手感火热哈哈,继续干。
P2347 NOIP 1996 提高组 砝码称重
P2347 NOIP 1996 提高组 砝码称重 - 洛谷![]() https://www.luogu.com.cn/problem/P2347
https://www.luogu.com.cn/problem/P2347
题目描述
设有 1g、2g、3g、5g、10g、20g 的砝码各若干枚(其总重 ≤1000),可以表示成多少种重量?
输入格式
输入方式:a1,a2,a3,a4,a5,a6
(表示 1g 砝码有 a1 个,2g 砝码有 a2 个,...,20g 砝码有 a6 个)
输出格式
输出方式:
Total=N(N 表示用这些砝码能称出的不同重量的个数,但不包括一个砝码也不用的情况)
输入输出样例
输入 #1复制
1 1 0 0 0 0输出 #1复制
Total=3说明/提示
【题目来源】
NOIP 1996 提高组第四题
思路
嗯,这个是多重背包哈,和其他背包区别就是,这个背包不像完全背包一样,每个物品可以无限放,也不像01背包一样只能放一个,他是每个物品给你可以放的数量。dp数组:dpj表示重量j是否可组成
先放一个无优化版本
cpp
#include<bits/stdc++.h>
using namespace std;
bool dp[1001];
int main() {
// 砝码重量
const int weights[6] = {1, 2, 3, 5, 10, 20};
// 存储每种砝码的数量
int counts[6];
for (int i=0;i<6;i++) {
cin>>counts[i];
}
dp[0]=true; // 初始状态:重量0可达
// 处理每种砝码
for (int i=0;i<6;i++){
// 处理当前砝码的每个实例
for (int k=0;k<counts[i];k++){
// 从大到小更新可达重量列表
for (int j=1000;j>=weights[i];j--){
if (dp[j-weights[i]]) {
dp[j] = true;
}
}
}
}
int total=0;
for (int j=1;j<=1000;j++){
if (dp[j]){
total++;
}
}
cout <<"Total="<<total<<;
return 0;
}优化
二进制优化原理
假设有13个1g砝码:
-
拆分为:1个、2个、4个、6个(1+2+4=7,剩余6)
-
这样只需4次处理代替13次处理
-
因为这些组合可以表示0-13之间的任何数量:
-
1 = 1
-
2 = 2
-
3 = 1+2
-
4 = 4
-
5 = 1+4
-
...
-
13 = 1+2+4+6
-
cpp
#include<bits/stdc++.h>
using namespace std;
bool dp[1001];
int main() {
// 砝码重量
const int weights[6] = {1, 2, 3, 5, 10, 20};
// 存储每种砝码的数量
int counts[6];
for (int i=0;i<6;i++) {
cin>>counts[i];
}
dp[0]=true;
for(int i=0;i<6;i++){
int w=weights[i];
int num=counts[i];
int k=1;
while(k<=num){
int all_w=k*w;
for(int j=1000;j>=all_w;j--){
if(dp[j-all_w]){
dp[j]=1;
}
}
num-=k;//减去已经处理的量
k*=2;
}
//处理一下剩余的量
if(num>0){
int all_w=num*w;
for(int j=1000;j>=all_w;j--){
if(dp[j-all_w]){
dp[j]=1;
}
}
}
}
int total=0;
for (int j=1;j<=1000;j++){
if (dp[j]){
total++;
}
}
cout <<"Total="<<total;
return 0;
}P2722 USACO3.1 总分 Score Inflation
P2722 USACO3.1 总分 Score Inflation - 洛谷![]() https://www.luogu.com.cn/problem/P2722
https://www.luogu.com.cn/problem/P2722
题目背景
选手在我们 USACO 的竞赛中的得分越多我们越高兴。
我们试着设计我们的竞赛以便人们能尽可能的多得分,这需要你的帮助。
题目描述
我们可以从几个种类中选取竞赛的题目,这里的一个"种类"是指一个竞赛题目的集合,解决集合中的题目需要相同多的时间并且能得到相同的分数。
你的任务是写一个程序来告诉 USACO 的职员,应该从每一个种类中选取多少题目,使得解决题目的总耗时在竞赛规定的时间里并且总分最大。
输入格式
输入的第一行是用空格隔开的两个整数,分别代表竞赛时间 m 和题目类 n。
第 2 到第 (n+1) 行,每行两个用空格隔开的整数,第 (i+1) 行的整数 pi,ti 分别代表解决第 i 类题得到的分数和需要花费的时间。
既然是某一类题目,那么这一类题目可以重复选择。
输出格式
