

文章目录
- [4.1 为何重点选择 TensorFlow?](#4.1 为何重点选择 TensorFlow?)
-
- [4.1.1GitHub 活跃度:社区支持碾压级领先](#4.1.1GitHub 活跃度:社区支持碾压级领先)
- 4.1.2求职市场需求:企业首选框架
- [4.2 TensorFlow 的三大核心优势](#4.2 TensorFlow 的三大核心优势)
- [4.3 NLP 技术落地的基石层](#4.3 NLP 技术落地的基石层)
- [4.4 TensorFlow 的桥梁作用](#4.4 TensorFlow 的桥梁作用)
- [4.5 NLP 框架体系的核心演进逻辑](#4.5 NLP 框架体系的核心演进逻辑)
- [4.6 基于场景的框架选型策略](#4.6 基于场景的框架选型策略)
- [4.7 深度学习框架学习建议](#4.7 深度学习框架学习建议)
说完任务分类,我们来框架介绍。在了解了 NLP 的整体概况后,接下来我们来看:当我们编写 NLP 程序或实际运用 NLP 技术时,具体会用到哪些工具框架?
本次要介绍的核心框架主要有三个,分别是scikit-learn(简称 skl) 、Gensim 和 TensorFlow 。需要先说明一下,原文中提到的 "json" 应为表述偏差,实际在 NLP 领域用于训练词向量的主流第三方库是 Gensim,此处已修正,避免误导。
这三个框架的核心用途各有侧重:
-
scikit-learn(skl):主要用于机器学习模型的构建,以及模型评价指标的计算。它是一个出现时间较早、技术生态非常成熟的机器学习库,在传统机器学习任务中应用广泛。
-
Gensim:专门用于 NLP 领域的词向量训练,是该场景下的专属第三方库,操作便捷且效果稳定,是词向量训练的常用工具。
-
TensorFlow:用于构建深度学习模型,也是本次框架介绍的重点内容。
4.1 为何重点选择 TensorFlow?
首先,TensorFlow 由谷歌(Google)开发,出现时间较早,在深度学习框架领域积累深厚。我们可以从两个关键维度来看它的优势:
4.1.1GitHub 活跃度:社区支持碾压级领先
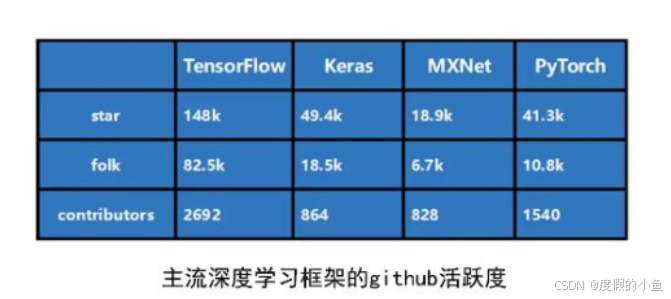
无论是技术架构还是开发者群体,都习惯通过排行榜来判断工具的流行度。从近期 GitHub 的活跃度数据来看,TensorFlow 在深度学习框架中处于碾压其他框架的地位。
目前主流的深度学习框架主要有三个:TensorFlow 、Keras 和 PyTorch(原文中 "pad touch" 为 "PyTorch" 的发音误写,"kras" 为 "Keras" 的拼写误写,此处已修正)。其中,Keras 本质上是在 TensorFlow 基础上封装的高层接口(可以理解为 "套了个壳子"),并非完全独立的底层框架;除此之外,还有一些知名度较低的框架,比如微软推出的 CNTK(原文 "max net" 表述偏差)、已逐渐被淘汰的 Caffe(原文 "cno" 表述偏差),以及国内百度开发的 PaddlePaddle(飞桨)。但从行业主流应用来看,仍以 TensorFlow、Keras、PyTorch 这三者为主。
在这三大框架中,TensorFlow 的高活跃度意味着它拥有极其庞大的社区,而庞大的社区能带来两大核心好处:
-
Debug 更便捷:如果用小众框架(如 CNTK)写程序报错,在中文网站上基本查不到解决方案,即便去国外网站搜索,信息也很有限;但用 TensorFlow 时,无论是中文还是英文社区,都有大量开发者分享的问题解决方案,遇到问题能快速定位并解决。
-
论文模型复现更轻松:对于已发表的深度学习论文,其模型的 TensorFlow 复现版本是最多的。一方面,开发者使用 TensorFlow 的基数大,复现门槛低;另一方面,很多论文作者本身也会选择 TensorFlow 完成实验(不过也有部分科研人员更偏爱 PyTorch,因为它的语法相对简洁,两者在论文复现领域的应用比例大致五五开)。
4.1.2求职市场需求:企业首选框架
学习技术框架的重要目的之一是为了求职,即便未来创业,也需要选择一个主流框架作为团队的核心工具。从美国多家主流招聘网站的岗位需求排行来看,TensorFlow 的提及率 "一枝独秀",也就是说,企业层面非常青睐使用 TensorFlow 的技术人才,掌握它能显著提升求职竞争力。
4.2 TensorFlow 的三大核心优势
TensorFlow 能在众多框架中脱颖而出,核心源于以下三点不可替代的优势:
-
社区庞大:形成 "用得越多→生态越好→用得更多" 的正向循环
庞大的社区是 TensorFlow 最大的优势。开发者越多,就会有更多人贡献教程、解决方案、工具插件,进而吸引更多人使用;而新用户的加入又会进一步丰富社区生态,形成良性循环。我们每一位开发者都是这个社区的受益者 ------ 遇到问题能快速找到答案,学习时能获取海量免费资源。
-
平台支持广泛:全场景适配无压力
作为谷歌开发的框架,TensorFlow 对不同平台的支持非常全面,包括树莓派(嵌入式设备)、安卓(移动端)、Windows(桌面端)、iOS(苹果移动端)等,且每个平台的配套功能都十分完善。虽然目前其他深度学习框架也在逐步扩展平台支持,但从当前成熟度来看,TensorFlow 仍处于领先地位。
-
算法落地能力强:支持分布式训练且易上手
这是 TensorFlow 打动企业的 "大杀器"------ 它能直接支持算法落地,并且可以轻松部署分布式训练。在早期,分布式训练是 TensorFlow 的独家优势;即便现在其他框架也开始支持,但谷歌已将分布式训练功能深度集成到 TensorFlow 中,操作门槛极低,不需要开发者编写复杂的底层代码。
这种特性对两类人群尤其友好:一是初创公司,能快速搭建大规模训练系统,降低技术成本;二是需要做 Demo 演示的开发者,能快速实现模型的工业化部署,提升效率。
在已梳理的 scikit-learn、Gensim、TensorFlow 等经典框架基础上,若要完整解构 NLP 框架体系,还需串联 "经典工具的技术定位" 与 "新一代方案的演进逻辑",明确不同阶段框架的适配场景,避免开发者陷入 "技术迭代即替代" 的认知误区。
4.3 NLP 技术落地的基石层
从技术演进脉络来看,经典框架实则是 NLP 工业化落地的 "基石层",即便在新一代技术兴起的背景下,其在特定场景的价值仍无法被替代。
scikit-learn:轻量级任务的高效解决方案
scikit-learn 作为传统机器学习的代表,虽不直接支持深度学习,但在 NLP 预处理环节仍不可替代 ------ 例如文本特征的 TF-IDF 提取、分类任务的逻辑回归建模等轻量级场景,其低算力消耗、快部署速度的优势,是深度学习框架无法比拟的。对于数据量较小、任务复杂度低的场景(如简单文本分类、关键词匹配),使用 scikit-learn 能以更低的开发成本快速实现需求,无需投入深度学习框架的高算力资源。
Gensim:低资源文本场景的轻量化补充
Gensim 聚焦的词向量训练,虽已被 BERT 等预训练模型的动态词嵌入技术部分覆盖,但在处理低资源文本(如小语种、垂直领域语料)时,其基于 LDA、Word2Vec 的无监督训练能力,仍能以更低成本实现基础语义表征,成为预训练模型的 "轻量化补充方案"。例如在缺乏大规模标注数据的垂直行业(如小众医疗领域、地方方言处理),Gensim 无需复杂的算力支持,即可快速构建基础的文本语义模型,为后续技术优化提供初始支撑。
4.4 TensorFlow 的桥梁作用
TensorFlow 作为经典深度学习框架的核心,并非被新一代技术淘汰,而是通过生态升级成为 "衔接枢纽",实现与新技术的深度融合。
生态升级:适配 Transformer 与预训练模型
近年来兴起的 Transformer 架构、预训练模型(如 BERT、GPT),虽常与 PyTorch 关联,但 TensorFlow 生态通过 TensorFlow Hub(预训练模型库)、TensorFlow Text(NLP 专用处理模块)的升级,已实现与新一代技术的深度融合。例如谷歌推出的 BERT 官方实现版本,同时支持 TensorFlow 与 PyTorch,开发者可直接在 TensorFlow 生态中调用预训练模型,无需重构技术栈。
部署优势:工业级场景的落地保障
在工业级部署中,基于 TensorFlow 训练的预训练模型,可通过 TensorRT 加速、TensorFlow Lite 轻量化,更顺畅地落地到移动端、边缘设备,这正是其 "经典框架" 与 "新一代技术" 兼容的核心价值。相比部分新兴框架在部署环节的适配短板,TensorFlow 凭借成熟的跨平台支持能力,成为企业将大模型、预训练技术落地到实际产品(如智能 APP、嵌入式设备)的首选工具。
4.5 NLP 框架体系的核心演进逻辑
新一代 NLP 技术方案并非独立存在,而是在经典框架基础上的 "能力延伸",二者协同构成完整的技术链路。
技术复用:新一代方案的底层支撑
例如采用 LoRA 技术对大模型进行微调时,若底层框架为 TensorFlow,可直接复用其分布式训练逻辑,无需重构训练流程;在多模态 NLP 任务中,Gensim 提取的文本特征,可与 TensorFlow 处理的图像特征无缝拼接,形成 "经典工具 + 新一代技术" 的协同方案。这种复用性大幅降低了新技术的开发门槛,让开发者无需从零搭建系统。
功能互补:解决不同维度的技术需求
这种 "兼容而非替代" 的演进逻辑,正是 NLP 框架体系的核心特征 ------ 经典工具解决 "基础能力稳定性" 问题(如数据预处理、轻量化建模),新一代方案解决 "复杂任务突破性" 问题(如大模型微调、多模态理解),二者共同构成 NLP 技术落地的完整链路,覆盖从简单需求到复杂场景的全范围应用。
4.6 基于场景的框架选型策略
对开发者而言,理解 NLP 框架体系的最终目的是 "按需选型",避免盲目追逐技术热点而忽视实用价值。
轻量任务选型:优先经典工具组合
处理传统文本分类、简单语义匹配、低资源文本建模等轻量任务时,优先选择 scikit-learn+Gensim 的组合,以更低的算力成本、更快的开发速度实现需求,避免过度依赖复杂的深度学习框架。
复杂场景选型:经典框架 + 新一代技术
构建深度学习模型、对接工业级部署(如移动端应用)时,以 TensorFlow 为核心框架;探索大模型微调、多模态融合等复杂任务时,在 TensorFlow 等经典框架基础上叠加 LoRA、Transformer 等新一代技术模块,既保障技术稳定性,又具备任务突破性。
4.7 深度学习框架学习建议
很多人会纠结 "该学多少个框架",其实无需过度焦虑 ------深度学习框架学会一个核心的即可。
以 TensorFlow 为例,学会它之后,再学习 Keras 和 PyTorch 会非常快。因为这三大框架的核心接口命名高度统一:比如构建卷积神经网络时,2D 卷积层都叫Conv2D(原文 "CN AV 2d""CN v1d" 为拼写误写,正确表述为Conv2D"Conv1D");计算交叉熵损失时,接口名称和核心参数也基本一致。即便有极少数参数表述略有差异,只要看一眼官方文档的说明,就能立刻理解并上手使用。
未来遇到新发表的论文时,只要能看懂论文中的网络框架图(Model 层结构),就能用已经掌握的框架快速复现出来,无需为 "没学过对应框架" 而发愁。
下一章节内容 模型了解