本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
LangGraph 被广泛认为是构建生产级代理系统的首选。今天我们将通过深度研究助手这个示例,深入探讨 LangGraph 的工作流程和 MCP 的集成模式。如果对你有所帮助,记得告诉身边有需要的朋友。

一、核心设计理念
双服务器MCP集成
- 自定义研究服务器:提供FAISS向量存储、语义搜索工具及本地资源管理
- Firecrawl MCP服务器:支持实时网络爬取/数据提取(需Node.js v22+)
bash
npm install -g @mcp-servers/firecrawl # 安装命令状态化智能体(Stateful Agent)
LangGraph的StateGraph实现:
- 持久化对话记忆
- 多轮工具调用链
- 动态工作流分支(工具调用/资源加载/用户指令响应)
用户元命令控制
| 命令格式 | 功能说明 |
|---|---|
| @prompt: | 加载特定提示模板 |
| @resource: | 加载指定资源 |
| @use_resource: | 执行资源查询 |
二、核心模块实现
1. LangGraph工作流引擎
python
from langgraph.graph import StateGraph
workflow = StateGraph(AgentState)
workflow.add_node("research", research_tool_node)
workflow.add_node("web_crawl", firecrawl_node)
workflow.add_conditional_edges(
"agent",
decide_next_action,
branches={"research": "research", "web": "web_crawl"}
) # 动态路由逻辑2. 模块化工具设计
RAG即服务:拆分为独立工具而非固定流水线
- 向量存储工具:save_to_vectorstore()
- 检索工具:semantic_retrieval(query)
工具热插拔:新增工具只需注册到MCP服务器
python
@mcp_tool
def pdf_extractor(url: str) -> str:
"""Firecrawl网页PDF提取工具"""
return firecrawl_api.scrape(url, params={"extract_pdf": True})3. 多服务器资源调度
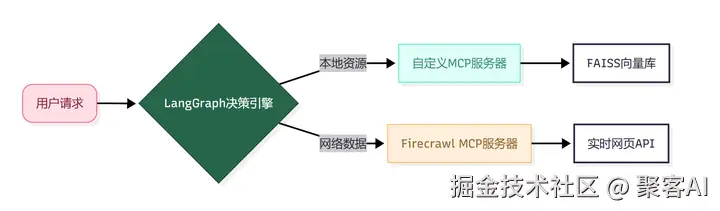
三、关键技术优势
可扩展架构
- 横向扩展:新增MCP服务器即扩展能力域
- 工具热更新:修改工具无需重启智能体
用户主导的工作流
perl
if user_input.startswith("@prompt:"):
load_prompt(user_input.split(":")[1]) # 动态提示加载
elif user_input.startswith("@use_resource:"):
uri, query = parse_resource_cmd(user_input)
execute_resource_tool(uri, query) # 按需资源调用生产级容错机制
- 工具调用超时自动回退
- MCP服务器心跳检测
- 错误输出结构化重试
四、实施路线图
环境准备
bash
git clone https://github.com/example/mcp-research-assistant
cd mcp-research-assistant && uv sync # 依赖安装Firecrawl配置
yaml
# config.yaml
firecrawl:
api_key: YOUR_API_KEY
mcp_endpoint: "stdio" # 或 https://api.firecrawl.io启动双服务器
yaml
# 终端1:启动自定义MCP服务器
python research_server.py --port 8033
# 终端2:启动Firecrawl服务
firecrawl-mcp --transport stdio五、典型工作流示例
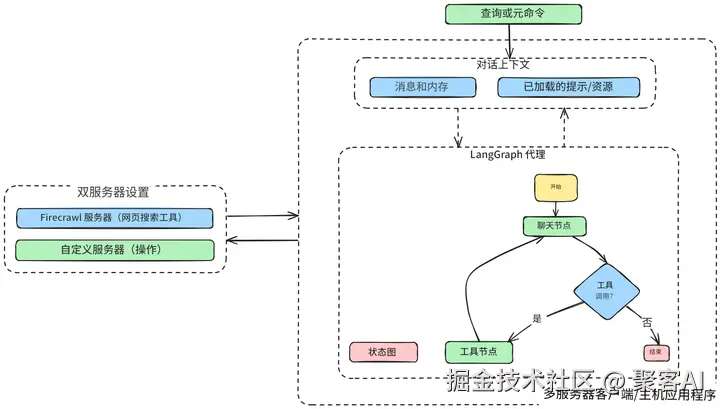
添加图片注释,不超过 140 字(可选)
- 用户输入:@use_resource:arxiv_papers "transformer optimization"
- LangGraph路由至研究服务器
- FAISS执行语义检索
- 结果整合至对话上下文:
json
{
"tool_output": "10篇相关论文摘要...",
"next_step": "是否需要深度网络搜索?"
}结语
该架构通过MCP协议实现工具/资源的标准化封装,结合LangGraph的状态化工作流引擎,构建出具备动态决策能力的研究助手。核心创新点在于:
- 用户元命令驱动的控制模式
- RAG能力的工具化解耦
- 多MCP服务器热插拔机制
好了,今天的分享就到这里,点个小红心,我们下期见。