在上一篇我们讲了 ShardingSphere-JDBC的读写分离和垂直分片:
那么这篇文章就作为续篇来讲一下如何通过该框架来实现水平分片,多表操作等一系列操作。
水平分片
这里给大家画一张图:竖着的线把表分开就是垂直分片,横着的线把表切开就是水平分片
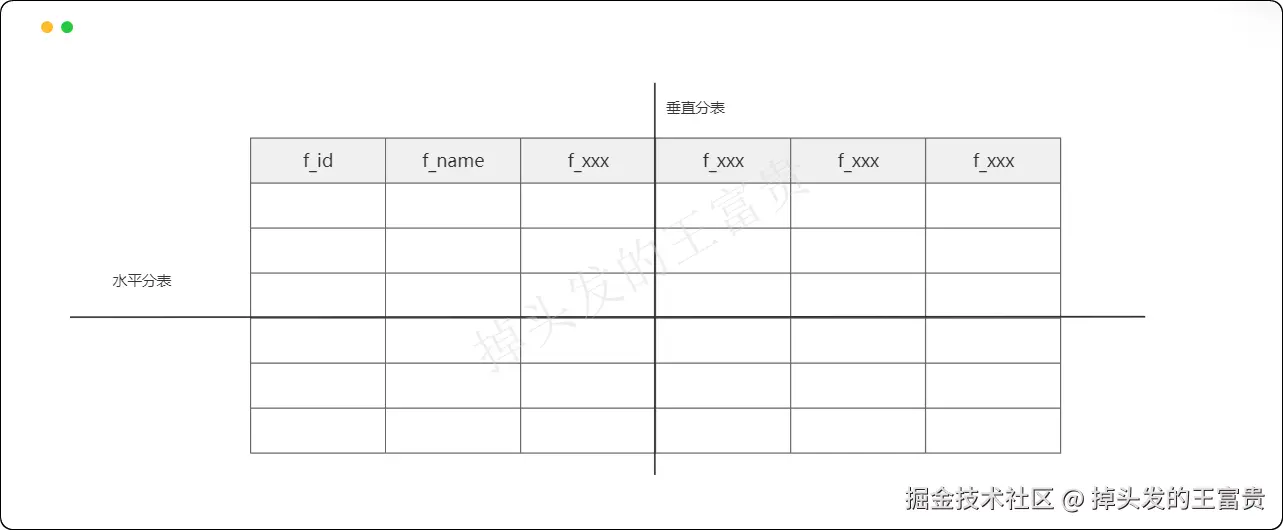
既然我们之前的垂直分片讲完了我们来讲一下如何使用这个框架进行水平分片。
第一步,搭建环境
还是和上一篇一样,我们使用docker进行环境的搭建,这次我们要准备两个容器:
| 角色 | ip | 端口 |
|---|---|---|
| order0 | 127.0.0.1 | 13308 |
| order1 | 127.0.0.1 | 13309 |
创建order0容器
bash
# 创建容器
docker run -d -p 13308:3306 -v C:\docker\mysql\order0\conf:/etc/mysql/conf.d -v C:\docker\mysql\order0\data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 --name order0 mysql:8.0.29
#进入容器:
docker exec -it order0 env LANG=C.UTF-8 /bin/bash
#进入容器内的mysql命令行
mysql -uroot -p123456
#修改默认密码插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';创建order1容器
bash
# 创建容器
docker run -d -p 13309:3306 -v C:\docker\mysql\order1\conf:/etc/mysql/conf.d -v C:\docker\mysql\order1\data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 --name order1 mysql:8.0.29
#进入容器:
docker exec -it order1 env LANG=C.UTF-8 /bin/bash
#进入容器内的mysql命令行
mysql -uroot -p123456
#修改默认密码插件
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';这两步是为了创建容器,准确来说是根据mysql:8.0.29镜像为基础new了两个容器出来,如果不理解推荐去看一下博主之前有关docker的文章:
| 标题 | 链接 |
|---|---|
| 作为开发者,看完这篇文章就可以快速上手Kubernetes了 | juejin.cn/post/749716... |
| 不会Kubernetes?一站式入门指南,带你快速掌握 K8s的核心组件 | juejin.cn/post/749567... |
| Dockerfile不会写?于是我花十分钟看了这篇文章 | juejin.cn/post/749428... |
| SpringBoot应用:Docker与Kubernetes全栈实战秘籍 | juejin.cn/post/744068... |
| Docker入门之Windows安装Docker初体验 | juejin.cn/post/741565... |
| 从零开始玩转 Docker:一站式入门指南,带你快速掌握镜像、容器与仓库 | juejin.cn/post/740318... |
| 面试官让你介绍一下docker,别再说不知道了 | juejin.cn/post/740283... |
| Windows 10环境用Docker发布SpringBoot项目 | juejin.cn/post/724197... |
如果你对docker很了解,那么自然就知道了,如果你对docker不了解也不想去看,那么你就可以理解为这里创建了两个不同的数据库就行了
第二步,创建数据库
order0容器的t_order0和t_order1表
sql
CREATE DATABASE d_order;
USE d_order;
CREATE TABLE `t_order0` (
`f_id` bigint NOT NULL COMMENT '主键',
`f_order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '订单号',
`f_user_id` bigint DEFAULT NULL COMMENT '用户id',
`f_amount` decimal(10,2) DEFAULT NULL COMMENT '数量',
PRIMARY KEY (`f_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `t_order1` (
`f_id` bigint NOT NULL COMMENT '主键',
`f_order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '订单号',
`f_user_id` bigint DEFAULT NULL COMMENT '用户id',
`f_amount` decimal(10,2) DEFAULT NULL COMMENT '数量',
PRIMARY KEY (`f_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;order1容器的t_order0和t_order1表
sql
CREATE DATABASE d_order;
USE d_order;
CREATE TABLE `t_order0` (
`f_id` bigint NOT NULL COMMENT '主键',
`f_order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '订单号',
`f_user_id` bigint DEFAULT NULL COMMENT '用户id',
`f_amount` decimal(10,2) DEFAULT NULL COMMENT '数量',
PRIMARY KEY (`f_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `t_order1` (
`f_id` bigint NOT NULL COMMENT '主键',
`f_order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '订单号',
`f_user_id` bigint DEFAULT NULL COMMENT '用户id',
`f_amount` decimal(10,2) DEFAULT NULL COMMENT '数量',
PRIMARY KEY (`f_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;加上上篇文章创建的t_user表,我们目前的环境就是这样的:
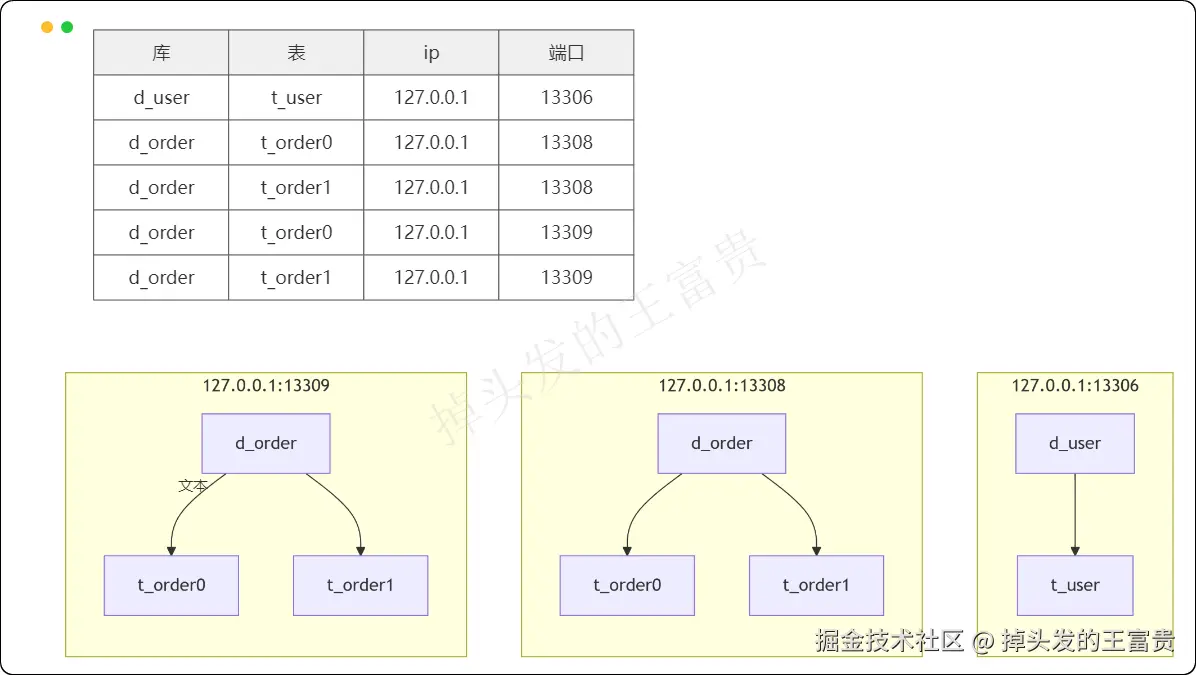
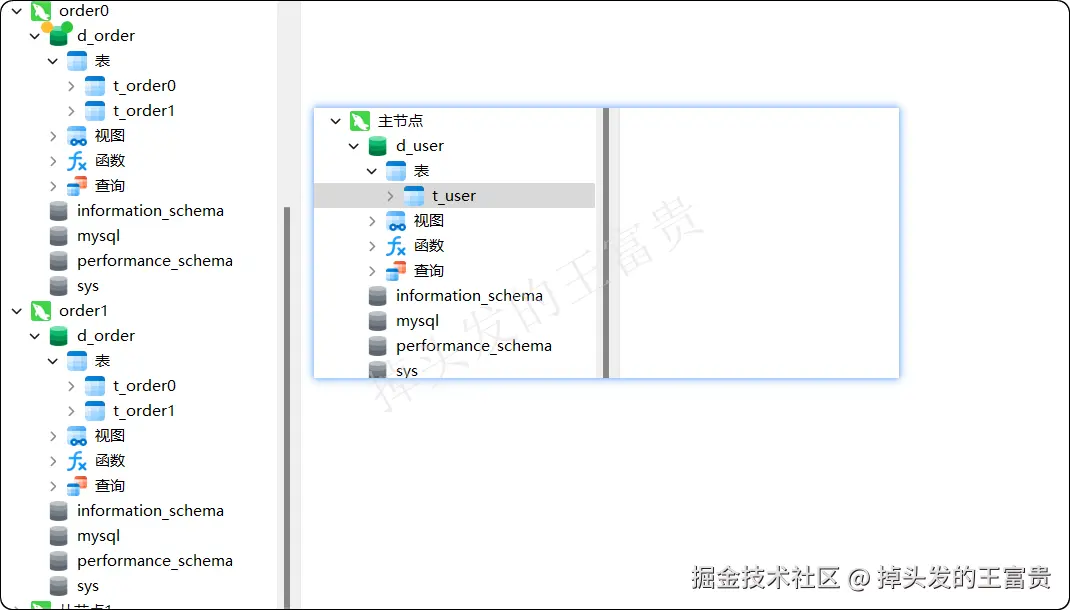
这样是不是就很清晰明了了,创建之后我们用Navicat连接一下就是这样式的:
第三步,编写实体类
注意这里不能用自增的id了,因为水平分片的原因使用自增id会出现id冲突的问题,就会出现四个订单id都为1的情况,所以这里我们使用 IdType.ASSIGN_ID
java
package com.masiyi.shardingsphere.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.math.BigDecimal;
/**
*
* @TableName t_order
*/
@TableName(value ="t_order")
@Data
public class Order {
/**
* 主键
*/
@TableId(value = "f_id", type = IdType.ASSIGN_ID)
private Long id;
/**
* 订单号
*/
@TableField(value = "f_order_no")
private String orderNo;
/**
* 用户id
*/
@TableField(value = "f_user_id")
private Long userId;
/**
* 数量
*/
@TableField(value = "f_amount")
private BigDecimal amount;
}
java
package com.masiyi.shardingsphere.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
*
* @TableName t_user
*/
@TableName(value ="t_user")
@Data
public class User {
/**
* 主键
*/
@TableId(value = "f_id", type = IdType.AUTO)
private Long id;
/**
* 名字
*/
@TableField(value = "f_uname")
private String uname;
}第四步,编写Mapper
java
package com.masiyi.shardingsphere.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.masiyi.shardingsphere.entity.Order;
import com.masiyi.shardingsphere.entity.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}
java
package com.masiyi.shardingsphere.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.masiyi.shardingsphere.entity.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserMapper extends BaseMapper<User> {
}第五步,编写配置文件
配置数据源
这块就和我们上一篇一样,没什么好讲的,注意填写你自己的数据源地址
properties
#========================数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order0,order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://127.0.0.1:13306/d_user
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order0.jdbc-url=jdbc:mysql://127.0.0.1:13308/d_order
