这个教程是一边学习一边写的,中间可能会出现一些疏漏或者错误,如果您看到该篇文章并且发现了问题,还请多多指教!
1. 文件检索
a.Embedding
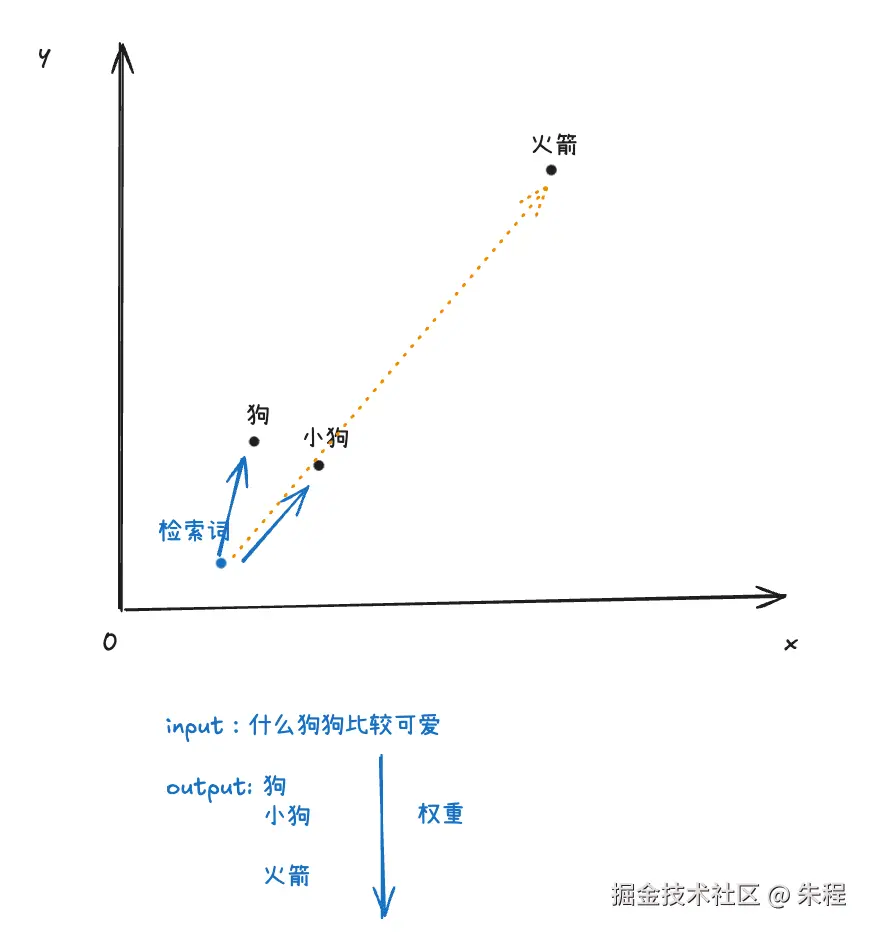
在大模型的检索中,根据语义来检索相关的内容是必要的,例如我们搜索"手机电池续航"时,可能会想要搜索"充电宝","待机时长"等内容,但是如果按关键词搜索可能找不到相关的内容。这个时候我们就需要"向量化 "处理数据,也就是"Embedding",这里我们先粗略的理解一下Embedding。如果要手动实现 Embedding ,我们可能需要学习nlp相关的各类知识,门槛比较高,但是借助于 Embedding model 这个黑盒,我们可以将关注点放到我们的工程上来。Embedding model 实际上就是一种高级翻译器,它的关键能力是语义理解和上下文感知。想象你有一个二维的向量空间,中间的内容有"狗","小狗","火箭",一个文本 Embedding 模型会学习到"狗"和"小狗"这两个词在向量空间里应该非常接近,而"狗"和"火箭"则会相隔很远,我们在向量化的过程中就是把内容转变成多维向量空间中的座标。
b. 如何实现
在了解了Embedding相关的内容之后,我们来动手实现一下将数据向量化。我们需要一个容器来存储这些向量座标,传统的结构化数据库也可以存储,但是不适合向量化搜索,我们需要向量数据库来存储这些数据。LangChain也提供了一个基于内存的向量数据库,这里我们直接使用它作为我们的存储数据库。我们先拉取Embedding model,使用命令 ollama pull hf.co/Qwen/Qwen3-Embedding-4B-GGUF:Q4_K_M 来拉取 qwen3 的 embedding 模型作为我们的处理模型,同时准备好我们的示例文档。
ts
import { OllamaEmbeddings } from "@langchain/ollama";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import "cheerio";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
const embeddings = new OllamaEmbeddings({
model: "hf.co/Qwen/Qwen3-Embedding-4B-GGUF:Q4_K_M",
});
// 定义向量数据库
const vectorStore = new MemoryVectorStore(embeddings);
// 使用 cheerio 加载网页内容
const selector = "p";
const cheerioLoader = new CheerioWebBaseLoader(
"https://www.bjnews.com.cn/detail/165821990514497.html",
{
selector: selector,
}
);
const docs = await cheerioLoader.load();
// 定义分割器
const splitter = new RecursiveCharacterTextSplitter({
// 分块大小
chunkSize: 500,
// 重叠大小,用来连接每个分块之间的内容,比如分块1是从[0...500], 分块2是从[400, 900]
chunkOverlap: 100,
separators: ["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""], // 中文分隔符
});
const allSplits = await splitter.splitDocuments(docs);
// 存入向量数据库
await vectorStore.addDocuments(allSplits);
// 检索
const retrievedDocs = await vectorStore.similaritySearchWithScore("巨魔芋的科研和经济价值");
console.log(retrievedDocs);我们可以输入不同的内容来看输出的结果是什么样,这里我们查看原文发现最后一段明确的给出了关于"巨魔芋的科研和经济价值"的答案,查看一下我们的结果
json
[
[
Document {
pageContent: '。 同时巨魔芋还具有很高的科研和经济价值,球茎内含有大量的葡甘聚糖,是目前发现的最优良可溶膳食纤维之一,可广泛应用于食品、医药、化妆品、化工和生物等多个领域。国家植物园的科研人员正在研究如何把巨魔芋与同属其他种具有使用价值的魔芋进行杂交,培育出新的魔芋品种。 新京报记者 张璐编辑 刘茜贤 校对 李立军想要发表评论,阅读更多精彩内容,快来下载新京报客户端吧',
metadata: [Object],
id: undefined
},
0.9744232671711778
],
[
Document {
pageContent: '。 巨魔芋看上去十分巨大,但它实际上是草本植物。无论是它犹如树干粗细的叶子,还是巨大的肉穗花序,其内部结构都是高度纤维化、角质化的六棱柱子蜂窝状结构。此次巨魔芋的群体开花,也使得国家植物园得以对巨魔芋进行更细致的观察。科研人员还记录下了巨魔芋雄花出花粉的过程,并首次以视频形式对外进行公布。科研人员正研究巨魔芋杂交,培育新的魔芋品种 巨魔芋的引种栽培研究对国家植物园来说有着重要意义。巨魔芋原产于印度尼西亚西部苏门答腊岛热带密林,属于珍稀濒危植物,国际自然保护联盟(IUCN)在其发布的1997年濒危物种红色名录中就已经将巨魔芋列为易危种。 由于人类对棕榈产品和木材的大量需求,苏门答腊岛的热带雨林受到巨大破坏。据不完全统计,印度尼西亚已经失去了72% 的原始热带雨林,情况仍在恶化,导致巨魔芋的原始生境受到直接破坏,巨魔芋的野外生存状况岌岌可危,需要对这个物种进行保存并研究它的生物学习性及繁殖机制,想办法增加它的数量。 同时巨魔芋还具有很高的科研和经济价值,球茎内含有大量的葡甘聚糖,是目前发现的最优良可溶膳食纤维之一,可广泛应用于食品、医药、化妆品、化工和生物等多个领域',
metadata: [Object],
id: undefined
},
0.9718207467148721
],
[
Document {
pageContent: '。目前正值国家植物园挂牌3个月之际,巨魔芋的群体开花体现了国家植物园在植物迁地保护、科学研究和栽培养护的高超水平。 巨魔芋是天南星科魔芋属植物,是世界珍稀濒危植物。巨魔芋体型高大,虽然是草本植物,却拥有世界上最大的不分枝肉穗花序,肉穗花序包括五百多枚雌花和两千多枚雄花。现在已知最高的花序达到3米多,比普通的房屋还要高。在肉穗花序的周围,紫红色的佛焰苞犹如一个倒立的烟囱,将花序保护在中央,本次展出的巨魔芋花序高1.66米。 由于巨魔芋的花朵巨大,十分消耗养分,因此它的花期只有48小时左右。开花时,巨魔芋会释放自己合成的、含一百多种化学物质的气体,主要成分为碳氢化合物及硫化物,所以会散发一股腐肉的气味。同时巨大的佛焰苞变成深紫色模拟腐肉的样子。巨魔芋开花时会放热,花序温度持续在36摄氏度左右,与人体体温接近。 在苏门答腊密林深处,生活着众多的苍蝇、食腐甲虫等昆虫以及一些小型的食腐动物,巨魔芋所模拟的这一切,无论是气味、颜色还是温度的变化,都是为了吸引这些昆虫和动物为它传粉。 巨魔芋看上去十分巨大,但它实际上是草本植物',
metadata: [Object],
id: undefined
},
0.961195925741902
],
[
Document {
pageContent: '巨魔芋开花极难,一生只开3-4次花,每次开花不超过2天,全世界人工栽培开花次数仅100余次。 今天(7月19日),国家植物园(北园)展览温室内一株巨魔芋正在开花,就在它的旁边,另一株巨魔芋也已含苞待放。这是国家植物园近期开花的第二株巨魔芋,本次开花的巨魔芋与7月6日开花的第一株巨魔芋以及即将开放的第三株巨魔芋实现人工栽培状态下的巨魔芋群体开花,属世界首次。工作人员给巨魔芋测量佛焰苞宽度。国家植物园(北园)供图 工作人员给巨魔芋测量温度。国家植物园(北园)供图 工作人员使用热成像设备拍摄巨魔芋。国家植物园(北园)供图首次公布巨魔芋雄花出花粉视频 巨魔芋是世界珍稀濒危植物三大旗舰种之一,是世界上单体花序最大的植物,是世界上最臭的花。巨魔芋开花极难,一生只开3-4次花,每次开花不超过2天,全世界人工栽培开花次数仅100余次。目前正值国家植物园挂牌3个月之际,巨魔芋的群体开花体现了国家植物园在植物迁地保护、科学研究和栽培养护的高超水平。 巨魔芋是天南星科魔芋属植物,是世界珍稀濒危植物',
metadata: [Object],
id: undefined
},
0.9539265581706111
]
]我们可以看到我们的答案的相关度得分是最高的,这样就完成了对文档内容的检索。但是这只是一个很简单的"hello world"示例,实际工程中我们对用于检索的文档一般要经历数据清洗 => 数据向量化 => 测试输出内容 => 反馈到向量化这样的循环来不断迭代优化我们的功能。
2. RAG
RAG(Retrieval Augmented Generation )技术是我们在实践中会经常用到的一种技术,例如智能客服系统,构建公司内部的知识库系统等等。RAG技术主要解决了大模型的训练语料落后于现实时间以及针对私有的知识领域无法回答这两个问题,简单来说就是我们给大模型提供了一种能够基于我们私有的知识文档来回答或者解决问题的能力。
RAG主要可以分为四个步骤
- 数据处理:爬取或者准备相应的语料作为我们的数据,将这些语料分割并嵌入向量数据库
- 检索:将输入的内容作为查询的向量来查找向量数据库中最相似的文档块
- 增强:将检索到的文档块作为上下文原始问题一起作为提示词发送给大模型
- 生成:大模型通过增强后的提示词来生成最终答案
尽管之前我们提到可能会在向量化这个过程进行迭代,但是对于整个rag系统的优化来说我们是以一种端到端的方式,在数据处理阶段进行优化保证数据质量提高检索的准确性,在生成阶段进行优化保证回答的质量和可靠性。
基于这四个步骤和前面文档检索小结的内容,我们来实现一个简单的RAG系统。
ts
import { ChatOllama, OllamaEmbeddings } from "@langchain/ollama";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import "cheerio";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { Annotation, StateGraph } from "@langchain/langgraph";
import { Document } from "@langchain/core/documents";
// 定义生成大模型
const llm = new ChatOllama({
model: 'qwen3:8b',
temperature: 0
})
// 定义向量模型
const embeddings = new OllamaEmbeddings({
model: "hf.co/Qwen/Qwen3-Embedding-4B-GGUF:Q4_K_M",
});
// 定义向量数据库
const vectorStore = new MemoryVectorStore(embeddings);
// 加载并分割博客内容
const selector = "p";
const cheerioLoader = new CheerioWebBaseLoader(
"https://www.bjnews.com.cn/detail/165821990514497.html",
{
selector: selector,
}
);
const docs = await cheerioLoader.load();
// 定义分割器
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 100,
separators: ["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""], // 中文分隔符
});
const allSplits = await splitter.splitDocuments(docs);
// 存入向量数据库
await vectorStore.addDocuments(allSplits);
// 定义提示词
const promptTemplate = ChatPromptTemplate.fromTemplate(
`你是一个专业的问题解答任务的助手。使用以下检索到的上下文回答问题。如果不知道答案,就说不知道。最多使用三句话,答案要简明扼要。
question: {question};
context: {context};
answer:
`
)
// 定义流程状态
const InputStateAnnotation = Annotation.Root({
question: Annotation
})
const StateAnnotation = Annotation.Root({
question: Annotation<string>,
context: Annotation<Document[]>,
answer: Annotation<string>,
})
// 检索相关文档
const retrieval = async (state: typeof InputStateAnnotation.State) => {
const docs = await vectorStore.similaritySearch(state.question as string)
return {
context: docs
}
}
// 根据检索内容生成回答
const generate = async (state: typeof StateAnnotation.State) => {
const docsContent = state.context.map(doc => doc.pageContent).join('\n')
const prompt = await promptTemplate.invoke({
question: state.question,
context: docsContent
})
const result = await llm.invoke(prompt)
return {
answer: result.content
}
}
// 定义工作流
const workflow = new StateGraph(StateAnnotation)
.addNode('retrieval', retrieval)
.addNode('generate', generate)
.addEdge('__start__', 'retrieval')
.addEdge('retrieval','generate')
.addEdge('generate', '__end__')
const app = workflow.compile()我们通过输入不同的问题来看看回答的结果。
ts
const res = await app.invoke({
question: "巨魔芋的科研和经济价值"
})
console.log(res.answer);
<think>
好的,用户问的是巨魔芋的科研和经济价值。我需要从提供的上下文中找到相关信息。首先,快速浏览上下文,注意到多次提到科研和经济价值。比如,球茎含有葡甘聚糖,是优良的可溶膳食纤维,应用领域广泛。还有科研人员在研究杂交培育新品种,以及引种栽培对保护物种的重要性。另外,巨魔芋的结构和开花特性可能也有科研价值,比如其独特的结构和传粉机制。经济价值方面,除了葡甘聚糖的应用,可能还有其作为珍稀植物的潜在价值。需要确保回答简明,不超过三句话,且使用用户提供的上下文内容。注意不要添加额外信息,如果不知道的就不说。确认上下文没有提到其他经济价值,所以主要围绕葡甘聚糖的应用和杂交研究。科研方面包括结构研究、传粉机制和保护研究。经济价值主要是葡甘聚糖的应用领域。整理成两到三句话,确保准确。
</think>
巨魔芋具有显著的科研和经济价值,其球茎富含葡甘聚糖,是优质的可溶膳食纤维,可应用于食品、医药、化妆品等领域。科研人员正通过杂交培育新品种,并研究其结构、传粉机制及迁地保护技术,以促进物种保存与利用。
ts
const res = await app.invoke({
question: "全球变暖的原因"
})
console.log(res.answer);
<think>
好的,用户的问题是关于全球变暖的原因,但提供的上下文内容却主要涉及国家植物园、巨魔芋的开花情况,以及一些许可证信息。首先,我需要确认上下文中是否有任何与全球变暖相关的信息。快速浏览后,发现内容主要讲的是植物园的活动、巨魔芋的生物学特性,以及一些网站的备案信息,没有提到气候变化、温室气体、人类活动等因素。
接下来,用户可能希望得到关于全球变暖的成因,比如二氧化碳排放、森林砍伐、工业活动等。但根据提供的上下文,这些内容并未涉及。因此,按照指示,如果不知道答案,应该回答不知道。同时,需要确保答案不超过三句话,并且简明扼要。因此,正确的做法是直接告知用户提供的上下文与问题无关,无法给出答案。
</think>
提供的上下文内容主要涉及国家植物园、巨魔芋的生物学特性及网站备案信息,未提及全球变暖的相关原因。因此,无法基于此回答问题。我们看到现在大模型对于我们的输入内容做出了不同的回答
3. 小结
通过这一章的内容我们初步认识了 rag 的原理和工作流程,但是在实现上我们只做了简单的处理,如果面对复杂的语料数据,我们需要通过元信息,合理分块等等方法来进行优化,下一章我们来探索相关的优化方法