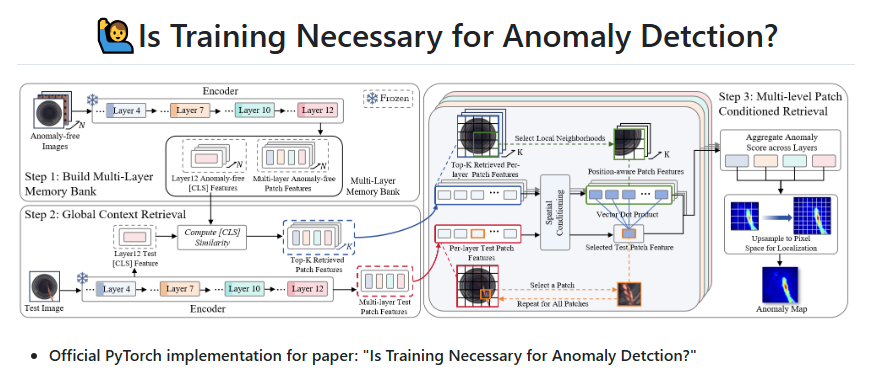
开源项目地址:https://github.com/longkukuhi/RAD
检测效果:
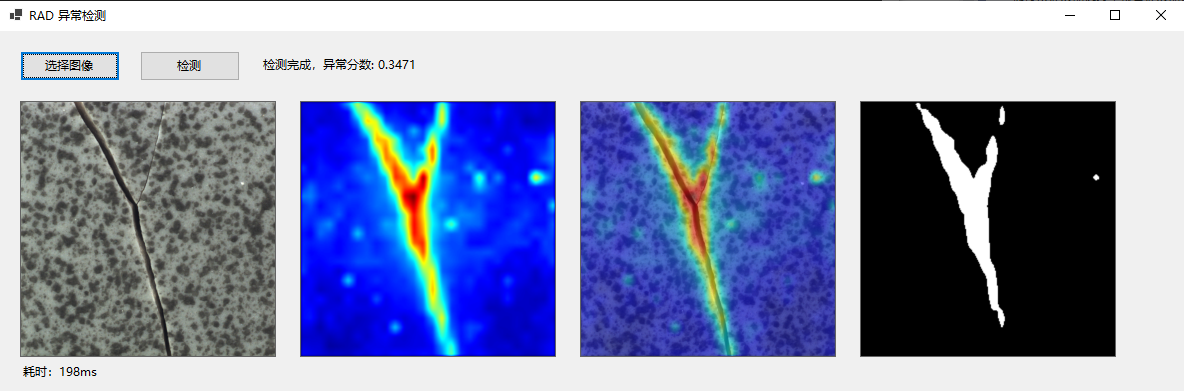
此处展示的是C#中OpenvinoSharp加载onnx模型并配合构建的多层特征记忆库进行缺陷检测的实测效果,大家可以参考文后的Python转换及推理代码,进行C#代码编写
文件功能详解
1. dataset.py
作用:定义各个数据集的 Dataset 类,并封装数据增强方法。
主要类/函数:
-
get_data_transforms(size, isize, mean_train, std_train):返回训练/测试时使用的图像变换组合(resize → ToTensor → center crop → normalize)。 -
get_strong_transforms:更强的数据增强(随机裁剪、翻转、色彩抖动),主要用于某些需要增强的场景。 -
MVTecDataset:加载 MVTec AD 数据集,支持 train/test 阶段,自动匹配图像与对应的 ground truth 掩码。
-
RealIADDataset:加载 Real‑IAD 数据集,根据 JSON 描述文件组织图像和掩码路径。
-
LOCODataset:加载 LOCO 数据集(逻辑与结构异常检测)。
-
其他数据集类:包括 InsPLADDataset、AeBADDataset、MVTecDRAEMDataset(用于合成异常训练)、MVTecSimplexDataset(使用 simplex 噪声生成异常样本)等。
相互关系:其他脚本(如构建记忆库、评估)通过该类获取数据。
2. build_bank_multilayer.py
作用 :为 MVTec AD、VisA 或 3D‑ADAM 构建多层特征记忆库。
关键步骤:
-
解析命令行参数,包括数据路径、要处理的类别列表、DINOv3 模型名称与权重、图像尺寸、批大小、要提取的层索引(如
3 6 9 11)、输出文件路径。 -
调用
get_data_transforms获得图像变换,用ImageFolder读取每个类别的train目录(所有图像均为正常样本),并将所有类别的正常样本合并为一个ConcatDataset。 -
使用
IndexedDataset包装,使每次返回样本时同时返回索引,便于后续索引操作。 -
加载 DINOv3 模型并设置为评估模式。
-
调用
build_memory_bank_multilayer函数:-
遍历数据集,对每批图像调用
encoder.get_intermediate_layers(..., return_class_token=True),获得指定层的 patch token 和 CLS token。 -
将每一层的特征分别收集到列表中,最后用
torch.cat合并为完整的特征矩阵。 -
返回层索引列表、CLS 特征列表(每个元素形状
[N, C])和 patch 特征列表(每个元素形状[N, L, C])。
-
-
保存结果到指定的
.pth文件。
输出 :一个包含 layers、cls_banks、patch_banks 三个字段的字典文件。
3. build_realiad_bank_multilayer.py
作用 :与 build_bank_multilayer.py 完全相同,但专门针对 Real‑IAD 数据集。
差异点:
-
使用
RealIADDataset而非ImageFolder读取数据。 -
命令行参数中的默认类别列表为 Real‑IAD 的 30 个类别。
-
数据路径指向 Real‑IAD 的根目录。
4. rad_mvtec_visa_3dadam.py
作用:对 MVTec AD、VisA 或 3D‑ADAM 进行异常检测评估。
主要流程:
-
解析参数:数据路径、记忆库路径、DINOv3 配置、保存目录、KNN 参数(
k_image)、图像级分数聚合方式(max_ratio)、是否使用位置感知记忆库(use_positional_bank)、层融合权重(layer_weights)等。 -
准备测试数据:为每个类别创建对应的 Dataset(MVTecDataset 或 ImageFolder),并构建 DataLoader。
-
加载 DINOv3 模型和预先构建的记忆库(包含多层 CLS 与 patch 特征)。
-
对每个类别调用
eval_patch_knn_multilayer_cluster函数:-
提取测试图像的指定层特征(patch tokens 和 CLS tokens)。
-
使用最高层的 CLS 特征与记忆库中所有 CLS 特征计算相似度,选出最相似的
k_image个训练样本。 -
对于每一层,将测试 patch 特征与选出的训练样本的 patch 特征进行余弦相似度计算,得到每个 patch 的异常分数(1 - 最大相似度)。若启用
use_positional_bank,则每个 patch 只与训练样本中对应位置邻域内的 patch 比较。 -
将各层的异常分数按权重融合,得到最终 patch 级异常分数,重塑为特征图并上采样到指定大小(
resize_mask)。 -
应用高斯平滑,与 ground truth 对齐后收集像素级和图像级的预测分数。
-
计算各类指标:AUROC(图像/像素)、AP、F1、AUPRO(PRO 曲线下面积)。
-
-
记录每个类别的结果,输出均值。
可视化 :若指定 vis_dir,会为部分测试样本生成包含输入图像、最近邻训练图像、异常热图、GT 掩码的对比图。
5. rad_real_iad.py
作用 :针对 Real‑IAD 的评估脚本,逻辑与 rad_mvtec_visa_3dadam.py 几乎一致。
差异点:
-
使用
RealIADDataset加载测试数据。 -
默认参数值根据 Real‑IAD 特点调整(如
k_image=900)。 -
函数
eval_patch_knn_multilayer_cluster内部完全相同(因为特征提取和检索逻辑与数据集无关)。
6. utils.py
作用:提供各种辅助函数,供评估脚本和可能的训练脚本使用。
主要函数:
-
指标计算 :
roc_auc_score、average_precision_score(实际调用 sklearn)、f1_score_max(通过 PR 曲线寻找最佳阈值)、compute_pro(计算 PRO 曲线下面积,用于像素级评估)。 -
图像处理:
-
min_max_norm、cvt2heatmap、show_cam_on_image:将异常图转换为彩色热图并叠加在原图上。 -
get_gaussian_kernel:生成高斯平滑卷积核,用于对异常图进行平滑。
-
-
评估函数:
-
evaluation_batch、evaluation_batch_mae、evaluation_uniad:用于不同模型的批量评估(可能用于对比实验)。 -
save_eval_visualization和save_eval_visualization_masked:保存评估时的可视化结果。
-
-
损失与梯度操作 :
global_cosine、global_cosine_focal等,可能用于需要训练的场景(但本项目核心无需训练)。 -
学习率调度 :
WarmCosineScheduler。
文件之间的相互关系
下图概括了各模块的依赖关系:
text
┌─────────────────┐
│ dataset.py │
└────────┬────────┘
│ 提供 Dataset 类
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌────────────────────┐ ┌────────────────────┐ ┌────────────────────┐
│build_bank_multilayer│ │build_realiad_bank_ │ │rad_mvtec_visa_3dadam│
│.py │ │multilayer.py │ │.py │
│(MVTec/VisA/3D-ADAM)│ │(Real-IAD) │ │(MVTec/VisA/3D-ADAM)│
└─────────┬──────────┘ └─────────┬──────────┘ └─────────┬──────────┘
│ 读取正常样本 │ 读取正常样本 │ 加载记忆库 & 测试样本
▼ ▼ │
┌─────────────────────────────────────────────────────┘
│ 调用 DINOv3 提取特征
▼
┌────────────────────┐ ┌────────────────────┐
│ memory bank │─────▶│ rad_real_iad.py │
│ (.pth 文件) │ │ (Real-IAD) │
└────────────────────┘ └────────────────────┘
│ 加载记忆库 & 测试样本
▼
┌────────────────┐
│ utils.py │
└────────────────┘
提供指标计算、可视化等-
数据集层 :
dataset.py定义了所有数据集的加载方式,被所有其他脚本使用。 -
记忆库构建层 :
build_bank_multilayer.py和build_realiad_bank_multilayer.py依赖 DINOv3 模型和dataset.py,生成记忆库文件。 -
评估层 :
rad_mvtec_visa_3dadam.py和rad_real_iad.py加载记忆库文件、DINOv3 模型和测试数据,调用utils.py中的函数计算指标和可视化。 -
工具层 :
utils.py为评估提供底层支持。
注意事项
使用 pip install -r requirements.txt安装 遇到错误时,可以将requirements.txt文件替换成下面内容核心科学计算库:放宽版本以适配 Python 3.10 和 NumPy 2.x
matplotlib>=3.5.0
numpy>=1.24.0
opencv_python_headless>=4.6.0
pandas>=1.5.0
Pillow>=9.0.0
scikit_image>=0.19.0
scikit-learn>=1.2.0
scipy>=1.9.0
工具库
tabulate>=0.9.0
tqdm>=4.64.0
ptflops>=0.7
timm>=0.9.0
PyTorch 系列:移除具体的 CUDA 后缀,让 pip 自动匹配或从官方源安装
注意:torch 和 torchvision 建议单独安装,或者在这里只写基础版本
torch>=2.0.0
torchvision>=0.15.0
如果要导出onnx,可以使用下面脚本(项目中没有给出pth转onnx的方法)
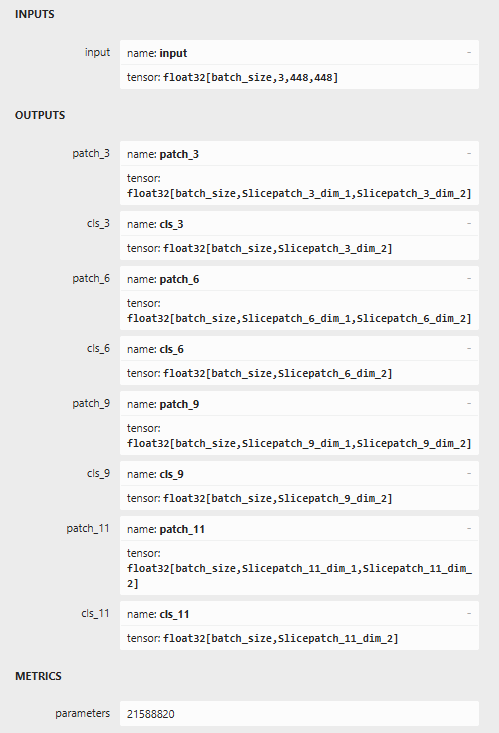
"export_onnx.py"
import torch
from dinov3.hub.backbones import load_dinov3_model
加载 DINOv3 模型(与 RAD 使用的相同)
model = load_dinov3_model(
'dinov3_vits16',
pretrained_weight_path='./weights/dinov3_vits16_pretrain_lvd1689m-08c60483.pth'
)
model.eval()
包装模型,使其 forward 返回指定层的 patch tokens 和 cls token
class DINOv3Wrapper(torch.nn.Module):
def init(self, model, layer_indices):
super().init()
self.model = model
self.layer_indices = layer_indices
def forward(self, x):
x: N, C, H, W
intermediates = self.model.get_intermediate_layers(
x,
n=self.layer_indices,
return_class_token=True,
reshape=False,
norm=True
)
patch_tokens = \[\]
cls_tokens = \[\]
for patch, cls in intermediates:
patch_tokens.append(patch) # N, L, C
cls_tokens.append(cls) # N, C
将所有层的输出拼接成一个大的输出(或返回 tuple)
这里返回两个列表,但 ONNX 要求固定数量的输出,因此我们将它们展平
方案:将 patch 和 cls 按顺序拼接为一个 tensor 列表,并分别命名
outputs = \[\]
for i, (p, c) in enumerate(zip(patch_tokens, cls_tokens)):
outputs.append(p) # patch token for layer i
outputs.append(c) # cls token for layer i
return outputs
要导出的层(与构建记忆库时一致)
layer_indices = 3, 6, 9, 11
wrapper = DINOv3Wrapper(model, layer_indices)
准备 dummy 输入(需与训练时预处理一致:448x448,归一化方式不变)
dummy_input = torch.randn(1, 3, 448, 448)
定义输出名称
output_names = \[\]
for idx in layer_indices:
output_names.append(f'patch_{idx}')
output_names.append(f'cls_{idx}')
动态轴:batch 维度可变
dynamic_axes = {'input': {0: 'batch_size'}}
for name in output_names:
dynamic_axesname = {0: 'batch_size'}
导出 ONNX
torch.onnx.export(
wrapper,
dummy_input,
"dinov3_multilayer.onnx",
input_names='input',
output_names=output_names,
dynamic_axes=dynamic_axes,
opset_version=14, # 推荐 14 以上
do_constant_folding=True,
export_params=True
)
print("ONNX 模型导出成功!")
如果要将bank pth转bin格式(方便C#调用),可以使用以下脚本
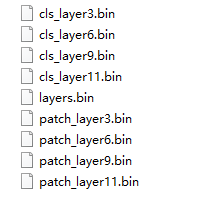
"bank_pth2bin.py"
import torch
import numpy as np
import struct
加载记忆库
bank = torch.load('./bank/mvtec_dinov3_vits16_multilayer36911_448_bank.pth', map_location='cpu')
layers = bank'layers' # 3,6,9,11
cls_banks = bank'cls_banks' # list of N, C
patch_banks = bank'patch_banks' # list of N, L, C
def save_array_as_bin(arr, filename):
"""
将 numpy 数组保存为 bin 文件,格式:
int32 维度数量 (ndim)
int32 每个维度的大小 (重复 ndim 次)
float32 所有数据(按行主序,即 C-order)
"""
with open(filename, 'wb') as f:
写入维度数
f.write(struct.pack('i', arr.ndim))
写入每个维度的长度
for dim in arr.shape:
f.write(struct.pack('i', dim))
写入数据(注意:numpy 默认 C-order,直接 tobytes() 即可)
f.write(arr.astype(np.float32).tobytes())
保存每个层
for i, layer in enumerate(layers):
cls_arr = cls_banksi.numpy() # N, C
patch_arr = patch_banksi.numpy() # N, L, C
save_array_as_bin(cls_arr, f'./bin/cls_layer{layer}.bin')
save_array_as_bin(patch_arr, f'./bin/patch_layer{layer}.bin')
保存层索引(简单保存为 int 列表)
with open('layers.bin', 'wb') as f:
f.write(struct.pack('i', len(layers)))
for layer in layers:
f.write(struct.pack('i', layer))
print("已转换为 .bin 文件")
onnx测试脚本
"test_onnx_openvino2.py"
import numpy as np
import os
import struct
import cv2
import matplotlib.pyplot as plt
from PIL import Image
import torchvision.transforms as transforms
import sys
import time
兼容新旧 OpenVINO 导入
try:
from openvino.runtime import Core, Tensor
except ImportError:
from openvino import Core, Tensor
-------------------------- 二进制记忆库读取 --------------------------
def read_2d_array_from_bin(file_path):
with open(file_path, 'rb') as f:
ndim = struct.unpack('i', f.read(4))0
if ndim != 2:
raise ValueError(f"期望二维数组,实际维度 {ndim}")
rows = struct.unpack('i', f.read(4))0
cols = struct.unpack('i', f.read(4))0
data = np.frombuffer(f.read(), dtype=np.float32).reshape(rows, cols)
print(f"读取 {file_path}: 形状 {data.shape}")
return data
def read_3d_array_from_bin(file_path):
with open(file_path, 'rb') as f:
ndim = struct.unpack('i', f.read(4))0
if ndim != 3:
raise ValueError(f"期望三维数组,实际维度 {ndim}")
d1 = struct.unpack('i', f.read(4))0
d2 = struct.unpack('i', f.read(4))0
d3 = struct.unpack('i', f.read(4))0
data = np.frombuffer(f.read(), dtype=np.float32).reshape(d1, d2, d3)
print(f"读取 {file_path}: 形状 {data.shape}")
return data
def read_layers_from_bin(file_path):
with open(file_path, 'rb') as f:
count = struct.unpack('i', f.read(4))0
layers = \[\]
for _ in range(count):
layers.append(struct.unpack('i', f.read(4))0)
print(f"读取 {file_path}: 层索引 {layers}")
return layers
-------------------------- 图像预处理 --------------------------
def preprocess_image(image_path, input_size=448):
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.CenterCrop(input_size),
transforms.Normalize(mean=0.485, 0.456, 0.406,
std=0.229, 0.224, 0.225)
])
img = Image.open(image_path).convert('RGB')
img_tensor = transform(img)
img_np = img_tensor.numpy()
img_np = np.expand_dims(img_np, axis=0).astype(np.float32)
return img_np
-------------------------- 工具函数 --------------------------
def normalize(vec):
norm = np.linalg.norm(vec) + 1e-8
return vec / norm
def resize_bilinear(src, dst_h, dst_w):
src_h, src_w = src.shape
scale_x = (src_w - 1) / (dst_w - 1) if dst_w > 1 else 0
scale_y = (src_h - 1) / (dst_h - 1) if dst_h > 1 else 0
dst = np.zeros((dst_h, dst_w), dtype=np.float32)
for y in range(dst_h):
fy = y * scale_y
y0 = int(fy)
y1 = min(y0 + 1, src_h - 1)
wy1 = fy - y0
wy0 = 1 - wy1
for x in range(dst_w):
fx = x * scale_x
x0 = int(fx)
x1 = min(x0 + 1, src_w - 1)
wx1 = fx - x0
wx0 = 1 - wx1
v00 = srcy0, x0
v01 = srcy0, x1
v10 = srcy1, x0
v11 = srcy1, x1
v0 = v00 * wx0 + v01 * wx1
v1 = v10 * wx0 + v11 * wx1
dsty, x = v0 * wy0 + v1 * wy1
return dst
def gaussian_kernel(size=5, sigma=1.0):
ax = np.linspace(-(size // 2), size // 2, size)
xx, yy = np.meshgrid(ax, ax)
kernel = np.exp(-0.5 * (xx**2 + yy**2) / sigma**2)
kernel = kernel / np.sum(kernel)
return kernel
def apply_gaussian_blur(anomaly_map, kernel_size=5, sigma=1.0):
from scipy.ndimage import convolve
kernel = gaussian_kernel(kernel_size, sigma)
return convolve(anomaly_map, kernel, mode='reflect')
-------------------------- 主推理类 --------------------------
class RADInference:
def init(self, onnx_path, bank_dir, k_image=150, layer_weights=None):
print("初始化 RADInference...")
self.k_image = k_image
加载 ONNX 模型
print(f"加载 ONNX 模型: {onnx_path}")
self.core = Core()
model = self.core.read_model(onnx_path)
self.compiled_model = self.core.compile_model(model, "CPU")
self.infer_request = self.compiled_model.create_infer_request()
print("模型加载成功,输出名称列表:")
for out in self.compiled_model.outputs:
print(f" {out.any_name}")
加载记忆库
print(f"加载记忆库: {bank_dir}")
layers_path = os.path.join(bank_dir, "layers.bin")
self.layers = read_layers_from_bin(layers_path)
self.num_layers = len(self.layers)
self.cls_banks = \[\]
self.patch_banks = \[\]
for layer in self.layers:
cls_path = os.path.join(bank_dir, f"cls_layer{layer}.bin")
patch_path = os.path.join(bank_dir, f"patch_layer{layer}.bin")
self.cls_banks.append(read_2d_array_from_bin(cls_path)) # N, C
self.patch_banks.append(read_3d_array_from_bin(patch_path)) # N, L, C
预归一化 patch 记忆库(加速后续计算)
print("预归一化 patch 记忆库...")
self.patch_banks_norm = \[\]
for pb in self.patch_banks:
norms = np.linalg.norm(pb, axis=2, keepdims=True) + 1e-8
pb_norm = pb / norms
self.patch_banks_norm.append(pb_norm)
层权重
if layer_weights is None:
self.layer_weights = np.ones(self.num_layers) / self.num_layers
else:
self.layer_weights = np.array(layer_weights) / sum(layer_weights)
其他常量
self.embed_dim = self.cls_banks0.shape1 # 384
self.num_patches = self.patch_banks0.shape1 # 784
self.patch_h = self.patch_w = int(np.sqrt(self.num_patches)) # 28
print(f"初始化完成: 层数={self.num_layers}, 嵌入维度={self.embed_dim}, patch数={self.num_patches}")
def infer(self, image_path, output_size=256, apply_smoothing=True):
print("\n===== 开始推理 =====")
start_total = time.time()
1. 预处理
print("步骤1: 图像预处理...")
t = time.time()
input_data = preprocess_image(image_path)
print(f" 耗时: {time.time()-t:.2f}s")
2. 创建 Tensor 并设置输入
print("步骤2: 创建输入 Tensor...")
t = time.time()
input_tensor = Tensor(input_data)
self.infer_request.set_input_tensor(0, input_tensor)
print(f" 耗时: {time.time()-t:.2f}s")
3. 推理
print("步骤3: 执行推理...")
t = time.time()
self.infer_request.infer()
print(f" 耗时: {time.time()-t:.2f}s")
4. 获取各层输出
print("步骤4: 获取输出张量...")
t = time.time()
patch_list = \[\]
cls_list = \[\]
for idx in self.layers:
patch_key = f'patch_{idx}'
cls_key = f'cls_{idx}'
patch_tensor = self.infer_request.get_tensor(patch_key)
cls_tensor = self.infer_request.get_tensor(cls_key)
patch_list.append(patch_tensor.data) # 1, L, C
cls_list.append(cls_tensor.data) # 1, C
print(f" 耗时: {time.time()-t:.2f}s")
5. 图像级检索(使用最高层 CLS)
print("步骤5: 图像级检索...")
t = time.time()
query_cls = cls_list-10 # C
norm_query_cls = normalize(query_cls)
cls_bank_global = self.cls_banks-1 # N, C
计算余弦相似度
cls_norms = np.linalg.norm(cls_bank_global, axis=1) + 1e-8
similarities = np.dot(cls_bank_global, norm_query_cls) / cls_norms
topk_indices = np.argsort(similarities)-self.k_image:::-1
print(f" 最高层检索完成,top-{self.k_image} 索引: {topk_indices:5}...")
print(f" 耗时: {time.time()-t:.2f}s")
6. 逐层 patch-KNN(优化版本)
print("步骤6: 逐层 patch-KNN...")
fused_scores = np.zeros(self.num_patches)
for li in range(self.num_layers):
layer_start = time.time()
print(f" 处理层 {self.layersli}...")
test_patch = patch_listli0 # L, C
归一化测试 patch
test_patch_norm = np.zeros_like(test_patch)
for p in range(self.num_patches):
test_patch_normp = normalize(test_patchp)
从预归一化的记忆库中取出 top-k 个训练样本的 patch 特征 k, L, C
bank_patch_norm = self.patch_banks_normlitopk_indices # k, L, C
重塑为 k\*L, C
kL = self.k_image * self.num_patches
bank_flat = bank_patch_norm.reshape(kL, self.embed_dim) # 117600, 384
k_actual = len(topk_indices)
kL_actual = k_actual * self.num_patches
bank_flat = bank_patch_norm.reshape(kL_actual, self.embed_dim)
对每个查询 patch 计算与所有 bank patch 的相似度
layer_scores = np.zeros(self.num_patches)
for p in range(self.num_patches):
q = test_patch_normp # 384
sims = np.dot(bank_flat, q) # kL
max_sim = np.max(sims)
layer_scoresp = 1.0 - max_sim
可选:每 100 个打印一次进度
if (p + 1) % 200 == 0:
print(f" 已处理 {p+1}/{self.num_patches} patches")
fused_scores += self.layer_weightsli * layer_scores
print(f" 层 {self.layersli} 处理完成,分数范围 {layer_scores.min():.4f}, {layer_scores.max():.4f}, 耗时 {time.time()-layer_start:.2f}s")
7. 重塑为 28x28
patch_map = fused_scores.reshape(self.patch_h, self.patch_w)
8. 上采样
print("步骤8: 上采样...")
t = time.time()
anomaly_map = resize_bilinear(patch_map, output_size, output_size)
print(f" 耗时: {time.time()-t:.2f}s")
9. 高斯平滑
if apply_smoothing:
print("步骤9: 高斯平滑...")
t = time.time()
anomaly_map = apply_gaussian_blur(anomaly_map, kernel_size=5, sigma=1.0)
print(f" 耗时: {time.time()-t:.2f}s")
10. 图像级分数
img_score = np.max(anomaly_map)
print(f"步骤10: 图像级分数 = {img_score:.4f}")
print(f"===== 推理结束,总耗时 {time.time()-start_total:.2f}s =====\n")
return anomaly_map, img_score
def release(self):
pass
-------------------------- 可视化 --------------------------
def visualize(image_path, anomaly_map, img_score, save_path=None):
img = cv2.imread(image_path)
if img is None:
print(f"无法读取图像: {image_path}")
return
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
归一化异常图
am_norm = (anomaly_map - anomaly_map.min()) / (anomaly_map.max() - anomaly_map.min() + 1e-8)
am_uint8 = (am_norm * 255).astype(np.uint8)
生成热图
heatmap = cv2.applyColorMap(am_uint8, cv2.COLORMAP_JET)
heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB)
调整大小
h, w = img.shape:2
heatmap_resized = cv2.resize(heatmap, (w, h), interpolation=cv2.INTER_LINEAR)
叠加
alpha = 0.5
overlay = cv2.addWeighted(img, 1 - alpha, heatmap_resized, alpha, 0)
显示
plt.figure(figsize=(15, 5))
plt.subplot(1, 4, 1)
plt.imshow(img)
plt.title("Original Image")
plt.axis('off')
plt.subplot(1, 4, 2)
plt.imshow(heatmap_resized)
plt.title("Anomaly Heatmap")
plt.axis('off')
plt.subplot(1, 4, 3)
plt.imshow(overlay)
plt.title(f"Overlay (score={img_score:.4f})")
plt.axis('off')
plt.subplot(1, 4, 4)
plt.imshow(am_norm, cmap='jet')
plt.title("Raw Anomaly Map")
plt.axis('off')
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"可视化结果已保存至 {save_path}")
plt.show()
-------------------------- 主程序 --------------------------
if name == "main":
参数配置
onnx_file = "dinov3_multilayer.onnx"
bank_directory = "bin"
test_image = "000.png"
output_vis = "result.png"
检查文件是否存在
if not os.path.exists(onnx_file):
print(f"错误: ONNX 文件不存在: {onnx_file}")
sys.exit(1)
if not os.path.exists(bank_directory):
print(f"错误: 记忆库目录不存在: {bank_directory}")
sys.exit(1)
if not os.path.exists(test_image):
print(f"错误: 测试图像不存在: {test_image}")
sys.exit(1)
try:
初始化
rad = RADInference(onnx_file, bank_directory, k_image=150)
推理
anomaly_map, score = rad.infer(test_image, output_size=256, apply_smoothing=True)
可视化
visualize(test_image, anomaly_map, score, save_path=output_vis)
print("程序正常结束。")
except Exception as e:
print(f"发生错误: {e}")
import traceback
traceback.print_exc()