前言
💖💖作者:计算机程序员小杨 💙💙个人简介:我是一名计算机相关专业的从业者,擅长Java、微信小程序、Python、Golang、安卓Android等多个IT方向。会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。热爱技术,喜欢钻研新工具和框架,也乐于通过代码解决实际问题,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💕💕文末获取源码联系 计算机程序员小杨 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目 计算机毕业设计选题 💜💜
一.开发工具简介
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
二.系统内容简介
基于大数据的全球电子商务供应链数据分析系统是一个综合运用现代大数据技术栈的企业级数据分析平台,该系统采用Hadoop+Spark作为核心大数据处理框架,结合Python编程语言和Django Web框架构建后端服务架构。系统前端采用Vue+ElementUI+Echarts技术栈实现用户界面和数据可视化展示,通过HTML+CSS+JavaScript+jQuery技术增强用户交互体验。在数据处理层面,系统深度集成Spark SQL进行大规模数据查询分析,利用Pandas和NumPy进行数据科学计算,通过HDFS实现海量数据的分布式存储管理。系统核心功能模块包括供应链数据管理、销售数据分析、库存健康监控、市场表现评估、产品组合分析、供应链成本控制以及综合数据可视化大屏,形成了从数据采集、存储、处理到分析展示的完整业务闭环,为电子商务企业的供应链管理决策提供数据支撑和智能分析服务。
三.系统功能演示
计算机毕设选题:电子商务供应链大数据分析系统Python+Django技术实现详解|毕设|计算机毕设|程序开发|项目实战
四.系统界面展示
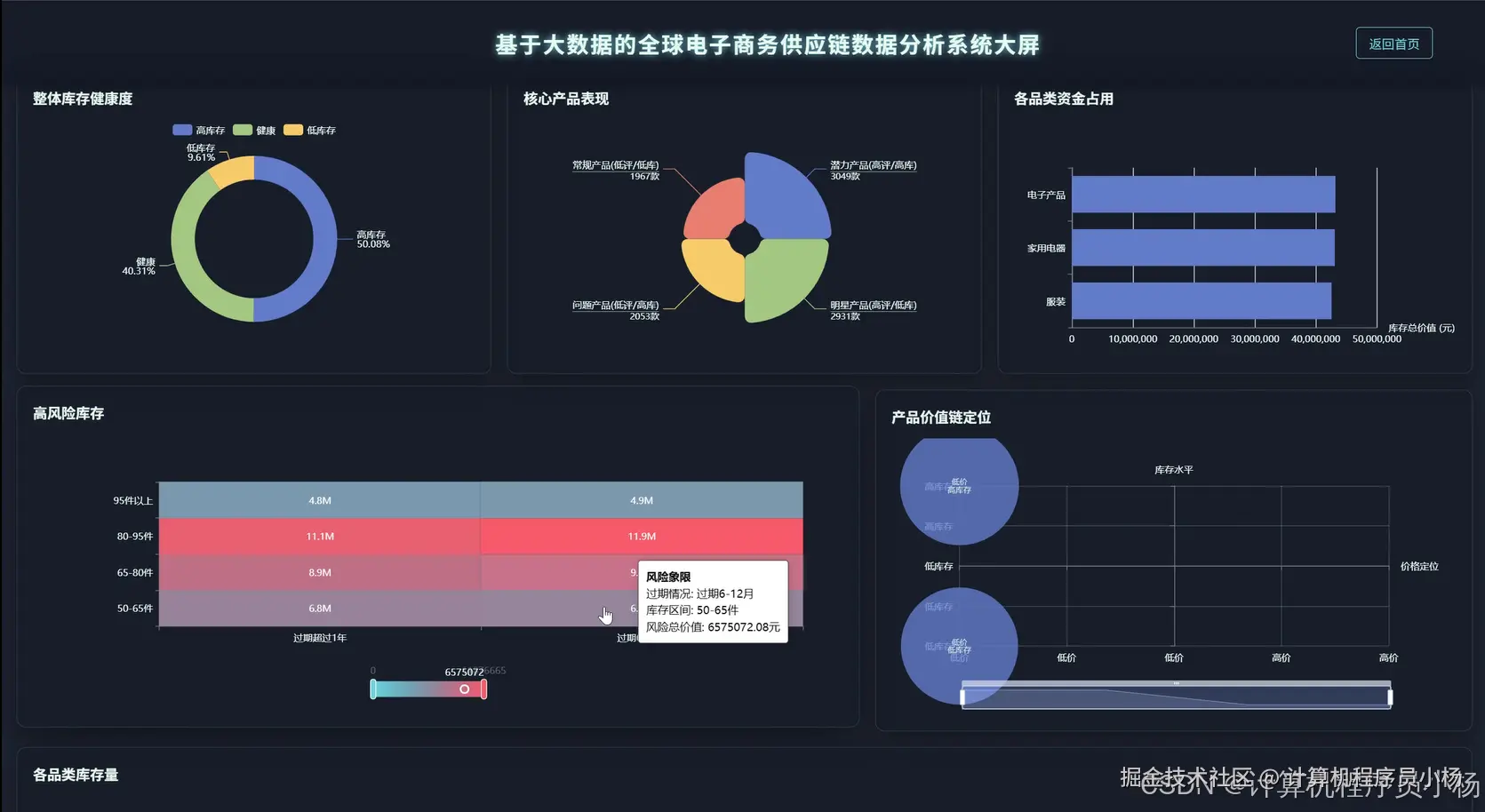
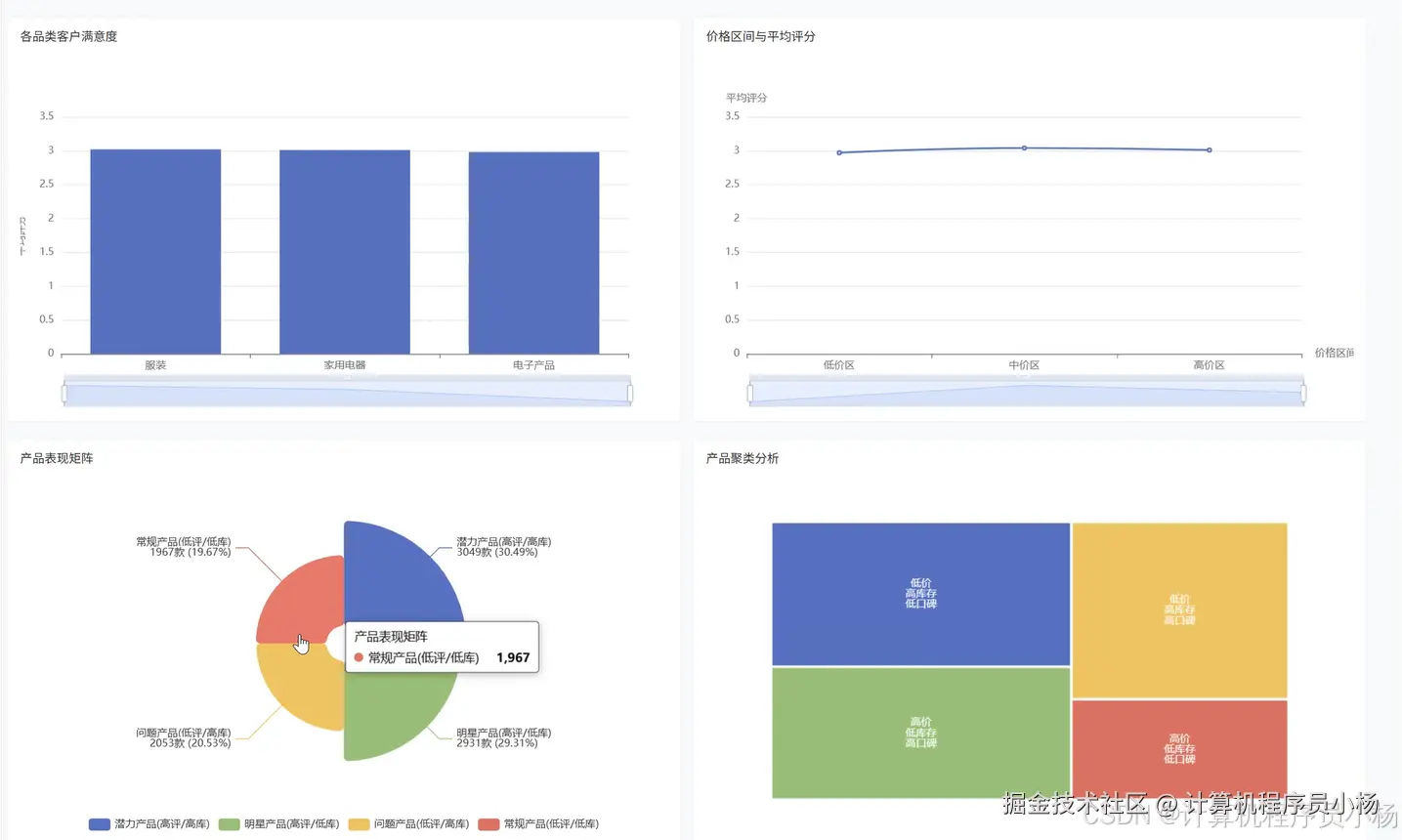
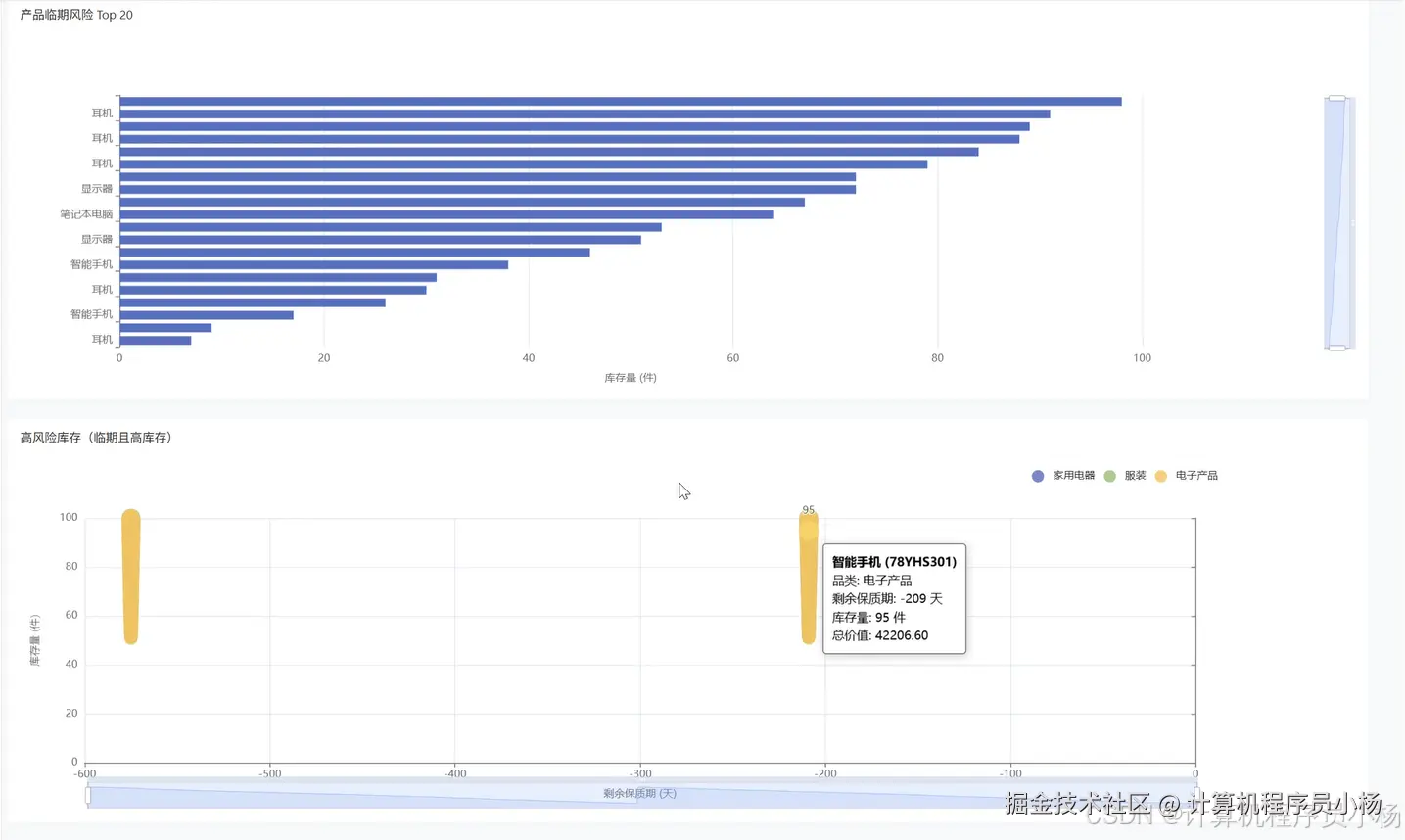
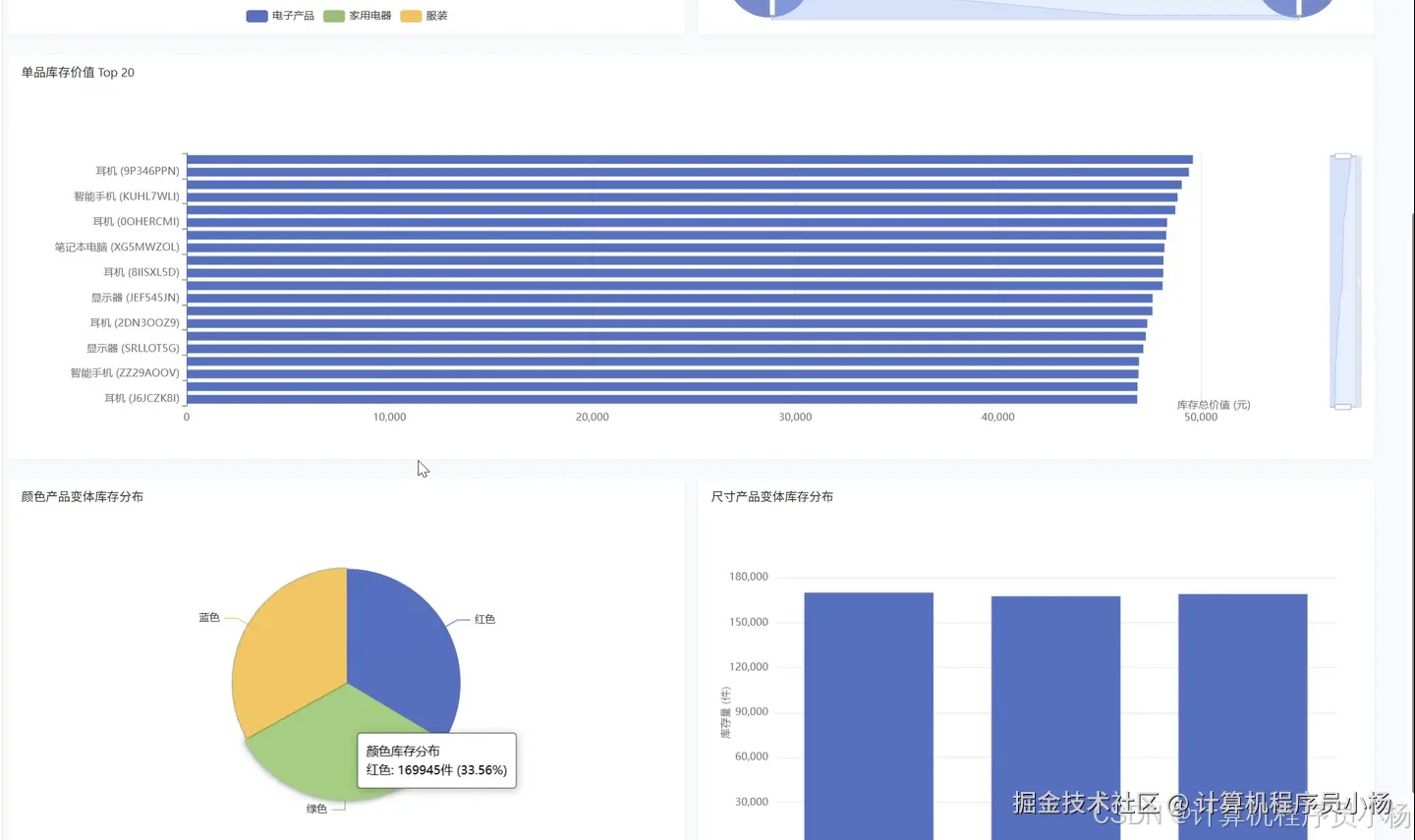
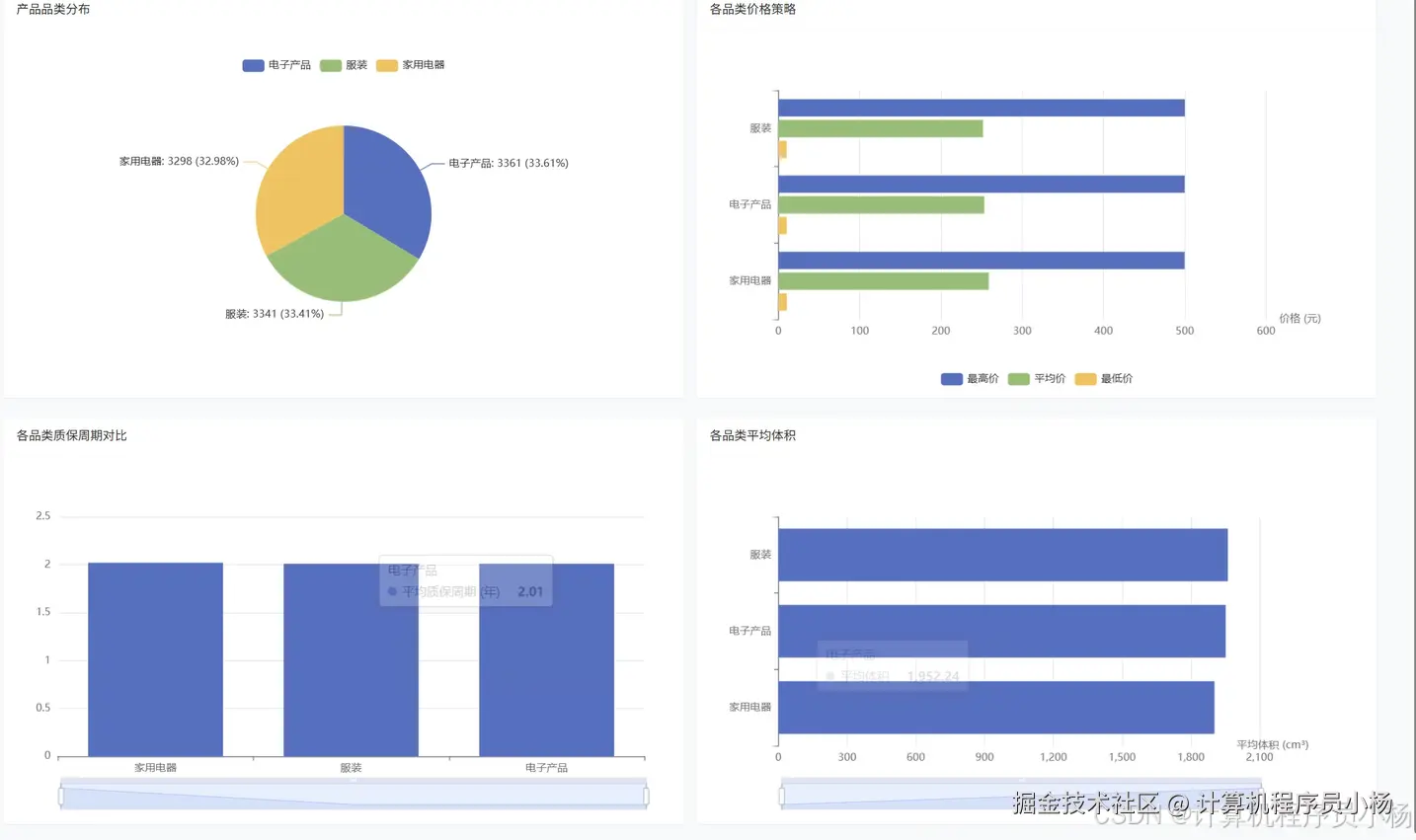
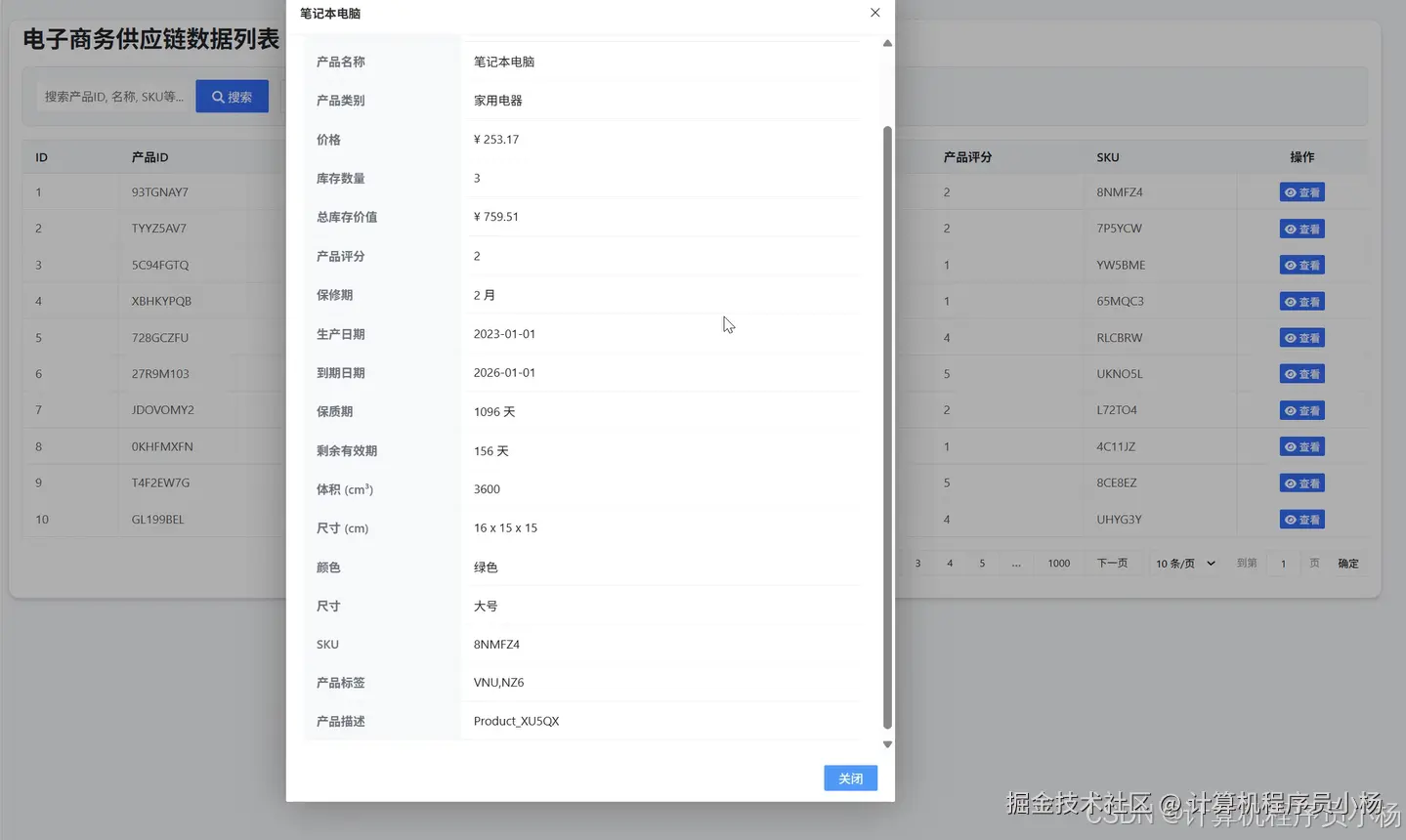
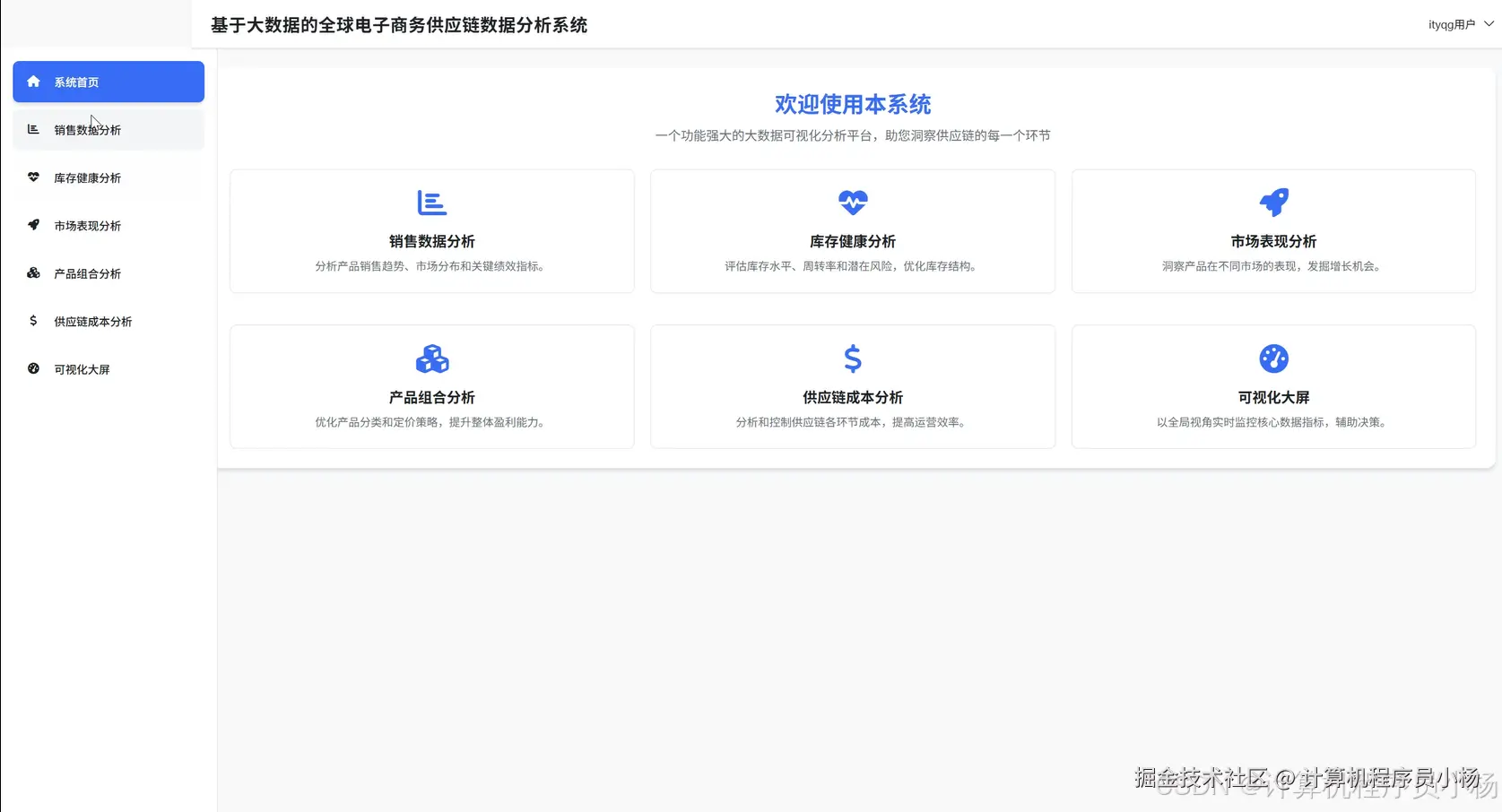
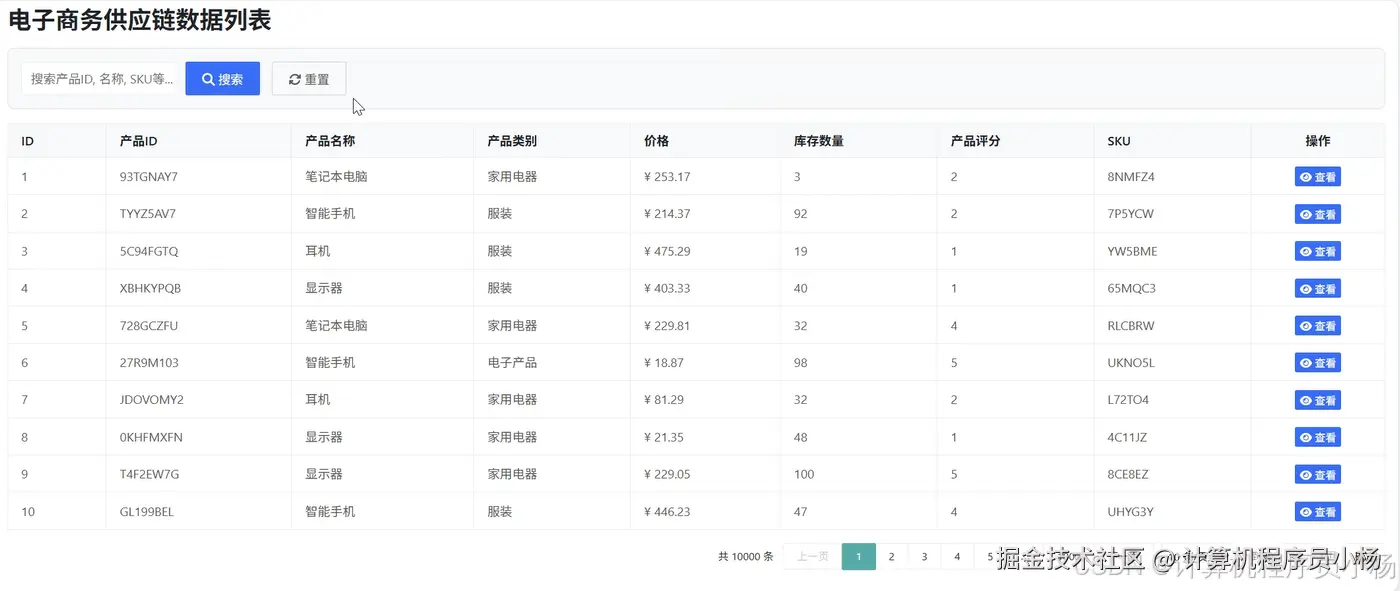
五.系统源码展示
python
from pyspark.sql import SparkSession
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
import pandas as pd
import numpy as np
import json
spark = SparkSession.builder.appName("SupplyChainAnalysis").config("spark.sql.adaptive.enabled", "true").getOrCreate()
@csrf_exempt
def sales_data_analysis(request):
if request.method == 'POST':
data = json.loads(request.body)
start_date = data.get('start_date')
end_date = data.get('end_date')
region = data.get('region')
df = spark.sql(f"""
SELECT product_id, region, sales_amount, order_date, quantity
FROM sales_data
WHERE order_date BETWEEN '{start_date}' AND '{end_date}'
AND region = '{region}'
""")
pandas_df = df.toPandas()
daily_sales = pandas_df.groupby('order_date')['sales_amount'].sum().reset_index()
product_performance = pandas_df.groupby('product_id').agg({
'sales_amount': 'sum',
'quantity': 'sum'
}).reset_index()
top_products = product_performance.nlargest(10, 'sales_amount')
sales_trend = []
for index, row in daily_sales.iterrows():
sales_trend.append({
'date': row['order_date'],
'amount': float(row['sales_amount'])
})
growth_rate = calculate_growth_rate(pandas_df)
regional_comparison = pandas_df.groupby('region')['sales_amount'].sum().to_dict()
peak_sales_day = daily_sales.loc[daily_sales['sales_amount'].idxmax()]