输出一行一个整数,代表最大的总分。
输入输出样例
输入 #1复制
300 4 100 60 250 120 120 100 35 20输出 #1复制
605说明/提示
数据规模与约定
对于 100% 的数据,保证 1≤n,m≤104,1≤pi,ti≤104。
思路
就是完全背包吧,就是纯模板
cpp
#include<bits/stdc++.h>
using namespace std;
int m,n;
int dp[10020];
int a[10020],b[10020];
int main(){
cin>>m>>n;
dp[0]=0;
for(int i=1;i<=n;i++) cin>>a[i]>>b[i];
for(int i=1;i<=n;i++){
for(int j=b[i];j<=m;j++){
dp[j]=max(dp[j],dp[j-b[i]]+a[i]);
}
}
cout<<dp[m];
}P2925 USACO08DEC Hay For Sale S
P2925 USACO08DEC Hay For Sale S - 洛谷![]() https://www.luogu.com.cn/problem/P2925
https://www.luogu.com.cn/problem/P2925
题目描述
农民 John 面临一个很可怕的事,因为防范力度不大所以他存储的所有稻草都被蟑螂吃光了,他将面临没有稻草喂养奶牛的局面。在奶牛断粮之前,John 拉着他的马车到农民 Don 的农场中买一些稻草给奶牛过冬。已知 John 的马车可以装的下 C(1≤C≤5×104) 立方的稻草。
农民 Don 有 H(1≤H≤5×103) 捆体积不同的稻草可供购买,每一捆稻草有它自己的体积 Vi(1≤Vi≤C)。面对这些稻草 John 认真的计算如何充分利用马车的空间购买尽量多的稻草给他的奶牛过冬。
现在给定马车的最大容积 C 和每一捆稻草的体积 Vi,John 如何在不超过马车最大容积的情况下买到最大体积的稻草?他不可以把一捆稻草分开来买。
输入格式
第一行两个整数,分别为 C 和 H。 第 2 到 H+1 行:每一行一个整数代表第 i 捆稻草的体积 Vi。
输出格式
一个整数,为 John 能买到的稻草的体积。
修改 by zhangsenhao6728
显示翻译
题意翻译
输入输出样例
输入 #1复制
7 3 2 6 5输出 #1复制
7
思路
小小的01背包模板
cpp
#include<bits/stdc++.h>
using namespace std;
int c,h;
int a[5020];
int dp[50020];
int main(){
cin>>c>>h;
dp[0]=0;
for(int i=0;i<h;i++){
cin>>a[i];
}
for(int i=0;i<h;i++){
for(int j=c;j>=a[i];j--){
dp[j]=max(dp[j],dp[j-a[i]]+a[i]);
}
}
cout<<dp[c];
}B. Mashmokh and ACM
Problem - 414B - Codeforces![]() https://codeforces.com/problemset/problem/414/B
https://codeforces.com/problemset/problem/414/B
Mashmokh's boss, Bimokh, didn't like Mashmokh. So he fired him. Mashmokh decided to go to university and participate in ACM instead of finding a new job. He wants to become a member of Bamokh's team. In order to join he was given some programming tasks and one week to solve them. Mashmokh is not a very experienced programmer. Actually he is not a programmer at all. So he wasn't able to solve them. That's why he asked you to help him with these tasks. One of these tasks is the following.
A sequence of l integers b 1, b 2, ..., b l (1 ≤ b 1 ≤ b 2 ≤ ... ≤ b l ≤ n) is called good if each number divides (without a remainder) by the next number in the sequence. More formally
for all i (1 ≤ i ≤ l - 1).
Given n and k find the number of good sequences of length k. As the answer can be rather large print it modulo 1000000007 (109 + 7).
DeepL 翻译
马什莫克的老板比莫克不喜欢马什莫克。于是他解雇了他。Mashmokh 决定不去找新工作,而是去上大学并参加 ACM。他想成为巴莫克团队的一员。为了加入,他接到了一些编程任务,需要在一周内完成。Mashmokh 并不是一个经验丰富的程序员。事实上,他根本就不是程序员。所以他无法完成这些任务。这就是为什么他请求您帮助他完成这些任务。其中一项任务如下。
一个由 l 个整数 b 1, b 2, ..., b l 组成的序列称为 (1 ≤ b 1 ≤ b 2 ≤ ... ≤ b l ≤ n ) 。如果每个数都除以序列中的下一个数(没有余数),那么这个序列 (1 ≤ b 1 ≤ b 2 ≤ ... ≤ b l ≤ n) 就叫做 好数。更正式地说,
对于所有 i . (1 ≤ i ≤ l - 1) .
给定 n 和 k ,求长度为 k 的好序列的个数。由于答案可能相当大,请将其打印为模数 1000000007 (109 + 7) 。 (109 + 7) .
Input
The first line of input contains two space-separated integers n , k (1 ≤ n , k ≤ 2000).
DeepL 翻译
输入
第一行输入包含两个空格分隔的整数 n , k (1 ≤ n , k ≤ 2000) 。
Output
Output a single integer --- the number of good sequences of length k modulo 1000000007 (109 + 7).
DeepL 翻译
输出
输出一个整数 - 长度为 k modulo 1000000007 的良好序列的个数。 (109 + 7) .
Examples
Input
Copy
3 2Output
Copy
5Input
Copy
6 4Output
Copy
39Input
Copy
2 1Output
Copy
2Note
In the first sample the good sequences are: 1, 1, 2, 2, 3, 3, 1, 2, 1, 3.
DeepL 翻译
注意
在第一个样本中,好的序列是 1, 1, 2, 2, 3, 3, 1, 2, 1, 3 .
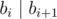
思路
总结一下题目让干啥 具体来说,题目让计算长度为 k 的序列个数,其中每个元素都是 1 到 n 之间的整数,且序列中每个元素都是前一个元素的倍数,我们举个例子,看题上给的样例序列长度为2时这五个1, 1, 2, 2, 3, 3, 1, 2, 1, 3 ,我们只要看末尾值,给末尾值找个倍数,在这个序列后面续上,这就能保证每个数都能整除后面的数,然后我们就可以继承上次长度的序列的个数了
从上面叙述来说,我们可以得到我们的dp数组和末尾的数以及当前序列的长度有关所以dpij表示以 i 结尾的长度为 j 的序列数量,看代码吧
cpp
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int mod=1e9+7;
int dp[2020][2020];
signed main() {
int n,k;
cin>>n>>k;
//每个数单独作为一个序列
for(int i=1;i<=n;i++) dp[i][1]=1;
for(int j=2;j<=k;j++){
for(int i=1;i<=n;i++){
for(int db=1;db*i<=n;db++){
(dp[i*db][j]+=dp[i][j-1])%=mod;
}
}
}
int ans=0;
for(int i=1;i<=n;i++){
(ans+=dp[i][k])%=mod;
}
cout<<ans<<endl;
return 0;
}A. Elimination
time limit per test
1 second
memory limit per test
256 megabytes
The finalists of the "Russian Code Cup" competition in 2214 will be the participants who win in one of the elimination rounds.
The elimination rounds are divided into main and additional. Each of the main elimination rounds consists of c problems, the winners of the round are the first n people in the rating list. Each of the additional elimination rounds consists of d problems. The winner of the additional round is one person. Besides, k winners of the past finals are invited to the finals without elimination.
As a result of all elimination rounds at least n ·m people should go to the finals. You need to organize elimination rounds in such a way, that at least n ·m people go to the finals, and the total amount of used problems in all rounds is as small as possible.
DeepL 翻译
2214 年 "俄罗斯代码杯 "竞赛的决赛选手将是在淘汰赛中获胜的参赛者。
淘汰赛分为正赛和附加赛。主淘汰赛每轮由 c 个问题组成,获胜者为评分表中排名前 n 位的选手。附加淘汰赛每轮由 d 道题组成。附加赛的获胜者为一人。此外,往届决赛的 k 名优胜者将被邀请参加决赛,无需参加淘汰赛。
所有淘汰赛的结果是至少有 n ·m 人进入决赛。您需要以这样一种方式组织淘汰赛,即至少有 n ·m 人进入决赛,并且所有淘汰赛中使用的问题总数越少越好。
Input
The first line contains two integers c and d (1 ≤ c , d ≤ 100) --- the number of problems in the main and additional rounds, correspondingly. The second line contains two integers n and m (1 ≤ n , m ≤ 100). Finally, the third line contains an integer k (1 ≤ k ≤ 100) --- the number of the pre-chosen winners.
DeepL 翻译
输入
第一行包含两个整数 c 和 d ( 1 ≤ c , d ≤ 100 ) --相应的主轮和附加轮的问题数。第二行包含两个整数 n 和 m ( 1 ≤ n , m ≤ 100 )。( 1 ≤ n , m ≤ 100 ).最后,第三行包含一个整数 k ( 1 ≤ k ≤ 100 ) --预选获胜者的人数。
Output
In the first line, print a single integer --- the minimum number of problems the jury needs to prepare.
DeepL 翻译
输出
第一行,打印一个整数--评委需要准备的问题的最少数量。
Examples
Input
Copy
1 10 7 2 1Output
Copy
2Input
Copy
2 2 2 1 2Output
Copy
0
思路
题目很长,先总结一下题意,就是有两类比赛,主轮比赛有c道题,可以有n个人通过,附轮有d道题,可以有1个人通过,,然后有k个人直接提前就通过了,现在问你通过至少n*m个人通过需要出最少几个题。。。咱可以反着说,主轮n个人的价值是c道题,附轮1个人的价值是d道题,现在问至少通过n*m个人的最小价值是几道题,,,可以看出背包的雏形了,然后这些题是无限的,所以是完全背包,就直接搞就行了,,重要的是这个至少俩字,问的是背包容量至少为n*m-k时候最少出几道题,我们要算一下要求的范围背包容量背包容量越大要出的题肯定是越多的这个是递增的,主轮分摊的是c/n.附轮分摊的是c/1所以如果,主轮分摊的多那我们全选主轮就好了,那我们是不是最多n*m个不需要再+1,附轮分摊的多就1个一个加上去,那直接n*m-k就行,就没必要再n*m个了,这其实也用到了点贪心,因为他就俩物品
cpp
#include<bits/stdc++.h>
using namespace std;
int f[10020];
int a[10];//物品的重量
int b[10];//物品的价值
//本题要求的是某个范围内的背包容量的最小价值
int main()
{
memset(f,0x3f,sizeof(f));
int c,d,n,m,k,v;
cin>>c>>d>>n>>m>>k;
if(n*m<=k)
{
cout<<0<<endl;
return 0;
}
v=n*m;
a[1]=n;
b[1]=c;
a[2]=1;
b[2]=d;
f[0]=0;
for(int i=1;i<=2;i++)
{
for(int j=a[i];j<=v;j++)
{
f[j]=min(f[j],f[j-a[i]]+b[i]);
}
}
int ans=INT_MAX;
for(int kk=0;kk<=k;kk++)
{
v=n*m-kk;
ans=min(ans,f[v]);
}
cout<<ans<<endl;
return 0;
}C. k-Tree
最近,一位富有创造力的学生 Lesha 听了一场关于树的讲座。讲座结束后,莱沙受到启发,想出了自己的树,他称之为 k 树。
k 树是一棵有无限根的树,其中:
- 每个顶点正好有 k 个子顶点;
- 每条边都有一定的权重;
- 如果我们查看从某个顶点到其子顶点的边(正好是 k 条边),那么它们的权重将等于 1, 2, 3, ..., k 。
莱莎的好朋友迪马一发现这棵树,就立刻产生了疑问:"从一棵 k 树的根开始,至少有一条边的权重至少为 d ,那么有多少条总权重为 n (路径中所有边的权重之和)的路径呢?由于方法的数量可能相当大,请打印出模数 1000000007 ( 109 + 7 )。
输入
一行包含三个空格分隔的整数: n 、 k 和 d 。( 1 ≤ n , k ≤ 100; 1 ≤ d ≤ k ).
