用户可自主手动管理一些希望大模型能够记忆的内容,进而增强大模型的能力,满足用户个性化的需求。本文将对open webui的记忆功能的使用进行讲解,然后对相关源码进行分析。
一、记忆管理
用户通过设置---> 个性化进入记忆管理页面:
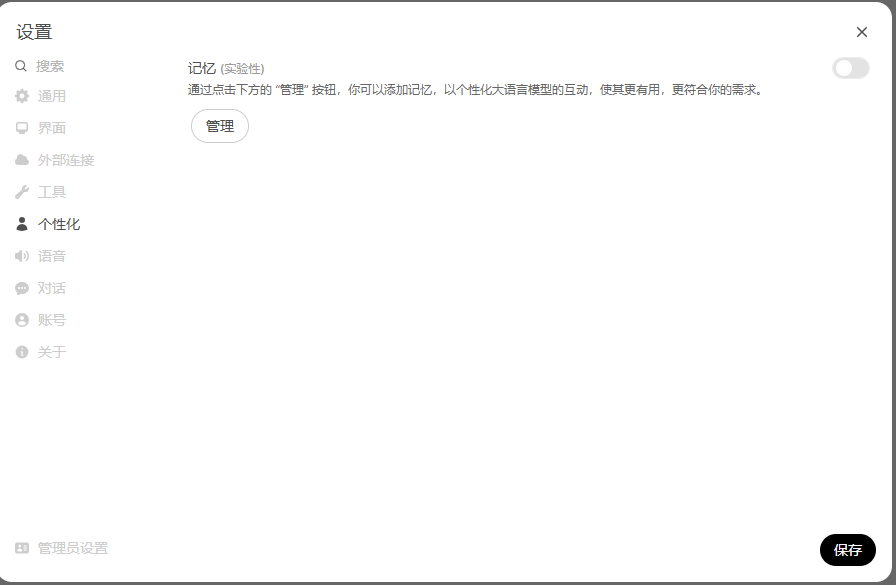
在该管理页面,先启用该功能,然后点击管理,进入记忆列表页面:
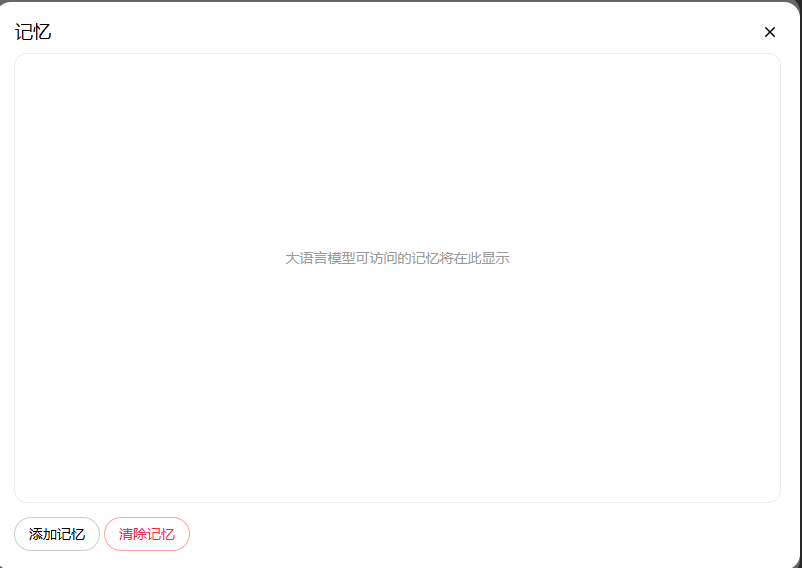
在该页面用户可以信增加记忆,也可以对已有的记忆进行删除。用户点击【添加记忆】,弹出录入对话框:

用户在此录入关于自己的相信信息,并店家【添加】后,完成记忆的增加,比如:
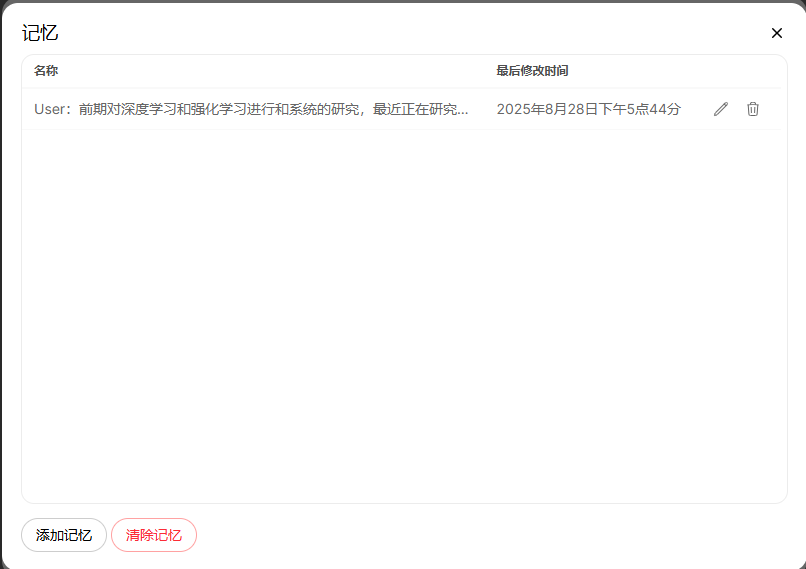
二、记忆管理分析
1)数据模型
记忆相关的表为memory,表定义如下:

该表的字段含义一目了然,无需赘述。
2)增加记忆
增加记忆时,前端提交数据如下:
{
"content":"User:正在研读open webui的使用和源代码,学习的同时针对不同的功能编写博客,分享给同道者。"
}
增加记忆时,源码如下:
该方法也非常简单。首先调用Memories.insert_new_memory把记忆数据查询到memory表中,然后调用VECTOR_DB_CLIENT.upsert方法把文档插入到向量库的user_memory_{user.id}集合中,供用户与大模型对话时查询使用,最后把记忆数据记录返回到前端。
@router.post("/add", response_model=OptionalMemoryModel)
async def add_memory(
request: Request,
form_data: AddMemoryForm,
user=Depends(get_verified_user),
):
memory = Memories.insert_new_memory(user.id, form_data.content)
VECTOR_DB_CLIENT.upsert(
collection_name=f"user-memory-{user.id}",
items=[
{
"id": memory.id,
"text": memory.content,
"vector": request.app.state.EMBEDDING_FUNCTION(
memory.content, user=user
),
"metadata": {"created_at": memory.created_at},
}
],
)
return memory
三、使用记忆分析
1)请求数据
与联网搜索类似,请求数据中对应的特征为true,具体如下:

2)源码分析
使用记忆代码入口在process_chat_payload中,具体如下:
核心代码是调用chat_memory_handler方法,完成记忆相关的处理。
async def process_chat_payload(request, form_data, user, metadata, model):
......
features = form_data.pop("features", None)
if features:
if "memory" in features and features"memory":
form_data = await chat_memory_handler(
request, form_data, extra_params, user
)
......
接下来对chat_memory_handler方法进行分析:
本方法流程如下:
1)先调用query_memory得到文档查询结果,最多为3个。
2)把查询结果按照{doc_idx+1}.创建日期{doc}格式拼接到user_context
3)把"User Context:\n{user_context}\n"插入到表单messages的系统消息中,作为上下文
4)返回更新后的表单内容
async def chat_memory_handler(
request: Request, form_data: dict, extra_params: dict, user
):
try:
results = await query_memory(
request,
QueryMemoryForm(
**{
"content": get_last_user_message(form_data"messages") or "",
"k": 3,
}
),
user,
)
except Exception as e:
log.debug(e)
results = None
user_context = ""
if results and hasattr(results, "documents"):
if results.documents and len(results.documents) > 0:
for doc_idx, doc in enumerate(results.documents0):
created_at_date = "Unknown Date"
if results.metadatas0doc_idx.get("created_at"):
created_at_timestamp = results.metadatas0doc_idx"created_at"
created_at_date = time.strftime(
"%Y-%m-%d", time.localtime(created_at_timestamp)
)
user_context += f"{doc_idx + 1}. {created_at_date} {doc}\n"
form_data"messages" = add_or_update_system_message(
f"User Context:\n{user_context}\n", form_data"messages", append=True
)
return form_data
最后分析一下query_memory方法的源码:
该方法很简单,从向量库的user_memory_{user.id}集合查询出与用户问题关联度高的文档
@router.post("/query")
async def query_memory(
request: Request, form_data: QueryMemoryForm, user=Depends(get_verified_user)
):
results = VECTOR_DB_CLIENT.search(
collection_name=f"user-memory-{user.id}",
vectors=request.app.state.EMBEDDING_FUNCTION(form_data.content, user=user),
limit=form_data.k,
)
return results