average_daily_sales = daily_sales['sales_amount'].mean()
total_revenue = pandas_df['sales_amount'].sum()
return JsonResponse({
'sales_trend': sales_trend,
'top_products': top_products.to_dict('records'),
'growth_rate': growth_rate,
'regional_comparison': regional_comparison,
'peak_sales_day': peak_sales_day['order_date'],
'average_daily_sales': float(average_daily_sales),
'total_revenue': float(total_revenue)
})
@csrf_exempt
def inventory_health_analysis(request):
if request.method == 'POST':
data = json.loads(request.body)
warehouse_id = data.get('warehouse_id')
threshold_days = data.get('threshold_days', 30)
df = spark.sql(f"""
SELECT product_id, current_stock, safety_stock, reorder_point,
last_restock_date, daily_sales_avg, warehouse_id
FROM inventory_data
WHERE warehouse_id = '{warehouse_id}'
""")
pandas_df = df.toPandas()
pandas_df['stock_days'] = pandas_df['current_stock'] / pandas_df['daily_sales_avg']
pandas_df['stock_days'] = pandas_df['stock_days'].replace([np.inf, -np.inf], 0)
low_stock_items = pandas_df[pandas_df['current_stock'] <= pandas_df['reorder_point']]
overstock_items = pandas_df[pandas_df['stock_days'] > threshold_days]
healthy_stock_items = pandas_df[
(pandas_df['current_stock'] > pandas_df['reorder_point']) &
(pandas_df['stock_days'] <= threshold_days)
]
stock_turnover = pandas_df['daily_sales_avg'] / pandas_df['current_stock']
stock_turnover = stock_turnover.replace([np.inf, -np.inf], 0)
average_turnover = stock_turnover.mean()
total_inventory_value = calculate_inventory_value(pandas_df)
stock_health_score = calculate_stock_health_score(pandas_df)
aging_analysis = perform_aging_analysis(pandas_df)
reorder_suggestions = generate_reorder_suggestions(pandas_df)
inventory_alerts = generate_inventory_alerts(low_stock_items, overstock_items)
return JsonResponse({
'low_stock_count': len(low_stock_items),
'overstock_count': len(overstock_items),
'healthy_stock_count': len(healthy_stock_items),
'average_turnover': float(average_turnover),
'total_inventory_value': total_inventory_value,
'stock_health_score': stock_health_score,
'aging_analysis': aging_analysis,
'reorder_suggestions': reorder_suggestions,
'inventory_alerts': inventory_alerts,
'low_stock_items': low_stock_items.to_dict('records')
})
@csrf_exempt
def supply_chain_cost_analysis(request):
if request.method == 'POST':
data = json.loads(request.body)
analysis_period = data.get('period', 'monthly')
cost_category = data.get('category', 'all')
df = spark.sql(f"""
SELECT supplier_id, cost_type, cost_amount, cost_date,
