基于YOLOv11训练无人机视角Visdrone2019数据集
Visdrone2019数据集介绍
VisDrone 数据集 是由中国天津大学机器学习和数据挖掘实验室 AISKYEYE 团队创建的大规模基准。它包含用于与无人机图像和视频分析相关的各种计算机视觉任务的,经过仔细标注的真实数据。
VisDrone 由 288 个视频片段(包含 261,908 帧)和 10,209 张静态图像组成,这些数据由各种无人机载摄像头拍摄。该数据集涵盖了广泛的方面,包括地点(中国 14 个不同的城市)、环境(城市和乡村)、物体(行人、车辆、自行车等)和密度(稀疏和拥挤的场景)。该数据集是在不同的场景以及天气和光照条件下,使用各种无人机平台收集的。这些帧通过手动方式进行了标注,包含超过 260 万个目标的边界框,例如行人、汽车、自行车和三轮车。此外,还提供了场景可见性、物体类别和遮挡等属性,以更好地利用数据。

类别:
0:Pedestrian(行人)
1:People(人群)
2:Bicycle(自行车)
3:Car(汽车)
4:Van(厢式货车)
5:Truck(卡车)
6:Tricycle(三轮车)
7:Awning-tricycle(带棚三轮车)
8:Bus(公交车)
9:Motor(摩托车)
数据集格式
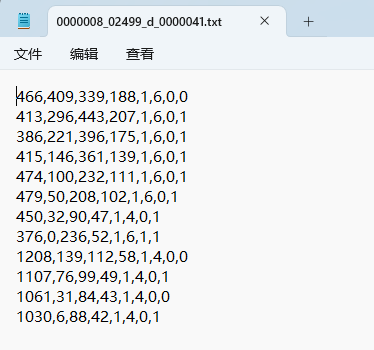
- 边界框左上角的x坐标
- 边界框左上角的y坐标
- 边界框的宽度
- 边界框的高度
- GROUNDTRUTH文件中的分数设置为1或0。1表示在计算中考虑边界框,而0表示将忽略边界框。
- 类别:忽略区域(0)、行人(1)、人(2)、自行车(3)、汽车(4)、面包车(5)、卡车(6)、三轮车(7)、雨篷三轮车(8)、公共汽车(9)、摩托车(10),其他(11)。
- GROUNDTRUTH文件中的得分表示对象部分出现在帧外的程度(即,无截断=0(截断比率0%),部分截断=1(截断比率1%°´50%))。
- GROUNDTRUTH文件中的分数表示被遮挡的对象的分数(即,无遮挡=0(遮挡比率0%),部分遮挡=1(遮挡比率1%°´50%),重度遮挡=2(遮挡率50%~100%))。

数据预处理
将数据处理成yolo的格式
yolo格式如下:
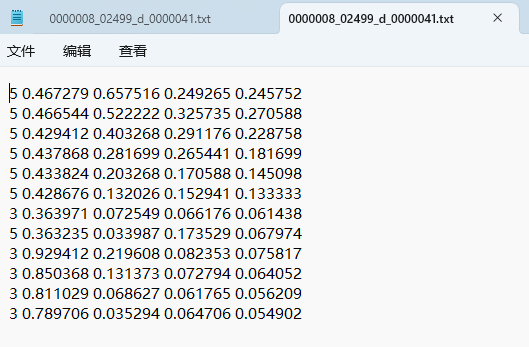
bash
import os
from pathlib import Path
import argparse
def visdrone2yolo(dir):
from PIL import Image
from tqdm import tqdm
def convert_box(size, box):
# Convert VisDrone box to YOLO xywh box
dw = 1. / size[0]
dh = 1. / size[1]
return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
(dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
for f in pbar:
img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
lines = []
with open(f, 'r') as file: # read annotation.txt
for row in [x.split(',') for x in file.read().strip().splitlines()]:
if row[4] == '0': # VisDrone 'ignored regions' class 0
continue
cls = int(row[5]) - 1 # 类别号-1
box = convert_box(img_size, tuple(map(int, row[:4])))
lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
fl.writelines(lines) # write label.txt
if __name__ == '__main__':
# Create an argument parser to handle command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument('--dir_path', type=str, default=r'E:\datasets\visdrone2019', help='visdrone数据集路径')
args = parser.parse_args()
dir = Path(args.dir_path)
# Convert
for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labelsyolov11模型训练
VisDrone.yaml
bash
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Crack-seg dataset by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/segment/crack-seg/
# Example usage: yolo train data=crack-seg.yaml
# parent
# ├── ultralytics
# └── datasets
# └── crack-seg ← downloads here (91.2 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/Desktop/XLWD/dataset/VisDrone2019/visdrone2019/VisDrone2019-DET-train # dataset root dir
train: images/train # train images (relative to 'path') 3717 images
val: images/val # val images (relative to 'path') 112 images
test: images/test # test images (optional)
# test: test/images # test images (relative to 'path') 200 images
nc: 10
# Classes
names:
0: pedestrian
1: people
2: bicycle
3: car
4: van
5: truck
6: tricycle
7: awning-tricycle
8: bus
9: motor训练脚本 train.py
bash
from ultralytics import YOLO
# import os
# os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# # 消除异步性,但是会带来性能的损失
if __name__ == '__main__':
# Load a COCO-pretrained YOLO11n model
# model = YOLO("yolo11n.pt")
model = YOLO(r"D:/SSJ/Work/ultralytics-main/yolo11n.pt",task='detect') # yolo11n-seg.pt segment
# model = YOLO(r"D:/SSJ/Work/ultralytics-main/yolo11n.pt",task='detect')
# model = YOLO(r"D:/SSJ/Work/ultralytics-main/runs/detect/train30/weights/best.pt",task='detect')
# # Train the model on the COCO8 example dataset for 100 epochs
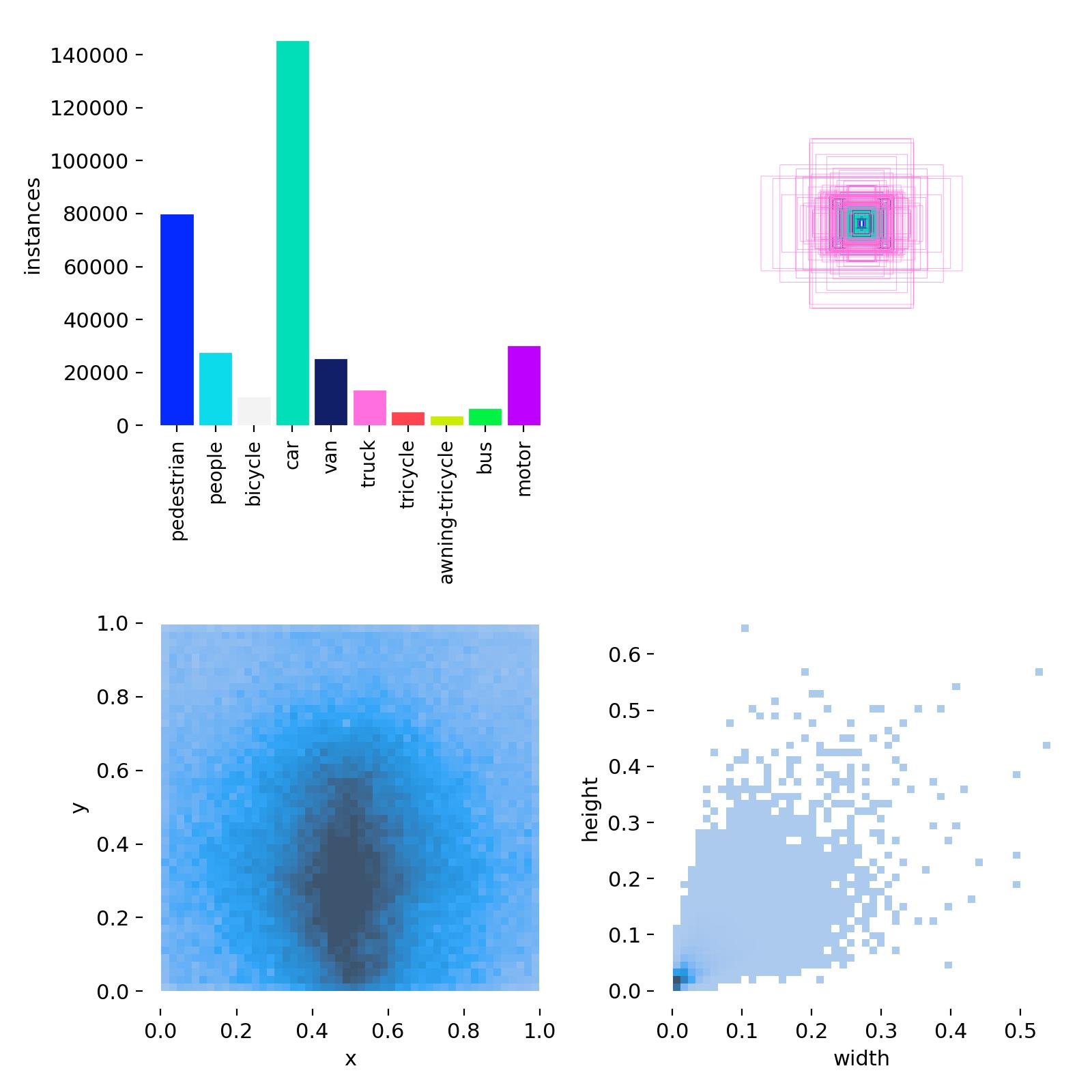
results = model.train(data="D:/Desktop/XLWD/dataset/ultralytics-8.3.39/demo/insulatorAndPersonDetect.yaml", epochs=100, batch=64,device=0,workers = 2)# imgsz=320,数据分布情况可视化
数据特点:数据不同类别的数量不均衡,小目标较多
训练结果
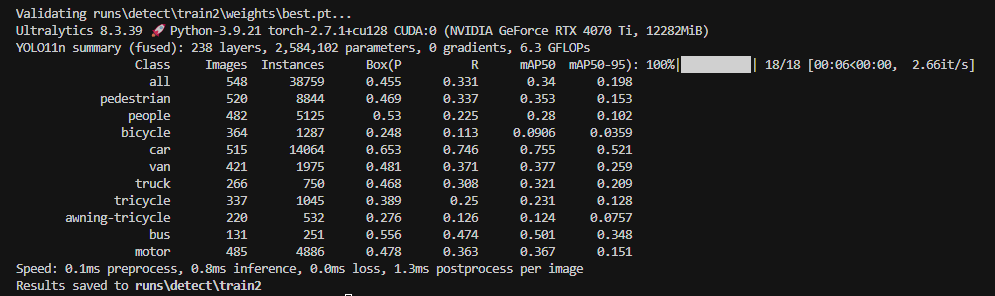
可以看出最终的结果只有car的识别准确率比较高,其余的都相对较低,当然这是由于训练不充分导致的。
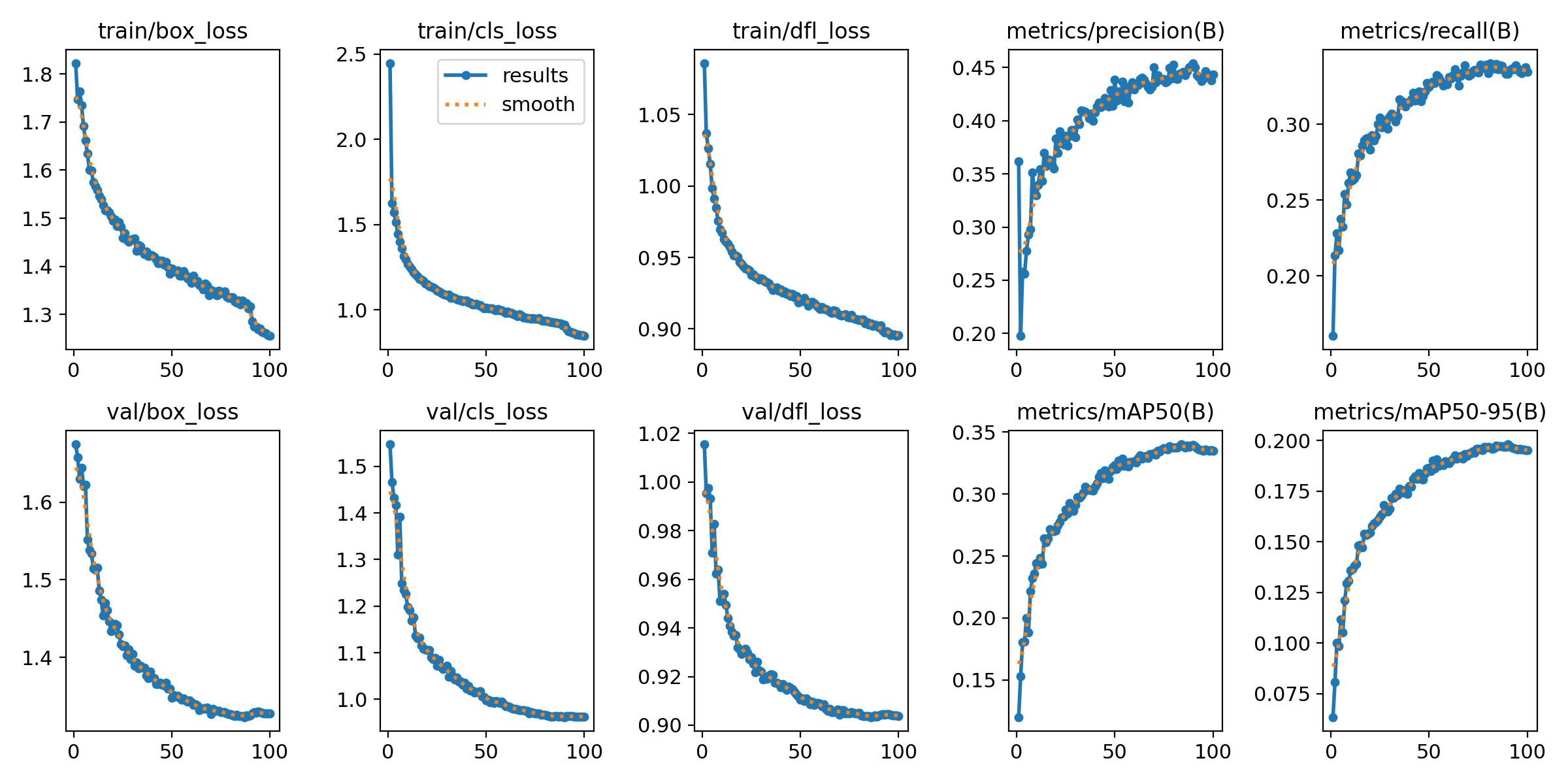
训练过程中的loss以及准确率如上,虽然最终准确率停留在0.45左右,但是已经比其他文章里的效果要好得多了,毕竟才训练了100个epoch。