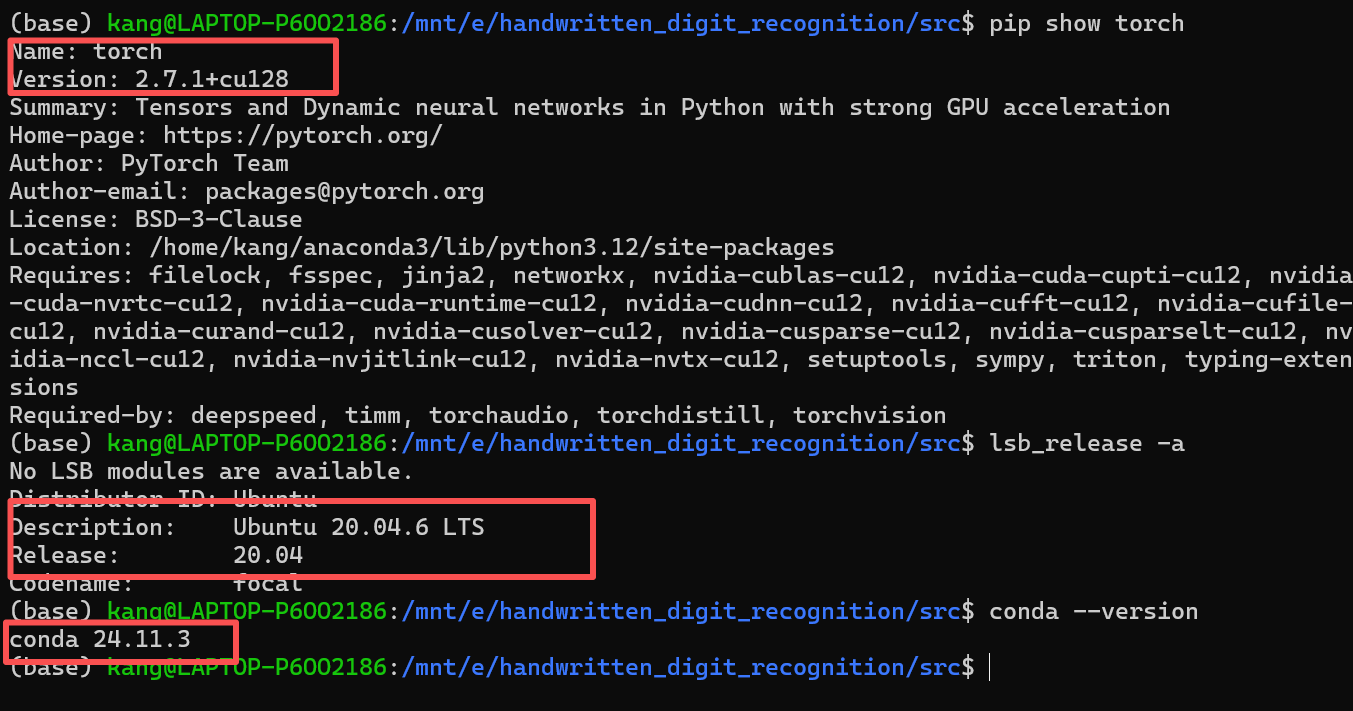
要使用这些数据集 ImageNet iNaturalist 2018 Places-LT 以及 ResNet-152 网络做长尾图像训练,目前租云服务器,需要什么样的配置?
在使用 ImageNet、iNaturalist 2018、Places - LT 这些大型数据集以及 ResNet - 152 网络进行长尾图像训练时,对云服务器的配置有较高要求,以下是详细的配置建议:
处理器(CPU)
- 核心数量:至少需要 16 核及以上的 CPU,多核处理器可以在数据预处理、多线程任务等方面发挥重要作用,加快数据处理速度。例如,在对大规模图像数据进行批量加载、图像裁剪、归一化等操作时,多核 CPU 能够并行处理,提高效率。
- 主频:CPU 主频建议在 3.0 GHz 及以上,较高的主频可以保证单个核心的计算能力,快速处理复杂的计算任务。
内存(RAM)
- 至少需要 128GB 的内存。这些大型数据集在加载到内存中进行训练时会占用大量空间,同时,ResNet - 152 网络在运行过程中也需要一定的内存来存储中间计算结果。如果内存不足,可能会导致数据频繁在内存和磁盘之间交换,严重影响训练速度。
存储(磁盘)
- 容量:至少需要 1TB 的可用磁盘空间。ImageNet、iNaturalist 2018 和 Places - LT 数据集本身就占据较大的存储空间,而且在训练过程中还会生成一些日志文件、模型检查点等数据。
- 类型:建议使用固态硬盘(SSD),SSD 的读写速度远高于传统的机械硬盘(HDD),可以大大减少数据读取和写入的时间,提高训练效率。
显卡(GPU)
- 数量:至少 4 张 NVIDIA GPU。ResNet - 152 是一个深度卷积神经网络,模型参数较多,训练时计算量巨大,多张 GPU 可以进行并行计算,显著加速训练过程。
- 型号:推荐使用 NVIDIA V100 或 A100 这种高性能的显卡。NVIDIA V100 具有强大的计算能力和高带宽显存,能够高效地处理卷积运算等操作;NVIDIA A100 则在性能上更上一层楼,采用了先进的架构和技术,能够进一步提高训练速度。
- 显存:每张 GPU 的显存至少为 32GB。在处理大规模图像数据和复杂的网络结构时,足够的显存可以避免因显存不足而导致的训练中断或性能下降。
网络
- 建议使用高速稳定的网络连接,带宽至少为 1Gbps。在训练过程中,可能需要从远程存储或数据中心下载数据集、上传模型等操作,高速网络可以减少数据传输时间,提高整体效率。
其他
- 确保云服务器支持 CUDA 和 cuDNN,这两个工具可以加速基于 NVIDIA GPU 的深度学习计算。同时,安装合适版本的深度学习框架,如 PyTorch 或 TensorFlow。
Pycham