product_category, shipping_cost, handling_cost
FROM supply_chain_costs
WHERE cost_date >= DATE_SUB(CURRENT_DATE(), 90)
""")
pandas_df = df.toPandas()
if cost_category != 'all':
pandas_df = pandas_df[pandas_df['cost_type'] == cost_category]
cost_breakdown = pandas_df.groupby('cost_type')['cost_amount'].sum().to_dict()
supplier_costs = pandas_df.groupby('supplier_id').agg({
'cost_amount': 'sum',
'shipping_cost': 'sum',
'handling_cost': 'sum'
}).reset_index()
monthly_trend = pandas_df.groupby(pandas_df['cost_date'].dt.to_period('M'))['cost_amount'].sum()
cost_efficiency_ratio = calculate_cost_efficiency(pandas_df)
cost_per_product = pandas_df.groupby('product_category')['cost_amount'].mean().to_dict()
total_logistics_cost = pandas_df[['shipping_cost', 'handling_cost']].sum().sum()
cost_variance = analyze_cost_variance(pandas_df)
supplier_performance = evaluate_supplier_performance(pandas_df)
cost_optimization_suggestions = generate_cost_optimization_recommendations(pandas_df)
budget_utilization = calculate_budget_utilization(pandas_df)
seasonal_cost_patterns = identify_seasonal_patterns(pandas_df)
return JsonResponse({
'cost_breakdown': cost_breakdown,
'supplier_performance': supplier_performance.to_dict('records'),
'monthly_trend': monthly_trend.to_dict(),
'cost_efficiency_ratio': float(cost_efficiency_ratio),
'cost_per_product': cost_per_product,
'total_logistics_cost': float(total_logistics_cost),
'cost_variance': cost_variance,
'optimization_suggestions': cost_optimization_suggestions,
'budget_utilization': budget_utilization,
'seasonal_patterns': seasonal_cost_patterns
})
def calculate_growth_rate(df):
if len(df) < 2:
return 0
current_period = df['sales_amount'].sum()
previous_period = df['sales_amount'].iloc[:len(df)//2].sum()
if previous_period == 0:
return 0
return ((current_period - previous_period) / previous_period) * 100
def calculate_inventory_value(df):
return df['current_stock'].sum() * 50
def calculate_stock_health_score(df):
healthy_items = len(df[(df['current_stock'] > df['safety_stock']) & (df['current_stock'] < df['reorder_point'] * 3)])
total_items = len(df)
return (healthy_items / total_items) * 100 if total_items > 0 else 0
def perform_aging_analysis(df):
current_date = pd.Timestamp.now()
df['days_since_restock'] = (current_date - pd.to_datetime(df['last_restock_date'])).dt.days
aging_buckets = {
'0-30 days': len(df[df['days_since_restock'] <= 30]),
'31-60 days': len(df[(df['days_since_restock'] > 30) & (df['days_since_restock'] <= 60)]),
