小某书最新起号方式,还得看 AI(doge)。
这两天打开一看,几乎全被各种精致逼真的手办图刷屏了:
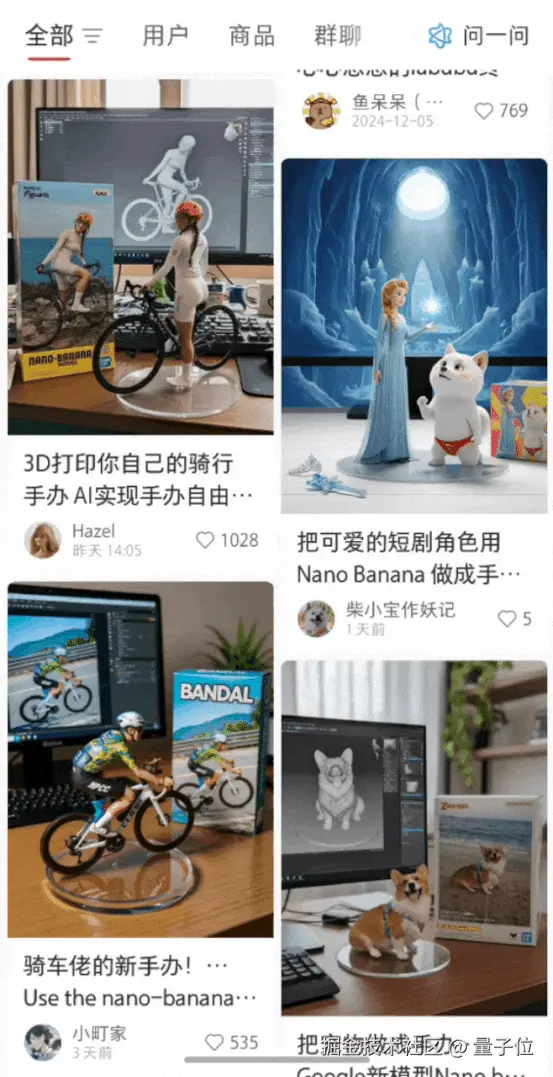
而且仔细一扒,甭管是 AI 圈、二次元圈还是骑行圈等等,感觉大家一下子都在玩。
so,发生了啥?到底是什么引得大家如此动作一致?
时刻游走在吃瓜第一线的量子位赶紧去瞧了瞧,结果发现,这不是最近爆火的图像编辑模型 nano-banana 嘛。

这个模型起初在 LMArena 平台匿名出现,后来因生图表现太好突然爆火,继而引得无数网友猜测其归属。
直到两天之前,谷歌才终于站出来认领了该模型,并表示其真身为 Gemini 2.5 Flash Image。
而随着 nano-banana 揭开神秘面纱,国内外网友更是掀起了一波疯狂试玩的热潮,其中手办尤其受到大家的青睐。
所以,如何用 nano-banana 生成同款手办?提示词该怎么写?
量子位手把手教程这就奉上------
实测爆火手办玩法
不卖关子,先看看网上爆火的生成 "真实手办" 的提示词。
Use the nano-banana model to create a 1/7 scale model, in a realistic style and environment. Place the figure on a computer desk, using a circular transparent acrylic base without any text.On the computer screen, display the ZBrush modeling process of the figure.Next to the computer screen, place a TAMIYA-style toy packaging box printedwith the original artwork.
(中译方便对照版:使用 nano-banana 模型制作一个 1/7 比例的实体模型,风格和环境保持写实。将模型摆放在电脑桌上,底座为圆形透明亚克力材质,且不带任何文字。电脑屏幕上显示的是该模型在 ZBrush 中的建模过程。在电脑屏幕旁边,放置一个 TAMIYA 风格的玩具包装盒,包装盒上印有原始插画。)
就用这套提示词和 Gemini 2.5 Flash,让我们试试水~

(PS:支持中文提示词,但偶尔会出现错误,需要多试几次,建议使用英文。)

以动漫角色为参考图,生成的 "手办" 效果确实不错。

出乎意料的是,只用了上面的提示词,它居然可以识别出是艾伦耶格尔(盒子上有他的名字)。
而且即使不是全身像也可以生成,但参考图以外的部位可能会有一些奇怪的地方。

可是一想到是银魂就觉得很合理怎么回事。

用家里的毛孩子作为参考图,简直是让人大呼 "购买链接在哪里" 的程度......

猫猫和狗狗都非常可爱。
要是能结合 3D 打印做出来就更好了(真的可以)。

虽然网上的案例已经很多了,但让我们再试试真人效果呢。
亲测,最好使用全身图。

只要是全身图就能成,包括这种搞怪动作乱飞的。

非常适合...... 你知道的,哪怕不是给自己,谁手里没几张好朋友的怪照片呢?
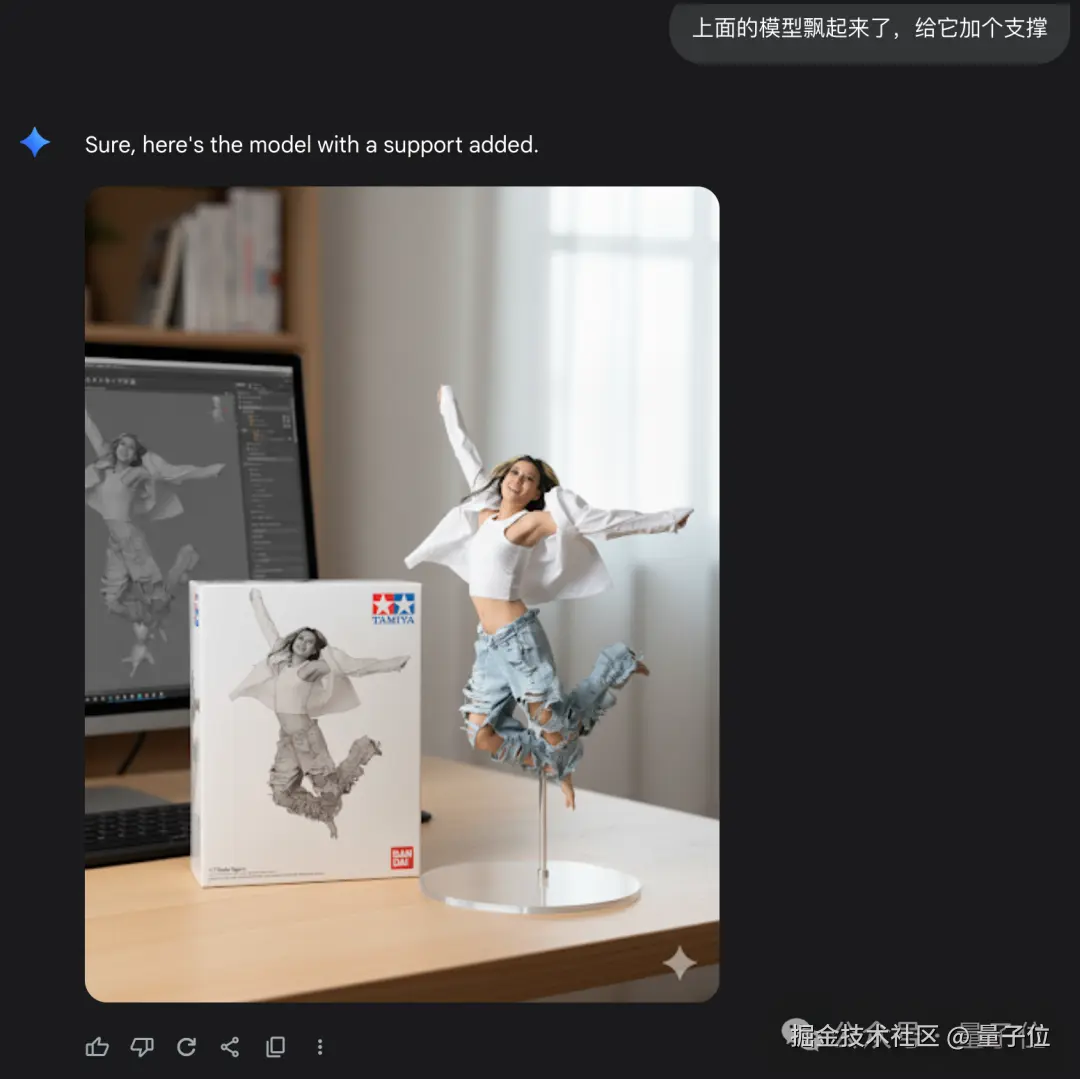
美中不足的是生成的 "手办" 好像没有支撑,但再补充一句就行。
上面的模型飘起来了,给它加个支撑。
这些玩法也很火
除了手办,nano-banana 还有一些脑洞大开的玩法也很火。
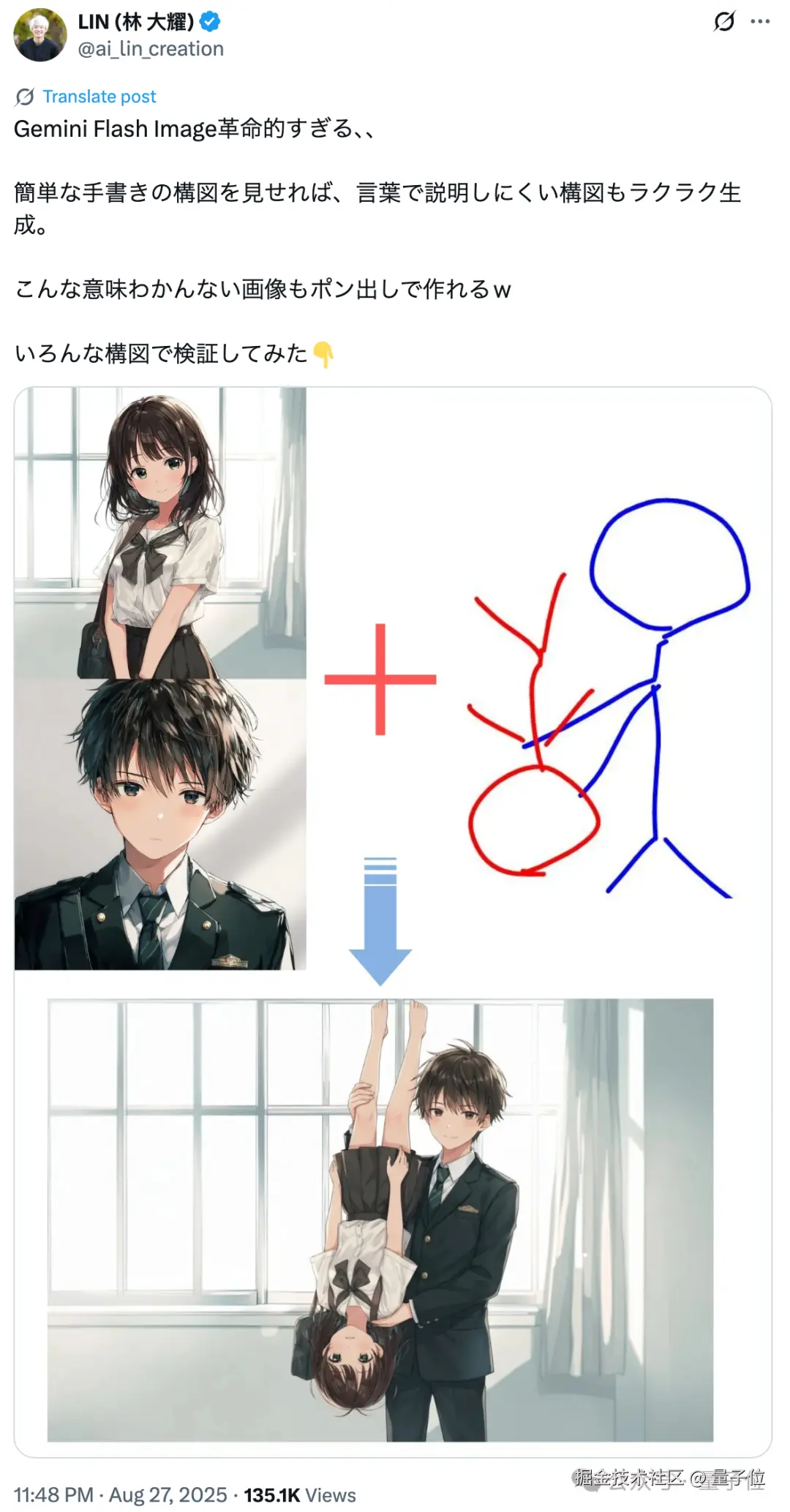
它可以同时结合 3 张图片进行创作,既然如此,有网友意识到,为什么不试着控制角色的姿态呢。