输出
打印一个整数 - 问题的答案模为 1000000007 ( 109 + 7 )。
Examples
Input
Copy
3 3 2Output
Copy
3Input
Copy
3 3 3Output
Copy
1Input
Copy
4 3 2Output
Copy
6Input
Copy
4 5 2Output
Copy
7
思路:
题目意思是 从根节点出发,总权重恰好为n(路径上所有边的权重之和),且至少有一条边的权重至少为d的路径有多少条?答案需要对1000000007取模。
初始化
f00 = 1:总权重为0时,只有空路径一条路径,且没有边,因此所有边都小于d(满足j=0)所以是一个方案。
f01 = 0:总权重为0时,没有边,因此不可能有边权重大于等于d。所以就0个方案
动态规划过程
遍历总权重i从1到n。
对于每个i,遍历可能的边权重j从1到k(表示当前选择的边的权重)。
如果j > i,则跳过(因为边权重大于总权重,无法构成路径)。
如果j >= d,则当前边的权重至少为d,因此无论之前的路径状态如何,添加这条边后路径都会满足至少有一条边权重大于等于d。于是:
fi1 += fi - j0 + fi - j1(从状态i-j转移过来)。
如果j < d,则当前边的权重小于d,因此路径状态保持不变。于是:
fi0 += fi - j0(之前所有边都小于d,现在仍然都小于d)。
fi1 += fi - j1(之前至少有一条边权重大于等于d,现在仍然如此)。
每次加法后都对结果取模,防止溢出。
cpp
#include<bits/stdc++.h>
using namespace std;
const int mod=1e9+7;
long long dp[120][2];
//dp[i][j],i是边权总重,j是是否有一个边权大于等于d,0 1表示
int main(){
int n,k,d;
cin>>n>>k>>d;
dp[0][1]=0;//边权总重为0时候,肯定没有大于等于d的边权所以情况为0
dp[0][0]=1;//边权总重为0时候,肯定有一个大于等于d的边权所以情况为1
for(int i=1;i<=n;i++){
for(int j=1;j<=k;j++){
if(j>i) break;//单个边权肯定不可能大于总重所以直接break就行
if(j>=d){
dp[i][1]+=dp[i-j][0]+dp[i-j][1];
dp[i][1]%=mod;
}
else{
(dp[i][0]+=dp[i-j][0])%=mod;
(dp[i][1]+=dp[i-j][1])%=mod;
}
}
}
cout<<dp[n][1];
}C. Woodcutters
小苏西每天睡前都要听童话故事。今天的童话故事讲的是砍柴人的故事,小女孩立刻开始想象砍柴人砍柴的情景。她想象出了下面描述的情形。
沿路有 n 棵树,坐标为 x 1, x 2, ..., x n 。每棵树的高度为 h i 。伐木工人可以砍倒一棵树,并将其砍向左边或右边。之后,它就会占据 *x* *i* - *h* *i* , *x* *i* 或 *x* *i* ;*x* *i* + *h* *i* 中的一段。未被砍伐的树木占据坐标为 x i 的一个点。如果倒下的树所占据的线段不包含任何被占据的点,伐木工人就可以砍树。伐木工人希望尽可能多地砍伐树木,因此苏西想知道最多可以砍伐多少棵树?
输入
第一行包含整数 n ( 1 ≤ n ≤ 105 )--树木数量。( 1 ≤ n ≤ 105 ) - 树的数量。
接下来的 n 行包含一对整数 x i , h i ( 1 ≤ x i , h i ≤ 109 ) - 第 і 棵树的坐标和高度。
这两对整数按 x i 升序排列。没有两棵树位于坐标相同的点上。
输出
打印一个数字--根据给定规则可以砍伐的最大树木数量。
Examples
Input
5 1 2 2 1 5 10 10 9 19 1Output
3
Input
5 1 2 2 1 5 10 10 9 20 1 Output 4 注意在第一个示例中,你可以这样砍树:
- 把第 1 棵树砍到左边--现在它占据了 - 1;1 段。
- 砍掉右边的第 2 棵树,现在它占据了 2;3 段。
- 留下第 3 -棵树--它占据了 5 点。
- 离开第 4 棵树--它占据了第 10 点。
- 把第 5 棵树向右倒下--现在它占据了 19;20 段。
在第二个示例中,您也可以将第 4 棵树向右砍伐,砍伐后它将占据点段 10;19 。
思路:
这道题说的是,一个人砍树,可以向右向左砍,但如果砍了后倒下的区域会覆盖到其他树,那就不能砍,然后倒下的区域是x i - h i , x i ] 或 *x* *i* ;*x* *i* + *h* *i* 中的一段(也就是向左的区域和向右的区域),现在问,最多能砍多少数树,我们定义dpij,i代表现在针对的当前第i颗树,j是当第i棵树的状态(0代表不砍这棵树,1代表砍了向左倒,2代表砍了向右倒),dpij的大小是,当前前i颗树砍的最大数量,状态转移方程看代码就行
cpp
#include<bits/stdc++.h>
using namespace std;
int x[100020];
int h[100020];
int dp[100020][3];
int main(){
int n;
cin>>n;
for(int i=1;i<=n;i++){
cin>>x[i]>>h[i];
}
dp[1][1]=1;
dp[1][2]=x[2]>x[1]+h[1];
x[n+1]=2000000001;
for(int i=2;i<=n;i++){
dp[i][0]=max(max(dp[i-1][0],dp[i-1][1]),dp[i-1][2]);
//第一种情况,向左倒
//向左倒,第i-1颗树向右1倒的情况
if(h[i-1]+x[i-1]<x[i]-h[i]){
dp[i][1]=dp[i-1][2]+1;
}
//向左倒,第i-1颗树不倒和向左倒的情况
if(x[i-1]<x[i]-h[i]){
dp[i][1]=max(dp[i][1],max(dp[i-1][1]+1,dp[i-1][0]+1));
}
//向右倒
if(x[i]+h[i]<x[i+1]){
dp[i][2]=max(max(dp[i-1][0],dp[i-1][1]),dp[i-1][2])+1;
}
}
cout<<max(max(dp[n][0],dp[n][1]),dp[n][2]);
return 0;
}C. Basketball Exercise
最后,SIS 启用了一个篮球场,因此 Demid 决定举行一次篮球训练。 2⋅n 名学生来到德米德的训练场,德米德将他们排成大小相同的两排(每排正好有 n 人)。每排从 1 到 n 的学生从左到右依次编号。
现在,Demid 想要选择一支球队打篮球。他将从左到右选择球员,每个被选中的球员(不包括第一个被选中的****)的指数将严格大于之前被选中的球员的指数。为了避免优先选择其中一行,德米德在选择学生时不会让连续被选中的学生属于同一行。第一个学生可以从所有 2n 学生中选出(没有其他限制),一个团队可以由任意数量的学生组成。
Demid 认为,为了组成一个完美的团队,他在选择学生时应尽可能使所有被选学生的总身高最大。请帮助 Demid 找出他可以选择的球队中球员总身高的最大值。
输入
输入的第一行包含一个整数 n ( 1≤n≤105 )--每行的学生人数。( 1≤n≤105 ) - 每行的学生人数。
输入的第二行包含 n 个整数 h1,1,h1,2,...,h1,n ( 1≤h1,i≤109 ),其中 h1,i 是第一行中 i -th 学生的身高。
输入的第三行包含 n 个整数 h2,1,h2,2,...,h2,n ( 1≤h2,i≤109 )。( 1≤h2,i≤109 ) ,其中 h2,i 是第二行中第 i 个学生的身高。
输出
打印一个整数--Demid 可以选择的球队中球员的最大总身高。
Input
Copy
5 9 3 5 7 3 5 8 1 4 5Output
Copy
29Input
Copy
3 1 2 9 10 1 1Output
Copy
19Input
Copy
1 7 4Output
Copy
7
思路:
这题主要就是说 需要帮助Demid选择一组学生,使得他们的总身高最大,同时满足选择顺序从左到右且索引严格递增,且不能连续选择同一排的学生。也就是说每一列只能选其中一个并且不能连续选同一行,我们可以这样设dp数组dpij,i代表就是每一行的每一列,j代表这一列的状态,选上面还是选下面还是不选,那我们就可以想到递推公式
dpi0=max(max(dpi-10,dpi-11),dpi-12);
dpi1=max(dpi-10,dpi-12)+ai;
dpi2=max(dpi-10,dpi-11)+bi;
cpp
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N=1e5+20;
int dp[N][3];
int a[N],b[N];
int n;
signed main(){
cin>>n;
for(int i=1;i<=n;i++){
cin>>a[i];
}
for(int i=1;i<=n;i++){
cin>>b[i];
}
dp[1][1]=a[1];
dp[1][2]=b[1];
for(int i=2;i<=n;i++){
dp[i][0]=max(max(dp[i-1][0],dp[i-1][1]),dp[i-1][2]);
dp[i][1]=max(dp[i-1][0],dp[i-1][2])+a[i];
dp[i][2]=max(dp[i-1][0],dp[i-1][1])+b[i];
}
cout<<max(max(dp[n][0],dp[n][1]),dp[n][2]);
return 0;
}这个文章就到这了,我也到校了嘿嘿