'60+ days': len(df[df['days_since_restock'] > 60])
}
return aging_buckets
def generate_reorder_suggestions(df):
reorder_needed = df[df['current_stock'] <= df['reorder_point']]
suggestions = []
for _, row in reorder_needed.iterrows():
suggestions.append({
'product_id': row['product_id'],
'current_stock': int(row['current_stock']),
'suggested_order': int(row['safety_stock'] * 2)
})
return suggestions
def generate_inventory_alerts(low_stock_df, overstock_df):
alerts = []
for _, row in low_stock_df.iterrows():
alerts.append({
'type': 'LOW_STOCK',
'product_id': row['product_id'],
'message': f"Product {row['product_id']} is below reorder point"
})
for _, row in overstock_df.iterrows():
alerts.append({
'type': 'OVERSTOCK',
'product_id': row['product_id'],
'message': f"Product {row['product_id']} has excess inventory"
})
return alerts
def calculate_cost_efficiency(df):
total_cost = df['cost_amount'].sum()
total_revenue = df['cost_amount'].sum() * 1.3
return (total_revenue - total_cost) / total_cost if total_cost > 0 else 0
def analyze_cost_variance(df):
cost_std = df['cost_amount'].std()
cost_mean = df['cost_amount'].mean()
return float(cost_std / cost_mean) if cost_mean > 0 else 0
def evaluate_supplier_performance(df):
performance = df.groupby('supplier_id').agg({
'cost_amount': ['mean', 'std'],
'shipping_cost': 'mean'
}).reset_index()
performance.columns = ['supplier_id', 'avg_cost', 'cost_stability', 'avg_shipping']
performance['performance_score'] = 100 - (performance['cost_stability'] / performance['avg_cost'] * 100)
return performance.fillna(0)
def generate_cost_optimization_recommendations(df):
high_cost_suppliers = df.groupby('supplier_id')['cost_amount'].mean().nlargest(3)
recommendations = []
for supplier_id, avg_cost in high_cost_suppliers.items():
recommendations.append({
'supplier_id': supplier_id,
'recommendation': f"Review pricing with supplier {supplier_id}",
'potential_savings': float(avg_cost * 0.1)
})
return recommendations
def calculate_budget_utilization(df):
total_actual_cost = df['cost_amount'].sum()
estimated_budget = total_actual_cost * 1.2
return (total_actual_cost / estimated_budget) * 100 if estimated_budget > 0 else 0
def identify_seasonal_patterns(df):
df['month'] = pd.to_datetime(df['cost_date']).dt.month
monthly_avg = df.groupby('month')['cost_amount'].mean().to_dict()
return {f"Month_{k}": float(v) for k, v in monthly_avg.items()}六.系统文档展示

结束
💛💛想说的话:感谢大家的关注与支持! 💕💕文末获取源码联系 计算机程序员小杨 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目 计算机毕业设计选题 💜💜