概述
文本处理和查询处理系统将自然语言查询转换为与 RAGFlow 的文档存储后端配合使用的优化搜索表达式。该系统支持中英文文本处理,具有专门的标记化、术语加权和查询增强技术。
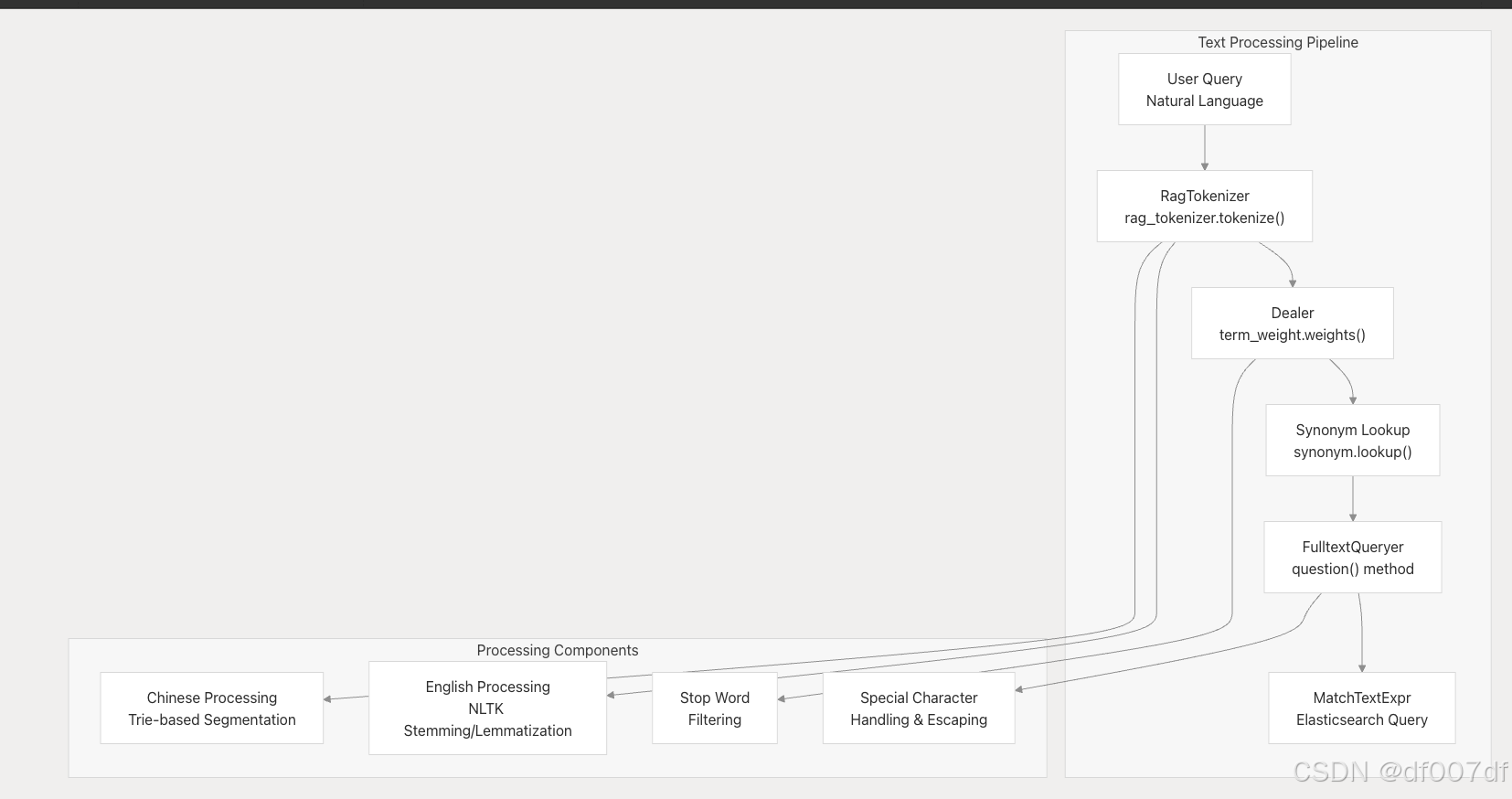
核心组件
FulltextQueryer 类
FulltextQueryer 类是查询处理和文本分析的主要接口。它协调标记化、术语加权和查询构造。
| 元件 | 目的 | 关键方法 |
|---|---|---|
| FulltextQueryer | 主查询处理控制器 | question()、paragraph()、hybrid_similarity() |
| RagTokenizer | 文本标记化和分段 | tokenize()、fine_grained_tokenize() |
| Dealer | 术语加权和预处理 | 权重()、 预代币()、拆分() |
系统使用预定义的查询字段进行初始化,这些字段在搜索期间接收不同的提升权重:
query_fields = [
"title_tks^10", # Title tokens (highest boost)
"title_sm_tks^5", # Title small tokens
"important_kwd^30", # Important keywords (highest boost)
"important_tks^20", # Important tokens
"question_tks^20", # Question tokens
