一、引言
一个常常被忽略的真相是:多达80%的数据库性能问题,其根源并非硬件资源不足,而是低效、冗长甚至是灾难性的SQL语句。一条未经优化的SQL,可以轻易地拖垮整个数据库,让昂贵的硬件资源形同虚设。SQL优化,是每一位后端开发者必须掌握的核心内功,一次有效的SQL优化,其效果立竿见影。
本文将带你掌握MySQL SQL优化,教你如何定位慢查询,如何设计高效的索引,如何编写出数据库"喜欢"的SQL语句。
二、索引的底层原理
MySQL的InnoDB引擎采用了B+树作为其索引的默认数据结构。它是一种多路平衡查找树。下图展示了B+树的核心结构与数据查询路径:
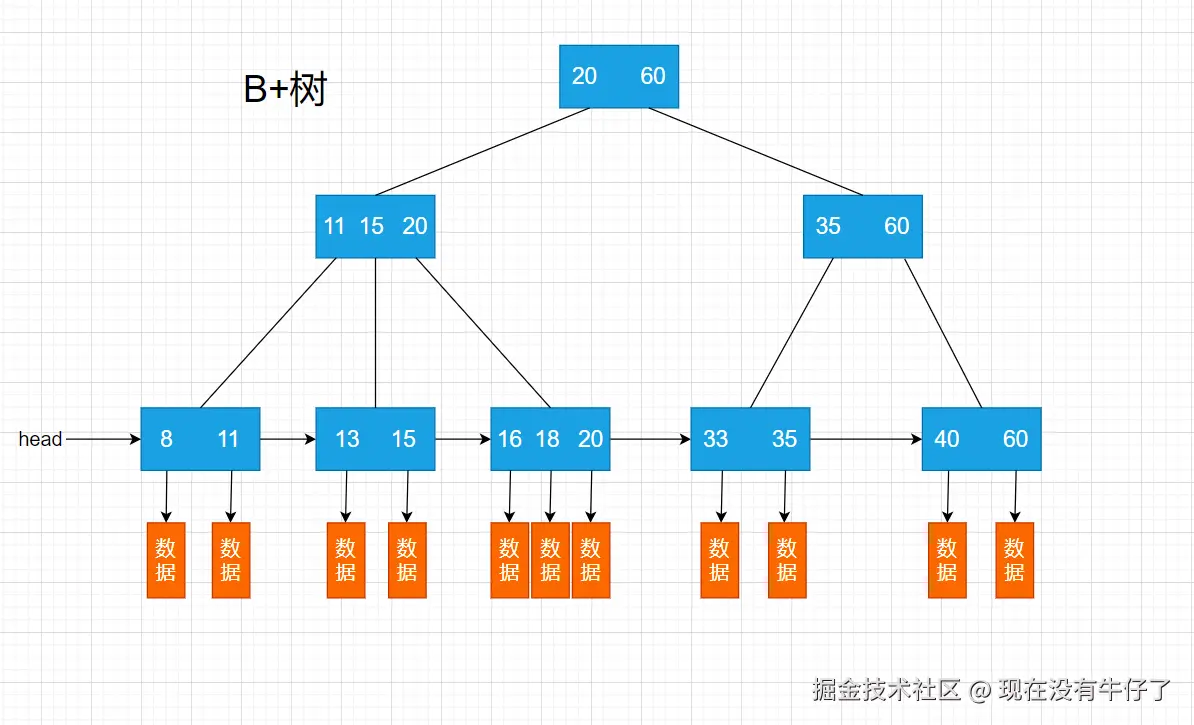
B+树的性能优势
- 对于以往的二叉树来说,一个节点下最多只能存储两个子节点,如果数据量非常大,树的结构就会很高,而树的高度往往对应磁盘I/O的次数,所以效率就会降低。B+树的节点下可以有很多个子节点,这意味着它可以用非常低的高度存储海量的数据,通常只需要2-4次磁盘I/O就能在上亿数据中定位到目标,极大地减少了耗时的磁盘访问。
- 所有数据记录都只存储在叶子节点上,并且所有叶子节点通过指针形成了一个双向有序链表。这使得范围查询和全表扫描变得无比高效:只需在叶子节点上定位到起点,然后顺着链表遍历即可,不再需要从树的根节点重新回溯。
- 因为所有数据都存储在叶子节点的关系,保证了每一个数据查询的稳定性。
三、索引的创建规则
先创建一个userinfo表,存放10w条用户数据
sql
CREATE TABLE `userinfo` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`gender` tinyint DEFAULT '0',
`domicile` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`phone` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`desc` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
)1. 选择查询频繁的字段作为索引,如查询条件、排序字段或分组字段
1.1. 为查询条件、排序字段创建索引
sql
-- 查询条件、排序字段为id,已经设置主键默认建立索引
-- 为性别字段建立索引
CREATE INDEX idx_user_gender on userinfo (gender)1.2. 创建索引前后查询时间测试
- 测试sql:
select gender from userinfo u group by gender- 创建索引前:0.120s
- 创建索引后:0.047s
2. 使用复合索引,覆盖sql查询的所有返回值
2.1. 创建针对用户名、住址、联系方式的复合索引
sql
-- 创建针对用户名、住址、联系方式的复合索引
create index idx_name_do_phone on userinfo (name,domicile,phone);如果只为一个列建立,但是查询的列有多个,mysql数据库会拿到这个索引key去回表查询出其他的字段;这个时候如果复合索引中包含索要查询的所有字段就不需要回表操作了,所以查询效率就会提高。
3. 如果字段的内容较长,应该使用前缀索引
sql
-- 创建用户描述前缀索引,只索引前5个字符
create index idx_user_desc on userinfo (`desc`(5))四、索引失效的情况
1. 没有遵循复合索引的最左匹配原则
比如,创建复合索引时的顺序是name,domicile,phone,那么查询的时候也要从最左侧的字段顺序查询:select name,domicile,phone from userinfo where id = 8000,否则,索引就会失效。
2. 在索引字段上进行了运算或类型转换
下图中使用explain分析工具得到的索引key为null,表示这条sql的索引失效了。
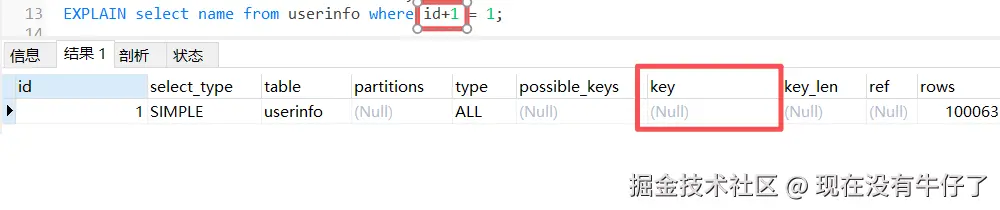
3. 创建了复合索引但是在条件中对复合索引中间的字段使用了范围查询,导致右边的字段索引失效
sql
select name,domicile,phone from userinfo where name = 'test1' and domicile < '地球2' and phone = '13771';上面的这条SQL语句,使用到了name,domicile,phone三个字段的复合索引,但是由于在where条件中,中间的domicile使用了范围查询,这就导致and phone = '13771'中的phone字段索引查询失效。
五、sql分析工具(EXPLAIN)简单介绍
如果一条SQL执行很慢,通常会使用EXPLAIN命令来分析这条SQL的执行情况。
sql
EXPLAIN select * from userinfo; 执行返回的字段中,可以根据key、key_len判断是否命中了索引,通过type可以了解到sql还有没有优化的空间,extra字段会告诉我们是否存在回表的情况。
执行返回的字段中,可以根据key、key_len判断是否命中了索引,通过type可以了解到sql还有没有优化的空间,extra字段会告诉我们是否存在回表的情况。
- key:实际选择的索引。
- key_len:索引的长度。
- extra:Using where表示条件查询,Using index表示避免了回表查询。
- type: 查询类型,一部分取值如下(性能由低到高):
- ALL:全表扫描,性能最差
- index:索引扫描,不需要回表
- range:范围检索
- fulltext:全文索引
- const:只匹配一行
- system:查询只有一条数据的表
六、关于SQL语句的其他优化方案
- 建表时选择合适的字段类型,避免多余空间的占用。
- 使用索引时,要遵循索引的创建原则。
- 编写SQL语句时,避免使用select *;尽量使用union all代替union;减少使用外连接,尽量使用内连接。
七、总结
给数据库做优化,其实就像给一个巨大的图书馆整理书籍,核心目的就是:让你能最快地找到你想要的那本书。索引的B+树结构就像是图书馆的书名记录,如果用户经常按照作者名去找书,那么就应该为作者名字段建立索引;而复合索引就像是图书馆为图书做了国家+年份等粗粒度分类。同时,要学会使用SQL诊断工具,SQL慢了,就用 EXPLAIN 这个命令看一下,它能告诉你数据库是怎么找数据的。
最后,希望本篇文章对您有帮助~