编者按: 强化学习能否像 GPT-3 改变自然语言处理那样,通过大规模扩展实现质的飞跃?为什么强化学习至今仍困在"先预训练,再微调"的传统模式中?为什么即使是最先进的 RL 模型,一旦脱离训练环境就变得如此脆弱?
无论是自动驾驶、机器人控制,还是复杂系统优化,我们都需要能够快速适应新任务、具备真正泛化能力的智能体。然而当前的 RL 模型就像是"高分低能"的应试选手 ------ 在熟悉的测试环境中表现优异,但面对真实世界的复杂性时却束手无策。
本文提出了 replication training 范式,为强化学习的规模化扩展指明了全新方向。作者不再拘泥于传统的游戏环境或仿真场景,而是大胆提议让 AI 复制现有的软件产品。它利用了互联网上丰富的软件资源,提供了客观明确的评估标准,同时训练了 AI 在长周期项目中保持稳定输出的能力。
作者 | Matthew Barnett, Tamay Besiroglu, Ege Erdil
编译 | 岳扬
GPT-3 证明了,仅仅通过扩大语言模型的规模,就能带来强大的、task-agnostic(译者注:模型不依赖特定任务的设计或微调,就能处理多种不同类型的任务。)、few-shot(译者注:模型仅需极少量示例,就能快速理解并执行新任务。)的性能,其表现通常优于经过精心微调的模型。在 GPT-3 出现之前,要达到最先进的性能,首先需要在大型通用文本语料库上对模型进行预训练,然后再针对特定任务进行微调。
如今的强化学习同样困在类似 GPT-3 之前的范式里。我们首先是对大模型进行预训练,然后在高度专业化的环境中,对特定任务进行精细的微调。但这种方法的根本局限在于:由此获得的能力难以泛化,导致性能"脆弱"(brittle performance) ------ 模型一旦脱离训练期间接触的精确语境,性能便会迅速退化。
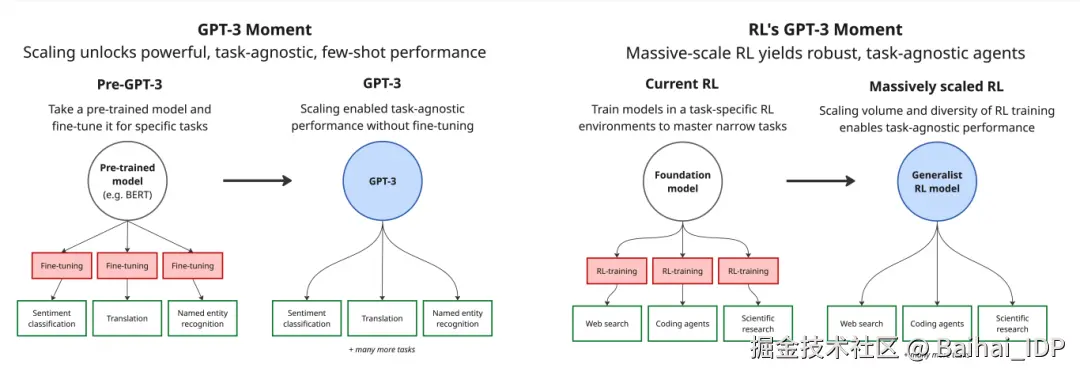
我们认为强化学习(RL)即将迎来其"GPT-3 时刻"。相比在有限数量的训练场景或任务设置上微调模型,我们预计该领域将转向在数千个多样化环境上进行大规模训练。有效实施这一做法将催生出具有 few-shot、task-agnostic 能力的 RL 模型,能够快速适应全新的任务。但实现这一点需要训练环境在规模和多样性上远超当前任何的可用资源。
01 究竟需要多少 RL 资源?
当前的 RL 数据集相对较小。例如,DeepSeek-R1 在大约 60 万个数学问题上进行了训练,这相当于人类连续努力六年的工作量(假设每个任务耗时五分钟完成)。相比之下,重建 GPT-3 那包含 3000 亿 token 的训练语料库,若按人类平均书写速度计算,需要大约数万年的写作时间。
需要说明的是,要达到与当前前沿模型预训练预算相当的 RL 计算支出,按人类完成相同任务所需时长来衡量,可能需要大约上万年。 DeepSeek-R1 在 RL 阶段使用了约 6e23 FLOP 的计算量1,按人类效率折算,对应约 6 年的时长。假设未来的训练任务使用与 DeepSeek-R1 相似的训练轮次(epochs)和组大小(group sizes),将此扩展至约 6e26 FLOP 意味着需要人类约 6000 年的工作时长。
尚不确定未来的强化学习训练会需要更大的还是更小的组规模(group sizes)、抑或是更多的训练轮次(epochs),尤其是随着任务分布多样性的增加。我们在这方面缺乏足够的数据,因此精确估算等效的人类工作时间仍很困难,尽管 1 万年左右似乎是一个较为合理的数量级。
这一过程要求模型完成的工作量,其规模可与 Windows Server 2008、GTA V 或 Red Hat Linux 7.1 等大型项目相当 ------ 每个项目估计都需要约 1 万年的累计人类工作量。
将强化学习(RL)扩展到这一规模在经济上是高效的。由于算力成本在总训练成本中占据主导地位,将强化学习的规模提升到与预训练预算相当的水平,能在不明显增加总成本的情况下带来大幅的性能提升。 然而,要实现这一目标,就必须大规模扩展强化学习环境(RL environments)的体量,同时确保任务能够实现自动化评估。这很可能需要开发新的构建强化学习环境的方法。
02 Replication training
想象一下,每次当你想要通过下一个词预测方法(next-token prediction)预训练语言模型时,都必须亲手创建整个训练语料库。显然,这极其不切实际。因此,我们转而利用海量的现有内容 ------ 如书籍、学术论文、博客帖子和 Reddit 讨论内容来构建训练语料库。
同样,我们推测,RL(强化学习)领域的"GPT-3 时刻"将主要依托于一种称为 replication training 的新范式来实现。 该范式要求 AI 复制现有的软件产品或其内部特定功能。实现复杂的哈希与加密算法的简单命令行工具是较为理想的初期目标,这种方案可以轻松扩展到更复杂的软件,例如网站、专业软件和游戏。
每项复制任务(replication tasks)均包含详细的说明规范和用于参考的实现方案。其核心思想是,AI 模型经过训练后能够生成与用于参考的实现方案完全一致的方案。这种清晰直接的方法极大地简化了评估过程,因为评分标准客观且明确:生成的实现方案的行为要么与用于参考的实现方案完全一致,要么就是不一致。
尽管这些复制任务(replication tasks)可能与日常的软件工程活动有所不同,但它们专门针对当前 AI 系统难以掌握的关键能力。例如,复制一个复杂的算法(如依据详细规范进行开发的、包含万行量级代码的加密/解密 CLI 工具),要求模型必须做到:
- 准确阅读并深度理解详细指令。
- 一丝不苟且精确无误地执行指令。
- 能够发现早期错误并可靠地恢复。
- 在长时间周期(相当于人类数月时间的开发工作量)内保持稳定输出 ------ 在此过程中,质量优劣完全由功能正确性直接判定。
- 在遇到困难时展现出韧性,而非草率止步于看起来"差不多能用"的方案。
我们预测,replication training 将成为 AI 领域的下一个范式,因为它顺延了我们在 AI 发展过程中已观察到的趋势 ------ 利用海量的现有人类生成数据来创建新任务。就像自然语言一样,软件在互联网上同样资源丰富。因此,replication training 提供了一种可扩展的途径,能高效生成复杂任务,推动我们实现可端到端完成完整软件项目的 AI。
然而,这种方法也面临着几项挑战。编写有效且全面的测试仍然是一项非同小可的任务,需要大量的工程投入。此外,复制任务(replication tasks)本身具有一定的人造性,因为精确复制现有软件并非日常软件工程的典型工作(尽管在软件移植、遗留系统重构、净室重新实现【译者注:clean-room reimplementations,指在严格隔离原始代码知识的前提下,仅通过分析功能规范或外部行为,重新实现与原有软件功能相同的程序。该过程需确保开发团队从未接触过原始源代码,以避免法律上的版权/专利侵权风险。】)等场景中确有其例。
尽管存在这些挑战,但我们认为 replication training 为将强化学习环境(RL environments)扩展到实现有意义泛化所需的庞大规模提供了一条清晰明确的路径。它很可能将成为解锁强化学习"GPT-3 时刻"的关键,为达成稳健的、task-agnostic 的性能提供所需的数万年量级的经验积累。
replication training 会是解锁 full automation of labor(译者注:通过 AI / 机器人系统实现人类所有劳动形式的自动化替代,达到无需人类直接参与即可完成经济生产活动的终极状态。)的终极范式吗?对此我们持怀疑态度。虽然它能催生可在精确设计规范下自主完成高复杂度软件项目的系统,但我们推测,这些能力仍将逊色于人类所具备的开放式能力。即便 AI 成为高级编程专家,它们在狭窄的软件领域之外的高层管理(译者注:high-level management,指组织架构中涉及战略决策、资源分配和跨部门协调的顶层管理职能。)与自主规划(agentic planning)方面也未必能胜任。
然而,正如我们需要先发明预训练,才能迈向 replication training,replication training 仍可作为通往下一范式的桥梁。我们对这一新范式的未来潜力充满期待。
END
本期互动内容 🍻
❓您预测 RL 领域的"GPT-3时刻"会在什么时间节点出现?3 年内、5-10 年,还是更久?请分享您的判断依据。
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: