GSFix3D: Diffusion-Guided Repair of Novel Views in Gaussian Splatting
论文目标
解决新视角合成artifacts问题。
现有方法的特点与不足
- 密集视角重建日趋可靠,但在约束不足的区域,新视角渲染仍容易出现伪影。
- 既往研究主要集中于稀疏视角设置,此类质量退化现象在该环境下更为明显。
- 已有方法的提出了一种欺骗性扩散模型,该模型可优化少视角重建生成的新视角渲染,并利用不确定性度量来提升一致性。RI3D采用两个独立的扩散模型分别修复可见区域和补全缺失区域,而我们的方法将这些任务整合到单一模型中。为提升时间连贯性,多种方法采用视频扩散模型。3DGS-Enhancer率先在大规模低质量-高质量图像配对数据集上训练视频扩散模型;GenFusion36通过模拟常见视角相关伪影的掩码策略,在易产生伪影的RGB-D视频上微调视频扩散模型以实现内容感知的外绘修复;而相关方法则采用免训练的场景接地引导机制来驱动视频扩散模型实现时序一致的合成。
- 尽管成果显著,现有的方法严重依赖定制化的预处理步骤来引导初始重建,并需要精心策划的数据集才能有效训练扩散模型。
新方法的思路与框架
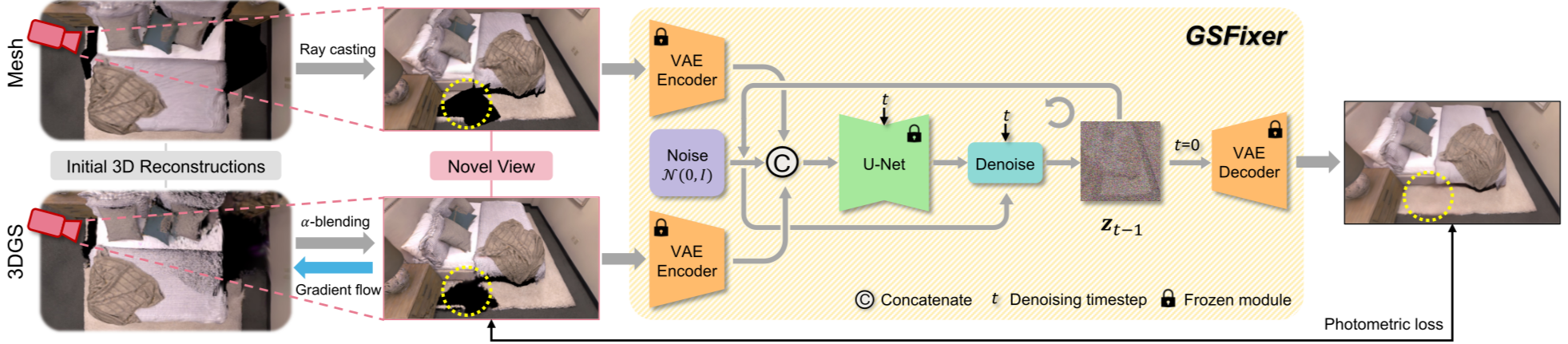
上图清晰地展示了GSFix3D的系统概览。给定一个初始的3DGS重建(以及一个辅助的Mesh网格),系统首先渲染出带有瑕疵的新视角图像。然后,这些图像作为条件输入被送入核心组件GSFixer。GSFixer通过逆向扩散过程,生成一张移除了伪影并补全了缺失区域的修复图像。最后,这张高质量的2D图像被用作"教师",通过光度损失(photometric loss)指导3DGS表示进行优化,从而将2D的修复成果固化到3D场景中。
具体实现
GSFix3D 是一个新颖的框架,旨在增强基于 3D 高斯分布 (3DGS) 重建渲染的全新视图的视觉保真度,尤其是在约束不足的区域或极端视角下,伪影和不完整的几何形状往往会降低图像质量。它解决了NVS非常关键的两个问题:
- 基于优化的 3D 表示的局限性(这些表示严重依赖于密集的观测数据)
- 2D 扩散模型缺乏 3D 感知能力的问题
GSFix3D 的核心是GSFixer,这是一个基于预训练的 Stable Diffusion v2 的潜在扩散模型,并通过定制协议进行了微调。该协议使 GSFixer 能够提取特定场景的先验信息,建模伪影模式,并获得强大的修复能力。该框架的工作原理是:
- 首先从初始 3DGS 重建中渲染新的视角图像,图像存在带瑕疵的伪影。
- 伪影图像作为条件输入到核心组件GSFixer,GSFixer 通过移除伪影和补充缺失内容来优化这些图像。最后,这些增强的图像被视为"教师",并被提升回 3DGS 表示,以提高底层重建的一致性和质量。
GSFixer 的微调协议被表述为如下的条件生成问题:
其中, 是真实 RGB 图像,
是 3DGS 表示渲染得到的图像,并且
是通过网格表示渲染的。这种双重调节策略充分利用了 3DGS(照片级真实感外观)和传统网格重建(在约束不足的区域提供连贯的几何结构和更强的空间先验)的互补优势。借助这两者的互补优势,提供给扩散模型能有更为丰富的纹理信息。
其中,**网格图是通过在线 RGB-D 映射系统 (GSFusion)**实时获取的
该网络架构利用冻结的变分自编码器 (VAE) 将所有图像编码到潜在空间。对于给定图像,其潜在编码表示为:
这产生了一个潜在三联体,标准去噪扩散概率模型 (DDPM) 公式用于训练条件 U-Net。对真值的潜在表示(无噪声),
,逐渐添加噪声:
其中,是标准高斯噪声,而
是噪声调度系数的累积乘积。条件U-Net
经过训练可以预测这种噪声
,相应的最小化 DDPM 优化目标如下:
其中,是预测噪声。U-Net 的输入是
, 为了适应增加的通道数,U-Net 的第一层通过复制原始权重并将值除以三进行扩展,同时保留预训练模型的初始化。
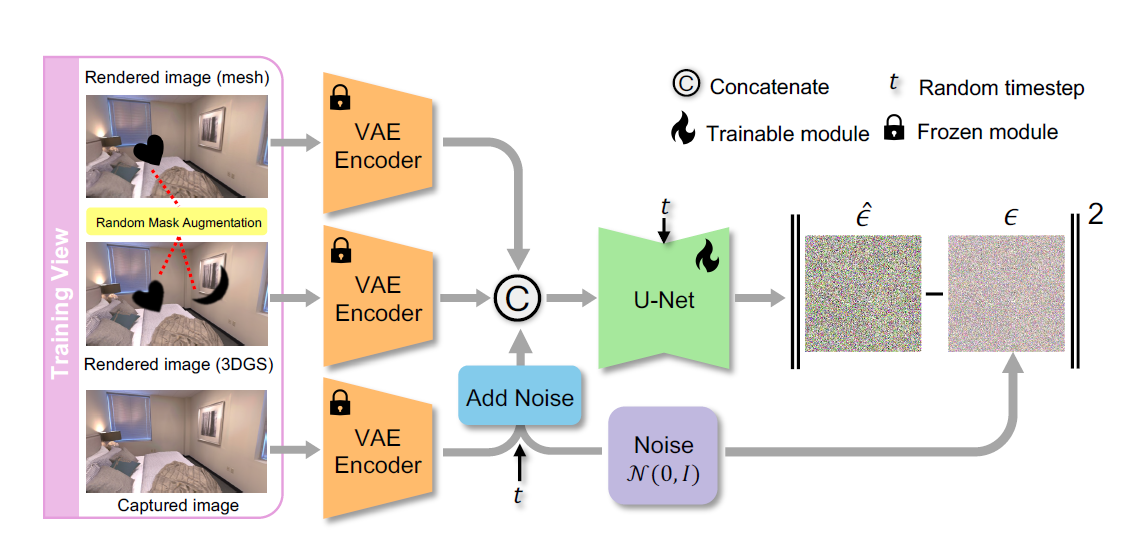
论文的核心部分 在于引入了一种名为随机掩码增强的关键数据增强策略,使 GSFixer 能够修复缺失区域,这些区域在新视角下通常呈现为黑洞。对于每个训练三元组,随机选择一个语义掩码(基于真实图像掩码)。
该掩码以两种方式应用:
- 将相同的掩码叠加在两个图像上
上模拟遮挡
- 另外应用一个独立的mask,用高斯滤波器稍微模糊,仅用于
推理过程中 ,微调后的 U-Net 参数被冻结。新的视图图像从网格和 3DGS 表示中渲染出来,并编码成潜在向量. 目标图像潜在表示
初始化为标准高斯噪声。它们级联起来如下:
使用确定性去噪扩散隐式模型 (DDIM) 方案,对 迭代去噪生成无噪图像的各时间步更新如下:
,
其中无噪图像的潜在状态 估计为:
.
最终的输出图像 使用 VAE 解码器
解码
得到。
GSFix3D的最后阶段将修复后的图像蒸馏回 3DGS 表示。利用 3DGS 的可微性,通过最小化修复图像与初始 3DGS 重建之间的光度损失,进一步优化初始 3DGS 重建的参数。以及渲染的图像
:
启用自适应密度控制,并将修复后的视图及其姿态附加到原始数据集中以进行进一步优化,以减少不一致性并提高全局一致性。
在 ScanNet++ 和 Replica 数据集上的实验表明,GSFix3D 在新型视图修复方面达到了最佳性能,并持续超越 DIFIX 和 DIFIX-ref 等基于扩散的现有方法。这是在小型合成数据集上进行初始预训练后,仅需极少的场景特定微调(在单个消费级 GPU 上仅需几个小时)即可实现的。
消融研究证实了双输入条件反射的有效性以及随机掩模增强在提升修复能力方面的关键作用。在自采集船舶数据和室外场景(使用 Gaussian-LIC 的 FAST-LIVO 数据集)上进行的真实测试进一步验证了 GSFix3D 对潜在姿态误差的稳健性,以及其对各种重建流程和挑战性场景的适应性。