点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到: Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Hadoop 集群启动
- Spark 集群启动
- h121 h122 h123 节点启动
- 集群启动测试 SparkShell

什么是RDD
RDD的基本概念
RDD(Resilient Distributed Dataset)是Spark框架中最核心的数据抽象,它是Spark实现分布式计算的基础数据结构。RDD代表一个不可变、可分区、元素可并行计算的分布式集合。
RDD的核心特性
RDD具有以下五个关键特征:
-
分区列表(Partitions):
- RDD由多个分区组成,每个分区包含数据集的一部分
- 分区是Spark并行处理的基本单位
- 例如:一个包含100万条数据的RDD可能被分成10个分区,每个分区约10万条数据
-
计算函数(Compute Function):
- 每个RDD都有一个计算函数compute,用于对分区进行计算
- 这个函数定义了如何从父RDD计算出当前RDD
- 例如:map操作会对每个分区应用相同的转换函数
-
依赖关系(Dependencies):
- RDD保存了与其他RDD的依赖关系列表
- 依赖分为窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)
- 窄依赖:每个父RDD分区最多被子RDD的一个分区依赖(如map、filter)
- 宽依赖:每个父RDD分区被子RDD的多个分区依赖(如groupByKey)
-
分区器(Partitioner)可选:
- 对于键值对RDD,可以指定分区器(如HashPartitioner或RangePartitioner)
- 分区器决定了数据在不同节点上的分布方式
- 例如:使用HashPartitioner会按照键的哈希值分配数据
-
优先位置列表(Preferred Locations)可选:
- 每个分区有一组优先位置(节点)列表
- 基于数据本地性原则,Spark会尽量将计算任务调度到数据所在节点
- 例如:从HDFS读取的数据会记录其所在的数据节点位置
RDD的设计优势
RDD的设计带来了以下重要优势:
- 容错性:通过血缘关系(Lineage)可以重建丢失的分区
- 并行性:分区机制天然支持并行计算
- 内存计算:数据可以持久化在内存中,提高计算速度
- 惰性求值:转换操作(Transformation)延迟执行,直到遇到行动操作(Action)才真正计算
RDD的应用场景详解
RDD(弹性分布式数据集)作为Spark的核心数据结构,适用于以下典型场景:
1. 需要多次使用的数据集(内存缓存优势)
- 当同一个数据集需要被多个操作重复使用时,RDD可以通过
.persist()或.cache()方法将数据缓存在内存中 - 典型应用:迭代式机器学习算法(如K-means聚类),每次迭代都需要重复使用训练数据
