一、背景
在之前的博客 vmlck大于rss的问题分析-CSDN博客 里,我们分析了一个进程的vmlck内存统计值大于rss统计值的问题,里面详细分析了内存统计更新的逻辑及原理,里面的 2.2 问题原因里也提到了进入handle_mm_fault的节奏并不是每个4k页进入一次的,在这篇博客里,我们会展开描述一下。
在这篇博客里的分析过程中会展示一些抓到的堆栈情况,所用到的抓取堆栈的调试程序会在后面的博客里进行介绍,这里聚焦到介绍handle_mm_fault进入节奏的相关细节。有关缺页异常的主要逻辑链的流程含义可以见之前的博客 内存管理之------get_user_pages和pin_user_pages及缺页异常_get user page-CSDN博客 里的第四章。
二、handle_mm_fault并不一定是每个page触发进入一次的
在之前分析 博客 vmlck大于rss的问题分析-CSDN博客 里的问题时,其实是写过一个测试的ko和一个测试的用户态堆栈解析程序来辅助定位问题的,关于这个ko和上层程序的介绍会在后面的博客里进行。
2.1 抓取执行到check_sync_rss_stat时进程的内存统计值状态进行分析
这里先贴出抓到的信息情况,下图里抓的是低版本内核里在每次执行到add_mm_counter/inc_mm_counter/dec_mm_counter时的情况(用了之前的博客 简易的替代tracepoint的调试手段的进一步改进-CSDN博客 里的打桩的方法,抓的执行到check_sync_rss_stat时进行的下图的打印):

从上图可以看到,连续的这几次start到end的区间所触发的handle_mm_fault并不是每个page都触发一次的,上图中的行末的index是指当前处理的这个page在文件里所有的从0开始的page的序号。
可以看到,两次check_sync_rss_stat之间,隔着的index需要时16,而check_sync_rss_stat函数只在handle_mm_fault最一开始被调用,说明同一个文件的两次handle_mm_fault隔了有16个page,如果按照默认的4k为PAGE_SIZE的话,就是64k。
2.2 文件页缺页异常触发节奏的相关原理
从上面 2.1 里我们通过日志观测到文件页的缺页异常并不是一次次page为颗粒度地进入到handle_mm_fault函数里,而是相隔了64k的大小。
事实上,对于文件页的缺页异常,内核里无论是低版本内核还是高版本内核都是有预取逻辑的。
预取逻辑的核心函数是do_fault_around,在do_fault_around函数的注释里也解释其用意:
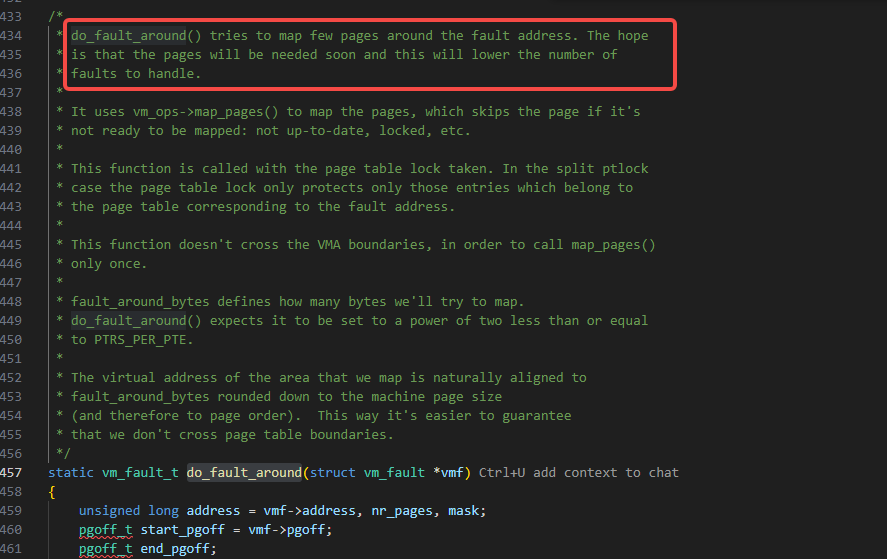
为的是减少缺页异常处理的次数。
相比"文件页的缺页异常并不是一次次page为颗粒度地进入到handle_mm_fault函数里,而是相隔了64k的大小"的说法,更准确的说法是,虽然缺页异常是PAGE_SIZE的粒度进行,但是因为内核有临近预取的机制,所以,在触发了某个文件页的缺页异常之后,后续临近的同一个映射的vma上的文件页也会跟着被触发缺页异常里的逻辑,这些临近的页的缺页的逻辑在同一次handle_mm_fault的调用里完成。
2.2.1 do_fault_around函数里计算出了end_pgoff传入给了vm_ops的map_pages函数
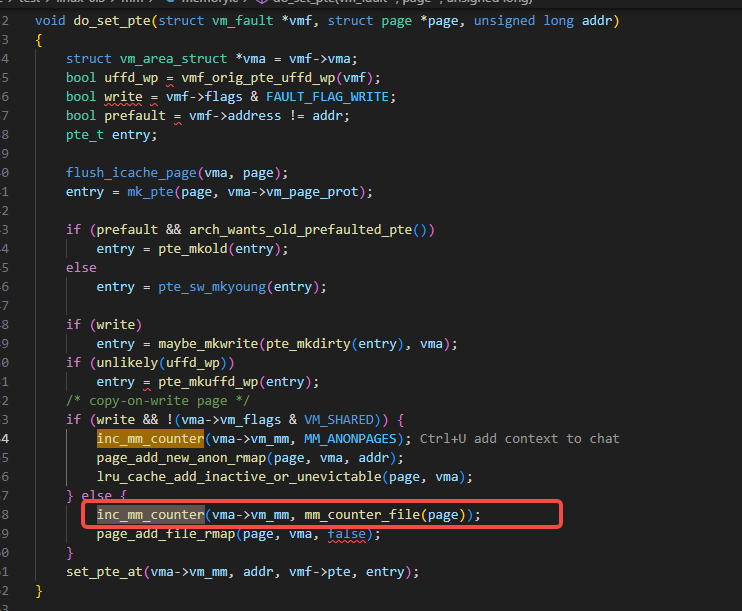
如下图红色框出的代码及注释,do_fault_around函数里,根据PTRS_PER_PTE、vma的映射的大小、系统设置的缺页异常预取大小,三个数值里取最小的值,作为实际预取的大小。
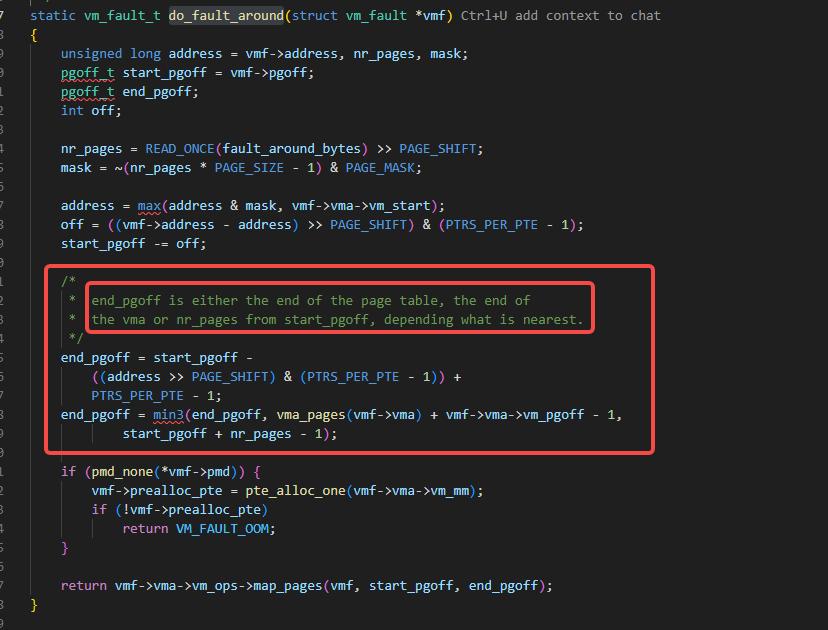
上面代码里的PTRS_PER_PTE可以理解为是一个页表里可以包含多少个条目,4k一个page,页表条目是8字节的话,那就是512个条目。
PTRS_PER_PTE的数值一般就是512,2的9次方,对应于下图里的红色框的9位。

x64下就是512:

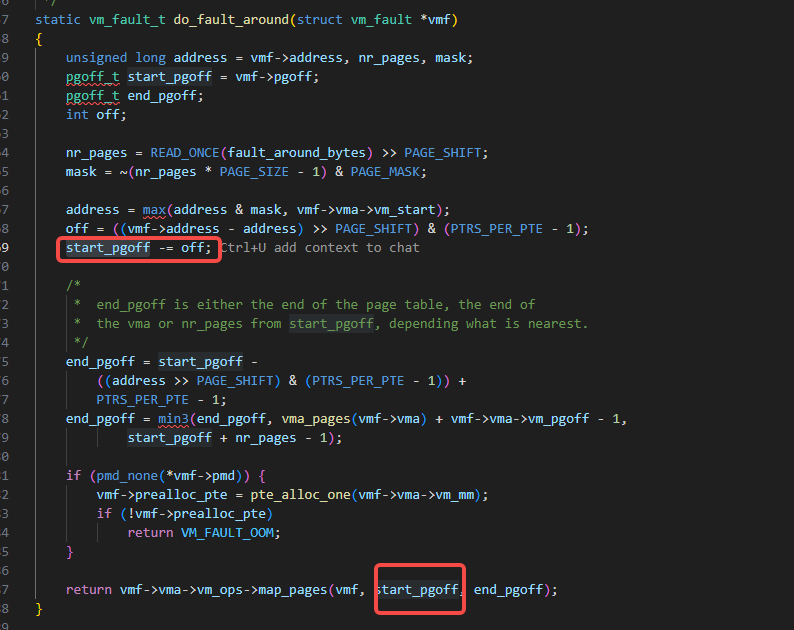
2.2.2 do_fault_around函数除了会预取之后的内容,也是会预取之前的内容
如何来理解这句标题呢,意思就是它预取的是一个范围。你读文件可能并不是按顺序的,但是它预取时是一起进行预取的。
从下图里的start_pgoff的计算就可以看到这一点:
2.2.3 从缺页异常到do_fault_around再到map_pages再到增加内存统计值的调用链
我们以高版本内核来介绍,缺页异常相关的调用链,抓到的堆栈如下(调用到最终增加内存统计值的inc_mm_counter):
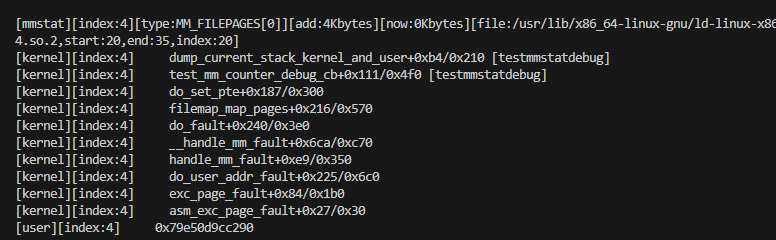
do_set_pte里会调用inc_mm_counter,在inc_mm_counter里,我们用 简易的替代tracepoint的调试手段的进一步改进-CSDN博客 里的方法打了一个桩,打出了上图的堆栈。
do_set_pte调用inc_mm_counter的图示:
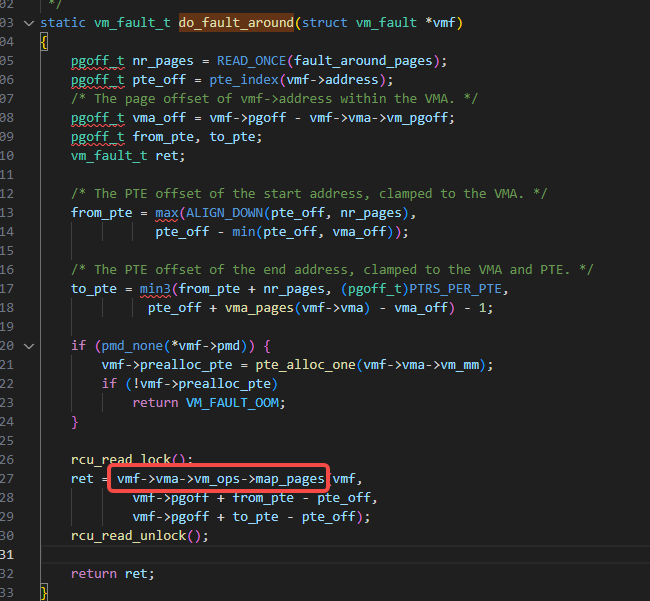
do_fault到filemap_map_pages的调用链经过摸索,如下:
do_fault->do_read_fault->do_fault_around->filemap_map_pages
下图里的vmf->vma->vm_ops->map_pages其实就是filemap_map_pages函数:
2.3 默认的预取大小及设置
默认的预取大小,无论是低版本内核还是高版本内核都是64k大小。
低版本内核里相关的参数是fault_around_bytes,高版本内核里相关参数是fault_around_pages。
这个值是可以设置的,如下图,默认是64k,我们可以把它改成32k:

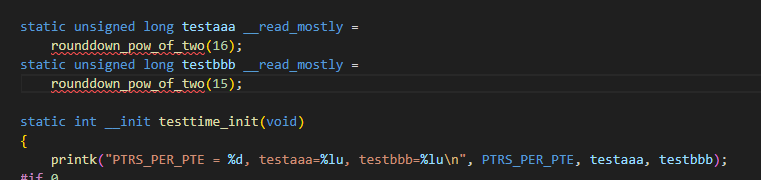
三、rounddown_pow_of_two的编程技巧
在设置预取大小的默认数值时,内核里使用了rounddown_pow_of_two函数来进行的静态初始化赋值的操作,这是一个很实用的技巧,可用来做一些内核代码里的一些变量的静态初始化操作。
如下图,如果要用一个自己定义的函数来返回一个数值是不允许的:


但是使用rounddown_pow_of_two就可以完成静态的初始化:
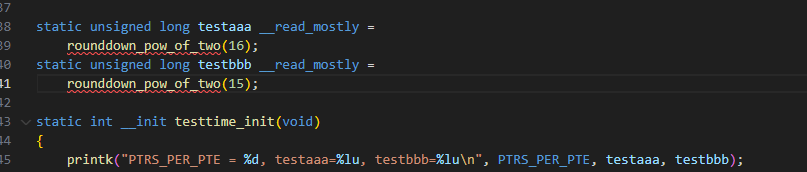
是可以编过的:

另外,rounddown_pow_of_two宏的含义还是比较好理解的,是用于取小于或等于传入数值的最大的2的幂次的数,如下图: