1. 词汇表大小(input_dim)计算方法
嵌入层Embedding中的input_dim是根据数据中所有唯一词(或字)的总数来决定的。可以通过Tokenizer文本分词和编码得到。
简单说,Tokenizer 是一个文本分词和编码器,它主要做两件事:
- 分词:将句子拆分成词或字
- 编码:为每个词/字分配唯一的数字编号
例如:
python
from keras.preprocessing.text import Tokenizer
# 假设这是你的训练文本数据
texts = [
"我爱吃苹果",
"苹果很好吃",
"我不喜欢香蕉",
"香蕉和苹果都是水果"
]
# 创建分词器并构建词汇表,设置 char_level=True 按字分词
# 如果想要更加合理的中文分词,比如"苹果"合并为一个词,可以使用中文分词工具(如 jieba)
# import jieba # 需要安装: pip install jieba后 tokenized_texts = [' '.join(jieba.cut(text)) for text in texts]
tokenizer = Tokenizer(char_level=True)
tokenizer.fit_on_texts(texts) # 学习所有文本,构建词汇表
# 查看词汇表,可以看到词或字对应的索引数字
word_index = tokenizer.word_index
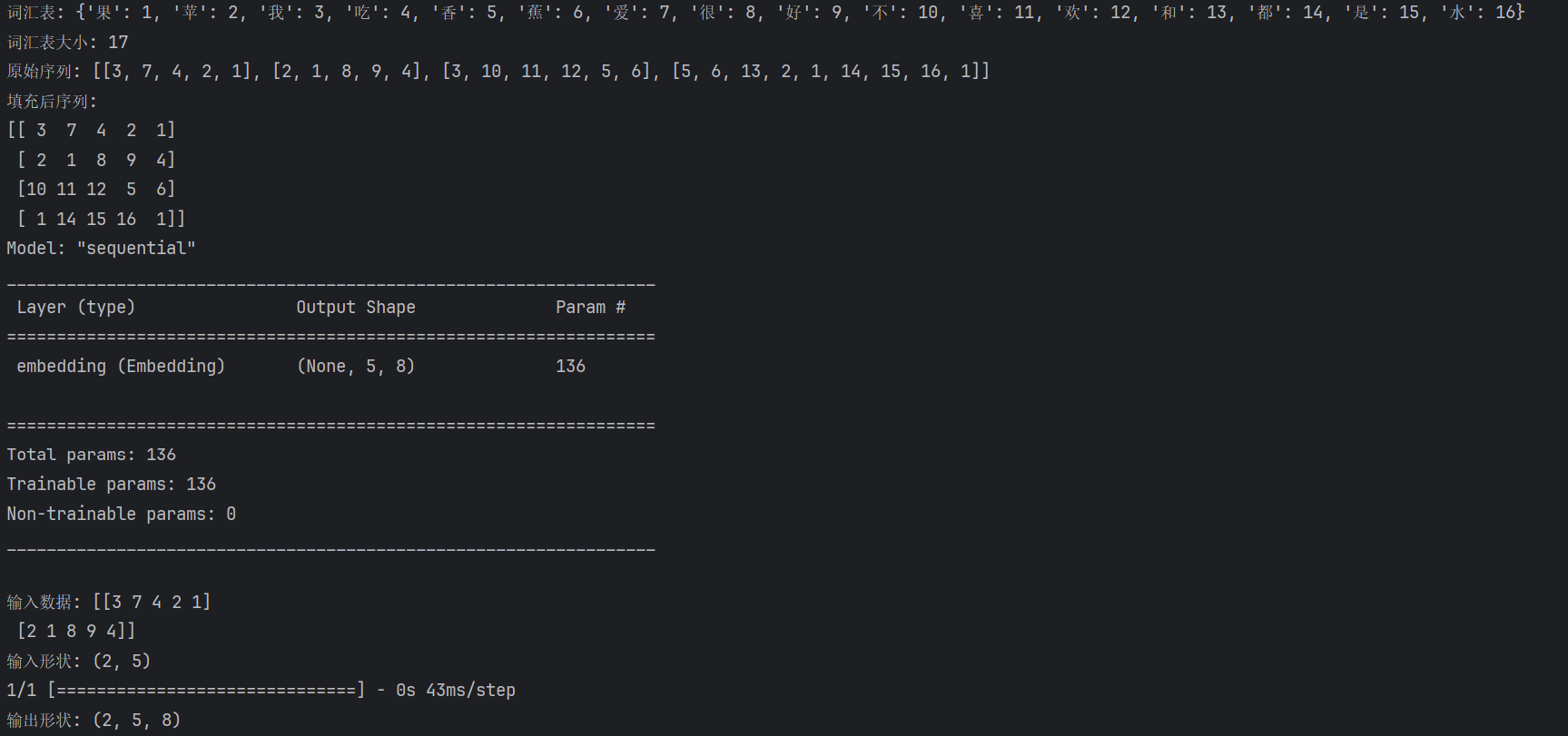
print("词汇表:", word_index)
# 输出可能是: {'果': 1, '苹': 2, '我': 3, '吃': 4, '香': 5, '蕉': 6, '爱': 7, '很': 8, '好': 9, '不': 10, '喜': 11, '欢': 12, '和': 13, '都': 14, '是': 15, '水': 16}
# 词汇表大小 = 唯一词的数量 + 1(+1是为了预留索引0给填充值),这边的值就是嵌入层Embedding中input_dim的数值
vocab_size = len(word_index) + 1
print("词汇表大小:", vocab_size) # 输出: 17
# 将文本转换为数字序列
sequences = tokenizer.texts_to_sequences(texts)
print("数字序列:", sequences)
# 输出:[[3, 7, 4, 2, 1], [2, 1, 8, 9, 4], [3, 10, 11, 12, 5, 6], [5, 6, 13, 2, 1, 14, 15, 16, 1]]所以 input_dim=18,因为我们的词汇表有17个唯一词 + 1个填充索引
2.Tokenizer作用和简单用法
Tokenizer会自动:
- 统计所有文本中出现的词/字
- 按出现频率从高到低排序
- 分配编号(频率最高的词编号为1,次高的为2,以此类推)
python
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 1. 准备数据
texts = [
"我爱吃苹果",
"苹果很好吃",
"我不喜欢香蕉",
"香蕉和苹果都是水果"
]
# 2. 创建词汇表
tokenizer = Tokenizer(char_level=True)
tokenizer.fit_on_texts(texts)
word_index = tokenizer.word_index
vocab_size = len(word_index) + 1 # +1 为填充符0
print("词汇表:", word_index)
print("词汇表大小:", vocab_size)
# 3. 文本转数字序列
sequences = tokenizer.texts_to_sequences(texts)
print("原始序列:", sequences)
# 4. 填充序列到相同长度(input_length=5)
padded_sequences = pad_sequences(sequences, maxlen=5, padding='post')
print("填充后序列:")
print(padded_sequences)
# 5. 创建Embedding层(input_dim根据vocab_size决定)
model = Sequential()
model.add(Embedding(
input_dim=vocab_size, # 这里是18
output_dim=8, # 每个词用8维向量表示,是一个超参数,需要根据经验和实验来确定,小词汇表(<1000):4-16维,一般8
input_length=5 # 每个序列5个词,由最大长度maxlen决定,这边是9。统计所有序列长度:取一个合适的百分位数(如95%)
))
# 查看模型摘要
model.summary()
# 测试预测
sample_input = padded_sequences[:2] # 取前两个样本
print("\n输入数据:", sample_input)
print("输入形状:", sample_input.shape) # (2, 5)
output = model.predict(sample_input)
print("输出形状:", output.shape) # (2, 5, 8)输出结果: