你是否有过这样的经历?问AI一个问题,它能自信满满地回答,但你稍微验证一下就发现------"这个回答完全是编造的"。没错,这就是当今大模型的典型特点:看似无所不知,实则可能自信地胡说八道。
这个问题该怎么解决?今天我们就来聊聊如何给AI装上一个"超级大脑"------通过RAG(检索增强生成)系统中的核心技术:信息检索!
当AI成为了"自信的编造者"
想象一下,你有一个AI购物助手小明,它知道很多商品信息,但有时会编造不存在的产品细节和评价。

图1:没有检索能力的AI助手对话流程
小明的问题很明显:它需要一种方法来"有据可依",而不是凭空编造信息。这正是信息检索技术要解决的核心问题!
传统检索方法:给AI装上"事实核查器"
要解决小明的编造事实问题,我们先来尝试最简单的方案------传统检索方法。
TF-IDF:不是"天府-国际大范坊"
TF-IDF听起来像某个高大上的购物中心名字,但其实是"词频-逆文档频率"的缩写。它的工作原理特别像一个挑剔的书评人:
- 这个词在文章里出现得多吗?(TF高)
- 这个词是不是到处都有?(IDF低)
想象小明在查找"iPhone 13"时:
- "iPhone"在某个商品描述中出现了5次(TF高)
- 但"iPhone"在所有手机商品描述中都很常见(IDF低)
- "13"出现2次(TF中等)
- "13"只在特定iPhone型号描述中出现(IDF中等)
结果:"13"这个数字比"iPhone"更能帮助定位到具体商品!

图2:TF-IDF检索流程
BM25:TF-IDF的"健身增强版"
如果说TF-IDF是普通人,那BM25就是经过健身的肌肉型选手。它基本原理差不多,但增加了两个"健身器材":
- k1参数:控制词频增长的"肌肉饱和度"(词出现得再多也不会无限加分)
- b参数:考虑文档长短的"体重调节器"(长文档中出现3次和短文档中出现3次,意义不同)
小明用了BM25后,不会再因为某个商品描述特别长,里面提到了很多次"Nike"就盲目推荐了。
倒排索引:图书馆的目录卡片
倒排索引听起来像是"倒着排",但其实是"从词到文档"的索引。
假设没有倒排索引,小明每次都要从头到尾读一遍所有商品信息------这就像你想知道图书馆里有没有关于"猫"的书,必须一本本翻过去看标题。
有了倒排索引,小明可以直接查:
rust
"iPhone" -> 商品1, 商品3, 商品7...
"13" -> 商品3, 商品12...
"Pro" -> 商品2, 商品3, 商品9...这样一来,当用户说"我想买iPhone 13 Pro",小明立刻就能找到商品3!
向量检索技术:当AI学会了"意会"
传统检索方法有个大问题:它们只懂"字面意思",不懂"弦外之音"。
比如用户问:"有没有适合马拉松的跑鞋?" 小明用TF-IDF查了半天:"对不起,没找到含'马拉松'的商品..."
这时候,向量检索技术闪亮登场!
稠密向量:把词变成"意义云团"
向量嵌入技术就像是给每个词、每句话都安装了一个"意义雷达",可以探测到表面文字之下的深层含义。
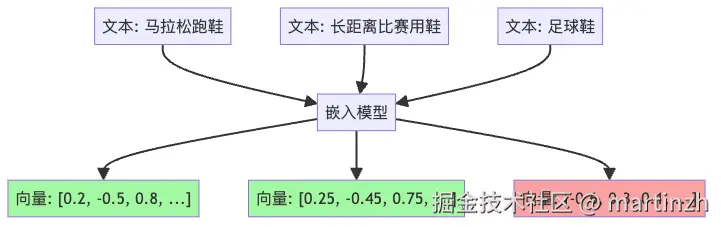
图3:文本向量化及相似度示意图
通过这种方式,即使商品描述中没有"马拉松"这个词,但如果它提到了"长跑"、"耐力"、"缓震"等概念,小明也能理解这可能是适合马拉松的鞋!
嵌入模型:AI的"语义理解器"
嵌入模型就像是各种各样的"翻译官",它们把人类语言翻译成AI能理解的数学表示:
- OpenAI的嵌入模型:像是英语外教,英文理解特别好
- BGE/text2vec:像是中文老师,对中文特别拿手
- 领域特定模型:就像各个学科的专业教授
小明根据自己的需求,可以选择最适合的"翻译官"。
向量数据库:高维空间的"邻居查找器"
当所有商品信息都变成了向量,小明面临新问题:如何从上百万个向量中快速找到最相似的?
这时候,向量数据库登场了!它们就像是专门设计的"高维空间导航仪":
- Chroma:小巧灵活,适合初创公司用的小电动
- Pinecone:云端服务,像是随叫随到的网约车
- Milvus:功能全面,堪比商务MPV
这些向量数据库使用了各种近似最近邻(ANN)算法,如HNSW、IVF等,让小明能在毫秒级时间内找到"意义相似"的商品。
混合检索策略:双剑合璧
小明用了向量检索后,发现了新问题:
- 用户:"我想买那款限量版的联名AJ1"
- 小明:(用向量检索)"这是几款篮球鞋..."(没找到"限量版"和"联名")
看来,两种检索方法各有优劣:
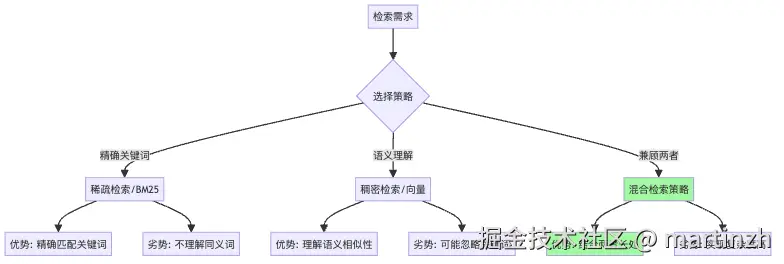
图4:不同检索策略的对比
聪明的小明决定两种方法一起用!这就是混合检索策略:
- 用BM25找出包含关键词"限量版"、"联名"、"AJ1"的商品
- 用向量检索找出语义上与查询相近的商品
- 通过某种融合策略(加权平均、排序融合等)合并结果
这样,小明就能既精确又全面地理解用户意图了!
实战应用:让你的AI助手变得更聪明
如果你想给自己的AI助手装上这套"记忆增强系统",这里有几个实用建议:
小型项目方案
如果你只是做个简单的个人助手,可以这样搭建:
- 文档处理:简单的文本分割
- 检索方法:TF-IDF + 基础向量检索
- 向量数据库:Chroma(轻量级)
- 模型选择:OpenAI的嵌入模型
代码实现起来可能只需要100行左右!
中大型项目方案
如果你要做企业级应用,建议这样配置:
- 文档处理:分层分块策略
- 检索方法:BM25 + 先进向量检索
- 向量数据库:Milvus/Weaviate(企业级)
- 模型选择:领域微调的嵌入模型
- 额外优化:查询重写、重排序
总结:为什么信息检索是AI"超级大脑"的关键?
回到开头的问题:为什么信息检索技术能够成为改变RAG系统游戏规则的"超级大脑"?
因为RAG的核心思想就是让AI能够"记住"和"查阅"大量信息,而不是把所有信息都塞进模型参数里。信息检索就像是给AI装上了一个无限容量的外置大脑,让它能够:
- 访问最新信息(不受训练数据时间限制)
- 查阅专业领域知识(不受通用训练的局限)
- 引用准确来源(而不是"幻觉")
正如我们的购物助手小明,有了这个"超级大脑",它就能在记住商品细节的同时,理解用户真正的需求,提供既准确又贴心的服务。信息检索技术从根本上改变了AI的运作规则,让有限的模型拥有了无限的知识获取能力。
下次当你的AI助手说"我记不起来了",别急着责怪它------它只是缺少了这个强大的"超级大脑"!装上它,规则就变了。