spring.shardingsphere.datasource.order0.username=root
spring.shardingsphere.datasource.order0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order1.jdbc-url=jdbc:mysql://127.0.0.1:13309/d_order
spring.shardingsphere.datasource.order1.username=root
spring.shardingsphere.datasource.order1.password=123456标准分片表配置
properties
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。可以写成这样:order$->{0..1}.t_order$->{0..1}
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order0.t_order0,order0.t_order1,order1.t_order0,order1.t_order1这里也是和我们上篇是一样的,告诉框架,两张表对应的数据库和具体的数据表。但是大家仔细看t_order 对应的值就特别多,这个时候我们可以使用inline表达式写成这样的:
properties
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order$->{0..1}水平分库
这里我们先演示水平分库,即两个库里面各只有一张表,所以我们需要改一下上面的inline表达式变成这样的:
properties
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order0分库策略
properties
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=f_user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=wfg_inline_userid这里就告诉框架,使用 f_user_id这个字段作为分库依据,而下面我们使用了一个算法,算法名称是我们自己起名的,对得上下面的算法就行了:
分片算法配置
properties
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.props.algorithm-expression=order$->{f_user_id % 2}类型:INLINE 行表达式分片算法
使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。 对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的 Java 代码开发,如: t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为 t_user_0 到 t_user_7。 详情请参见行表达式。
因为我们上面修改成只有两张表,所以我们使用 order$->{f_user_id % 2} 这个表达式告诉框架。
所以我们现在目前的properties是这样的:
properties
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#========================数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order0,order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://127.0.0.1:13306/d_user
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order0.jdbc-url=jdbc:mysql://127.0.0.1:13308/d_order
spring.shardingsphere.datasource.order0.username=root
spring.shardingsphere.datasource.order0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order1.jdbc-url=jdbc:mysql://127.0.0.1:13309/d_order
spring.shardingsphere.datasource.order1.username=root
spring.shardingsphere.datasource.order1.password=123456
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。可以写成这样:order$->{0..1}.t_order$->{0..1}
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
#spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order0.t_order0,order0.t_order1,order1.t_order0,order1.t_order1
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order0
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=f_user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=wfg_inline_userid
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.props.algorithm-expression=order$->{f_user_id % 2}编写controller类测试
java
/**
* 水平分片:插入数据测试
*/
@PostMapping("insert/database")
public void testInsertOrderDatabaseStrategy(){
for (long i = 0; i < 4; i++) {
Order order = new Order();
order.setOrderNo("2025120488992");
order.setUserId(i + 1);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
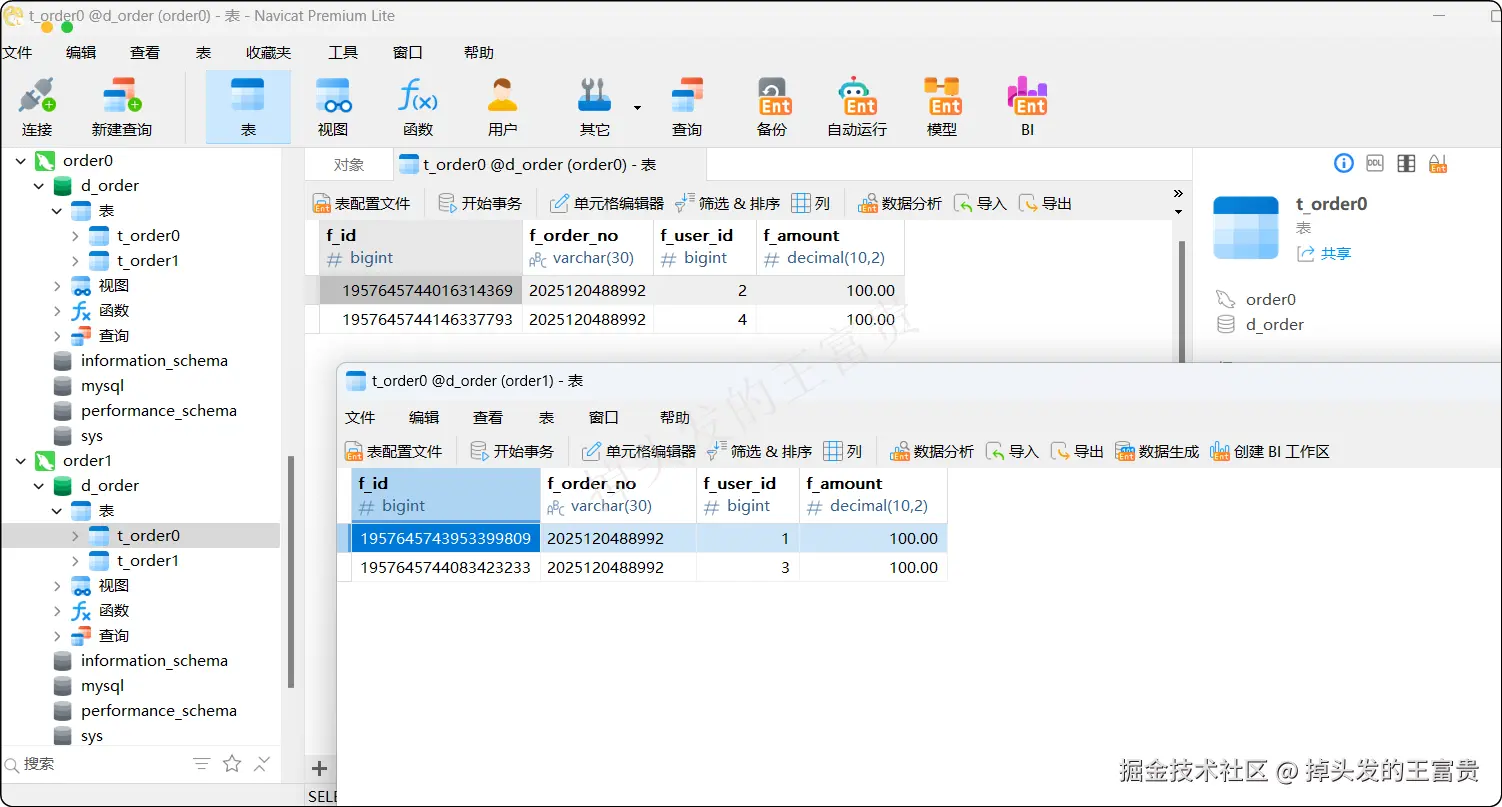
}这个时候因为userId会有四个值:1,2,3,4 。所以最终会被分配到两个库中:
水平分表
我们在水平分表的时候顺便也是做了分库,所以我们直接来做分库分表,我们把之前的配置写成这样:
properties
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。可以写成这样:order$->{0..1}.t_order$->{0..1}
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
#spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order0.t_order0,order0.t_order1,order1.t_order0,order1.t_order1
#spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order0
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order$->{0..1}分表策略
这里的配置我们分别配置了如何分库,分库的算法,如何分表,分表的算法,就像这样:
properties
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=f_user_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=f_order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=wfg_inline_userid
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=wfg_mod分片算法配置
properties
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.props.algorithm-expression=order$->{f_user_id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.props.sharding-count=2这里其实很好理解:我们分库的字段为f_user_id ,算法是行表达式分片算法 。分表的字段是f_order_no ,算法是 哈希取模分片算法 这个里面我们配置了 sharding-count 等于2,也就是说框架会根据f_order_no的hash值取模:
properties
System.out.println("wangfugui1".hashCode() % 2);然后平均分配到2个表中,所以这里如果我们为3,则对3取模,很好理解吧。
所以这里我们最终的properties文件长这样:
properties
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#========================数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order0,order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://127.0.0.1:13306/d_user
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order0.jdbc-url=jdbc:mysql://127.0.0.1:13308/d_order
spring.shardingsphere.datasource.order0.username=root
spring.shardingsphere.datasource.order0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order1.jdbc-url=jdbc:mysql://127.0.0.1:13309/d_order
spring.shardingsphere.datasource.order1.username=root
spring.shardingsphere.datasource.order1.password=123456
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。可以写成这样:order$->{0..1}.t_order$->{0..1}
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
#spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order0.t_order0,order0.t_order1,order1.t_order0,order1.t_order1
#spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order0
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order$->{0..1}
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=f_user_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=f_order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=wfg_inline_userid
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=wfg_mod
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.props.algorithm-expression=order$->{f_user_id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.props.sharding-count=2编写controller类测试
java
/**
* 水平分片:分表插入数据测试
*/
@PostMapping("insert/table")
public void testInsertOrderTableStrategy(){
for (long i = 1; i < 5; i++) {
Order order = new Order();
order.setOrderNo("wangfugui" + i);
order.setUserId(1L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
for (long i = 5; i < 9; i++) {
Order order = new Order();
order.setOrderNo("wangfugui" + i);
order.setUserId(2L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
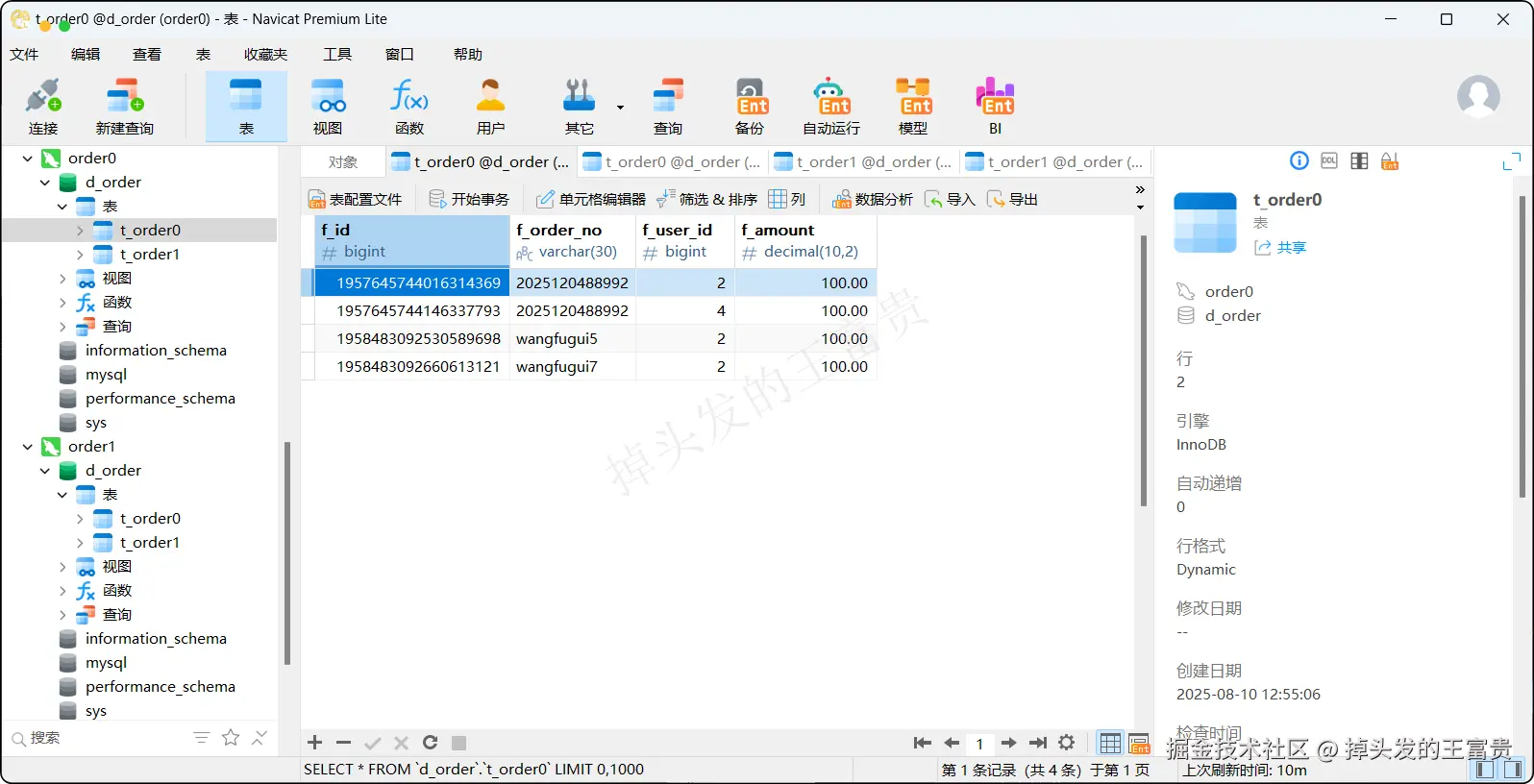
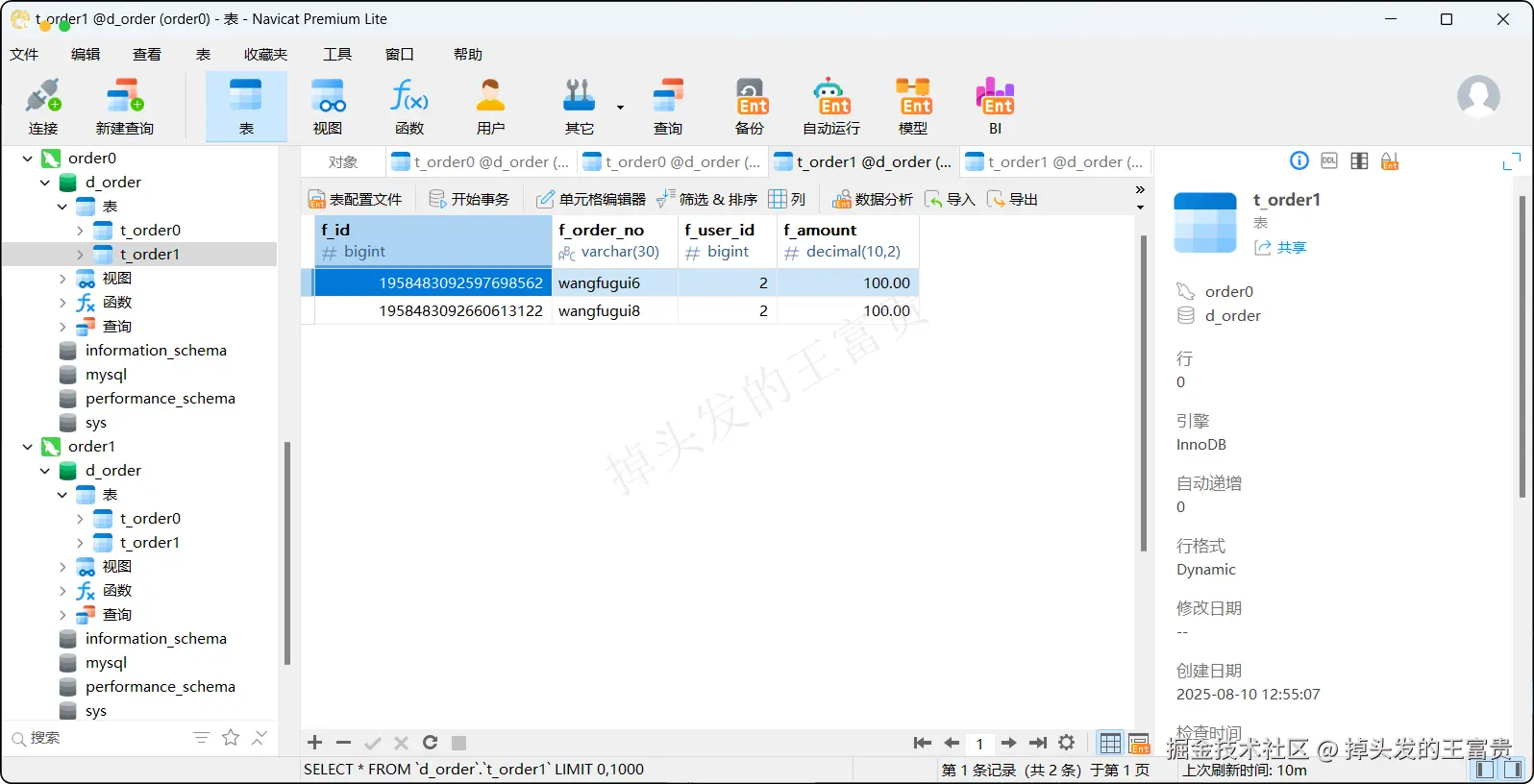
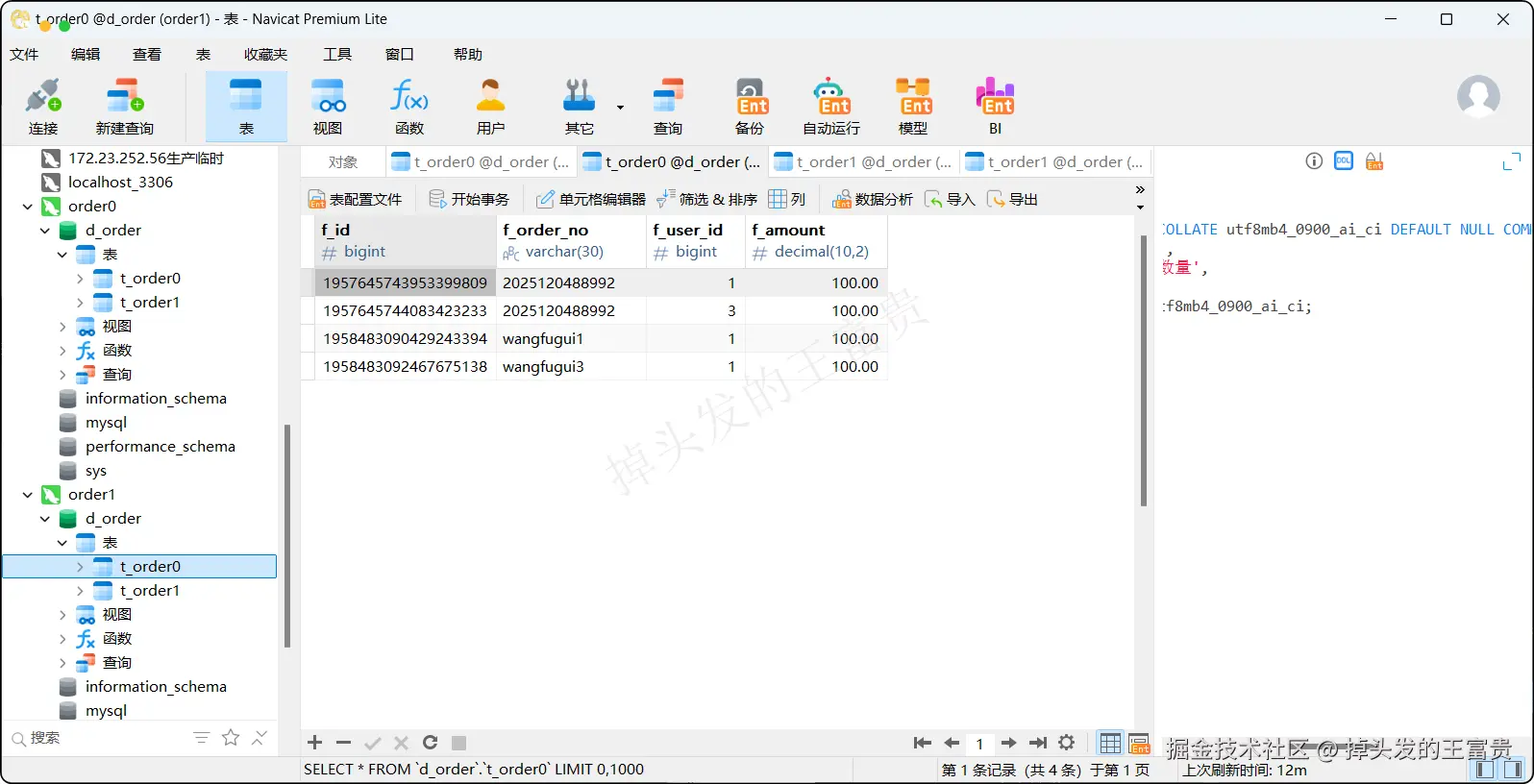
}那么执行之后我们再次查看我们的数据:
order0.t_order0
order0.t_order1
order1.t_order0
order1.t_order1
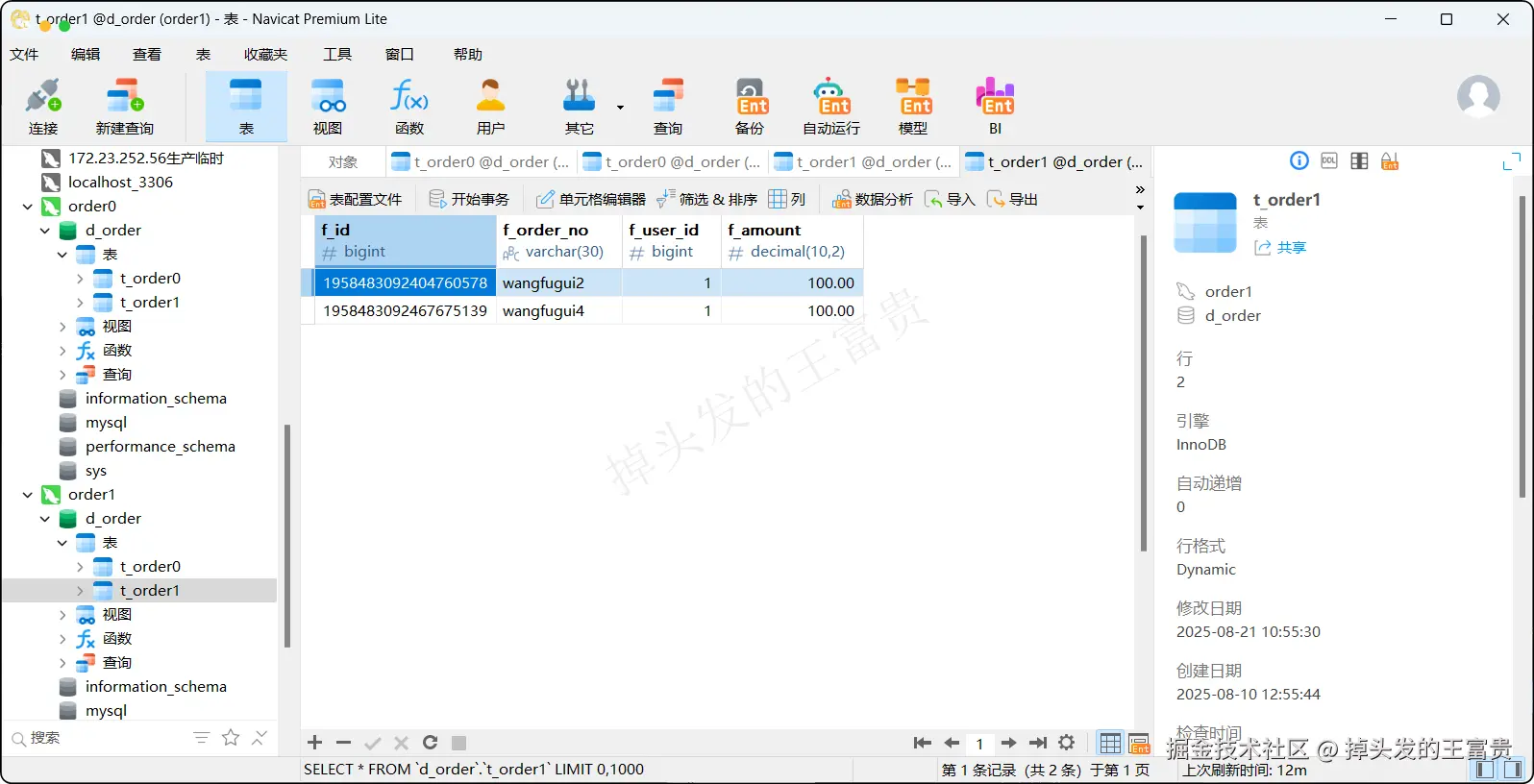
可以看到8条数据完美得插入到了我们的数据库中,而我们的sql就是正常编写,这些分库分表的操作:哪个数据落哪个库,落哪个表,ShardingSphere-JDBC已经帮我们完美得解决了。
多表操作
上面我们做的操作都是针对于单表操作的,所以这里我们来试一下多表的插入和查询
第一步,搭建环境
数据库还是用我们上面水平分表中的两个数据库,我们需要在order0和order1中都插入这两张表,这里面也添加了f_user_id和f_order_no用于和t_user和t_order表做绑定关系
java
CREATE TABLE `t_order_item0` (
`f_id` bigint NOT NULL,
`f_order_no` varchar(30) DEFAULT NULL,
`f_user_id` bigint DEFAULT NULL,
`f_price` decimal(10,2) DEFAULT NULL,
`f_count` int DEFAULT NULL,
PRIMARY KEY (`f_id`)
);
CREATE TABLE `t_order_item1` (
`f_id` bigint NOT NULL,
`f_order_no` varchar(30) DEFAULT NULL,
`f_user_id` bigint DEFAULT NULL,
`f_price` decimal(10,2) DEFAULT NULL,
`f_count` int DEFAULT NULL,
PRIMARY KEY (`f_id`)
);第二步,编写实体类
这里和上面不同的是我们的type需要用到了IdType.AUTO,这样当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
java
