标题:TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
作者:Haomiao Ni、Bernhard Egger、Suhas Lohit、Anoop Cherian、Ye Wang、Toshiaki Koike-Akino、Sharon X. Huang、Tim K. Marks
单位:1. 美国宾夕法尼亚州立大学(The Pennsylvania State University, USA);2. 德国埃尔朗根 - 纽伦堡弗里德里希 - 亚历山大大学(Friedrich-Alexander-Universit¨at Erlangen-N¨urnberg, Germany);3. 美国三菱电机研究实验室(Mitsubishi Electric Research Laboratories (MERL), USA)
发表:CVPR 2024
论文链接 :https://arxiv.org/pdf/2404.16306
项目链接 :https://merl.com/demos/TI2V-Zero
代码链接:暂无
关键词:文本条件图像到视频生成(TI2V)、零样本学习(Zero-Shot Learning)、扩散模型(Diffusion Models)、预训练文本到视频模型(Pretrained Text-to-Video Models)、时序连贯性(Temporal Continuity)、重复 - 滑动策略(Repeat-and-Slide Strategy)、DDPM 逆过程(DDPM Inversion)、重采样(Resampling)
在文本条件图像到视频(TI2V)生成领域,如何让模型在不额外训练的前提下,根据单张图像和文本指令生成时序连贯、细节保真的视频,一直是研究难点。传统方法往往依赖大规模视频 - 文本数据集训练,或需设计复杂的图像 - 文本融合模块,导致通用性和效率受限。本文精读的CVPR 2024论文《TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models》,提出了一种突破性的零样本解决方案,无需微调或引入外部模块,仅通过调制预训练 T2V 扩散模型的采样过程,即可实现图像引导的视频生成。
一、研究背景与问题定义
1.1 任务背景:TI2V 的核心需求
文本条件图像到视频生成(TI2V)的目标是:给定一张初始图像(如 "微笑的女性")和文本描述
(如 "女性正在喝水"),合成一段包含M个新帧的视频
,要求视频既符合文本语义,又与初始图像的视觉细节(如人物身份、背景)保持一致。
TI2V 在艺术创作、数据增强、影视特效等领域具有重要应用,但现有方法存在两大关键问题:
- 高训练成本:多数方法(如 MAGE、DragNUWA)需在大规模视频 - 文本数据集上进行耗时的训练,且依赖定制化网络结构以支持图像 - 文本联合条件;
- 泛化性受限:部分方法(如 DynamicCrafter)虽基于预训练 T2V 模型,但仍需训练额外的图像编码模块,无法实现 "零样本" 适配任意图像。
1.2 核心挑战
TI2V 任务的核心挑战在于时序连贯性 与视觉细节保真的平衡:
- 预训练 T2V 模型的时序注意力机制通常依赖自身生成的帧间信息,难以主动利用外部输入的初始图像;
- 直接用随机高斯噪声初始化新帧生成,易导致帧间运动不连贯、细节丢失(如初始图像中的人物发型、背景物体在后续帧中消失);
- 零样本场景下,无法通过训练调整模型参数,需仅通过采样过程调制实现图像引导。
1.3 研究目标
TI2V-Zero 的核心目标是:基于预训练 T2V 扩散模型,无需任何优化、微调或外部模块,实现零样本 TI2V 生成,同时保证视频的时序连贯性和视觉细节一致性。
二、相关工作梳理
为凸显 TI2V-Zero 的创新点,需先明确其在现有研究中的定位,现有相关工作主要有两类:
2.1 条件图像到视频生成(TI2V)
传统 TI2V 方法可分为 "训练依赖型" 和 "部分依赖预训练型":
- 训练依赖型:如 MAGE(2022)通过 3D 轴向 Transformer 存储 "外观 - 运动对齐表示",DragNUWA(2023)设计轨迹采样器和多尺度融合模块,但均需在视频 - 文本数据集上从头训练,成本高;
- 部分依赖预训练型:如 DynamicCrafter(2023)基于预训练 T2V 模型 VideoCrafter,但需额外训练 "图像编码网络" 将图像投影到文本对齐空间,并添加双交叉注意力层融合信息,仍未实现 "零样本"。
TI2V-Zero 的差异在于:完全不依赖任何额外训练,仅通过调制预训练模型的采样过程实现图像引导。
2.2 扩散基础模型的适配
扩散模型(DM)在图像(如 Stable Diffusion)和视频(如 ModelScopeT2V、VideoCrafter)生成中已取得成功,其核心优势是可通过 "知识迁移" 适配下游任务。现有适配方向包括:
- 图像任务:个性化生成(Textual Inversion)、图像编辑(Repaint);
- 视频任务:视频编辑(FateZero)、视频生成(AnimateDiff)。
但针对T2V 模型的零样本图像引导适配,现有研究仍属空白。TI2V-Zero 首次探索了 "仅通过采样过程调制" 的适配方式,无需修改模型结构或训练参数。
三、方法详解:TI2V-Zero 的核心设计
TI2V-Zero 基于预训练 T2V 扩散模型(本文选用 ModelScopeT2V),通过三大核心模块解决零样本 TI2V 的挑战:"重复 - 滑动" 策略 (Repeat-and-Slide)、DDPM 逆过程初始化 (DDPM Inversion)、重采样技术(Resampling)。在展开前,需先明确预训练 T2V 模型的基础结构。
3.1 基础:预训练 T2V 扩散模型(ModelScopeT2V)
ModelScopeT2V 是一种 ** latent 视频扩散模型 **,结构与 Stable Diffusion 类似,核心包括三部分:
- 帧自动编码器(Encoder/Decoder):
- 编码器
:将像素空间的帧
- 解码器D:将 latent
- 编码器
- 3D 去噪 U-Net(
- 核心模块,负责在 latent 空间进行扩散去噪,包含初始块、下采样块、时空块(捕捉空间 - 时间依赖)、上采样块;
- 时空块由 2D 空间卷积、1D 时间卷积、2D 空间注意力、1D 时间注意力组成;
- 文本条件机制:
- 用 CLIP 模型将文本
- 在 U-Net 的空间注意力层中,将
- 采用无分类器引导(Classifier-Free Guidance) :训练时以固定概率将文本嵌入替换为 "空标签",采样时通过如下公式增强文本引导强度:
- 用 CLIP 模型将文本
3.2 基线方法:基于替换的图像引导(Replacing-based Baseline)
为凸显核心设计的必要性,论文先提出了一种直观的基线方法,再分析其缺陷:
- 思路 :在扩散逆过程的每一步,将当前 latent 序列
- 缺陷:如图 3 所示,基线方法生成的视频与初始图像完全脱节(如 "骑马" 任务中,生成帧的人物与初始图像人物无关)。原因是:预训练模型的时序注意力更倾向于 "同类来源" 的 latent(即模型自身生成的 latent),而忽略 "外部来源" 的初始图像 latent,导致帧间一致性丢失。

注:红色框为给定初始图像。基线方法(Replacing)仅在 "单帧预测"(已知所有其他帧,预测缺失帧)中有效,在 TI2V 和视频补全任务中完全失效;TI2V-Zero 则可生成时序连贯的视频。
3.3 核心设计 1:"重复 - 滑动" 策略(Repeat-and-Slide)
针对基线方法的缺陷,"重复 - 滑动" 策略通过强制时序注意力仅依赖初始图像及已生成帧,解决 "外部 latent 被忽略" 的问题,核心分为两步:
步骤 1:构建初始 Latent 队列
- 初始阶段,仅有一张初始图像
- 队列
步骤 2:帧生成与队列滑动
- 逐帧生成 :每次扩散逆过程仅生成 1 个新帧(而非整个视频),即从队列
- 队列滑动 :生成新帧后,将队列
关键公式
在扩散逆过程的每一步 t,将当前 latent 序列的前 K 帧替换为 "队列
的 t 步带噪 latent"
(
),公式如下:
,此操作强制时序注意力只能从
(外部来源)获取信息,从而保证新生成帧与初始图像的一致性。
3.4 核心设计 2:DDPM 逆过程初始化(DDPM Inversion)
传统扩散模型用随机高斯噪声 ()初始化逆过程,但这会导致新帧与初始图像的时序连贯性差(如图 4 第 2 行,生成帧的人物表情与初始图像完全无关)。

注:红色框为初始图像,文本为 "略带悲伤表情的女性"。从左到右为视频的第 1、6、11、16 帧。可见 "DDPM 逆过程 + 重采样" 的组合效果最优。
论文提出用DDPM 前向过程生成初始噪声,核心思路:
- 对队列
- 用
- 效果:如图 4 第 3 行所示,相比随机初始化,DDPM 逆过程初始化使生成帧与初始图像的表情、细节更一致;定量上,FVD(视频质量指标,越低越好)从 1656.37 降至 339.89(表 1,第1、2行)。
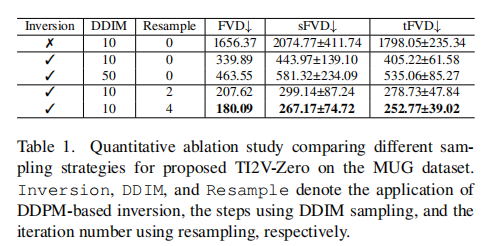
3.5 核心设计 3:重采样技术(Resampling)
为进一步提升帧间运动连贯性和细节保真度,论文引入重采样技术(源自图像修复任务 Repaint),核心操作:
- 在扩散逆过程的每一步 t,完成一次去噪(从
- 作用:通过 "去噪 - 加噪" 的循环,让模型在每一步更充分地对齐 "引导 latent(
- 效果:如图 4 第 5-6 行所示,重采样使生成帧的发型、面部细节更稳定,FVD 从 339.89 进一步降至 180.09(表 1,第2、5行)。
3.6 完整生成流程
结合三大核心设计,TI2V-Zero 的完整生成流程如下(输入:初始图像、文本
、预训练 T2V 模型;输出:M+1 帧视频):
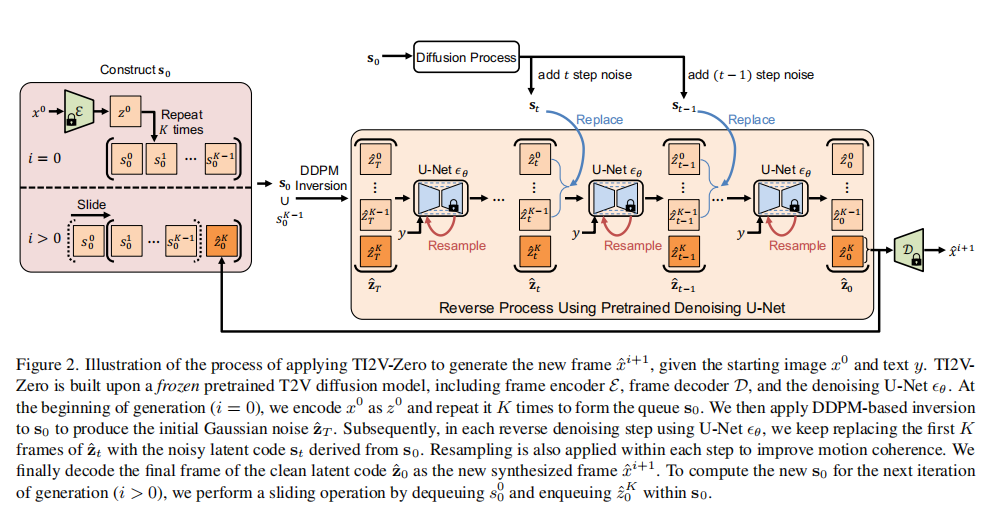
注:左半部分为队列构建与 DDPM 逆过程初始化,右半部分为扩散逆过程与重采样。i=0 为首次生成,i>0 为后续帧生成(队列滑动后)。
- 编码初始图像 :用编码器
- 初始化队列 :将
- 逐帧生成(循环 M 次) :a. DDPM 逆过程初始化 :对
- 输出视频 :合并初始图像
算法伪代码如下:

四、实验验证:全面评估性能
论文在领域特定数据集 (MUG、UCF101)和开放域数据集(OPEN)上进行实验,重新验证了 TI2V-Zero 的有效性,主要对比了基线方法和当前 SOTA 模型 DynamicCrafter。
4.1 实验设置
数据集
| 数据集 | 任务类型 | 数据规模 | 文本模板 | 视频参数 |
|---|---|---|---|---|
| MUG | 面部表情 | 10 个 subject(5 男 5 女),4 种表情(愤怒、开心、悲伤、惊讶) | "A 性别 with the expression of slight {表情} on her/his face." | 16 帧,256×256 |
| UCF101 | 人体动作 | 10 个动作类(如划船、冲浪、化妆),每类 10 个视频 | "A person is 动作." | 16 帧,256×256 |
| OPEN | 开放域 | 10 个文本 prompt(如 "北极极光""威尼斯贡多拉"),每类 100 张初始图像(Stable Diffusion 生成) | 原始文本(如 "A romantic gondola ride through the canals of Venice at sunset.") | 16 帧,256×256 |
评估指标
- FVD(Fréchet Video Distance):衡量生成视频与真实视频的分布差异,越低越好;
- sFVD(Subject-conditioned FVD):衡量同一初始图像下生成视频与真实视频的一致性(主体保真度);
- tFVD(Text-conditioned FVD):衡量同文本下生成视频与真实视频的一致性(语义保真度)。
对比模型
- DynamicCrafter(SOTA):基于 VideoCrafter 预训练模型,需训练额外图像编码模块;
- ModelScopeT2V(基线):仅文本引导的 T2V 模型,无图像引导;
- TI2V-Zero(无重采样):仅含 "重复 - 滑动" 和 DDPM 逆过程,无重采样;
- TI2V-Zero(有重采样):完整版本。
4.2 核心实验结果
1. 领域特定数据集性能(MUG & UCF101)

表 3 展示了各模型在 MUG 和 UCF101 上的定量对比,核心结论:
- TI2V-Zero(有重采样)在所有指标上大幅优于 DynamicCrafter 和 ModelScopeT2V:
- MUG 上,FVD 从 DynamicCrafter 的 1094.72 降至 180.09,sFVD 从 1359.86 降至 267.17(主体细节更保真);
- UCF101 上,FVD 从 DynamicCrafter 的 589.59 降至 477.19,tFVD 从 1540.02 降至 1306.75(动作语义更一致);
- 重采样技术的增益显著:TI2V-Zero(有重采样)比(无重采样)在 MUG 上 FVD 降低 47%,证明其对细节和连贯性的提升。
2. 开放域数据集性能(OPEN)
由于开放域无真实视频作为 ground truth,论文通过定性对比验证性能(图 5):
- DynamicCrafter:难以保留初始图像细节(如 "威尼斯贡多拉" 中,生成帧的贡多拉颜色与初始图像不符),运动多样性差;
- TI2V-Zero(有重采样):精准保留初始图像的视觉特征(如极光的颜色、贡多拉的形状),且运动连贯(如极光的流动、贡多拉的前进方向稳定)。

注:红色框为初始图像,从左到右为视频的第 1、6、11、16 帧。TI2V-Zero(有重采样)在所有场景下均优于 DynamicCrafter 和无重采样版本。