"content_ltks^2", # Content large tokens
"content_sm_ltks" # Content small tokens (base weight)
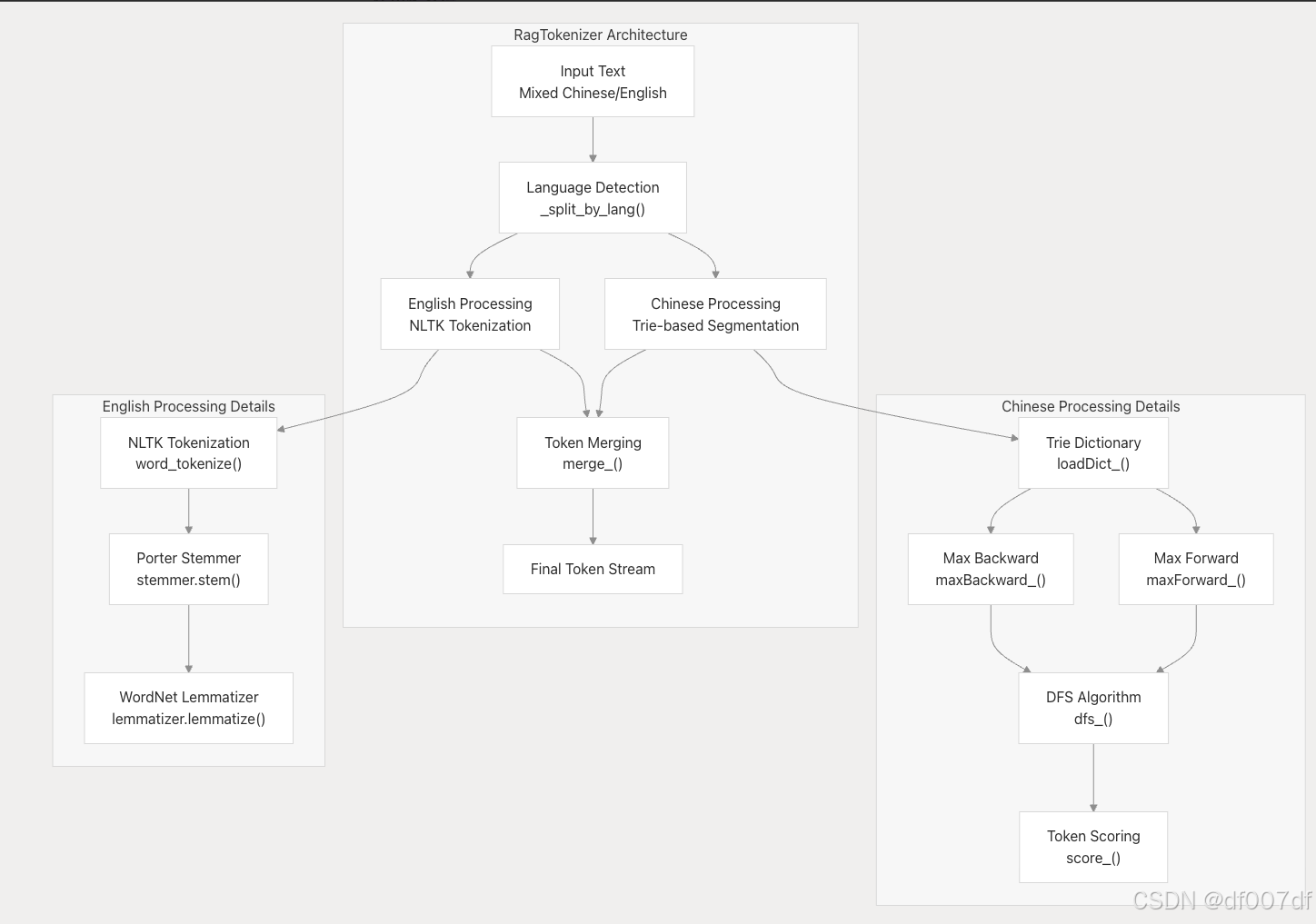
]代币化系统
RagTokenizer 使用基于 trie 的方法进行中文文本分割,使用 NLTK 进行英文处理:
术语权重和评分
Dealer 类使用 IDF 分数和语言特征实现复杂的术语加权:
| 加权因子 | 公式 | 目的 |
|---|---|---|
| 频率 IDF | log10(10 + (N - s + 0.5) / (s + 0.5)) | 惩罚常用术语 |
| 文档频率 IDF | 与文档计数类似的公式 | 上下文感知权重 |
| NER 权重 | 命名实体类型乘数 | 提升重要实体 |
| POS 重量 | 基于词性的评分 | 语法重要性 |
最终权重结合了以下因素: (0.3 * freq_idf + 0.7 * df_idf) * ner_weight * pos_weight
查询处理管道
问题处理
question() 方法将用户查询转换为与 Elasticsearch 兼容的查询表达式:
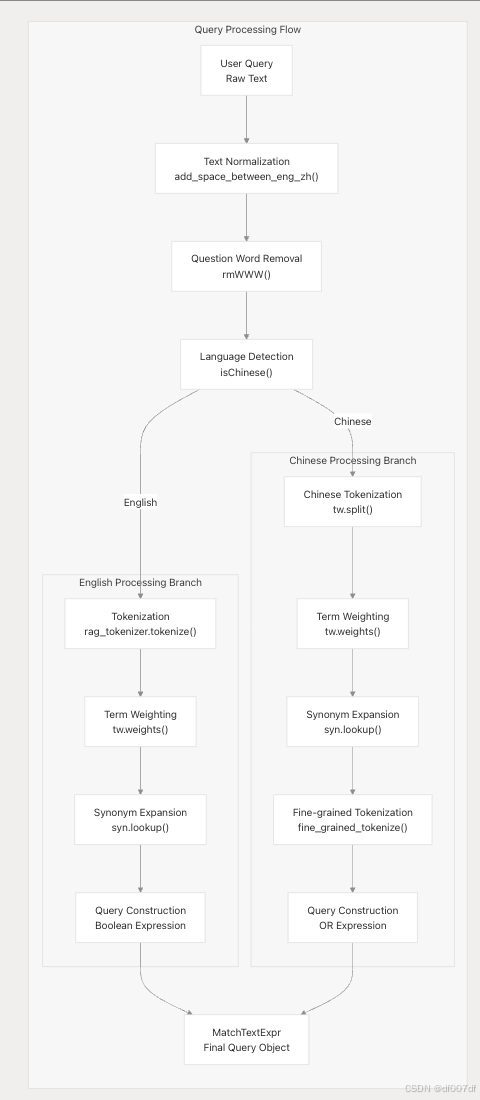
文本预处理函数
该系统包括几个文本预处理实用程序:
| 功能 | 目的 | 实现 |
|---|---|---|
| subSpecialChar() | 转义 Elasticsearch 特殊字符 | re.sub(r"(:{}/\[-*"() |
| isChinese() | 检测中文文本优势 | 基于比率的性格分析 |
| rmWWW() | 删除疑问词和停用词 | 基于正则表达式的多种语言过滤 |
| add_space_between_eng_zh() | 在英文和中文之间添加空格 | 基于正则表达式的文本规范化 |
相似性计算
混合相似性评分
hybrid_similarity() 方法将向量相似性与基于标记的相似性相结合:
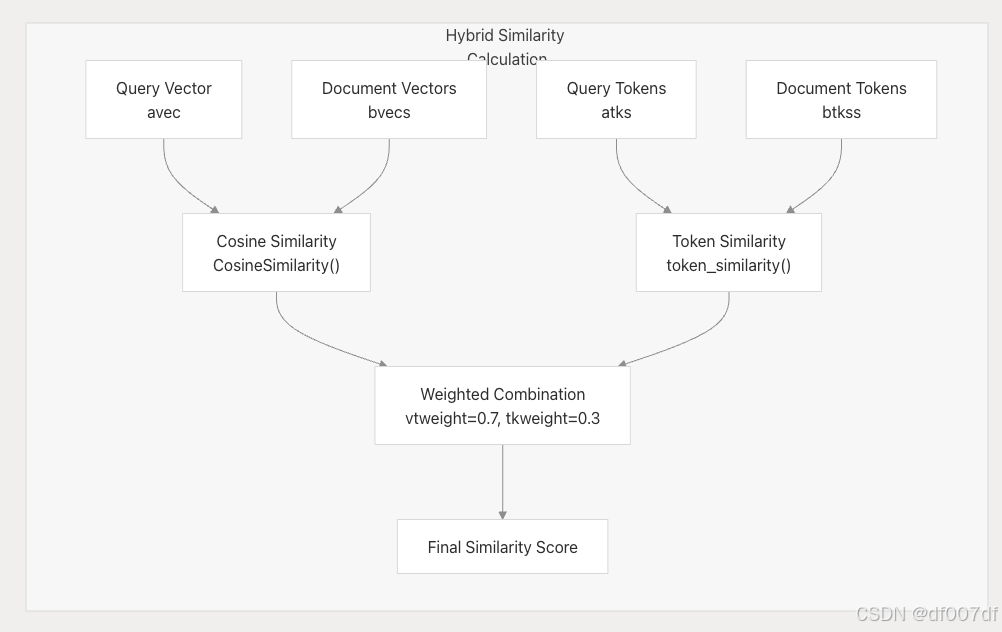
公式为: vector_sim * 0.7 + token_sim * 0.3
代币相似度算法
代币相似性使用加权术语匹配:
# Simplified version of the similarity calculation
def similarity(self, qtwt, dtwt):
s = 1e-9 # Small constant to avoid division by zero
for k, v in qtwt.items():
if k in dtwt:
s += v # Add query term weight if present in document
q = 1e-9 # Query normalization factor
for k, v in qtwt.items():
q += v # Sum all query term weights
return s/q # Normalized similarity score段落处理
paragraph() 方法通过从文本内容中提取和加权关键术语来生成基于内容的检索查询:
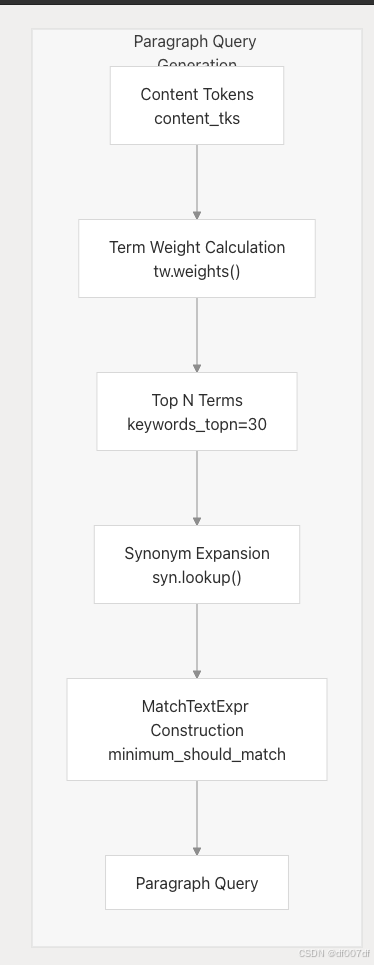
该方法构造具有动态最小匹配要求的查询:min(3, len(keywords) // 10)
与文档存储集成
查询处理系统生成与 RAGFlow 的文档存储层集成的 MatchTextExpr 对象:
| 参数 | 目的 | 示例值 |
|---|---|---|
| query_fields | 要使用权重搜索的字段 | "title_tks\^10", "content_ltks\^2" |
| query_string | Elasticsearch 查询表达式 | (term1^1.5 OR synonyms^0.2) |
| boost | 总体查询提升因子 | 100 |
| minimum_should_match | 最低匹配项 | 0.6 或 3 |
配置和定制
系统使用多个可配置资源:
| 资源 | 位置 | 目的 |
|---|---|---|
| 字典 | rag/res/huqie.txt | 中文分割词典 |
| NER 数据 | rag/res/ner.json | 命名实体识别映射 |
| 术语频率 | rag/res/term.freq | 文档频率统计 |
| 停用词 | 内置套装 | 要过滤的常用词 |