

• 论文题目:
H-RDT: Human Manipulation Enhanced Bimanual Robotic Manipulation
• 论文链接:
• 项目主页:
embodiedfoundation.github.io/hrdt
H-RDT 架构
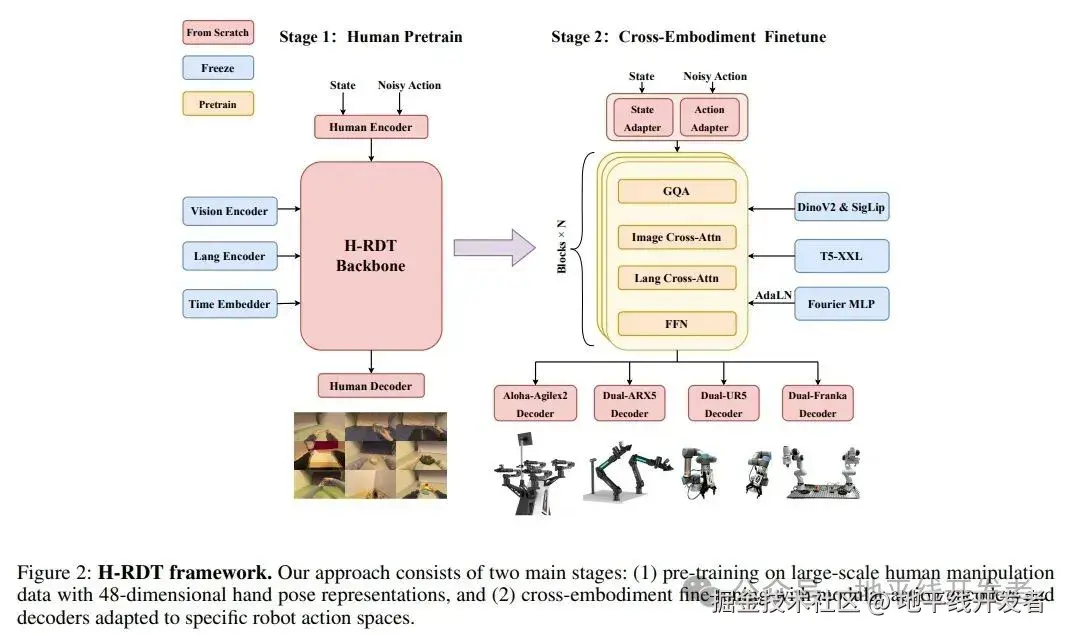
H-RDT是一个具有20亿参数的扩散Transformer,使用流匹配来建模双臂机器人的复杂动作分布。H-RDT采用两阶段训练范式:1)在大规模第一人称人类数据上预训练;2)通过模块化动作编解码器在机器人数据上进行微调,实现跨本体迁移。
人类动作表征设计
我们采用较为精细的3D手部姿态表示方法,将动作编码为紧凑的48维向量,以捕捉关键的双手灵巧操作信息:
- 双手手腕位姿 (Bilateral Wrist Pose) :
(1)左右手的3D位置(3×2)与6D姿态(6×2),共计18维;
(2)与机器人控制中的末端执行器 (End-Effector) 控制参数对齐;
- 十个手指的指尖位置 (Fingertip Position) :
(1)每个手五根手指,各提取一个三维坐标,总共10×3=30维;
(2)用于表达手指张合、握持形态等细粒度操作意图。
总计:18(手腕)+30(指尖)=48维动作表示
这种表征策略的优势体现在三个方面:
(1)动作通用性强:该表示可以视作覆盖大多数操作型机器人的"上层动作空间",能覆盖如双臂7-DoF机械臂、并联夹爪等控制参数;
(2)保留人类操作的关键特征:指尖相对位置、手腕旋转、抓取姿态等都被编码在其中,保留了对操控几何和力学要素的刻画能力;
(3)提供显式的动力学参数:相比于point flow等表征方式,无需额外增加动力学映射,更为聚焦操作语义。
模型结构
H-RDT构建了一个五模块组成的DiT (Diffusion Transformer) 框架,负责从多模态感知输入生成机器人控制序列:
-
视觉编码器 (DinoV2+SigLIP) :提取RGB观测的视觉特征;配有MLP Adapter映射到transformer嵌入空间。
-
语言编码器 (T5-XXL) :编码自然语言任务指令;同样通过MLP Adapter接入主干。
-
模块化动作编/解码器:编码器对机器人状态向量与噪声动作轨迹分别编码;解码器将输出特征解码为Action Chunk,其在微调阶段对不同本体重新初始化。
-
Transformer主干(类LLaMA3架构):使用SwiGLU激活与RMSNorm;使用解耦交叉注意力分别对视觉和语言信息进行融合;流时间 (τ) 通过AdaLN注入。
两阶段训练范式
阶段一:人类数据预训练
第一阶段使用EgoDex数据集,以48维人手动作表征对H-RDT进行预训练。EgoDex数据集包括338 K+条轨迹、涵盖194项不同操作任务,全面覆盖了人类操作策略、物体交互方式以及双手协作。
阶段二:跨本体微调
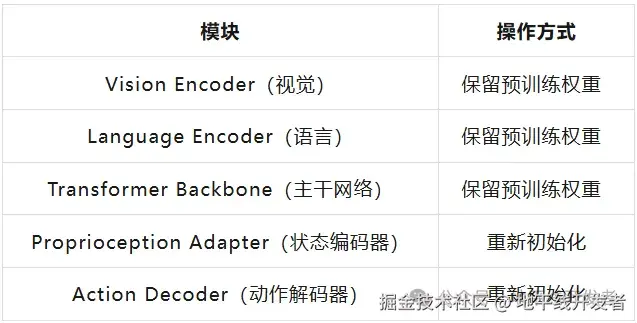
第二阶段对特定机器人本体微调时,需重新初始化动作编码器和解码器子模块以适应不同本体,其余模块使用预训练权重进行微调。
流匹配训练方法

实验结果
真机实验
我们在三种真实机器人上进行多任务训练,用于验证模型的跨本体迁移能力与实际部署的鲁棒性。
1)Aloha-Agilex-2.0实验
两项任务均采用基于子任务的评分体系,全部完成视为完全成功。各方法各任务均测试25次。
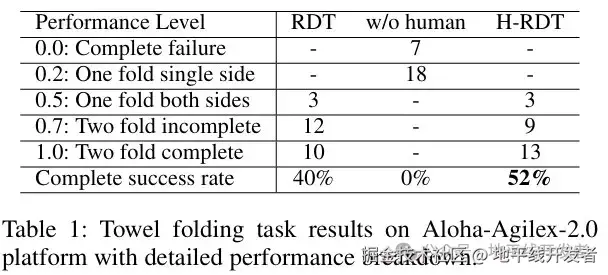
**任务1叠毛巾:**测试模型连续折叠柔性物体的能力。

实验结果如下表所示,H-RDT的完全成功率为52%,RDT为40%,未经人类数据预训练的模型成功率为0。
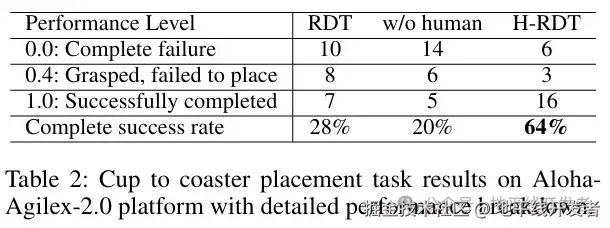
任务2将杯子放到杯垫上: 该任务测试模型的空间推理能力,要求模型根据杯子的自动选择合适的手去抓杯子(左侧杯子必须用左手抓,右侧杯子必须用右手抓)。

实验结果如下表所示,H-RDT的完全成功率为64%,RDT为28%,未经人类数据预训练的模型成功率为20%。
2)双臂ARX5小样本实验
我们设计了一个极具挑战的任务:在双臂ARX5机器人上完成113个不同的抓取放置任务,每个任务仅提供1到5个示范样本。

实验结果如下表所示,H-RDT成功率达到了41.6%,而π0仅为31.2%,RDT为16%,未经人类数据预训练的模型17.6%。
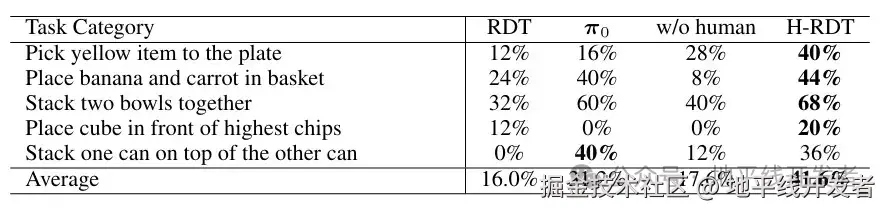
3)双臂UR5+UMI实验
我们在双臂UR5机器人上评估了H-RDT,人类演示数据通过UMI收集。任务为双手协作放置外卖袋,细分为四个连续步骤:右手抓取 → 右手放置 → 左手抓取 → 左手放置。
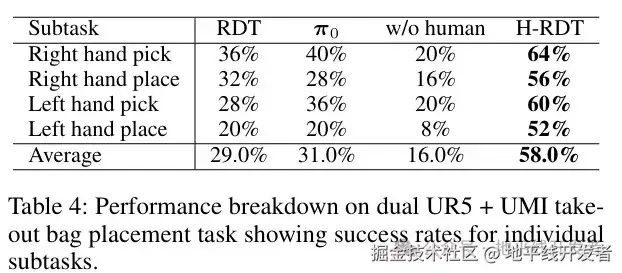
实验结果如下表所示,H-RDT完全成功率达到58.0%,远超RDT(29%)、 π0(31%)、未经人类数据预训练的版本(16%)。
仿真测试
我们在仿真环境RoboTwin 2.0上进行了全面测试,包括单任务和多任务设置:
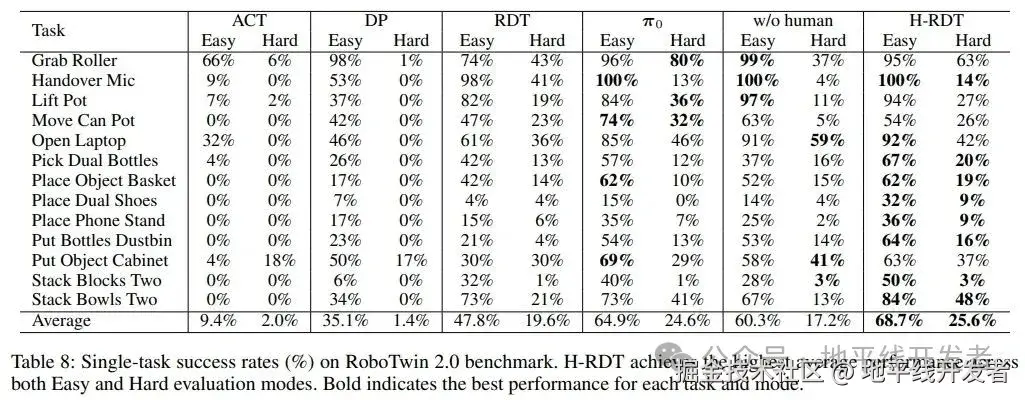
**单任务实验:**在RoboTwin 2.0基准测试的13项操作任务上评估单任务性能。每项任务使用简单模式下收集的50个演示样本进行训练,并在两种模式下评估:包括简单模式(干净桌面)与困难模式(随机光照、杂乱环境)。
H-RDT在简单模式下取得了最高68.7%的平均成功率,在困难模式下为25.6%,显著优于其他方法;且在简单和困难模式下均大幅超越未经人类数据预训练的版本 (w/o human) ,证明了利用人类操作数据预训练的有效性。
**多任务实验:**在RoboTwin 2.0的45项任务上进行多任务实验,使用在困难模式下收集的约2250个演示样本进行训练,评估了10项任务子集。实验结果如下表所示。
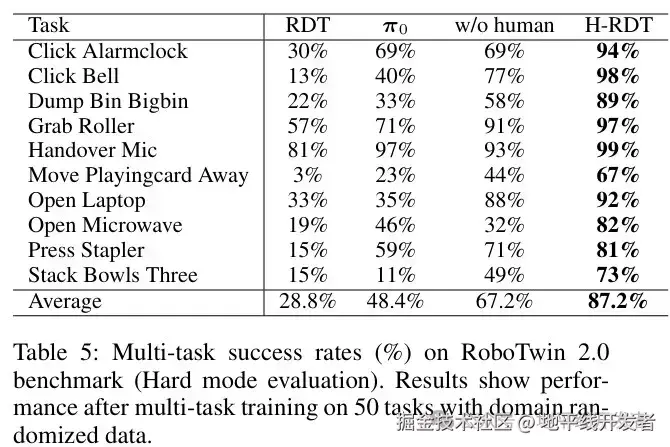
在多任务场景中,H-RDT取得了高达87.2%的平均成功率,显著优于RDT(28.8%)、π0(48.4%)和未经人类数据预训练的版本w/o human(67.2%)。H-RDT相较于未经人类数据预训练版本w/o human平均成功率提高了20.0%,明显大于在单任务场景。这表明,在多任务场景中,利用人类操作数据进行预训练能提供更好的性能。
**跨本体泛化:**为进一步验证H-RDT的跨本体迁移能力,在仿真环境中对两种不同的机器人本体Aloha-Agilex-1.0和Franka-Panda进行了多任务实验,实验结果如下图所示。
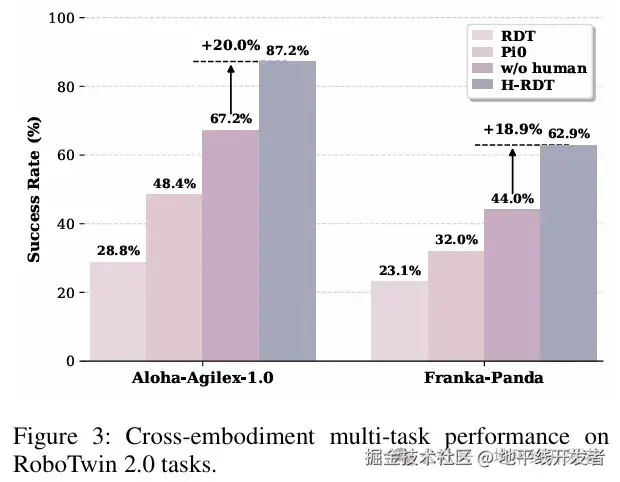
H-RDT在两种机器人上均表现出很强的性能,在 Aloha-Agilex-1.0上达到87.2%的成功率,在Franka-Panda上达到62.9%的成功率,在两个机器人上均显著优于基线方法。
总结与展望
本文提出H-RDT模型,使用具有3D手部位姿标注的第一人称人类操作视频预训练以增强双臂机器人的操作能力。展望未来,面对数据采集成本高、模型泛化困难等挑战,人类操作数据凭借其极低的采集成本和丰富的操作语义,将成为机器人策略学习不可忽视的新"宝藏"。