本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
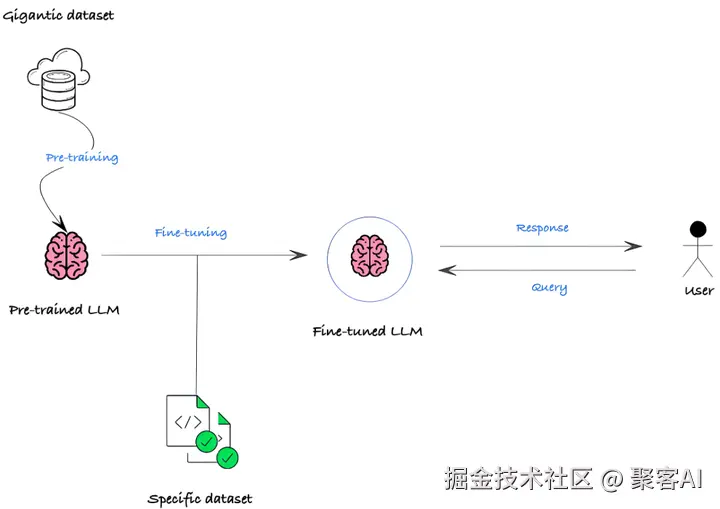
我们都知道文本嵌入模型能将文本表示为具有语义意义的向量,广泛应用于检索、分类、检索增强生成(RAG)等场景。然而,通用嵌入模型在特定领域任务上往往表现不佳,语义相似度不足以确保检索结果真正有用。解决这一问题的核心方法是微调(fine-tuning),它通过额外训练调整模型行为,使其适应领域特定需求。今天我们将探讨微调的技术原理、实施步骤,希望能帮助到各位,废话不多说,我们进入正文。
一、嵌入模型的基础与挑战
文本嵌入模型的核心价值在于其能捕捉文本的语义信息。在RAG系统中,嵌入模型用于三步检索过程:
- 为知识库中的所有项目计算向量表示(即嵌入)。
- 将输入文本(如用户查询)转换为相同模型的向量表示。
- 计算查询向量与知识库项的相似度,返回最相似项目。
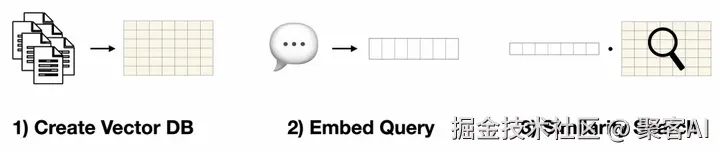
尽管这一过程灵活高效,但存在根本问题:语义相似并不保证检索项目能有效回答问题。
例如,查询"如何更新我的付款方式?"可能返回相似但不相关的响应:"要查看您的付款历史记录,请访问账单部分"。
这种不匹配在特定领域(如AI招聘)更突出,因为通用模型无法充分理解领域术语(如"扩展"或"实例"的特定含义)。
二、微调的核心原理:对比学习
微调通过对比学习(Contrastive Learning, CL)解决上述问题。CL的核心思想是学习表示,以最大化正样本对(如相关查询和答案)的相似度,同时最小化负样本对(如不相关配对)的相似度。这种方法不需要手动标注数据,而是利用数据固有结构(如元数据)自动整理正负对,从而实现大规模高效训练。
对比学习的关键优势包括:
- 数据效率:正负对可从无标签数据自动生成(如网络图像元数据),减少人工成本。
- 损失函数设计:CL使用特定损失函数(如CLIP中的损失)同时优化正负样本相似度,确保嵌入空间对齐。


在微调中,CL通过最小化相关对嵌入距离并最大化不相关对距离,使模型更好地区分有用和无用结果。例如,在AI招聘中,微调可确保查询"数据科学家经验"匹配到相关职位描述,而非语义相似但不相关的条目。
三、微调嵌入模型的五步实践流程
微调过程可分为五个关键步骤,每一步需仔细执行以确保效果。我以AI招聘信息匹配为例,详细说明每个步骤的实施方法。该示例目标是将求职者查询与职位描述(JD)精准匹配。
步骤1: 收集正负样本对
这是最关键且耗时的步骤,需要高质量数据准备。在AI招聘示例中,我们从Hugging Face数据集提取职位描述,生成合成查询,并清理数据以移除无关部分(如超过512令牌的文本)。具体流程:
- 加载数据集:使用Hugging Face的linkedin_job_listings数据集,提取标题和描述。
- 生成查询:借助GPT-4o-mini创建类似人类的搜索查询(如"数据科学家6年经验,LLM背景"),确保查询真实反映求职者意图。
- 清理数据:删除JDs中无关资格部分,避免模型处理超长文本。
- 创建正负对:正样本对由清理后的JDs和合成查询组成;负样本对通过预训练模型计算相似度后,选择最不相似的JDs生成,确保唯一性。
- 数据分割:将数据划分为训练集(80%)、验证集(10%)和测试集(10%),并上传至Hugging Face Hub便于访问。

最终数据集包含1012个清理JDs,确保正负对平衡。
步骤2: 选择预训练模型
选择合适的预训练模型是微调基础。我们评估多个模型(如sentence-transformers/all-mpnet-base-v2和sentence-transformers/all-distilroberta-v1),使用验证集计算准确率。评估器基于三元组(查询、正JD、负JD)设计:
- 导入模型并编码JDs。
- 计算相似度,通过TripletEvaluator评估准确率。 在AI招聘案例中,all-distilroberta-v1在验证集上初始准确率最高(88.1%),因此选为微调起点。
步骤3: 选择损失函数
损失函数选择取决于数据格式和任务目标。在AI招聘中,我们使用MultipleNegativesRankingLoss,因为它适合(锚点、正值、负值)三元组格式,能有效优化对比学习。损失函数通过最小化正样本距离、最大化负样本距离,提升模型区分能力。
步骤4: 微调模型
微调涉及定义训练参数并执行训练:
- 参数设置:epochs=1, batch_size=16, learning_rate=2e-5。对比学习受益于大batch size和无重复采样(使用NO_DUPLICATES采样器)。
- 训练执行:利用SentenceTransformerTrainer封装训练流程,包括数据集加载、损失应用和评估回调。训练中监控验证集性能,防止过拟合。 在实际项目中,微调后模型验证准确率显著提升至99%。
步骤5: 评估模型
评估基于测试集进行,确保模型泛化能力:
- 计算准确率:使用TripletEvaluator测试三元组匹配,AI招聘测试集准确率达100%。
- 推理应用:将微调模型部署至Hugging Face Hub,便于新查询嵌入和相似度计算(如编码查询"数据科学家6年经验,LLM,信用风险"并匹配JDs)。
四、作者结语
微调嵌入模型是提升特定领域任务性能的有效策略,尤其适用于像AI招聘这样的场景,其中通用模型无法捕捉领域细微差别。通过对比学习和五步流程(数据收集、模型选择、损失函数、训练和评估)可高效定制嵌入模型。好了,今天的分享就到这里,点个小红心,我们下期见。