介绍GSPO:一种革命性的语言模型强化学习算法
近年来,强化学习(RL)已成为训练大型语言模型(LLMs)的关键技术之一,尤其是在推动模型在数学、编程等复杂推理任务上的表现。然而,现有的RL算法(如GRPO)在训练大规模模型时常常面临稳定性差、易发生灾难性崩溃等问题。为了解决这些根本性挑战,阿里巴巴Qwen团队提出了一种全新的强化学习算法------Group Sequence Policy Optimization (GSPO),该算法在训练稳定性、效率和最终性能方面均显著优于现有方法。
一、背景与动机
传统的RL算法(如PPO、GRPO)大多基于token级别的重要性采样(importance sampling)进行策略优化。GRPO虽避免了价值模型的使用,但其token级的重要性权重设计存在根本缺陷:每个token的权重仅基于单个样本计算,无法有效纠正分布偏差,反而引入高方差噪声。随着响应长度增加,这种噪声会累积并最终导致模型崩溃,且往往不可逆转。
GSPO的提出正是基于这样一个核心洞察:优化目标的最小单位应与奖励的授予单位一致。既然奖励是针对整个响应序列(sequence)给出的,那么重要性采样和优化也应在序列级别进行。
二、GSPO的核心思想
GSPO算法摒弃了token级别的重要性比率,转而使用序列级别的重要性比率,定义为:
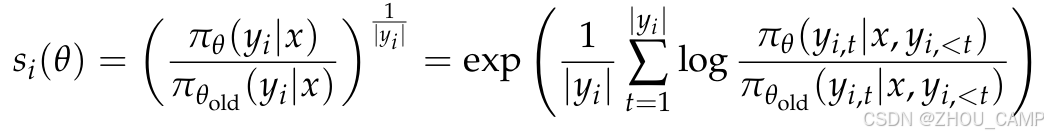
该比率反映了从旧策略中采样的响应在新策略下的偏离程度,与序列级别的奖励自然对齐。GSPO的优化目标如下:
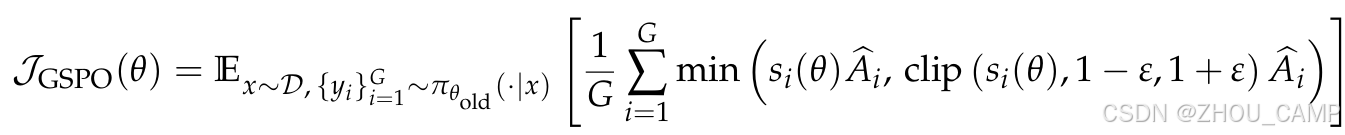
三、GSPO的优势
1. 训练稳定性显著提升
GSPO从根本上解决了GRPO中因token级权重不稳定导致的训练崩溃问题。实验表明,GSPO能够持续稳定训练,即便在生成长响应或训练混合专家模型(MoE)时也是如此。
2. 更高的训练效率
尽管GSPO会裁剪掉更多token,但其序列级别的梯度估计更加高效和可靠,从而在相同计算量和查询次数下取得更好的训练效果和基准性能。
3. 适用于MoE模型
GSPO天然克服了MoE模型中专家激活波动带来的训练不稳定问题,无需依赖复杂的"路由回放"(Routing Replay)策略,简化了训练流程并降低了内存与通信开销。
4. 简化RL基础设施
由于GSPO仅依赖序列级别的似然计算,其对计算精度差异的容忍度更高,使得直接使用推理引擎(如vLLM)返回的似然值进行优化成为可能,从而避免了训练引擎的重复计算。
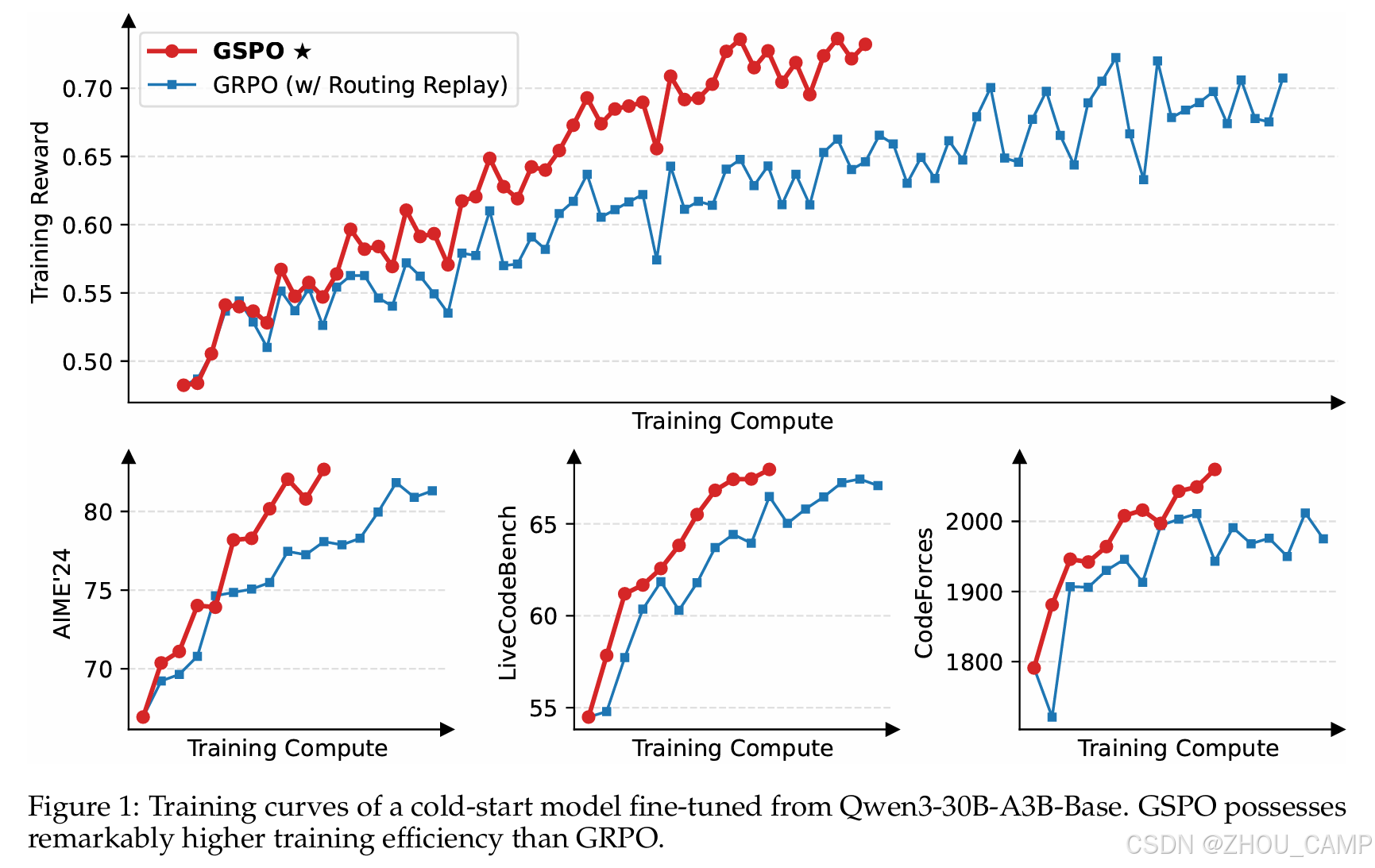
四、实验效果
团队在基于Qwen3-30B-A3B-Base的冷启动模型上进行了实验,在AIME'24、LiveCodeBench和CodeForces等基准测试中,GSPO均显著优于GRPO。训练过程中,GSPO表现出持续的奖励提升和性能改进,展现了其在大规模RL扩展中的强大潜力。
五、总结与展望
GSPO不仅是一种更加稳定和高效的RL算法,更是推动语言模型智能进一步发展的关键技术。其序列级别的优化理念与奖励机制的自然对齐,为未来RL训练提供了新的理论基础和实践路径。阿里巴巴Qwen团队已将GSP成功应用于Qwen3系列的训练中,取得了显著性能提升,并将继续推动RL技术在大模型训练中的规模化应用。