在Redis的使用过程中,大Key问题可谓是"隐形杀手"------平时不声不响,一旦爆发就会引发连锁反应:响应变慢、连接超时、内存溢出,甚至导致主备切换。今天我们就来全面解析Redis大Key问题的排查与解决方案。

一、什么是Redis大Key?
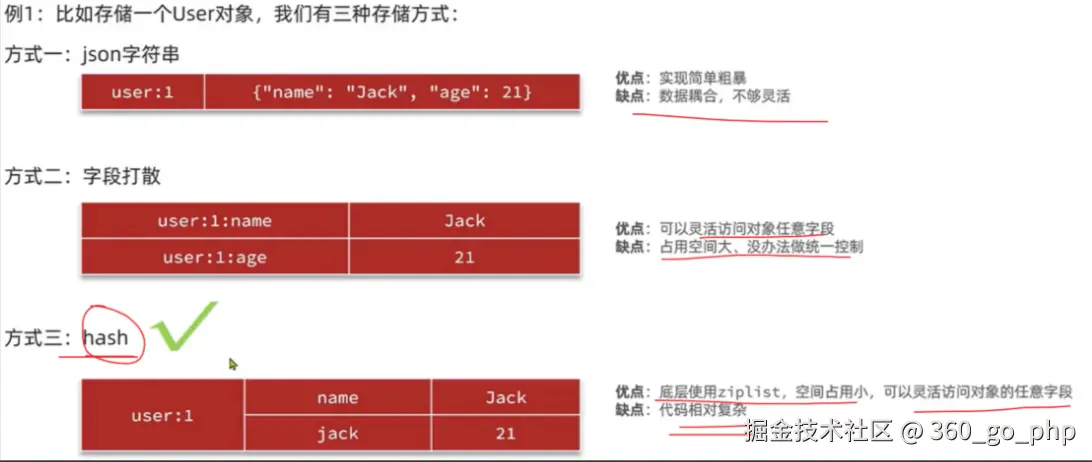
Redis大Key并不是指Key的名称很长,而是指该Key所对应的Value过大。根据不同数据类型,业界普遍采用以下阈值作为判断标准:

| 数据类型 | 大Key判断标准 | 说明 |
|---|---|---|
| String类型 | 值超过10KB | 单个字符串值过大 |
| Hash/List/Set/ZSet | 元素个数超过5000个 | 成员数量过多 |
| Hash格式 | 成员总Value超过10MB | 虽然成员数不多,但每个成员很大 |
 需要注意的是,不同云厂商的标准略有差异。例如,腾讯云将String类型的大Key阈值定为10MB ,而华为云和阿里云建议将String类型控制在10KB以内。在实际生产中,建议根据业务场景和实例规格灵活调整。
需要注意的是,不同云厂商的标准略有差异。例如,腾讯云将String类型的大Key阈值定为10MB ,而华为云和阿里云建议将String类型控制在10KB以内。在实际生产中,建议根据业务场景和实例规格灵活调整。
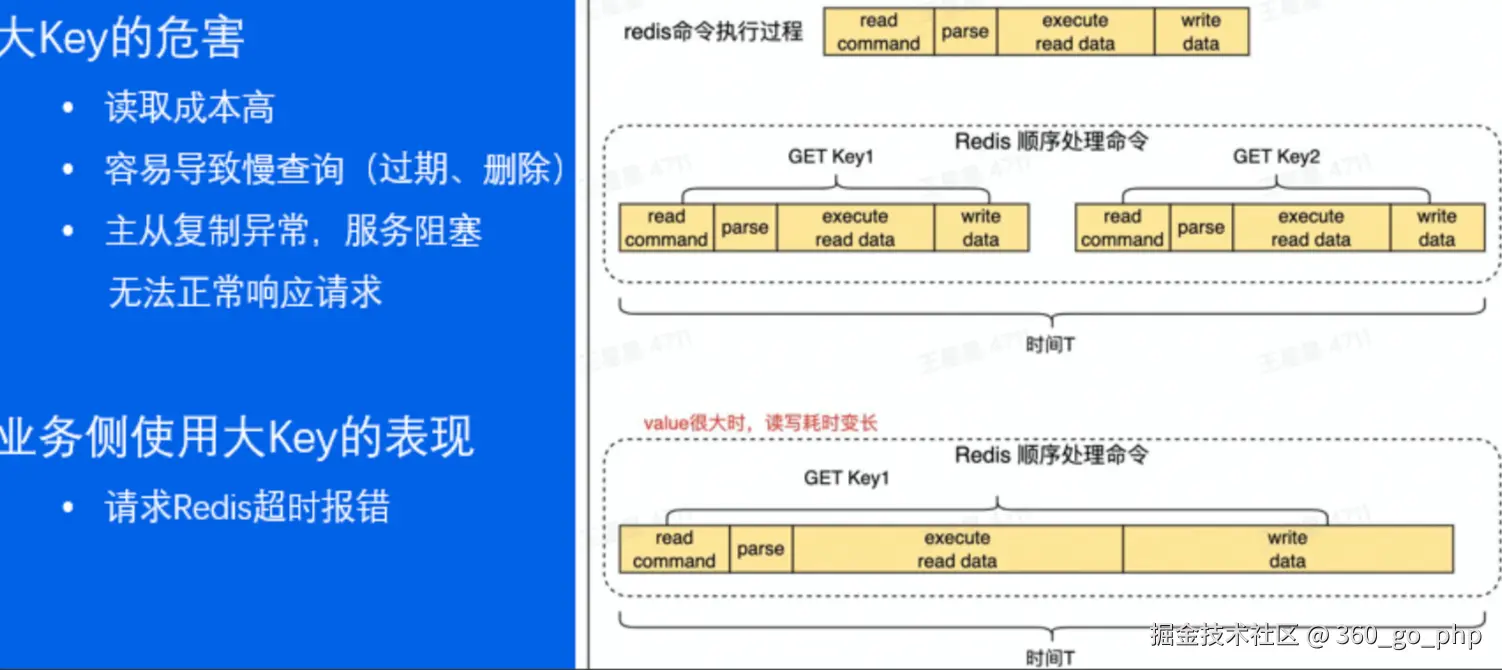
二、大Key带来的影响
 大Key对Redis的影响是多方面的,轻则性能下降,重则引发系统故障:
大Key对Redis的影响是多方面的,轻则性能下降,重则引发系统故障:
1. 内存压力与数据倾斜
 内存使用不均衡 :在集群架构中,某个数据分片的内存使用率远超其他分片,导致内存资源无法均衡。当实例内存达到
内存使用不均衡 :在集群架构中,某个数据分片的内存使用率远超其他分片,导致内存资源无法均衡。当实例内存达到maxmemory上限时,可能导致重要Key被逐出,甚至引发内存溢出(OOM)。
2. 性能问题
 请求响应时间上升 :Redis是单线程架构,操作大Key耗时较长。例如,对一个包含数万个元素的Hash执行
请求响应时间上升 :Redis是单线程架构,操作大Key耗时较长。例如,对一个包含数万个元素的Hash执行hgetall操作,会长时间阻塞Redis主线程,导致后续请求排队等待,整体服务性能下降。
3. 网络拥塞
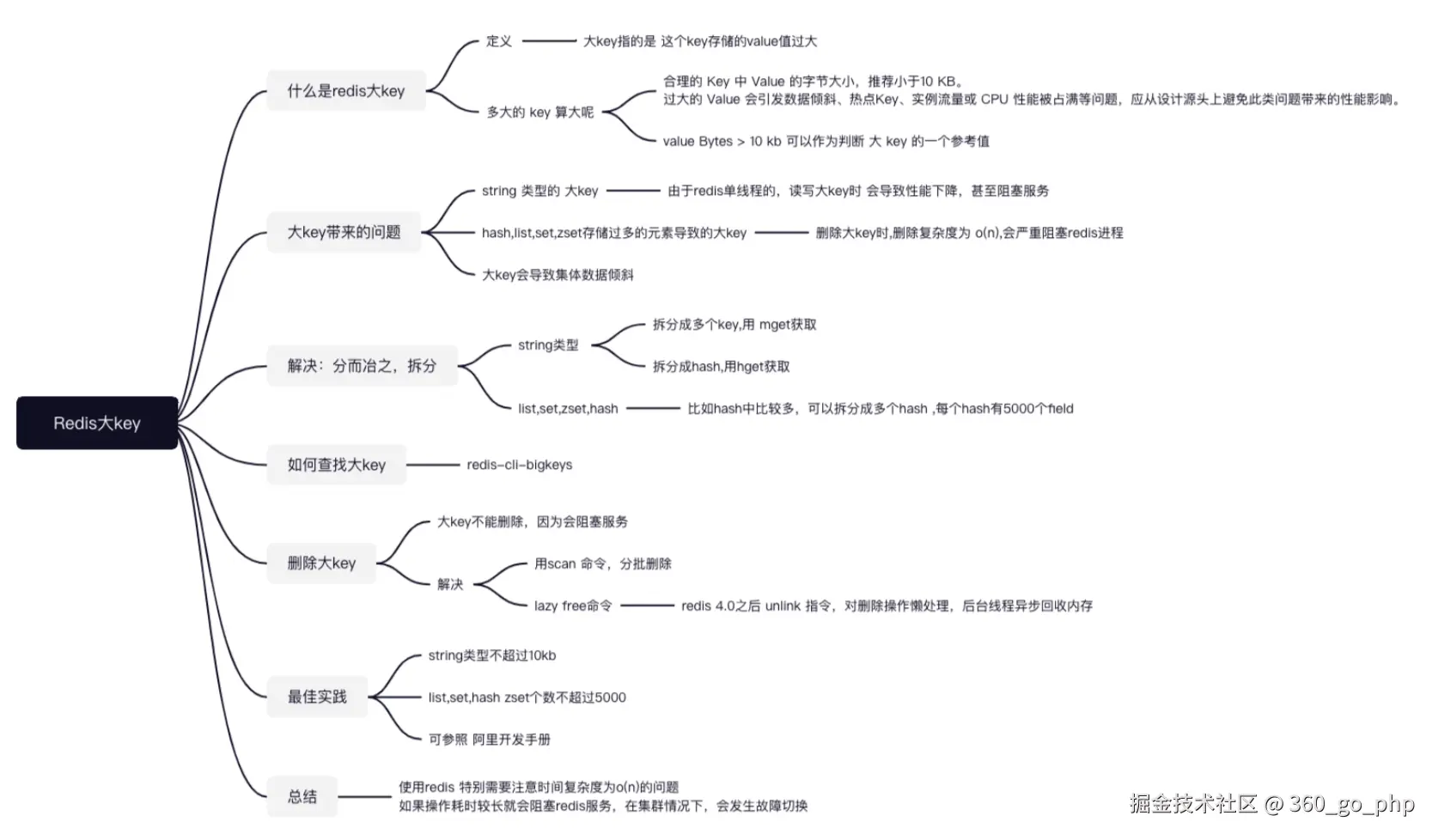 带宽被占满:假设一个大Key占用1MB空间,每秒访问1000次,就会产生1000MB的流量。这不仅可能导致实例的带宽被占满,还可能影响同网络内的其他服务。
带宽被占满:假设一个大Key占用1MB空间,每秒访问1000次,就会产生1000MB的流量。这不仅可能导致实例的带宽被占满,还可能影响同网络内的其他服务。
4. 主从同步风险
 同步中断或主备切换 :对大Key执行删除操作时,如果使用
同步中断或主备切换 :对大Key执行删除操作时,如果使用DEL命令,易造成主库长时间阻塞,进而可能引发主从同步中断或主备切换。
5. 持久化问题
 备份恢复耗时增加:使用RDB快照或AOF日志时,大Key会导致备份和恢复操作变得更为耗时,因为需要处理大量数据。
备份恢复耗时增加:使用RDB快照或AOF日志时,大Key会导致备份和恢复操作变得更为耗时,因为需要处理大量数据。
6. 慢查询问题
 慢查询日志堆积:对大Key的操作通常会花费更多时间,容易被记录到慢查询日志中,影响监控和分析。