3. 初始图像来源的影响(UCF101)
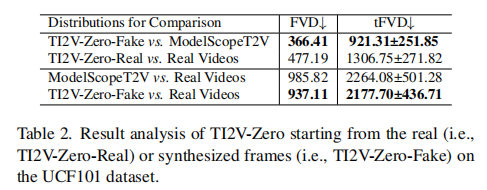
论文进一步分析 "初始图像是真实图像还是合成图像" 对性能的影响(表 2):
- TI2V-Zero-Real:初始图像为 UCF101 的真实帧;
- TI2V-Zero-Fake:初始图像为 ModelScopeT2V 生成的合成帧;
- 结论:TI2V-Zero-Fake 的 FVD(366.41)优于 TI2V-Zero-Real(477.19),原因是合成初始帧与预训练模型的 latent 分布更匹配;但即便用真实初始帧,TI2V-Zero 仍优于 ModelScopeT2V(FVD 985.82),证明其对初始图像来源的鲁棒性。
4.3 扩展任务验证
TI2V-Zero 的 "队列构建" 机制使其可无缝扩展到其他视频生成任务:
1. 视频补全(Video Infilling)
- 任务:给定视频的部分帧(如奇数帧),补全缺失帧(如偶数帧);
- 方法:将给定帧编码为 latent,构建初始队列\(S_0\),后续帧生成时滑动队列;
- 结果:如图 3 第 6 行所示,补全帧与给定帧的时序和细节一致(如 "骑马" 任务中,补全帧的人物姿势与给定帧连贯)。
2. 长视频生成(Long Video Generation)
- 任务:生成超过 16 帧的视频(如 128 帧);
- 方法:通过 "逐帧生成 + 队列滑动" 的循环,持续扩展视频长度;
- 结果:如图 6 所示,128 帧视频(每 14 帧展示一帧)可稳定保留初始图像的背景细节(如山脉形状),无明显抖动或细节丢失。

注:红色框为初始图像,文本为 "北极极光的迷人景象"。展示的是第 0、14、28、...、112 帧,可见背景山脉和极光效果始终连贯。
五、局限性与未来方向
5.1 现有局限性
- 依赖预训练模型能力:TI2V-Zero 的生成质量受限于预训练 T2V 模型(如 ModelScopeT2V),若预模型难以生成复杂动作(如舞蹈),TI2V-Zero 也无法突破;
- 生成质量缺陷:部分视频存在模糊或闪烁 artifacts,尤其在快速运动场景(如 "冲浪");
- 推理速度慢:逐帧生成需为每个帧单独运行完整扩散过程,16 帧视频在 Quadro RTX 6000 上需约 24.7 秒,慢于 DynamicCrafter(155 秒 / 16 帧,但需注意 TI2V-Zero 无需训练)。
5.2 未来研究方向
- 适配更强预训练模型:将 TI2V-Zero 扩展到更先进的 T2V 模型(如 Sora、VideoCrafter2),提升复杂场景和动作的生成能力;
- 后处理优化:引入视频去模糊(Blind Deblurring)、去闪烁(Deflickering)技术,改善生成质量;
- 加速采样:采用快速扩散采样方法(如 DPM-Solver),减少单帧生成时间,提升效率。
六、总结
TI2V-Zero 的核心创新在于 **"零样本" 适配预训练 T2V 扩散模型 **:通过 "重复 - 滑动" 策略强制时序注意力利用初始图像,DDPM 逆过程保证时序连贯性,重采样提升细节保真度,三者结合实现了无需训练的图像引导视频生成。实验证明,其在领域特定和开放域任务上均优于现有 SOTA 模型,且可扩展到视频补全、长视频生成等任务。
该工作为 "扩散模型的零样本条件适配" 提供了新思路 ------ 无需修改模型结构或训练参数,仅通过采样过程调制即可解锁新能力,为后续低资源视频生成研究提供了重要参考。