- 示例:
val cachedRDD = sc.textFile("data.txt").cache()
2. 需要细粒度控制的转换操作
- RDD提供丰富的底层API,支持完全控制数据处理过程
- 包括:map、filter、flatMap等基本转换,以及自定义分区控制
- 适合场景:需要精确控制数据分区或执行位置的复杂计算任务
3. 需要构建复杂的数据处理流水线
- 通过RDD的转换操作可以构建多阶段处理流水线
- 典型流程:数据清洗 → 特征提取 → 模型训练
- 示例:
scala
val pipeline = sc.textFile("logs")
.filter(_.contains("ERROR")) // 过滤
.map(parseLog) // 解析
.groupBy(_.service) // 分组4. 需要基于键值对的聚合操作
- 提供reduceByKey、groupByKey等专门针对键值对RDD的操作
- 适合场景:统计计算、关联分析等
- 示例:
wordCount = text.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
实际应用领域
-
ETL处理(数据抽取-转换-加载):
- 处理大规模日志文件
- 数据格式转换(CSV→Parquet)
- 数据质量校验
-
机器学习算法:
- 支持迭代式计算(梯度下降等)
- 可以配合MLlib库使用
- 适合定制化算法实现
-
图计算:
- 通过GraphX扩展实现
- 用于社交网络分析、推荐系统等
- 支持Pregel图计算模型
与其他API的关系
虽然Spark后续推出了DataFrame(结构化API)和DataSet(类型安全API),但RDD仍保持其独特优势:
- 最底层的执行引擎
- 完全控制计算过程
- 支持任意Java/Scala对象
- 适合非结构化数据处理
在Spark 2.x+版本中,RDD可以与DataFrame相互转换,开发者可以根据场景选择最合适的抽象层。
RDD 特点介绍
不可变性(Immutability)
RDD一旦创建,就不能被修改。每次对RDD进行操作(例如过滤、映射等)都会产生一个新的RDD。这种不可变性简化了并行处理,因为无需担心多个计算节点间的数据竞争。
分布式(Distributed)
RDD的数据分布在多个节点上,这使得Spark能够处理大规模的数据集。RDD的每个分区都可以在不同的节点上独立处理。
容错性(Fault Tolerance)
RDD通过"血统"(Lineage)记录其生成方式。如果RDD的某些分区在计算过程中丢失,可以根据这些血统信息重新计算丢失的数据。通过这种方式,RDD能够在节点故障时自动恢复。
惰性求值(Lazy Evaluation)
RDD的操作被分为两类:转换操作(Transformations) 和 行动操作(Actions)。转换操作是惰性求值的,即不会立即执行,而是等到遇到行动操作时才触发计算。这样做的好处是可以通过合并多个转换操作来优化计算过程,减少不必要的中间计算。
类型安全(Type Safety)
在Scala语言中,RDD是类型安全的,意味着你可以在编译时捕获类型错误,这对开发者来说非常有帮助。
并行操作(Parallel Operation)
RDD的每个分区可以独立进行处理,允许多线程或多节点并行执行,充分利用集群的计算资源。
缓存与持久化(Caching and Persistence)
可以将RDD缓存或持久化到内存或磁盘中,以便在多次使用时避免重复计算,从而提高性能。
丰富的API
RDD提供了丰富的API支持各种操作,包括map、filter、reduceByKey、groupBy、join等,能够满足大部分分布式数据处理的需求。
RDD的特点
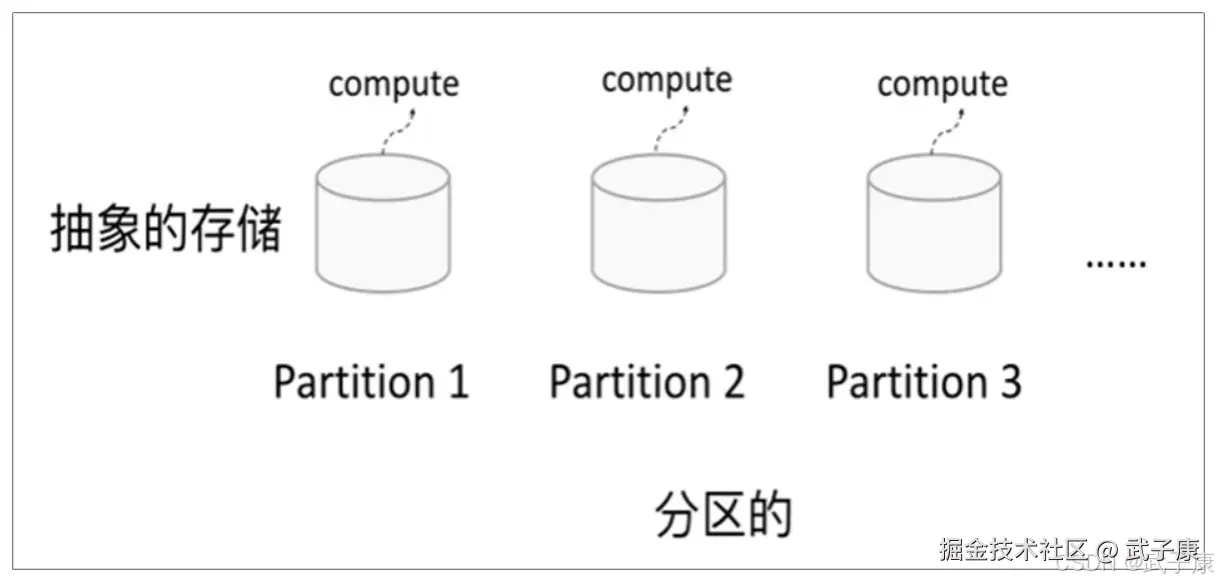
分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候通过一个compute函数得到每个分区的数据。如果RDD是通过己有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
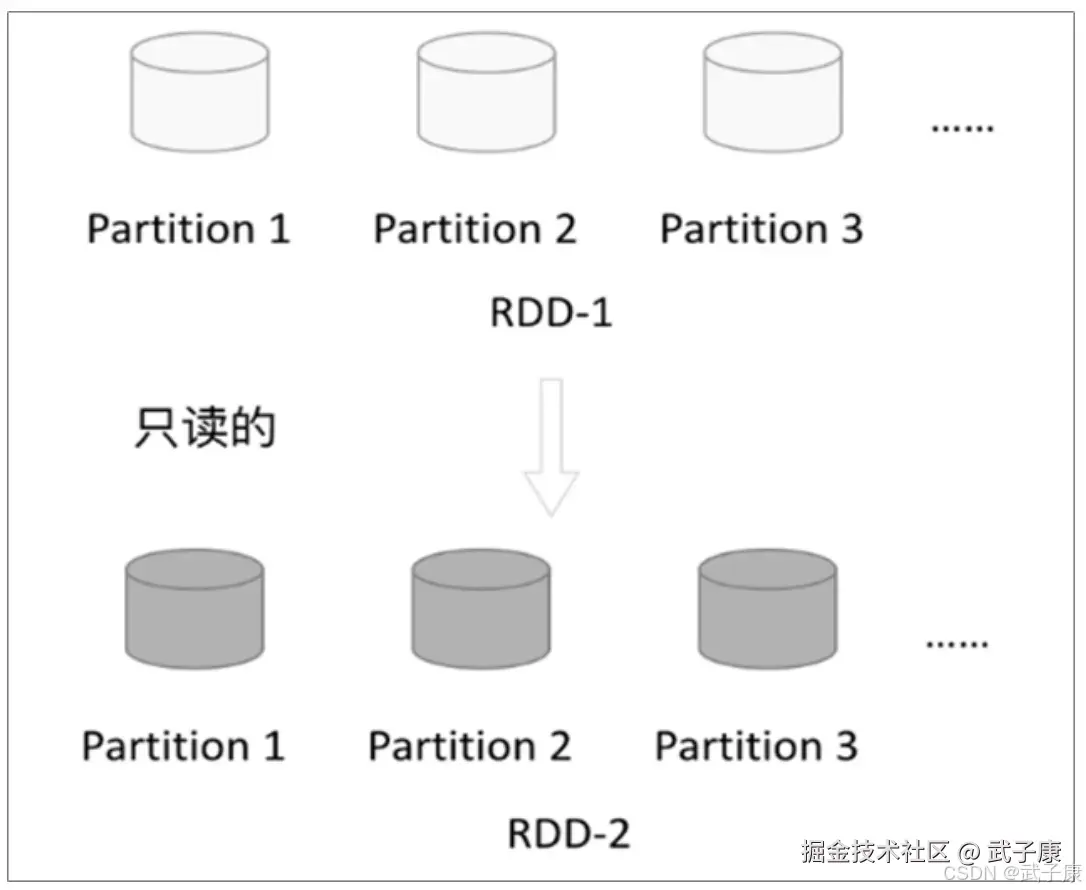
只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。 一个RDD转换为另一个RDD,通过丰富的算子(map filter union join reduceByKey等等)实现,不再像MR那样写Map和Reduce了。
