选择合适激活函数
激活函数在神经网络中作用有很多,主要作用是给神经网络提供非线性建模能力。如
果没有激活函数,那么再多层的神经网络也只能处理线性可分问题。常用的激活函数有
sigmoid、tanh、relu、softmax等。它们的图形、表达式、导数等信息如表5-2所示。
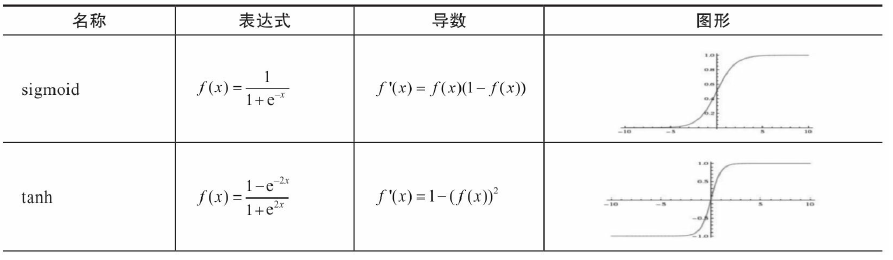
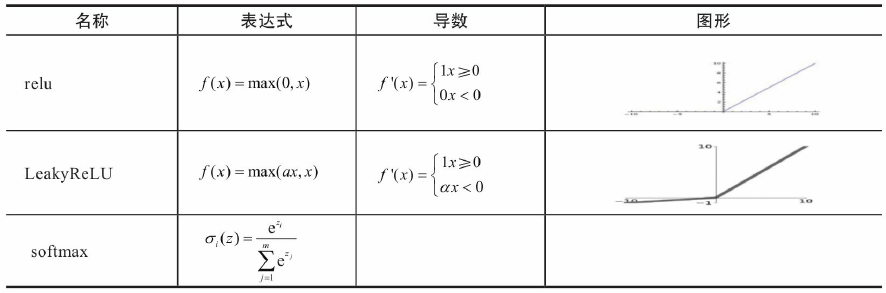
在搭建神经网络时,如何选择激活函数?如果搭建的神经网络层数不多,选择
sigmoid、tanh、relu、softmax都可以;而如果搭建的网络层次较多,那就需要小心,选择
不当就可导致梯度消失问题。此时一般不宜选择sigmoid、tanh激活函数,因它们的导数都
小于1,尤其是sigmoid的导数在0,1/4之间,多层叠加后,根据微积分链式法则,随着层
数增多,导数或偏导将指数级变小。所以层数较多的激活函数需要考虑其导数不宜小于1
当然也不能大于1,大于1将导致梯度爆炸,导数为1最好,而激活函数relu正好满足这个
条件。所以,搭建比较深的神经网络时,一般使用relu激活函数,当然一般神经网络也可
使用。此外,激活函数softmax由于∑lσl(z)=1\sum_{l} \sigma_{l}(z)=1∑lσl(z)=1
,常用于多分类神经网络输出层。
激活函数在PyTorch中使用示例:
python
m = nn.Sigmoid()
input = torch.randn(2)
output = m(input)激活函数输入维度与输出维度是一样的。激活函数的输入维度一般包括批量数N,即
输入数据的维度一般是4维,如(N,C,W,H)。
选择合适的损失函数
损失函数(Loss Function)在机器学习中非常重要,因为训练模型的过程实际就是优
化损失函数的过程。损失函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟
合时添加的正则化项也是加在损失函数后面。损失函数用来衡量模型的好坏,损失函数越
小说明模型和参数越符合训练样本。任何能够衡量模型预测值与真实值之间的差异的函数
都可以叫作损失函数。在机器学习中常用的损失函数有两种,即交叉熵(Cross Entropy)和
均方误差(Mean squared error,MSE),分别对应机器学习中的分类问题和回归问题。
对分类问题的损失函数一般采用交叉熵,交叉熵反应的两个概率分布的距离(不是欧
氏距离)。分类问题进一步又可分为多目标分类,如一次要判断100张图是否包含10种动
物,或单目标分类。
回归问题预测的不是类别,而是一个任意实数。在神经网络中一般只有一个输出节
点,该输出值就是预测值。反应的预测值与实际值之间的距离可以用欧氏距离来表示,所
以对这类问题通常使用均方差作为损失函数,均方差的定义如下:
MSE=∑i=1n(yi−yi′)2n\text{MSE} = \frac{\sum_{i=1}^{n} \left( y_i - y_i' \right)^2}{n} MSE=n∑i=1n(yi−yi′)2
PyTorch中已集成多种损失函数,这里介绍两个经典的损失函数,其他损失函数基本
上是在它们的基础上的变种或延伸。
1.torch.nn.MSELoss
具体格式:
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')计算公式:
ℓ(x,y)=L={l1,l2,...,lN}T,ln=(xn,yn)n \ell(x, y) = L = \left\{ l_1, l_2, \ldots, l_N \right\}^{\mathrm{T}}, \quad l_n = (x_n, y_n)^n ℓ(x,y)=L={l1,l2,...,lN}T,ln=(xn,yn)n
如果参数reduction为非None(缺省值为'mean'),则:
ℓ(x,y)={mean(L),if reduction='mean'sum(L),if reduction='sum' \ell(x, y) = \begin{cases} \text{mean}(L), & \text{if } \text{reduction} = \text{'mean'} \\ \text{sum}(L), & \text{if } \text{reduction} = \text{'sum'} \end{cases} ℓ(x,y)={mean(L),sum(L),if reduction='mean'if reduction='sum'
x和y是任意形状的张量,每个张量都有n个元素,如果reduction取'none',ℓ(x,y)\ell(x,y)ℓ(x,y) 将不是
标量;如果取'sum',则ℓ(x,y)\ell(x,y)ℓ(x,y)只是差平方的和,但不会除以n。
参数说明:
size_average、reduce在以后版本将移除,主要看参数reduction,reduction可以取
none、mean、sum,缺省值为mean。如果size_average、reduce取值,将覆盖reduction的取
值。
代码示例:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(10)
loss=nn.MSELoss(reduction='mean')
input=torch.randn(1,2,requires_grad=True)
print(input)
target=torch.randn(1,2)
print(target)
output=loss(input,target)
print(output)
output.backward()输出结果
tensor([[-0.6014, -1.0122]], requires_grad=True)
tensor([[-0.3023, -1.2277]])
tensor(0.0680, grad_fn=<MseLossBackward0>)2.torch.nn.CrossEntropyLoss
交叉熵损失(Cross-Entropy Loss)又称对数似然损失(Log-likelihood Loss)、对数
损失;二分类时还可称之为逻辑回归损失(Logistic Loss)。在PyTroch里,它不是严格意
义上的交叉熵损失函数,而是先将Input经过softmax激活函数,将向量"归一化"成概率形
式,然后再与target计算严格意义上的交叉熵损失。在多分类任务中,经常采用softmax激
活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的
是向量,并不是概率分布的形式。所以需要softmax激活函数将一个向量进行"归一化"成
概率分布的形式,再采用交叉熵损失函数计算loss。
一般格式:
python
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean计算公式:
loss(x,class)=−log(exp(xclass)∑jexp(xj))=−xclass+log(∑jexp(xj))\text{loss}(x, \text{class}) = -\log\left( \frac{\exp(x\\text{class})}{\sum_j \exp(xj)} \right) = -x\\text{class} + \log\left( \sum_j \exp(xj) \right)loss(x,class)=−log(∑jexp(xj)exp(xclass))=−xclass+log(j∑exp(xj))
符号解释:
- loss(x,class)\text{loss}(x, \text{class})loss(x,class):针对样本 xxx 和类别 class\text{class}class 的损失函数。
- log(⋅)\log(\cdot)log(⋅):自然对数(也可写为 ln(⋅)\ln(\cdot)ln(⋅),但深度学习中常省略底数默认自然对数)。
- exp(⋅)\exp(\cdot)exp(⋅):指数函数(即 e⋅e^{\cdot}e⋅)。
- ∑j\sum_j∑j:对所有类别 jjj 求和(jjj 为遍历所有类别的索引)。
- xclassx\\text{class}xclass:样本 xxx 在"class\text{class}class"类别上的输出(如神经网络最后一层的logit值)。
如果带上权重参数weight,则:
loss(x,class)=weightclass(−xclass+log(∑jexp(xj))) \text{loss}(x, \text{class}) = \text{weight}\\text{class} \left( -x\\text{class} + \log\left( \sum_j \exp(xj) \right) \right) loss(x,class)=weightclass(−xclass+log(j∑exp(xj)))
代码示例
python
import torch
import torch.nn as nn
torch.manual_seed(10)
loss=nn.CrossEntropyLoss()
#假设类别数为5
input=torch.randn(3,5,requires_grad=True)
#每个样本对应的类别索引,其值范围为[0,4]
target=torch.empty(3,dtype=torch.long).random_(5)
output=loss(input,target)
output.backward()