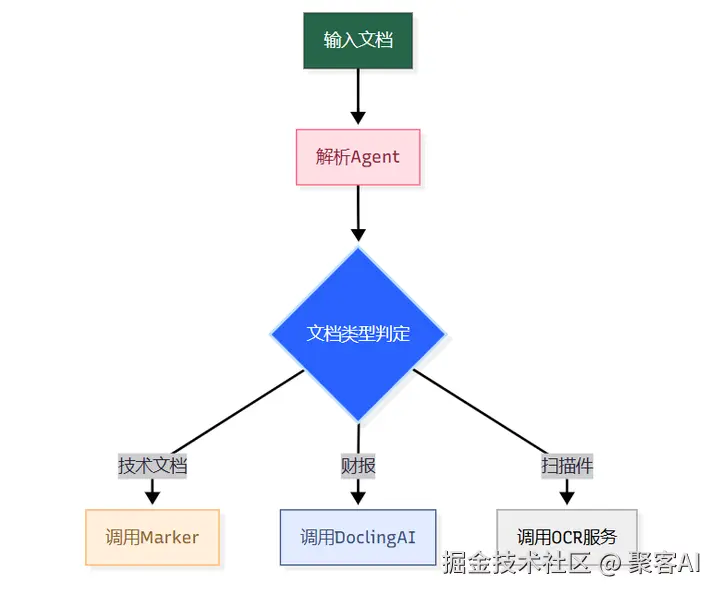
最终建议:将文档解析视为独立子系统持续迭代,其质量增益将产生10倍级下游效果放大。好了,今天的分享就到这里,点个小红心,我们下期见。