 RDD的操作算子包括两类:
RDD的操作算子包括两类:
- Transformation:用来对RDD进行转化,延迟执行(Lazy)
- Action:用来出发RDD的计算,得到相关计算结果或者将RDD保存的文件系统中
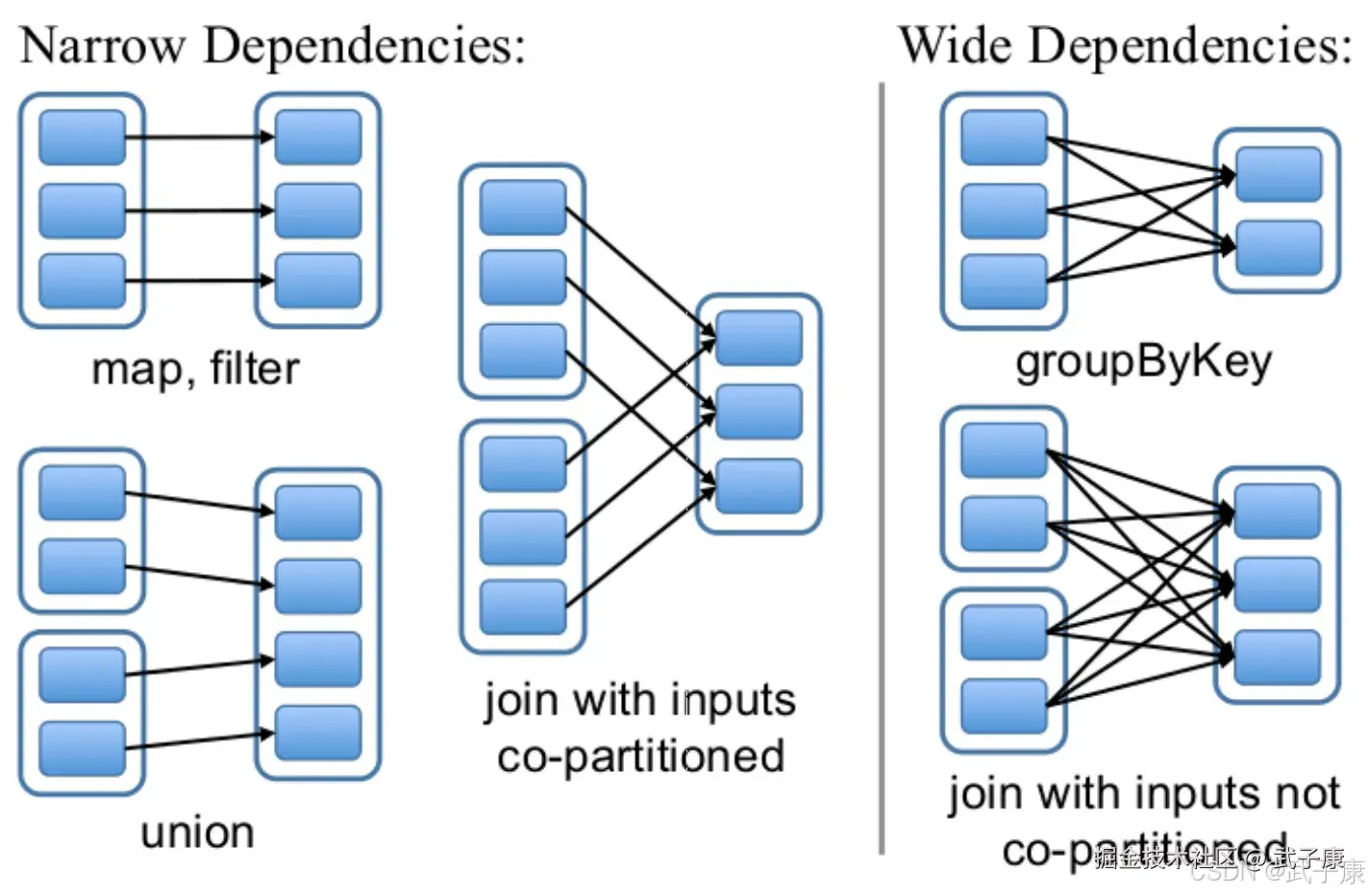
依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生出所必须得信息,RDDs之间维护着这种学院关系(lineage),也称为依赖。
- 窄依赖:RDDs之间的分区是一一对应的(1对1 或者 n对1)
- 宽依赖:子RDD每个分区与父RDD的每个分区都有关,是多对多的关系
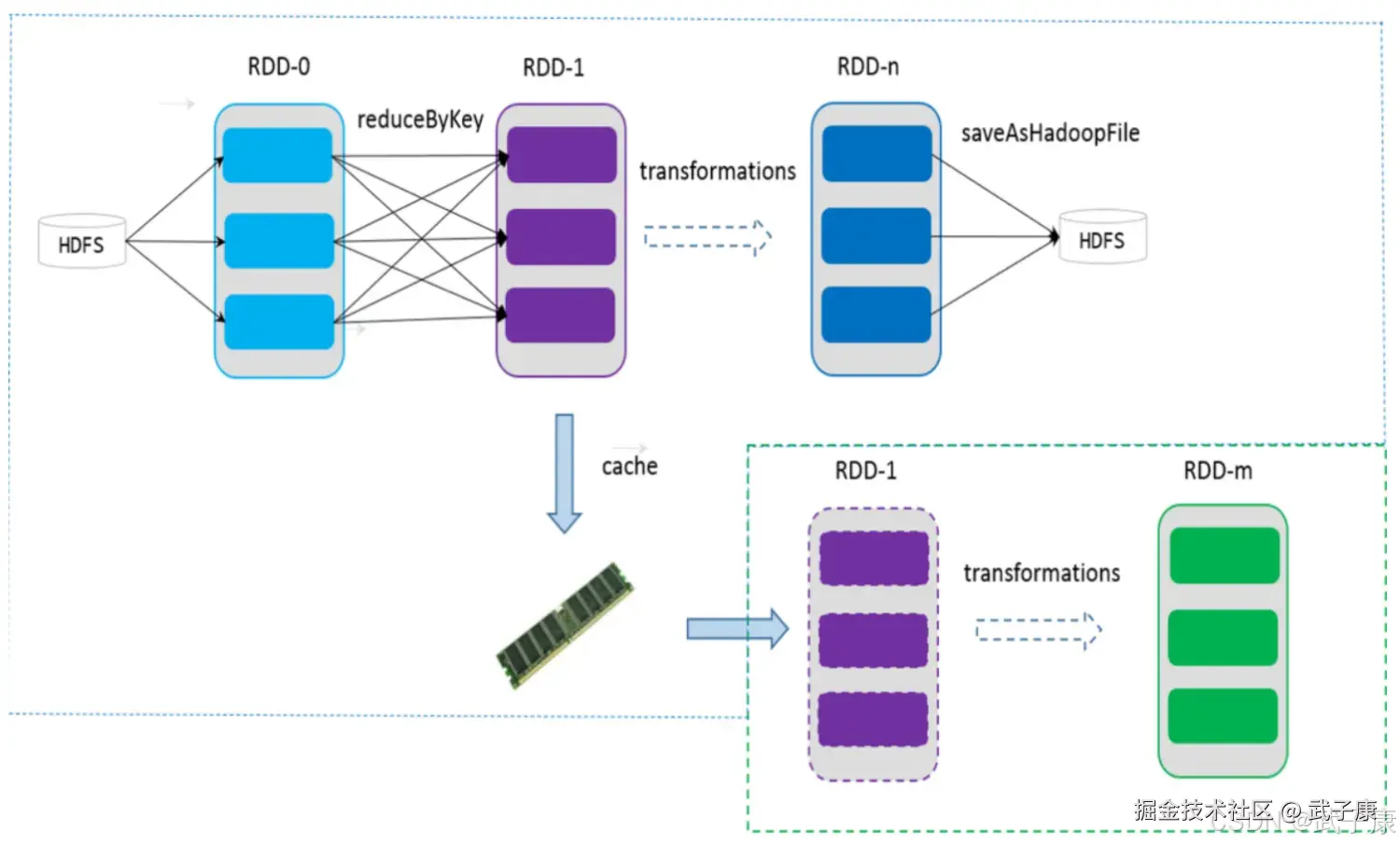
缓存
可以控制存储级别(内存、磁盘等)来进行缓存 如果在应用程序中多次使用同一个RDD,可以将RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存取而不用再根据血缘计算,加速后期的重用。
CheckPoint机制详解
1. RDD血缘关系的局限性
RDD(弹性分布式数据集)通过DAG(有向无环图)记录其转换过程,形成所谓的"血缘关系"(Lineage)。这种机制确实为RDD提供了天然的容错能力:当某个分区数据丢失时,Spark可以根据这个血缘关系重新计算恢复数据。然而,这种机制在长时间迭代型应用(如机器学习训练)中会暴露出明显的性能问题:
- 血缘链增长问题:例如在一个迭代100次的机器学习算法中,每次迭代都会产生新的RDD,血缘关系会变得非常长。如果第99次迭代失败,需要从头开始重新计算所有前98次迭代的结果。
- 计算资源浪费:长血缘链导致恢复时间显著增加,造成计算资源的浪费。
2. CheckPoint的工作原理
CheckPoint机制通过将RDD数据持久化到可靠存储系统(如HDFS)来解决上述问题:
-
持久化存储:
- 将RDD数据写入分布式文件系统如HDFS
- 存储格式通常是二进制格式,保证高效读写
- 默认存储级别是MEMORY_AND_DISK_SER
-
血缘关系切断:
scala// 示例:设置CheckPoint目录并执行CheckPoint sc.setCheckpointDir("hdfs://...") val rdd = sc.parallelize(1 to 100).map(_ * 2) rdd.checkpoint() -
恢复机制:
- 当CheckPoint过的RDD需要被使用时,直接从存储系统读取
- 不再需要沿血缘关系重新计算
3. 适用场景与最佳实践
典型应用场景:
- 机器学习模型训练(迭代算法)
- 图计算算法(如PageRank)
- 流处理中的有状态计算
配置建议:
- 对于迭代算法,建议每5-10次迭代执行一次CheckPoint
- 选择高性能的存储后端,如Alluxio可以加速CheckPoint过程
- 考虑使用REPLICATE存储级别提高可靠性
与persist()的区别:
| 特性 | CheckPoint | persist() |
|---|---|---|
| 存储位置 | 可靠存储系统 | 内存/本地磁盘 |
| 血缘关系 | 完全切断 | 保留 |
| 可靠性 | 高 | 取决于存储级别 |
| 性能影响 | 较大(涉及IO) | 较小 |
4. 实现细节
Spark执行CheckPoint的过程实际上是惰性的,只有在遇到Action操作时才会真正执行。为确保数据可靠性,Spark会先执行一次额外的计算任务将数据写入CheckPoint目录,这个过程是同步阻塞的。在Spark 2.1之后,引入了异步CheckPoint机制来减少性能影响。
Spark编程模型
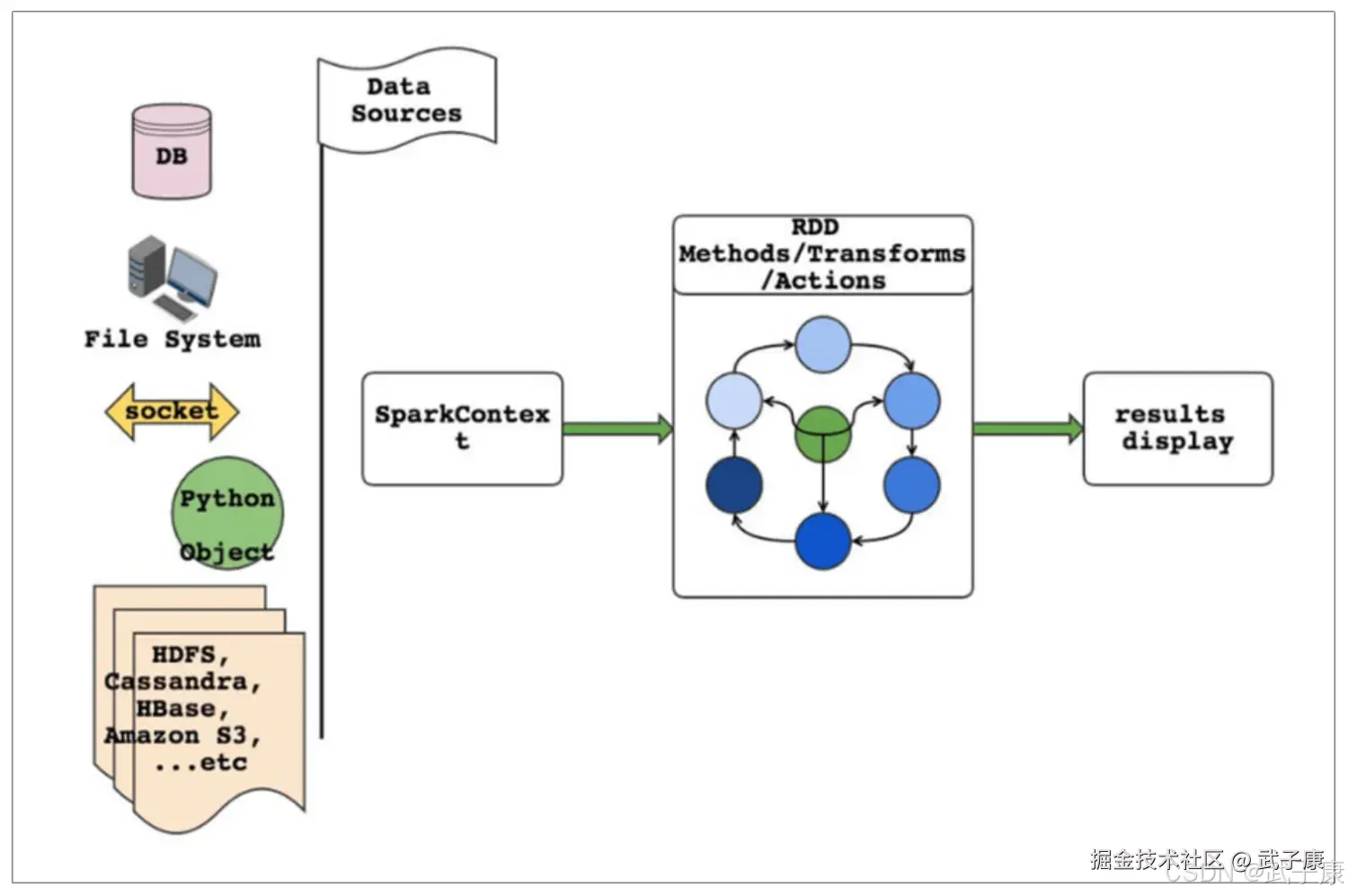
- RDD表示数据对象
- 通过对象上的方法调用来对RDD进行转换
- 最终显示结果或者将结果输出到外部数据源
- RDD转换算子称为Transformation是Lazy的(延迟执行)
- 只有遇到 Action算子,才会执行RDD的转换操作
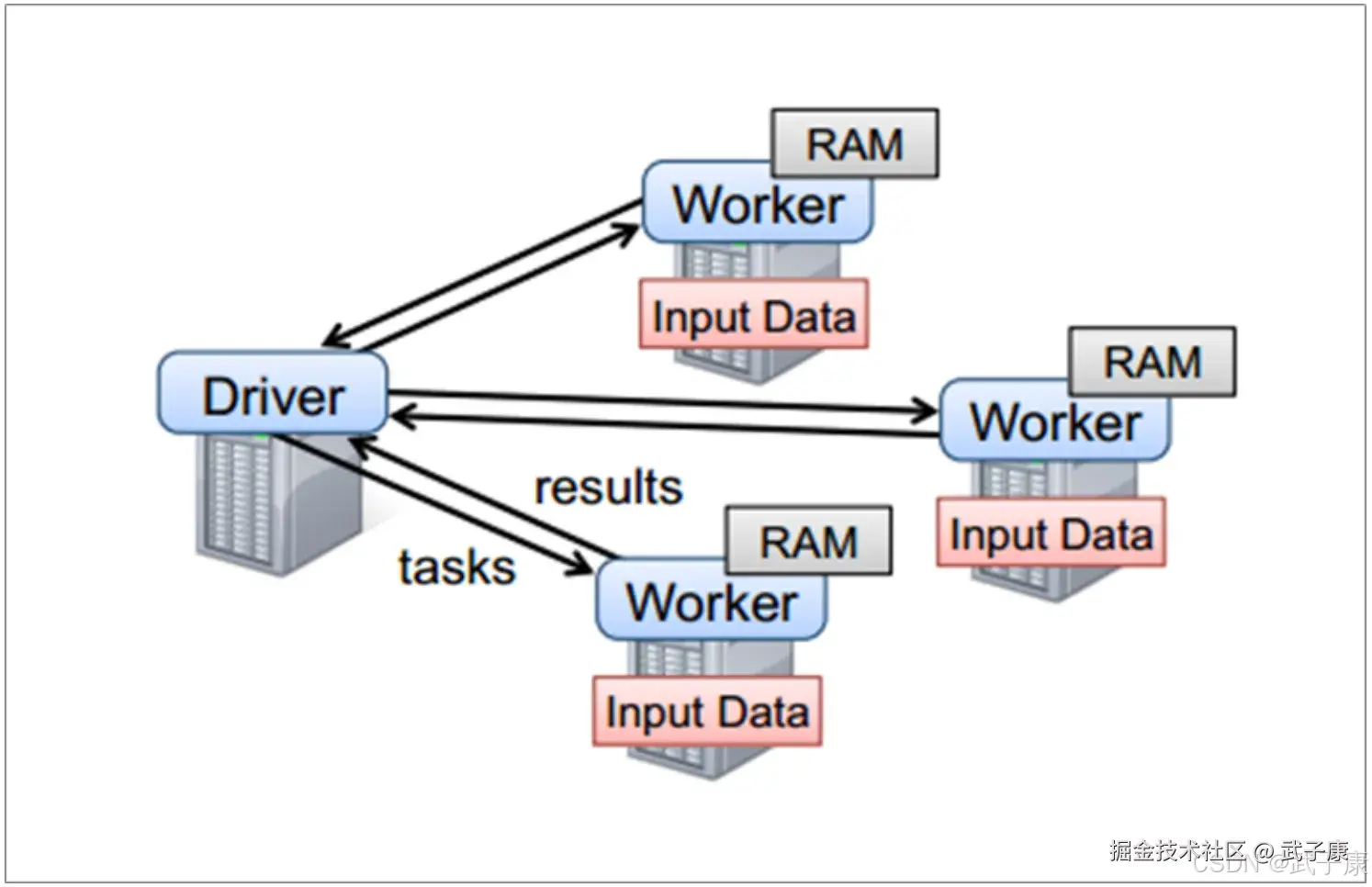
如果要使用Spark,就需要编写Driver程序,它被提交到集群运行。
- Driver中定义了一个或多个RDD,并调用RDD上的各种算子
- Worker则执行RDD分区计算任务