冷读问题的分析
最近有群里的同学咨询我关于线上RocketMQ集群服务器磁盘IOPS很高,业务方反馈写入延迟增大的问题。这种问题一般情况下都是RocketMQ集群产生冷读造成的,对于RocketMQ来讲,如果消费比较及时,大部分读取仅通过PageCache就完成了,但是冷读的消费者,读取的消息已经从pageCache中被驱逐了,此时消息的读取会从磁盘中读取,会消耗磁盘的带宽和IOPS。还有一点,冷读也会导致读放大,因为当消费者需要读取一条很久远的消息(产生冷读)时,系统必须从磁盘加载一个包含该消息的数据块,但由于数据块内混合存储了其他消息(其他Topic的或者其他队列的),导致实际读取的数据量远大于所需的数据量,从而造成了读放大效应,这种情况下,会挤压pageCache的空间,极端情况下会导致热数据会被置换。
冷读产生的原因
冷读产生的原因肯定是跟消费者相关的,一般来说,消费者是分为两种类型的,第一种是追尾读类型的消费者,一般在实时的消费,消费基本上在cache当中,消费的RT也较短,对系统资源的消耗也很低,另外一种就属于冷读的消费者了。 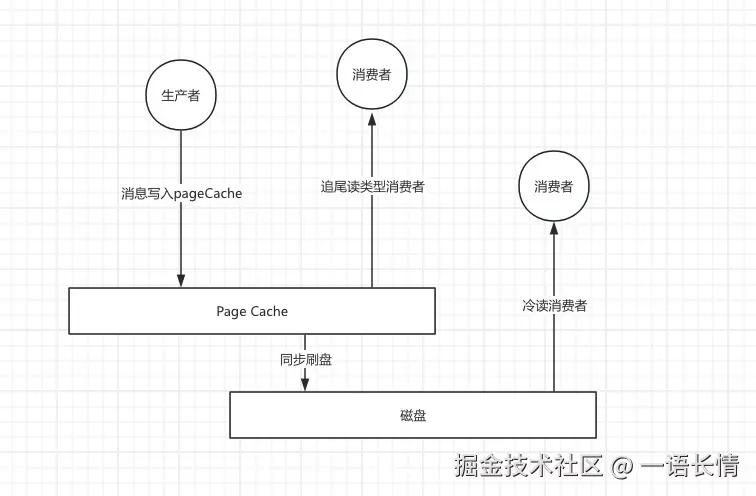
产生冷读的原因一个就是消费者的消费速度跟不上生产者的写入速度,导致消息积压。积压的消息因为"太老",早已从 PageCache 中被淘汰。另一种情况就是访问模式本身决定了要读取的数据不在缓存中,比如新的消费者组启动选择从CONSUME_FROM_FIRST_OFFSET的消费或者需要回溯消费的场景。
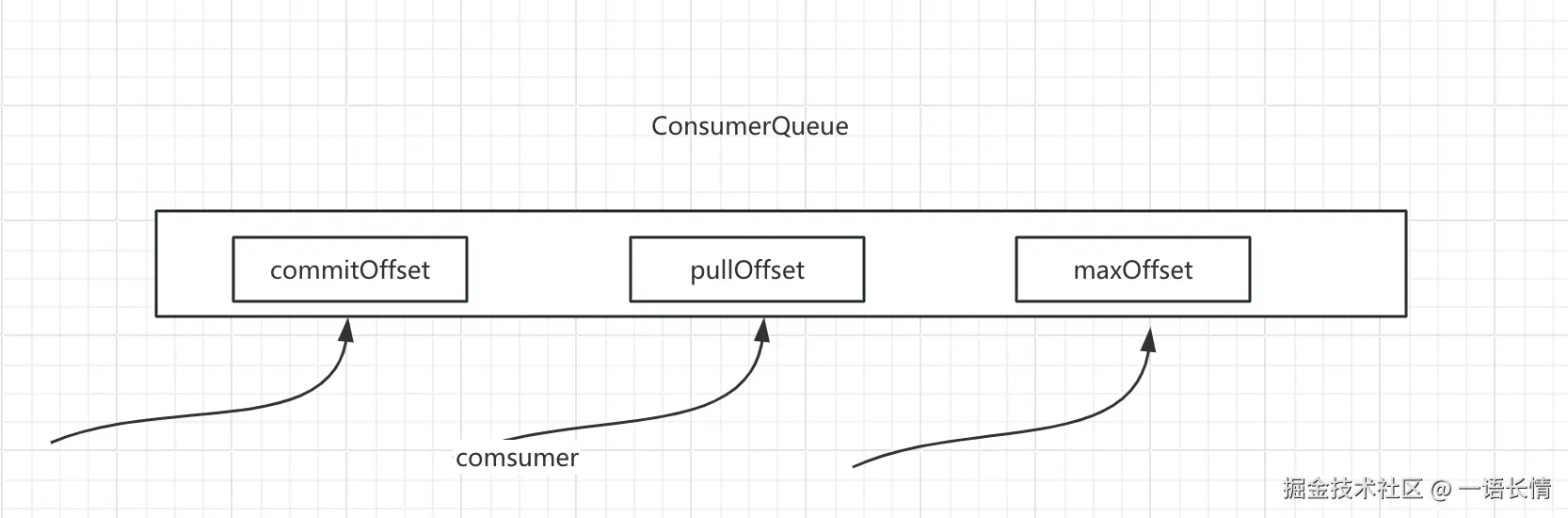
一个consumerQueue存在三种offset,一个是commitOffset 这个是消费者消费完成的位点,一个是pullOffset 这个是消费者正在拉取的位点,最后一个就是maxOffset 这个是这个队列最大可以消费的位点
冷读产生的原因就是pullOffset距离maxOffset太远了,导致这部分数据已经被置换到磁盘了,如果要读取的话,就需要从磁盘上面读取,这个读取是一个强烈的随机读IO,需要消耗磁盘的带宽和IOPS,磁盘现在要同时处理生产者的顺序写入和消费者的随机读取,这就破坏了生产者写入消息的顺序性,会导致写入延迟的增大,从pageCache的角度来看,大量冷读的数据会进入pageCache中,会挤压热数据的生存空间,为了容纳这些新的冷读数据,内核的 kswapd线程会开始回收页面,这可能会淘汰掉那些原本是热数据的消息或者索引,也可能导致后续本应是热读的操作再次变成冷读,形成恶性循环
冷读的处理
硬件方面有如下两点可以来进行优化:
- 内存,内存越大PageCache 能缓存更多的消息,需要从磁盘读取数据的概率更低,建议采用1:4 甚至 1:8 的 CPU 内存比的机器规格
- 磁盘IOPS,一般情况下 RocketMQ 不会触及磁盘带宽的瓶颈,但IOPS是更宝贵的资源,冷读会带来大量离散的IOPS,IOPS越高,冷读的服务能力越强。
线上遇到这种冷读情况后,若已经对业务造成了很大的影响,可以使用以下的几种处理方式来进行:
- 可以将受影响集群的重要业务相关的Topic写入流量迁移到其他的集群,保障核心业务不受影响
- 将正在冷读的consumerGroup进行短暂禁读处理,等业务峰值过后再放开,冷读的ConsumerGroup本身已经在延迟消费,再延迟一段时间基本上对业务无影响
- 有两个冷读相关拉取消息的参数maxTransferCountOnMessageInDisk、 maxTransferBytesOnMessageInDisk,第一个参数指的是每次冷读的Pull请求只能拉取8条消息,第二个参数每次冷读的Pull请求只能拉取64KB的消息内容,8和64都是默认值,可以改动的,如果要进一步限制冷读对系统的影响,可以将上述参数进一步调小,或者想要尽快处理完消息,也可以临时调大帮助业务方快速消费完堆积的数据