慢查询日志堆积:对大Key的操作通常会花费更多时间,容易被记录到慢查询日志中,影响监控和分析。
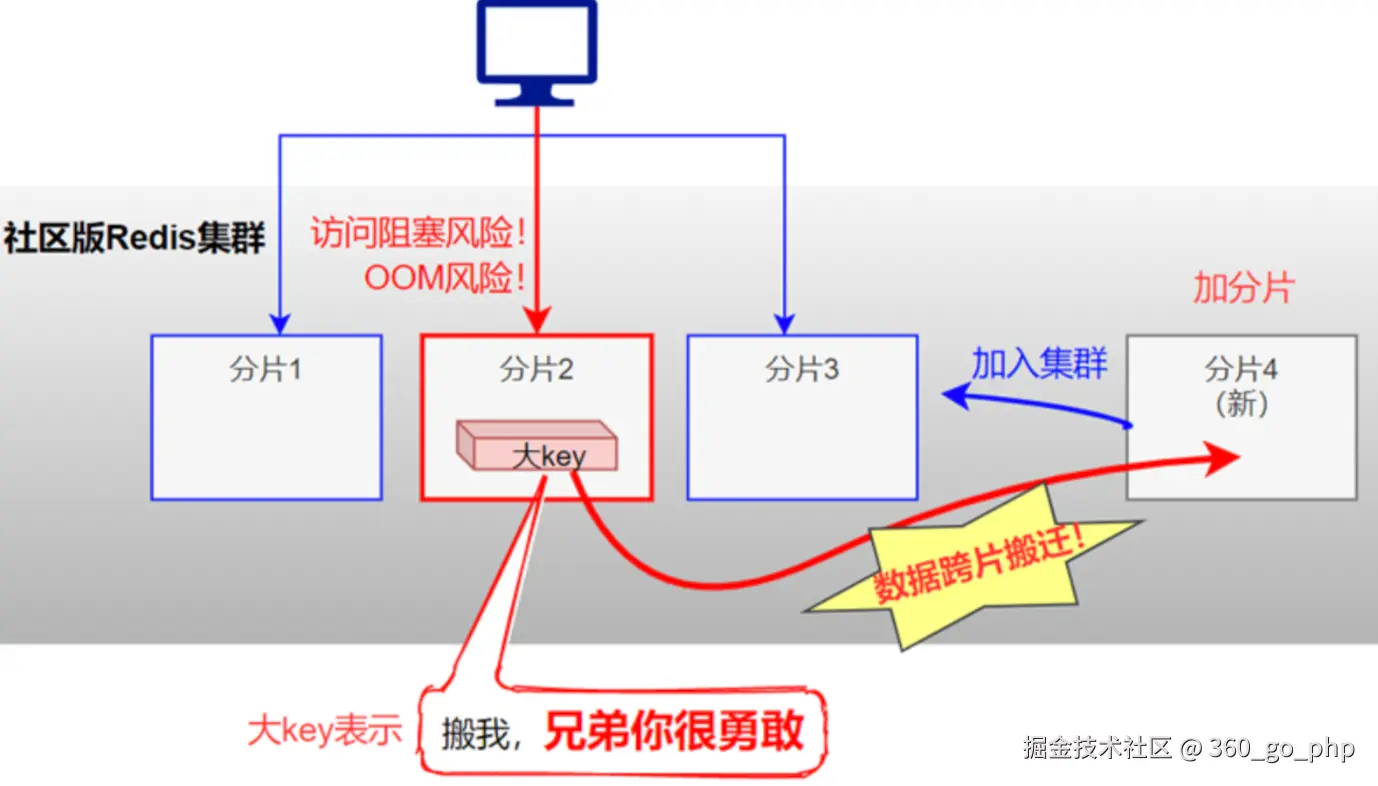
三、大Key产生的原因
大Key的产生往往是多种因素共同作用的结果:
| 原因类别 | 具体说明 |
|---|---|
| 业务规划不足 | 上线前没有对Key中的成员进行合理拆分,导致个别Key成员数量过多 |
| 数据模型设计不当 | 在不适用场景下使用Redis,如用String类型存放大体积二进制文件 |
| 未定期清理无效数据 | 如HASH类型Key中的成员持续增加,没有及时清理过期数据 |
| 消费侧故障 | 使用LIST类型的业务消费侧发生代码故障,导致成员只增不减 |
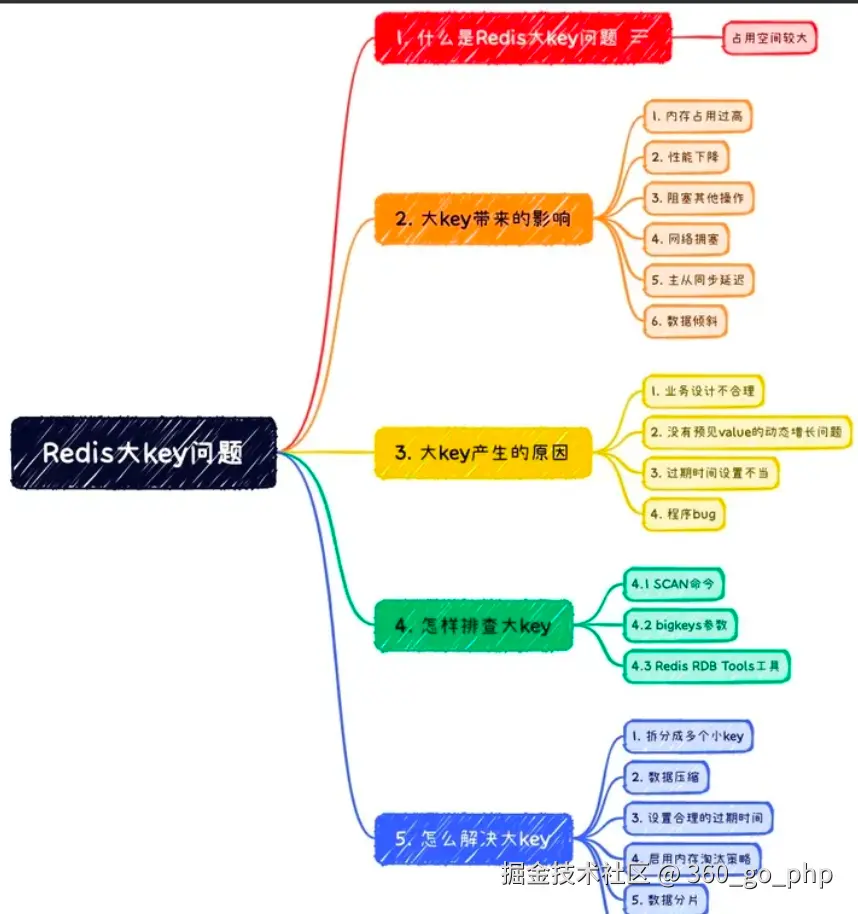
四、大Key的排查方法
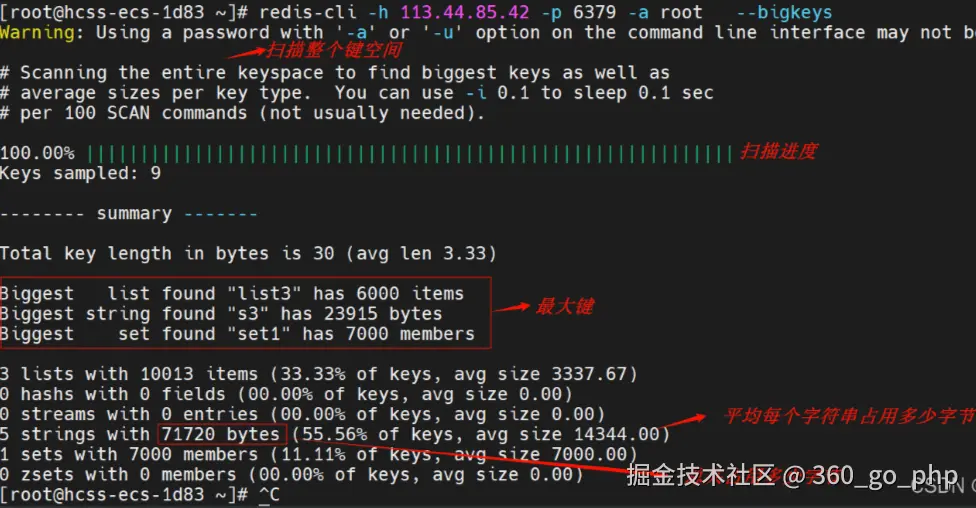
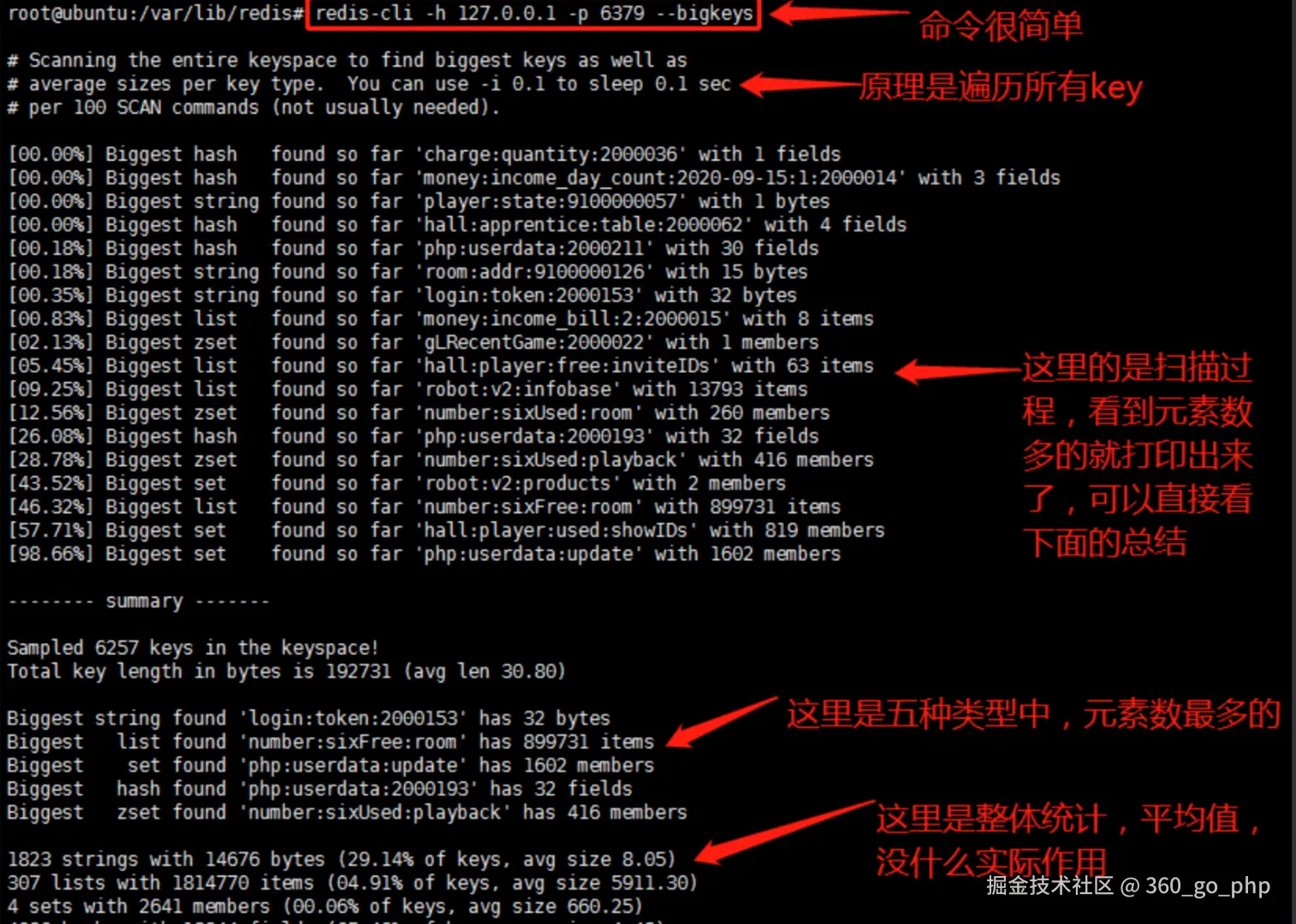
方法1:使用redis-cli --bigkeys(最常用)
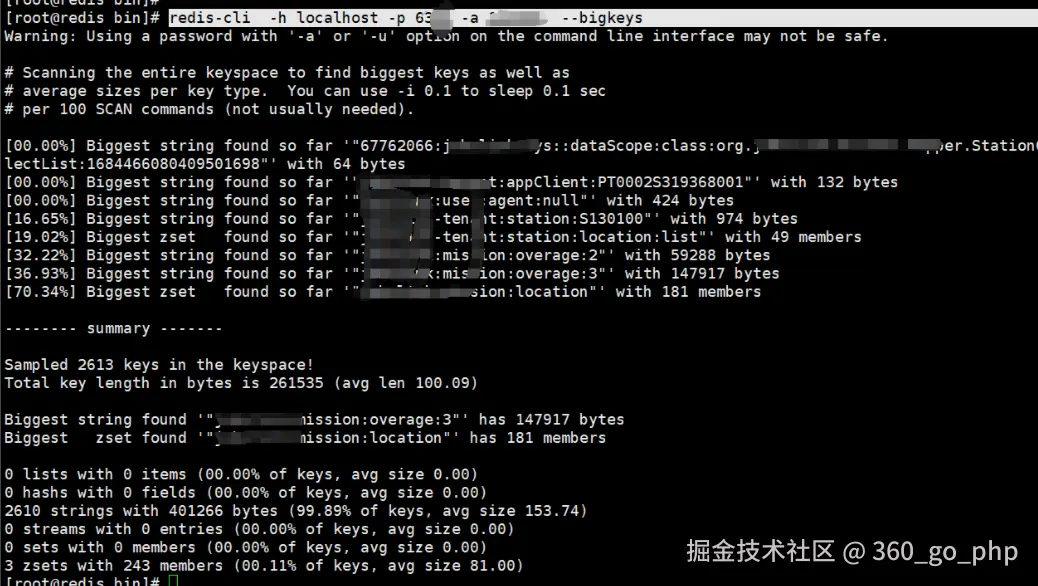 Redis-cli提供了
Redis-cli提供了--bigkeys参数,能够以遍历的方式分析Redis实例中的所有Key,并返回每种数据类型中Top1的大Key。
bash
# 基础用法
redis-cli -h <实例地址> -p <端口> -a <密码> --bigkeys
# 示例
redis-cli -h r-123456.redis.rds.aliyuncs.com -a yourpassword --bigkeys优点 :方便、快速、安全 缺点:
- 只能找出每种类型中最大的Key,无法获取所有大Key
- 需要遍历实例所有Key,可能影响实例性能
- 对于集合类型,返回的是元素个数,而非实际内存占用
方法2:使用SCAN命令自定义扫描(更灵活)
 通过
通过SCAN命令配合类型查询命令,可以自定义扫描逻辑,减小对Redis性能的影响。
bash
# 使用SCAN命令迭代所有键
redis-cli SCAN 0 COUNT 1000
# 对特定Key分析
# STRING类型:STRLEN key
# LIST类型:LLEN key
# HASH类型:HLEN key
# SET类型:SCARD key
# ZSET类型:ZCARD keyPython脚本示例:
python
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
keys = []
cursor = 0
count = 1000
while True:
cursor, key_data = r.scan(cursor, count=count)
keys.extend(key_data)
if cursor == 0:
break
for key in keys:
memory_usage = r.memory_usage(key)
if memory_usage > 10240: # 大于10KB
print(f"大Key:{key}, 内存占用:{memory_usage/1024:.2f}KB")方法3:使用redis-rdb-tools分析RDB文件(离线分析)
通过分析Redis的RDB快照文件,可以全面了解所有Key的内存占用情况,对线上服务零影响。
bash
# 安装
pip install rdbtools python-lzf
# 分析RDB文件,找出大于10KB的Key
rdb --command memory /path/to/dump.rdb --filter 'memory > 10240' --format csv --output big_keys.csv优点 :支持定制化分析,完全不影响线上服务 缺点:时效性差,RDB文件较大时耗时较长
方法4:使用云厂商控制台工具
各大云厂商都提供了便捷的大Key分析工具:
| 云厂商 | 工具名称 | 特点 |
|---|---|---|
| 腾讯云 | DBbrain | 实时诊断优化,大Key分析任务 |
| 阿里云 | Top Key统计 | 实时显示各数据类型Top3大Key |
| 华为云 | 大Key分析工具 | 通过DCS控制台操作 |
方法5:通过监控告警发现
配置节点级别的内存利用率监控告警。如果某个节点存在大Key,该节点的内存使用率会远高于其他节点,触发告警。
五、大Key的解决方案
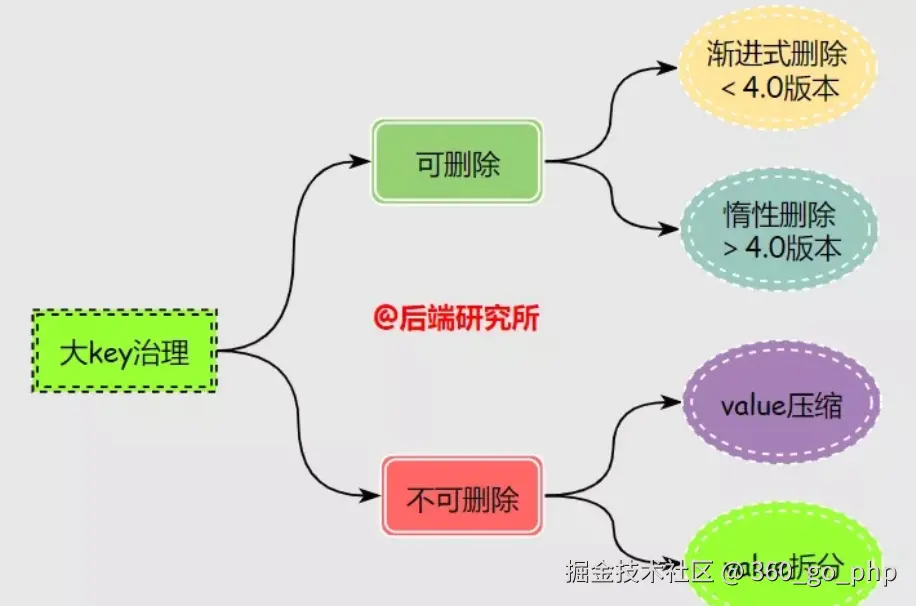
方案1:拆分大Key(最常用)
根据业务场景,将大Key拆分成多个小Key。
String类型拆分:
bash
# 原大Key
SET user:1001:profile "{大量JSON数据}"
# 拆分后
SET user:1001:profile:base "基本信息"
SET user:1001:profile:detail "详细信息"
SET user:1001:profile:extend "扩展信息"Hash类型拆分:在客户端定义一个分拆数量N,对field计算哈希值取模,确定该field落在哪个Key上。
python
# 拆分逻辑示例
N = 10 # 拆分成10个Key
field_hash = hash(field) % N
key = f"user:{user_id}:shard:{field_hash}"
hset(key, field, value)方案2:压缩大Key
对JSON、XML文本数据等可压缩数据,在序列化时启动压缩算法:
- 使用GZIP、Snappy等压缩算法
- 使用Protocol Buffers等二进制序列化协议
注意:压缩和解压缩会消耗额外的CPU资源,可能影响处理性能。
方案3:清理过期数据
对于大量过期数据堆积的场景,可以使用HSCAN命令配合HDEL命令对失效数据进行清理。
lua
-- Lua脚本示例:分批清理Hash中的过期字段
local cursor = '0'
repeat
local result = redis.call('HSCAN', KEYS[1], cursor, 'COUNT', 100)
cursor = result[1]
local fields = result[2]
for i = 1, #fields, 2 do
-- 判断字段是否过期(业务逻辑)
if 需要清理 then
redis.call('HDEL', KEYS[1], fields[i])
end
end
until cursor == '0'方案4:转存大Key
对于无法拆分的场景(如大文件、BLOB数据),将数据存至其他存储介质(如OSS、HDFS),在Redis中删除此类数据。
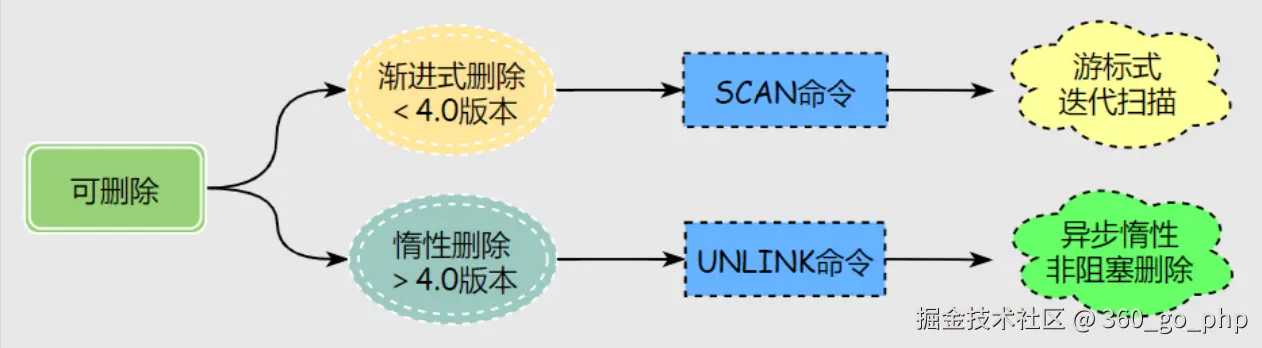
六、大Key的删除技巧
⚠️ 重要警告 :禁止直接使用DEL命令删除大Key!这会造成Redis长时间阻塞,甚至主备倒换。
推荐方法1:使用UNLINK命令(Redis 4.0+)
UNLINK命令通过异步方式清理Key,避免阻塞主线程。
bash
# 异步删除大Key
UNLINK large_key_name
# 批量异步删除
UNLINK key1 key2 key3推荐方法2:分批删除(Redis 4.0以下版本)
对于集合类型,使用SCAN命令分批读取,然后逐个删除。
lua
-- 分批删除Hash中的字段
local cursor = '0'
repeat
local result = redis.call('HSCAN', KEYS[1], cursor, 'COUNT', 100)
cursor = result[1]
local fields = result[2]
for i = 1, #fields, 2 do
redis.call('HDEL', KEYS[1], fields[i])
end
until cursor == '0'
-- 最后删除空Key
redis.call('DEL', KEYS[1])推荐方法3:控制删除速度
通过限制每批删除的数量和间隔时间,控制对Redis的影响。
python
# Python示例:分批删除大Key
keys_to_delete = ['key1', 'key2', 'key3'] # 大Key列表
batch_size = 10
for i in range(0, len(keys_to_delete), batch_size):
batch = keys_to_delete[i:i+batch_size]
r.unlink(*batch) # 异步删除
time.sleep(0.1) # 控制速度七、预防大Key的最佳实践

1. 合理设计数据模型
| 建议 | 说明 |
|---|---|
| String类型控制在10KB以内 | 避免存放大文本、图片等数据 |
| 集合类型元素不超过5000个 | 超过阈值应考虑拆分 |
| Key命名规范 | 前缀为业务缩写,避免特殊字符 |
| 合理设置过期时间 | 避免历史数据大量堆积 |
2. 使用合适的数据结构
- 对于时间序列数据,考虑使用Sorted Set而非String
- 对于对象存储,使用Hash而非序列化到String
- 对于需要范围查询的场景,使用ZSet
3. 建立监控预警机制
 设置合理的报警阈值:
设置合理的报警阈值:
- 内存使用率超过70%
- 内存在1小时内增长率超过20%
- 单个节点内存使用率明显高于其他节点
- 网络带宽使用率突增
4. 定期执行大Key扫描
 将大Key扫描纳入日常运维流程,定期(如每周)执行一次离线分析,及时发现问题。
将大Key扫描纳入日常运维流程,定期(如每周)执行一次离线分析,及时发现问题。
5. 使用TairHash等增强数据结构
 针对Hash类型的大Key场景,Tair(企业版)提供了
针对Hash类型的大Key场景,Tair(企业版)提供了TairHash,支持为每个field设置过期时间和版本,显著减少运维负担。
总结
Redis大Key问题是生产环境中最常见也最具破坏力的隐患之一。通过本文,我们了解到:
| 维度 | 核心要点 |
|---|---|
| 大Key定义 | String>10KB,集合>5000元素 |
| 主要影响 | 内存倾斜、性能下降、网络拥塞、同步风险 |
| 排查方法 | --bigkeys、SCAN命令、RDB分析、云工具 |
| 解决方案 | 拆分、压缩、清理、转存 |
| 删除技巧 | 使用UNLINK或分批删除,避免直接DEL |
| 预防措施 | 合理设计、监控预警、定期扫描 |
记住 :大Key问题的核心在于预防为主,治理为辅。在日常开发中遵循最佳实践,在运维中建立监控预警机制,才能让Redis真正发挥其高性能的优势。