package com.masiyi.shardingsphere.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import java.math.BigDecimal;
import lombok.Data;
/**
*
* @TableName t_order_item0
*/
@TableName(value ="t_order_item")
@Data
public class OrderItem {
/**
*
*/
@TableId(value = "f_id",type = IdType.AUTO)
private Long id;
/**
*
*/
@TableField(value = "f_order_no")
private String orderNo;
/**
*
*/
@TableField(value = "f_user_id")
private Long userId;
/**
*
*/
@TableField(value = "f_price")
private BigDecimal price;
/**
*
*/
@TableField(value = "f_count")
private Integer count;
}第三步,编写Mapper
java
package com.masiyi.shardingsphere.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.masiyi.shardingsphere.entity.Order;
import com.masiyi.shardingsphere.entity.User;
import com.masiyi.shardingsphere.vo.OrderVo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
@Select({"SELECT o.f_order_no AS orderNo, SUM(i.f_price * i.f_count) AS amount",
"FROM t_order o JOIN t_order_item i ON o.f_order_no = i.f_order_no",
"GROUP BY o.f_order_no"})
List<OrderVo> getOrderAmount();
}第四步,编写配置文件
基础配置和我们上面的没什么两样,不一样的配置如下:
配置了一个新表 t_order_item
properties
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=order$->{0..1}.t_order_item$->{0..1}配置了新表的分库和分表依赖的字段和算法(注意这里两个关联的表使用相同的分片键和分片策略。例如,如果 t_order 按 order_id 分片,t_order_item 也应按 order_id 分片):
properties
#------------------------分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=f_user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=wfg_mod
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=f_user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=wfg_mod
#------------------------分表策略
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=f_order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=wfg_hash_mod
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=f_order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=wfg_hash_mod配置分库分表的算法:
properties
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.props.algorithm-expression=order$->{f_user_id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.type=MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.props.sharding-count=2
# 哈希取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_hash_mod.props.sharding-count=2配置分布式序列策略配置,即我们f_id的生成规则:
properties
#------------------------分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=f_id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=wfg_snowflake
