一、什么是 RLHF?
RLHF(Reinforcement Learning with Human Feedback)是近年来推动大语言模型(LLM)快速发展的关键技术之一。
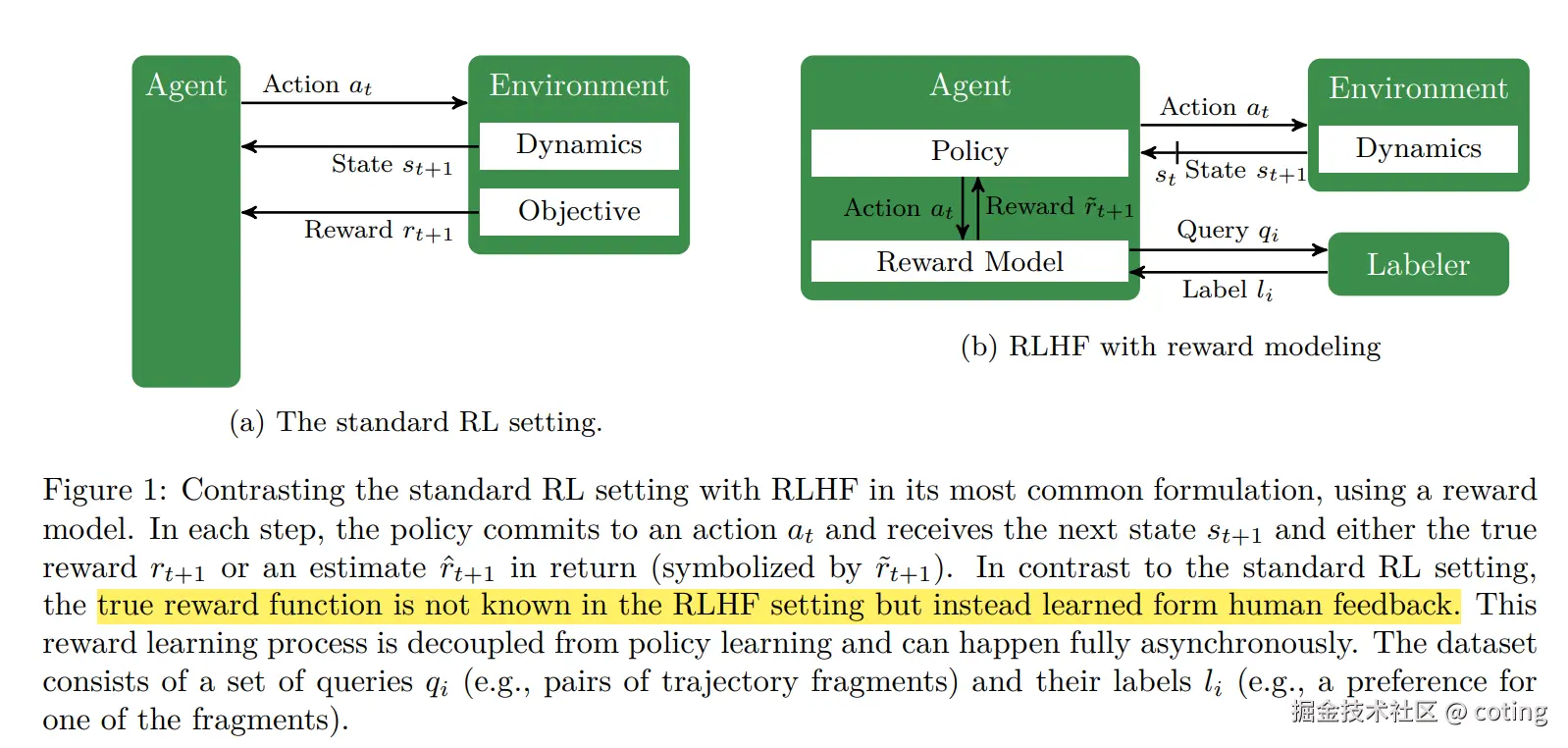
它的核心思想是:利用人类反馈来指导强化学习,从而让模型生成更符合人类偏好的内容 。
通常 RLHF 包含三个阶段:
- 监督微调(SFT):基于已有数据对预训练模型进行有监督学习。
- 奖励模型(Reward Model)训练:利用人类偏好数据训练一个奖励模型,用于衡量模型输出的优劣。
- 强化学习(RL)优化:通过 PPO 等算法,让模型根据奖励信号不断优化。
这种方法已经被广泛应用在 ChatGPT、Claude 等模型的训练中,能够显著提升模型的安全性、对齐性和实用性。
二、实战准备
本文将基于 trl 库实现 RLHF,示例流程包括环境配置、数据准备、奖励模型、PPO 训练和推理测试。
首先安装依赖:
bash
!pip install datasets trl peft accelerate bitsandbytes
!pip install huggingface_hub然后导入必要的库:
python
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead三、数据准备
我们使用自定义数据集,格式类似以下结构:
python
dataset = load_dataset("csv", data_files="data/custom_train.csv")
print(dataset["train"][0])示例样本:
json
{
"prompt": "写一首关于春天的诗",
"response": "春风拂面,百花齐放,燕子呢喃,绿意盎然。"
}这样,每条数据包含 prompt 和 response 字段。
四、模型初始化
这里选择一个基础的语言模型,并加上 Value Head,用于 PPO 训练。
python
model_name = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLMWithValueHead.from_pretrained(model_name)设置训练参数:
python
config = PPOConfig(
batch_size=16,
learning_rate=1.41e-5,
log_with="tensorboard",
project_kwargs={"logging_dir": "./logs"},
)五、奖励模型(Reward Model)
奖励模型用于对模型输出打分。在 Notebook 中,奖励函数采用了一个简单的打分逻辑(例如基于长度、关键字等规则),你也可以换成训练好的 Reward Model。
示例自定义奖励函数:
python
def compute_reward(text):
# 简单示例:鼓励长文本
return len(text.split()) / 50.0在实际应用中,可以加载预训练的 Reward Model,例如基于 BERT 或 RoBERTa,对输出进行更细致的质量判断。
六、PPO 训练
训练流程如下:
python
ppo_trainer = PPOTrainer(
config=config,
model=model,
tokenizer=tokenizer,
dataset=dataset["train"]
)
for batch in dataset["train"]:
query = batch["prompt"]
response = model.generate(**tokenizer(query, return_tensors="pt"))
response_text = tokenizer.decode(response[0], skip_special_tokens=True)
reward = compute_reward(response_text)
ppo_trainer.step([query], [response_text], [reward])训练过程中,模型会不断优化,使得生成结果更符合奖励模型的偏好。
七、推理测试
训练完成后,可以直接使用模型进行推理:
python
prompt = "请写一段关于人工智能的励志短文"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))生成效果会比原始模型更贴近我们设定的目标。
八、总结
通过本文,我们完成了 RLHF 的一个最小可复现流程:
- 准备数据集(Prompt + Response)
- 加载基础模型 + PPO Value Head
- 设计奖励函数(或使用 Reward Model)
- 用 PPO 算法优化模型
- 测试优化后的生成效果