同事再学习Python时遇到了两个东西:列表(list)和元组(tuple) 。这两个看起来好像差不多,都是一个能装东西的容器,不就是列表用方括号[],元组用圆括号()吗?于是觉得反正差不多,随便用呗。
如果这么想,那可就错过了Python设计里一个大大的精髓了。这俩玩意儿在底层实现和应用场景上,那真是截然不同的,这次我们就看看这两个家伙到底怎么用的和有什么区别!
底层解释
说白了,最根本的区别就一句话:列表是可变的,而元组是不可变的。
你别小看这个"可变"与"不可变",它直接决定了它俩在电脑内存里存在的方式。
列表是个"动态数组"
英文翻译过来就是内置可变序列,还能随时变身:增加、删除、修改里面的元素。
这个超能力是怎么实现的?在底层,Python会给列表分配一块内存空间。当你往列表里append一个新元素时,如果之前分配的空间不够了,Python不会卡住,它会干这么一件事:自动找一块更大的新内存,把老家所有的东西都搬过去,然后再把新元素请进门。
这个过程叫"内存超配"。为了避免每次append都来一次搬家大会,Python列表每次扩容时,都会多要一点空间,比如这次要了4个座,下次可能直接要8个,下下次要16个......这样大部分时候的append操作都会非常快,因为它有空位。只有在扩容的那一下,成本会高一点。
所以,列表的"可变"是以牺牲一点点内存和偶尔的扩容成本为代价的,换来的是灵活性。
元组是个"静态数组"。
 翻译过来就是内置不可变序列,里面的元素个数和内容一旦创建是改变不了的。 它在底层实现上就简单粗暴多了。Python给它分配一块固定大小的内存,然后就完事了。因为它不变,所以也不用留多余的空位,更不用担心扩容搬家的事。
翻译过来就是内置不可变序列,里面的元素个数和内容一旦创建是改变不了的。 它在底层实现上就简单粗暴多了。Python给它分配一块固定大小的内存,然后就完事了。因为它不变,所以也不用留多余的空位,更不用担心扩容搬家的事。
这就带来了两大优势:
- 更省内存:没有多余的空间浪费。
- 速度更快:因为结构简单固定,Python解释器处理元组的速度会比处理列表稍微快那么一丢丢。
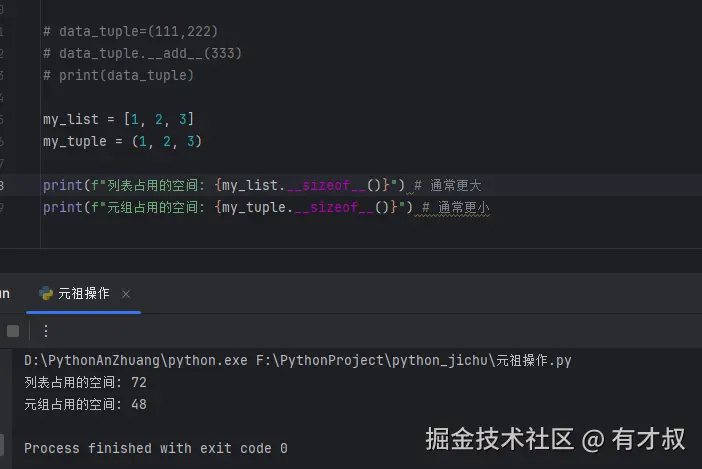
你可以用__sizeof__()方法看看它俩占多大地方,同样装1,2,3,元组的占用空间肯定比列表的小。
应用场景
明白了底层的区别,该怎么用就清晰了。记住一个原则:用元组来保证"事实不变",用列表来管理"动态变化"。
元组的场景:
-
字典的键(Key):这是元组的核心舞台!字典的键要求必须是"不可变"的,因为Python是靠键的哈希值来快速定位数据的。列表是可变的,它的哈希值会变,所以没资格当键。但元组可以,只要它里面所有的元素也都是不可变的(比如数字、字符串、元组)。
python# 正确示范:用元组做键,记录不同城市的经纬度 location_map = {} beijing_loc = (39.9042, 116.4074) location_map[beijing_loc] = "北京市" -
函数返回多个值:如果一个函数需要返回好几个值,直接return一个元组,既简单又清晰。拆包也方便。
pythondef get_user_info(): name = "张三" age = 30 return name, age # 这其实返回的是一个元组 (name, age) user_name, user_age = get_user_info() -
保证数据安全:当你需要传递一组数据,并且你绝对不希望这组数据在函数内部被意外修改时,就用元组。
列表的场景:
-
需要动态增删数据的集合:这是列表的主场。比如要处理一个日志文件,需要把每一行都读进来放到一个容器里,中途可能还要过滤掉一些无效数据(删除),那列表是不二之选。
-
栈(Stack)和队列(Queue) :虽然Python有专门的模块,但用列表来实现栈(
append和pop)和简单的队列是非常常见的操作。 -
进行数据运算和变化 :比如你有了一组数据,需要对它们进行排序(
sort)、反转(reverse)等各种操作,那必须得是列表。
总结
现在看看,列表和元组还一样吗?
- 列表 就像你的日常待办清单。你可以随时往上加新任务,完成的任务可以划掉,优先级变了还可以调整顺序。
- 元组 就像你的身份证信息(姓名、性别、出生日期)。一旦确定,谁也不能随便改。意义就在于其唯一性和不变性,用来唯一地标识你。
所以,下次写代码前,先想清楚:我这数据,将来要变吗?想清楚了再用吧!。