还可以结合视频生成模型创作连贯的动画。
不需要太过完整的动作示例(虽然使用详细示例可能会更精细),火柴人小草图同样可行。
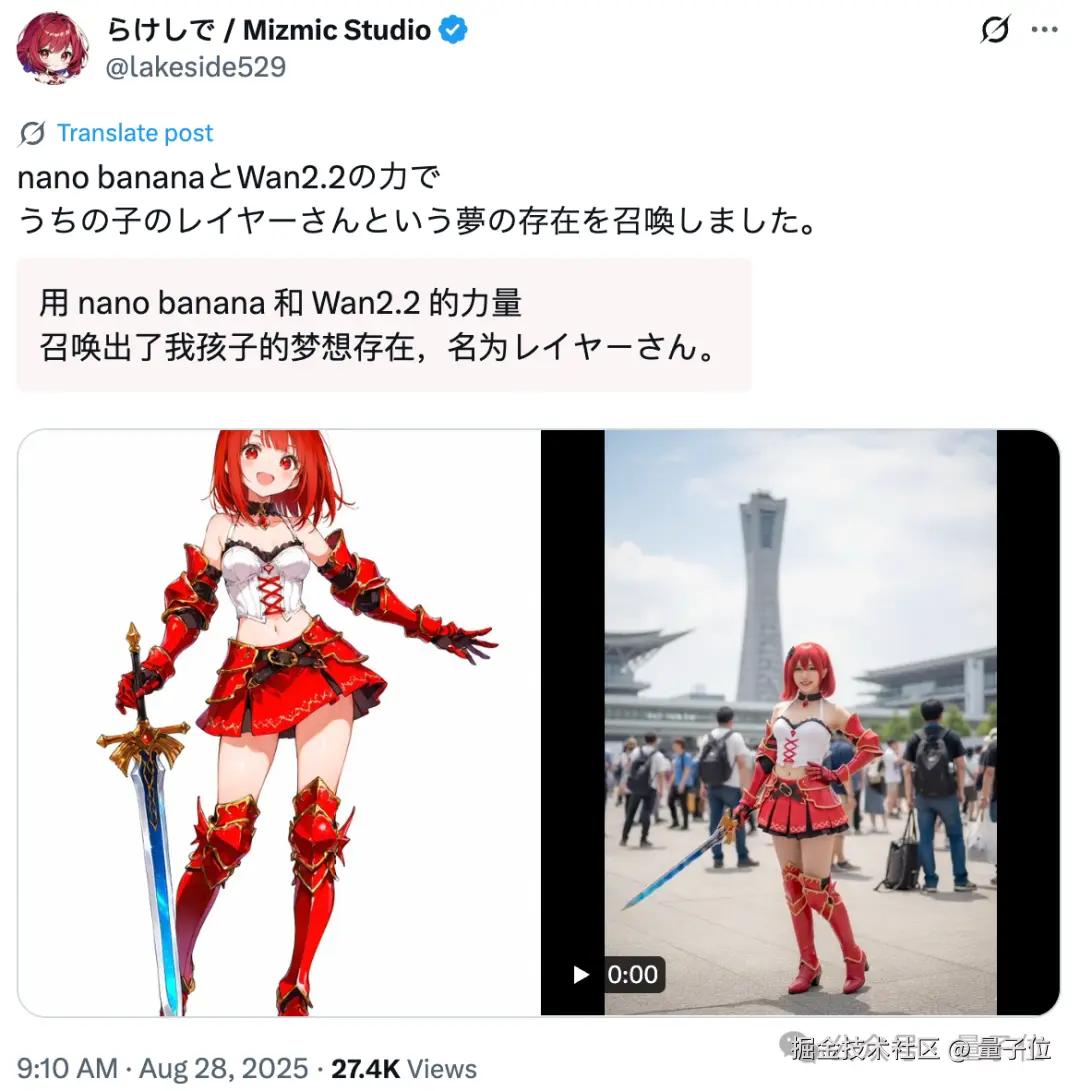
也有网友选择打破次元壁,让二次元人物成为真人出现在漫展场地。
这和真实的 cosplayer 有什么差别?
上述玩法我们也 "顺带" 实测了一下,提示词放在下面了,一起看看效果:
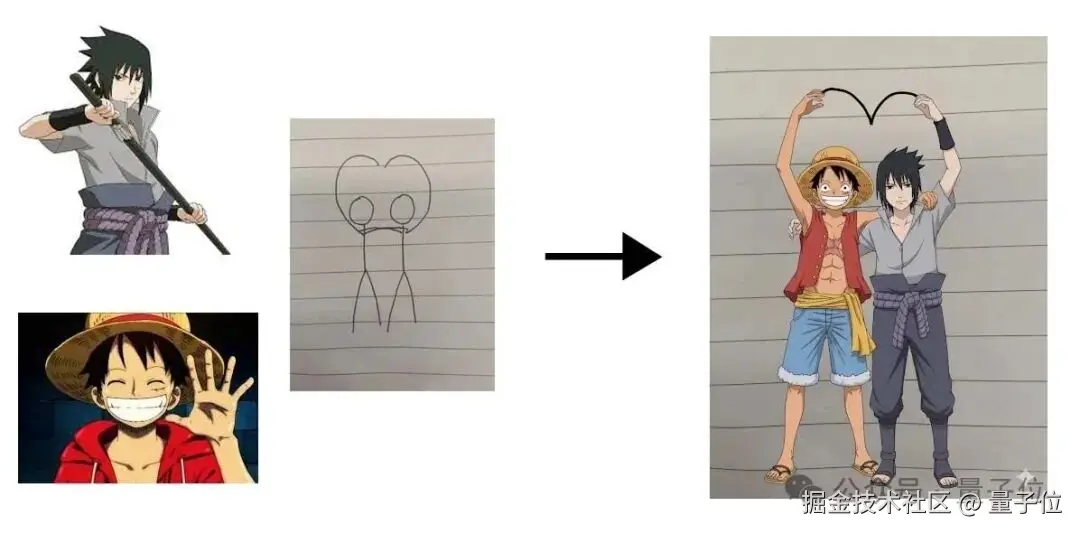
让图一和图二的角色摆出图三的姿势,一条手臂搭在对方的肩膀上,另一条手臂比心。
让图一和图二的角色以图三的姿势战斗,一个人出拳,一个人用腿踢。

生成一张真人扮演这张插画的照片,背景设置为 Comiket。
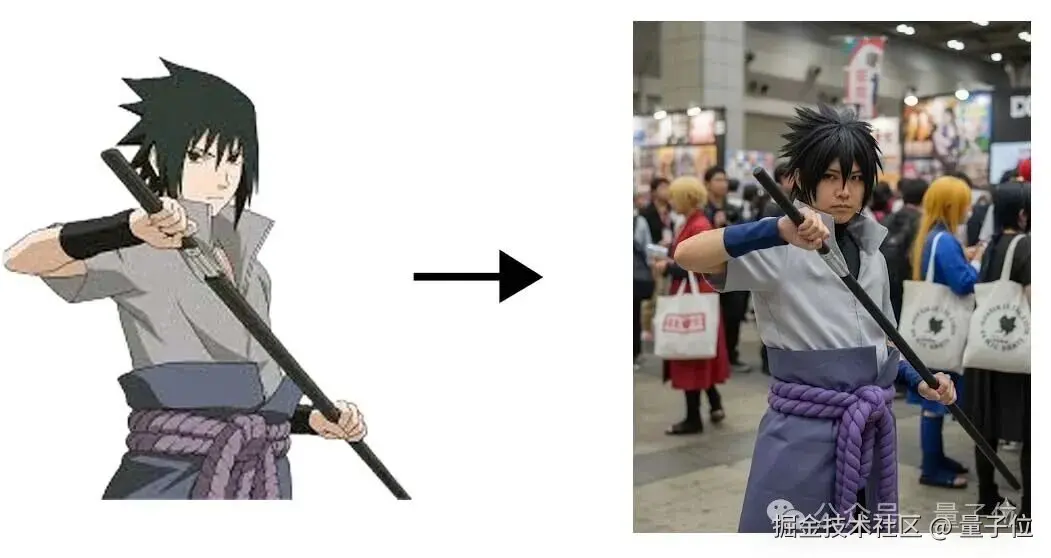
是生图(指没有修过的原图)啊,完全是 coser 生图啊!
团队透露背后技术细节
通过以上实测不难发现,nano-banana 确实有点东西。
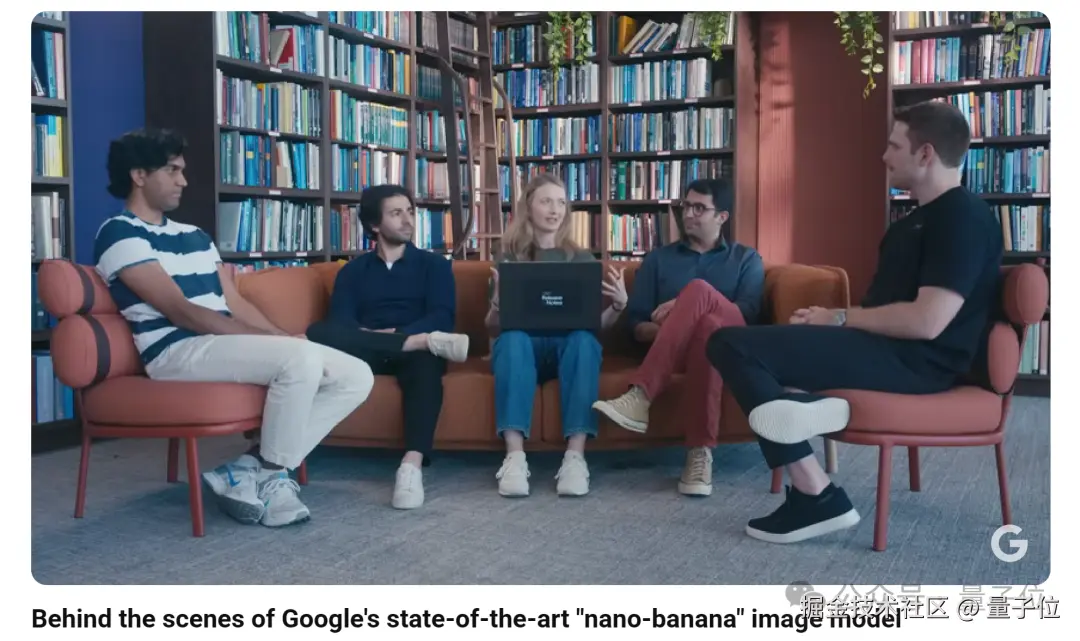
趁热打铁,谷歌 AI Studio 负责人 Logan Kilpatrick_(最右)_最近还采访了这个项目背后的团队。
从左到右分别是:研究工程师 Kaushik Shivakumar、研究工程师 Robert Riachi、小组产品经理 Nicole Brichtova、研究科学家 Mostafa Dehghani。
略过开头的产品功能介绍和演示环节,咱们直接来看看背后的核心技术原理。
第一,以文本渲染作为核心指标来快速衡量模型性能。
对图像生成模型来说,一个无法回避的难题是如何进行有效评估。传统的评估方法严重依赖 "人类偏好评估",不仅非常主观,而且需要耗费大量昂贵人力。
为此团队提出了一个新的替代指标------文本渲染。按照 Robert Riachi 的话来说:
当模型能处理好这种复杂的文字结构时,它同样也能学会图像里的其他结构。
Kaushik Shivakumar 进一步解释,之所以使用这个指标,还是因为一直以来几乎所有模型都无法很好解决文本渲染的问题。
它为模型训练提供了一个客观、可量化且不易饱和的衡量标准。相比于很快就会触及瓶颈的其他自动化图像质量指标,文本渲染的难度足够大,能够持续为模型的改进提供指引。
而且有趣的是,这一做法还带来了意料之外的好处------一些原本并非针对文本渲染的改动,却意外地提升了该指标的表现。
不过需要提醒,这并非意味着完全放弃了人工评估,只是考虑到训练成本,文本渲染可以作为一种更高效、经济且可靠的替代方案。
第二,通过原生多模态与交错式生成,实现复杂编辑与情境感知。
团队提到,该模型的核心优势在于原生多模态。原生多模态意味着图像的理解和生成能力被深度整合进了一个模型中,而非两个系统的简单拼接。
之所以要采用原生多模态,主要目标是在不同模态和能力之间实现 "正向迁移"。
就拿之前经常提到的数手指案例来说,明明图片上是 6 只手指,但 AI 可能会基于文本知识硬说成 5 只,而视觉信号能够为模型学习世界知识提供一条捷径。

根据介绍,堪比 "一对姐妹" 的图像理解与生成,其协同作用在 "交错式生成" 中得到了最充分的体现。
"交错式生成" 被视为该模型实现复杂、多轮编辑的关键技术,与传统模型一次性生成一张图片不同,交错式生成是一个连续的过程------不仅能理解当前的文本指令,还能看到并理解对话历史中的所有图片。
Mostafa Dehghani 进一步指出,它为解决极其复杂的图像生成任务提供了一种全新范式:
如果你的提示词包含了 6 个甚至 50 个不同的编辑要求,传统模型很可能在一次生成中无法满足所有细节。但利用交错式生成,模型可以将这个复杂任务分解为多个步骤,在不同的对话轮次中逐一完成编辑。
第三,该模型的进步离不开对上一代模型的深入反思和对用户反馈的积极响应。
根据透露,团队会直接在𝕏等社交平台上搜集用户反馈,将用户报告的失败案例系统性整理起来,并将其构建成内部的评估基准。
也就是说,每一个新版本的模型都必须在这些来自真实世界挑战的测试集上证明自己。
具体而言,这些曾经出现的 bug 包括:
1、像素级精确编辑:在 Imagen 2.0 中,用户在尝试对图像进行局部编辑时,模型可能会在添加新元素的同时不必要地改变图像的其他部分。
2、角色一致性:Imagen 2.0 已经能够在不改变角色位置的情况下为其添加帽子或改变表情。而新模型则实现了更高层次的一致性,能够从不同角度渲染同一个角色,生成看起来完全是同一个人的侧面或背面视图。它还可以将一件家具从原始照片中取出,放置到一个全新的环境中。
3、更自然的图像质感:之前的编辑操作有时会产生不自然的 PS 感或叠加感。
Anyway,正是因为团队积极收集用户反馈,弥补这些曾经的短板,新模型这才有了如今的爆火。
未来,谷歌的目标是将所有模态都整合到 Gemini 中,以实现 AGI。
One More Thing
顺带一提,谷歌这次还计划举办 Nano Banana Hackathon(黑客马拉松)活动。
持续时间为 2 天,届时将提供免费 API 使用额度。
获奖者有机会赢得奖品和开发者积分,以及一些和 Gemini 有关的 "酷炫玩意儿"。
最后,如果你现在想要试玩 Nano Banana 模型,可以通过 AI Studio 或 Gemini API 体验。
也可以直接在 Gemini 内使用。
AI Studio 体验地址:
aistudio.google.com/prompts/new...
参考链接:
1x.com/kei31/statu...
2x.com/yuhasbeenta...
3x.com/kiyoshi_shi...
4x.com/lakeside529...
5x.com/OfficialLog...
6x.com/OfficialLog...
欢迎在评论区留下你的想法!
--- 完 ---