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=f_id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=wfg_snowflake
#------------------------分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.wfg_snowflake.type=SNOWFLAKE
# 分布式序列算法属性配置
#spring.shardingsphere.rules.sharding.key-generators.wfg_snowflake.props.xxx=最后将我们的订单表和订单子表绑定到一起:
properties
#------------------------绑定表配置
# 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item配置完绑定表后再次进行关联查询的测试:
-
**如果不配置绑定表:测试的结果为8个SQL。**多表关联查询会出现笛卡尔积关联。
-
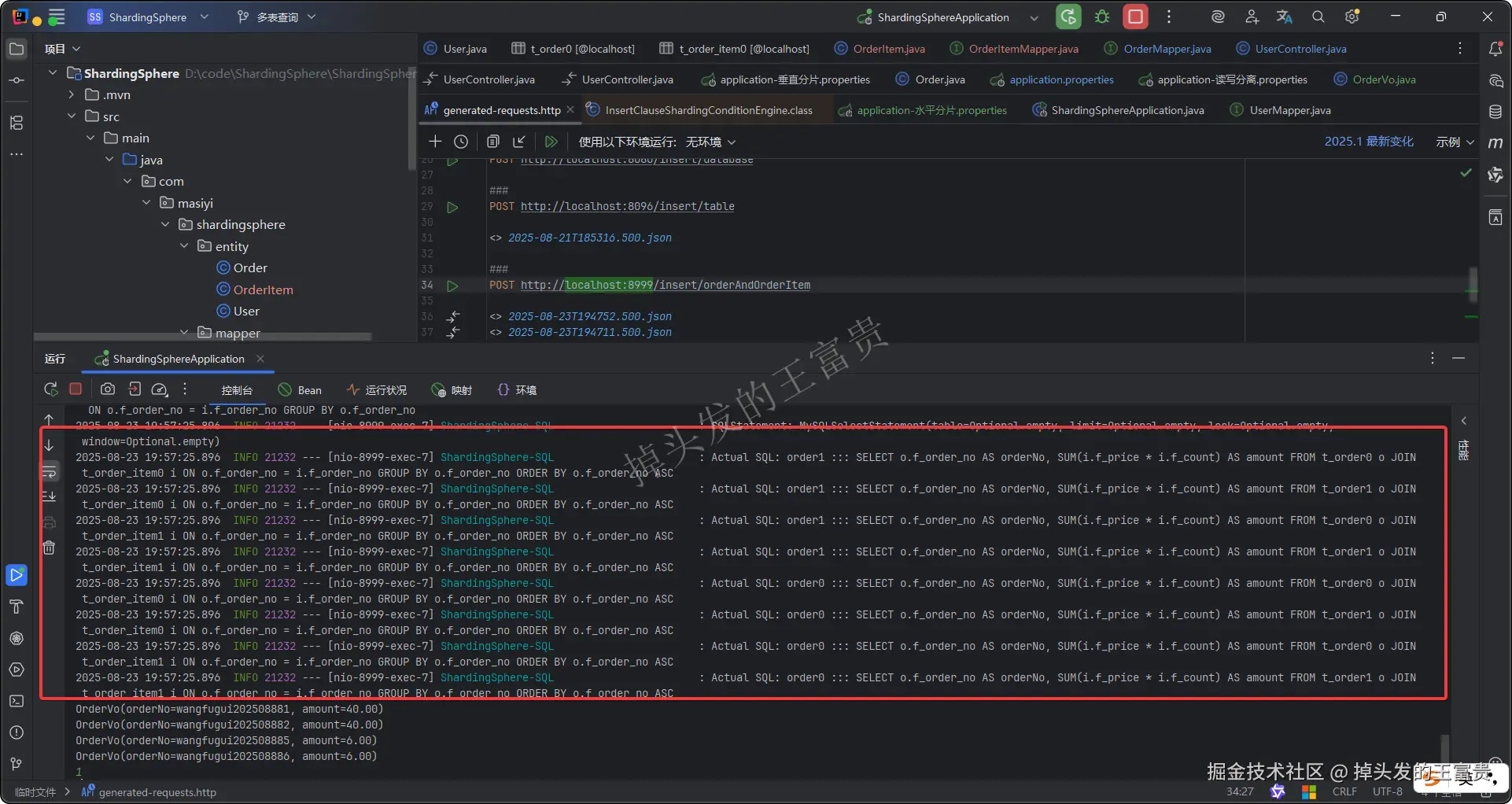
-
如果配置绑定表:测试的结果为4个SQL。 多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
-
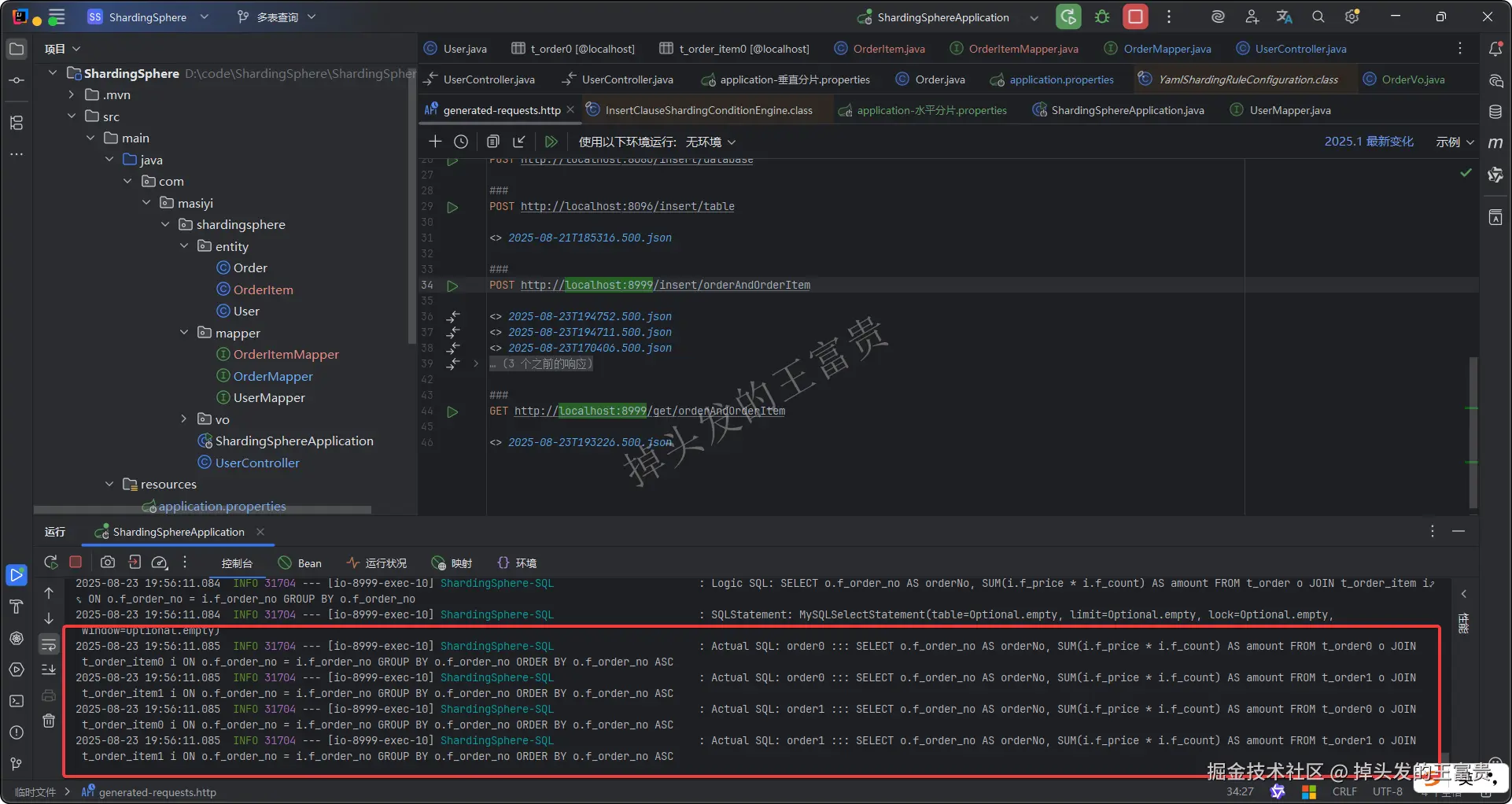
第五步,编写controller类测试
java
/**
* 测试关联表插入
*/
@PostMapping("insert/orderAndOrderItem")
public void testInsertOrderAndOrderItem(){
for (long i = 1; i < 3; i++) {
Order order = new Order();
order.setOrderNo("wangfugui20250888" + i);
order.setUserId(1L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("wangfugui20250888" + i);
orderItem.setUserId(1L);
orderItem.setPrice(new BigDecimal(10));
orderItem.setCount(2);
orderItemMapper.insert(orderItem);
}
}
for (long i = 5; i < 7; i++) {
Order order = new Order();
order.setOrderNo("wangfugui20250888" + i);
order.setUserId(2L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("wangfugui20250888" + i);
orderItem.setUserId(2L);
orderItem.setPrice(new BigDecimal(1));
orderItem.setCount(3);
orderItemMapper.insert(orderItem);
}
}
}
/**
* 测试关联表查询
*/
@GetMapping("get/orderAndOrderItem")
public void testGetOrderAmount(){
List<OrderVo> orderAmountList = orderMapper.getOrderAmount();
orderAmountList.forEach(System.out::println);
}我们执行插入之后可以看到每个表里面的情况:
t_order表
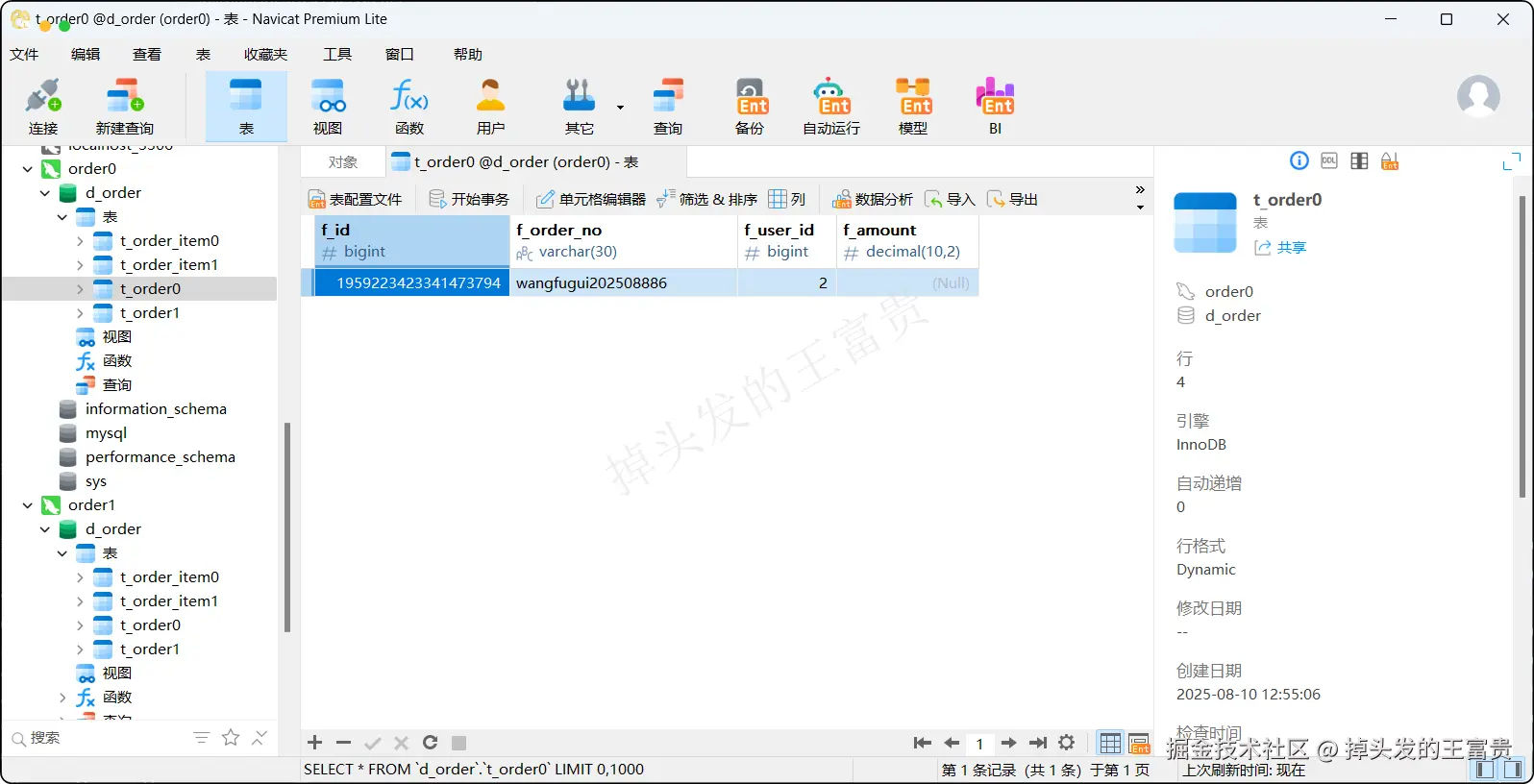
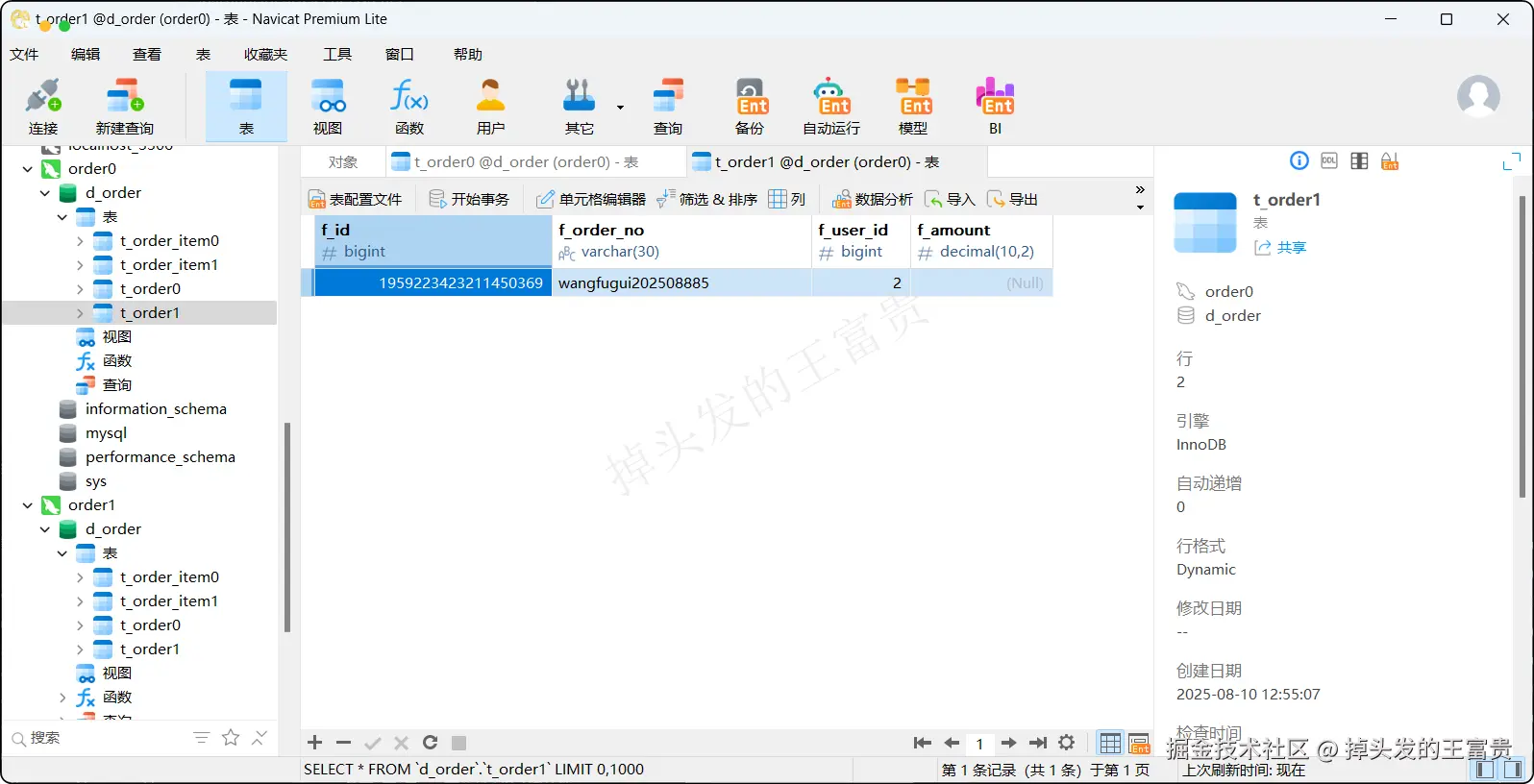
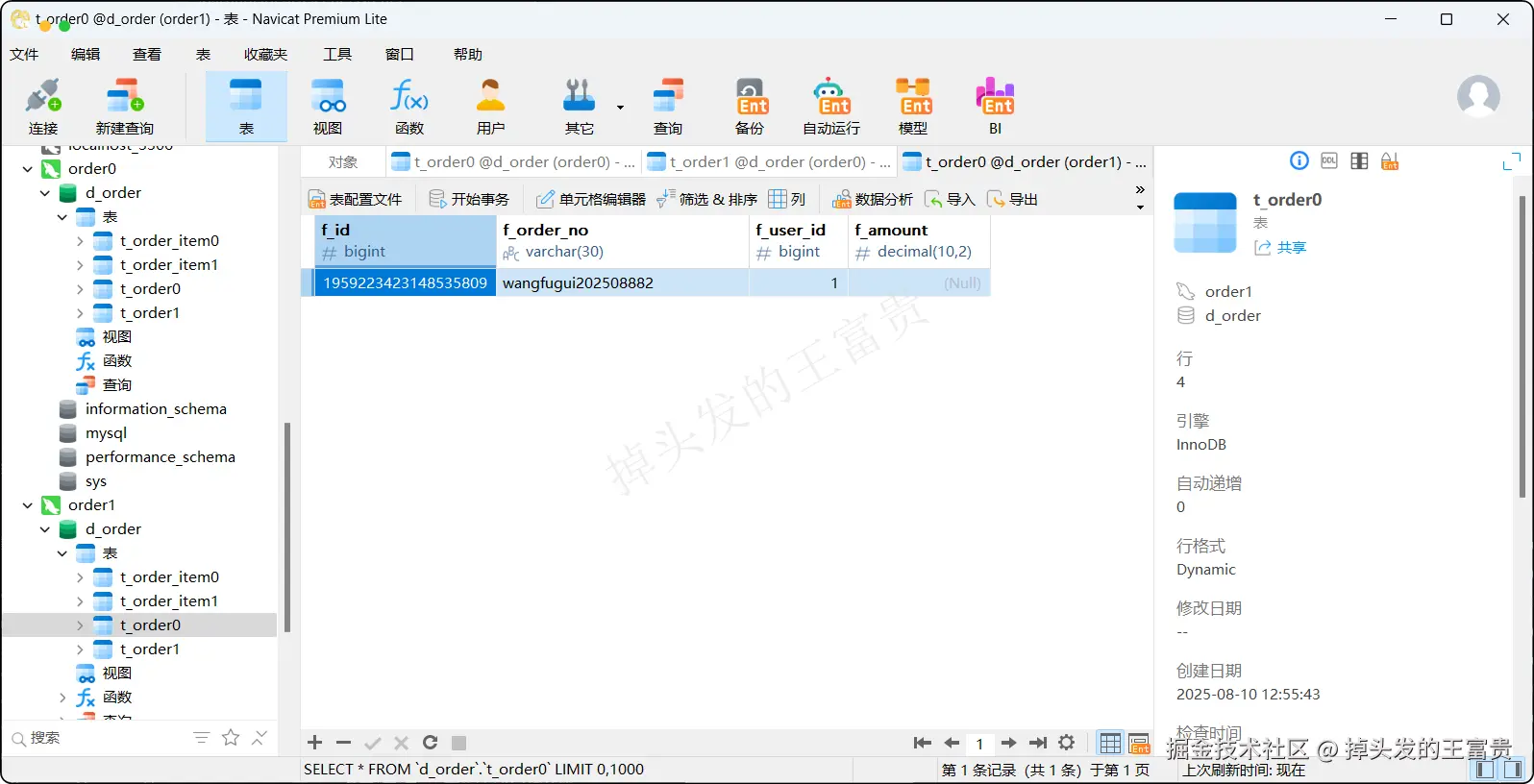
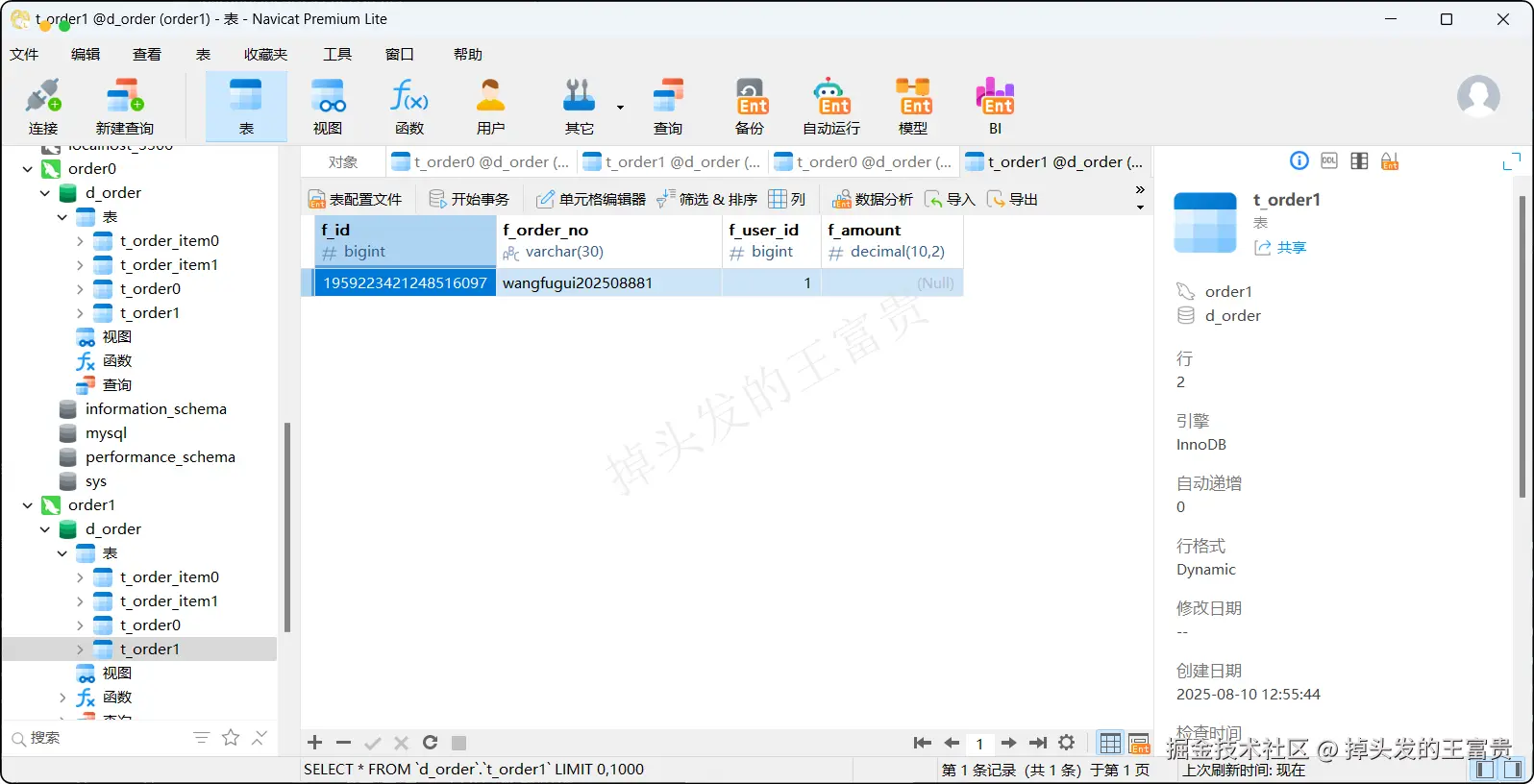
t_order_item表
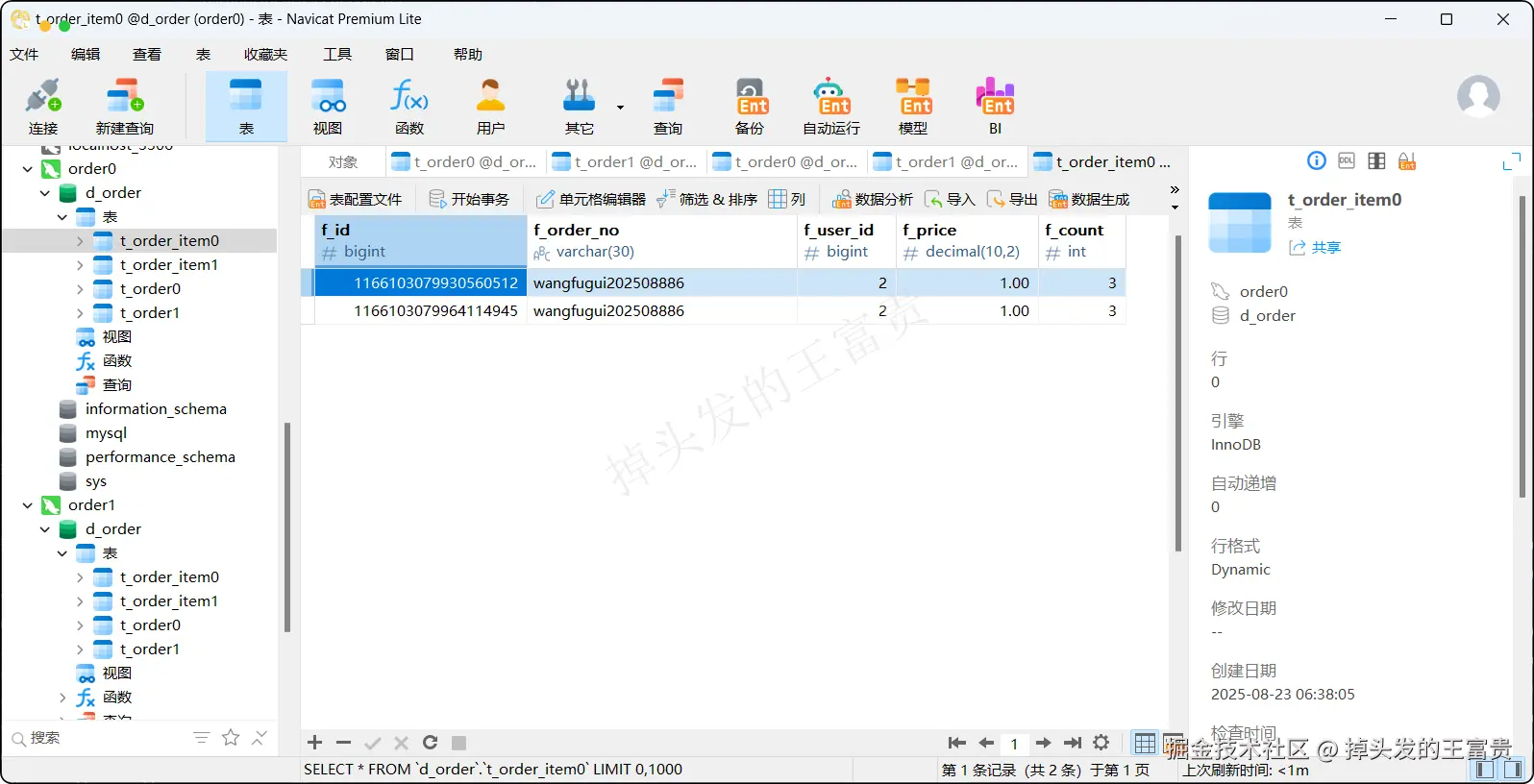
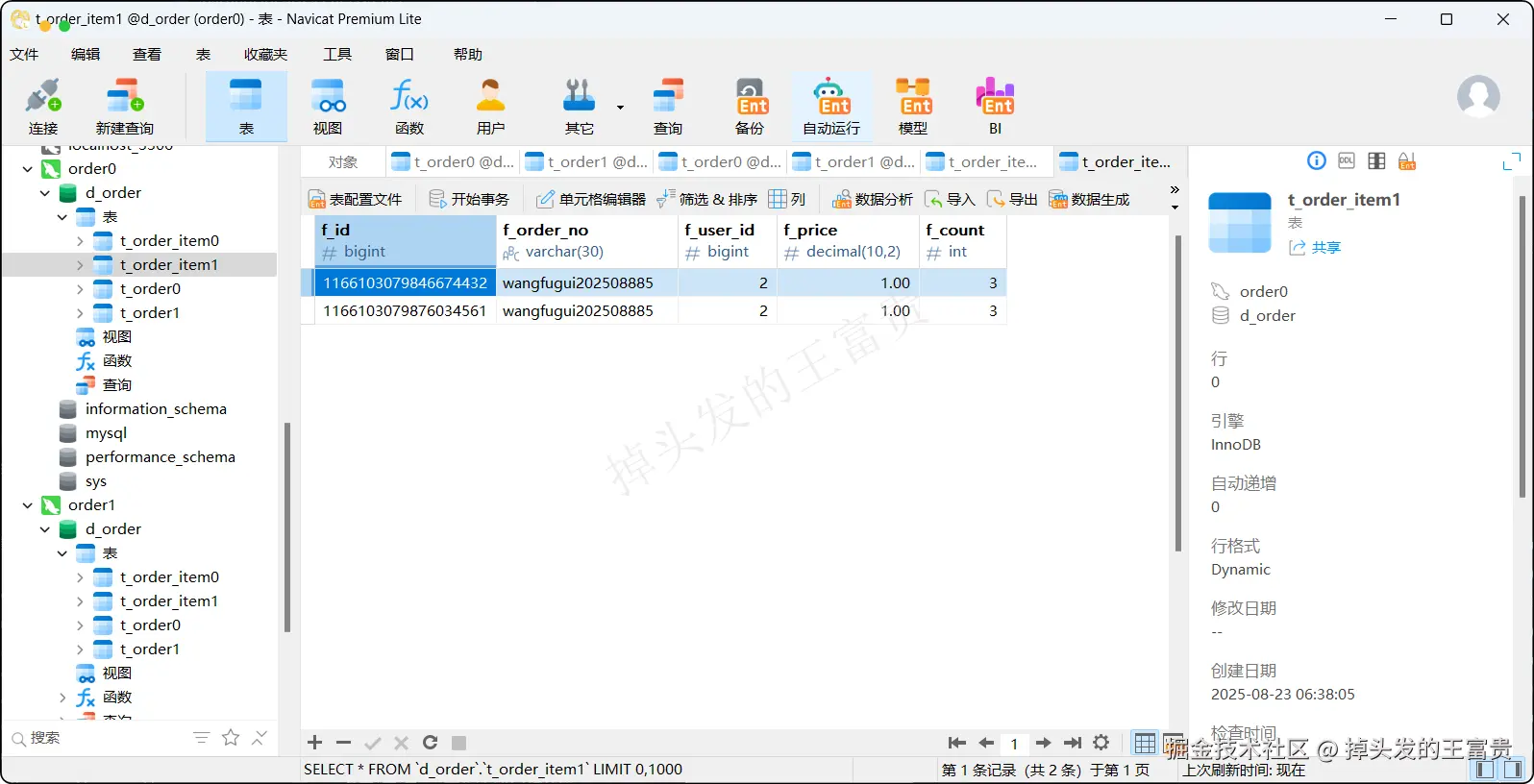
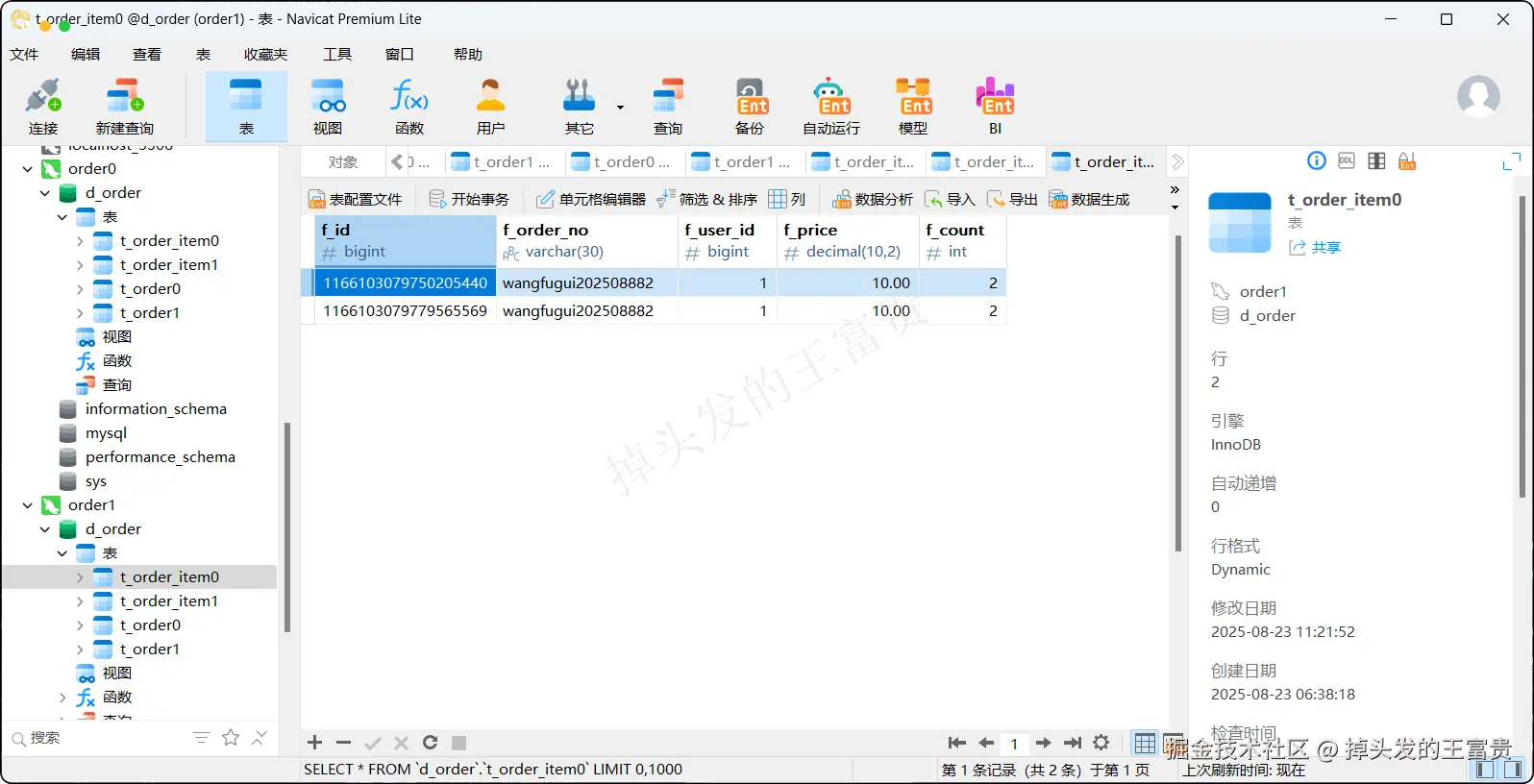
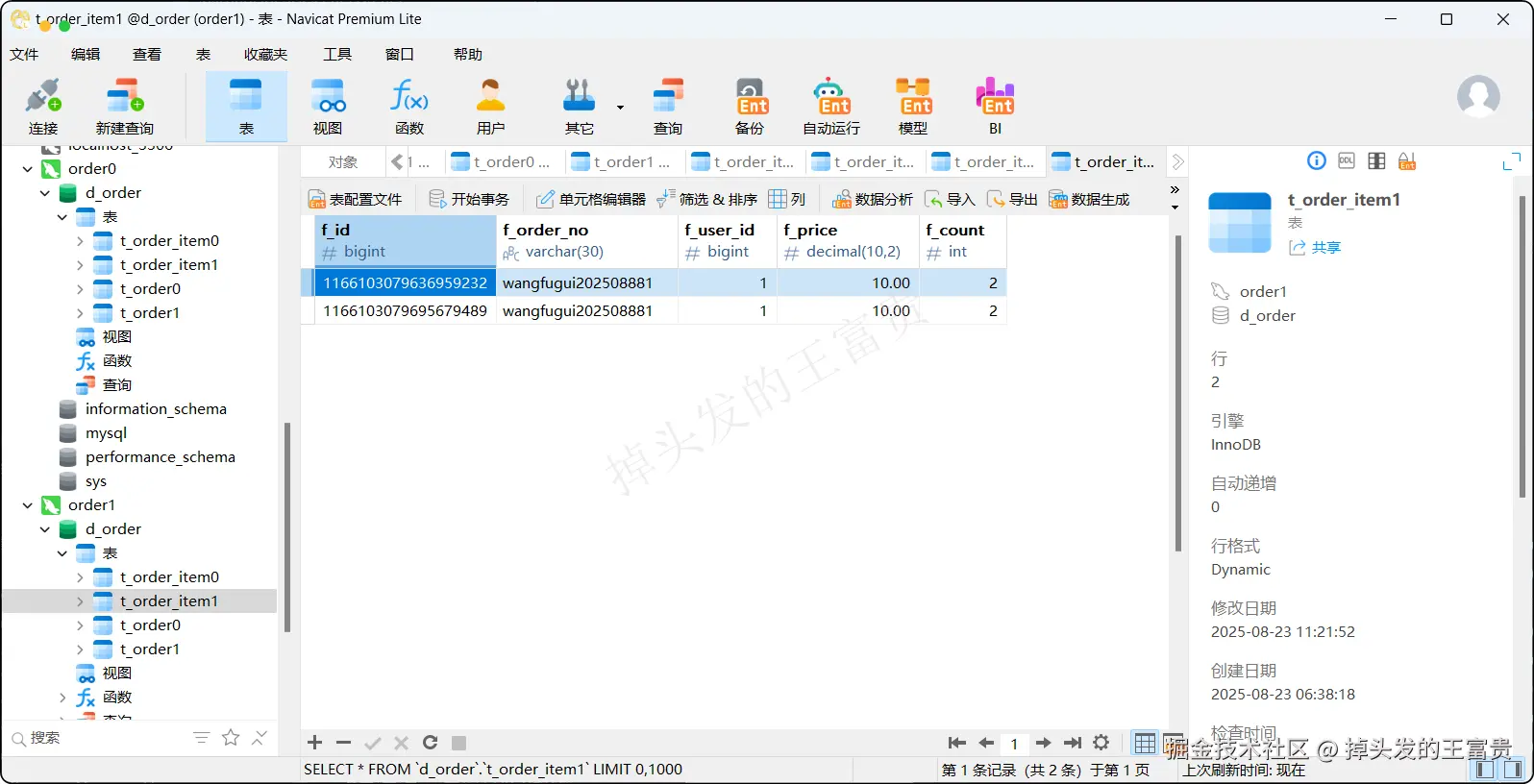
可以看到我们配置的相关算法都全部生效了,对应的表数据也成功插入进去了
那么我们执行查询关联表就可以看到对应的sql结果:
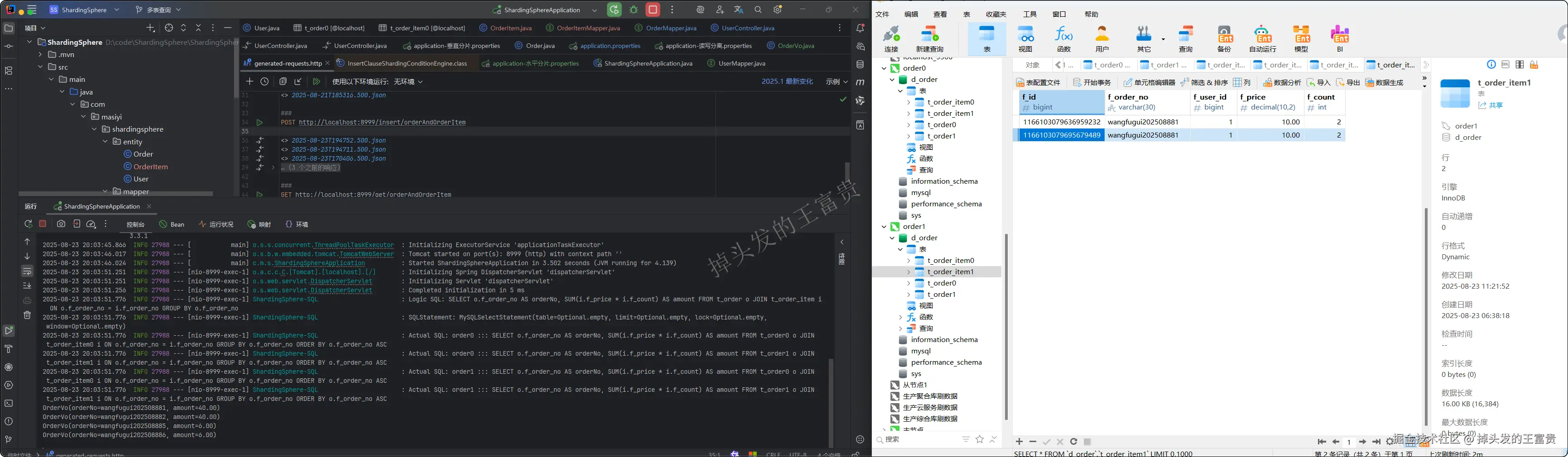
可以看到 wangfugui202508881的订单金额确实为 (2 * 10 + 2 * 10)= 40 。而我们配置的算法也保证了每个订单都分布在一个库或者表中,提升了我们的查询效率,这点可以在设计之初的时候就要注意好这一点。
那么最后我们的配置表就是长这样:
properties
#------------------------基本配置
# 应用名称
spring.application.name=sharging-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#------------------------数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order0,order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://127.0.0.1:13306/d_user
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order0.jdbc-url=jdbc:mysql://127.0.0.1:13308/d_order
spring.shardingsphere.datasource.order0.username=root
spring.shardingsphere.datasource.order0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order1.jdbc-url=jdbc:mysql://127.0.0.1:13309/d_order
spring.shardingsphere.datasource.order1.username=root
spring.shardingsphere.datasource.order1.password=123456
#------------------------标准分片表配置(数据节点配置)
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
# 缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
# order0.t_order0,order0.t_order1,order1.t_order0,order1.t_order1
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=order$->{0..1}.t_order_item$->{0..1}
#------------------------分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=f_user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=wfg_mod
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=f_user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=wfg_mod
#------------------------分表策略
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=f_order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=wfg_hash_mod
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=f_order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=wfg_hash_mod
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_inline_userid.props.algorithm-expression=order$->{f_user_id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.type=MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_mod.props.sharding-count=2
# 哈希取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.wfg_hash_mod.props.sharding-count=2
#------------------------分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=f_id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=wfg_snowflake
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=f_id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=wfg_snowflake
#------------------------分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.wfg_snowflake.type=SNOWFLAKE
# 分布式序列算法属性配置
#spring.shardingsphere.rules.sharding.key-generators.wfg_snowflake.props.xxx=
#------------------------绑定表配置
# 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item
server.port=8999以上就是本期教程的所有内容了,这里我们只注意了如何快速使用他,那么他里面的底层原理是怎么实现的呢,如何做到根据配置就可以达到只需要关注sql的编写就可以实现这种操作呢?这些如果大家感兴趣的话我们可以继续往下深挖。那么下期我们给大家带来ShardingSphere-Proxy的入门教程,欢迎大家关注!!
 参考资料:
参考资料: