前言
又是一年"金九银十"秋招季,大模型相关的技术岗位竞争也到了白热化阶段。为满足大家碎片化时间复习补充面试知识点的需求(泪目,思绪回到前两年自己面试的时候),笔者特开设 《大模型工程面试经典》 专栏,持续更新工作学习中遇到大模型技术与工程方面的面试题及其讲解。每个讲解都由一个必考题和相关热点问题组成,小伙伴们感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。
一、面试题:如何进行大模型多模态微调
1.1 问题浅析
在大模型多模态功能日益重要的今天,如何围绕大模型的多模态能力进行微调也成了非常热门的方向。要回答这个问题首先要了解多模态大模型的核心架构。
一般来说多模态大模型由训练好的语言模型和视觉编码器组合而来,其中视觉编码器负责将视觉信息转化为高维向量,然后借助投影层将高维度向量转化为语言模型能够理解的token,最终让语言模型能够像理解文字一样理解图像。其中投影层是整个多模态大模型的关键组件,虽然参数量很少但对模型性能影响重大,同时投影层也是绝大多数大模型多模态微调的切入点。
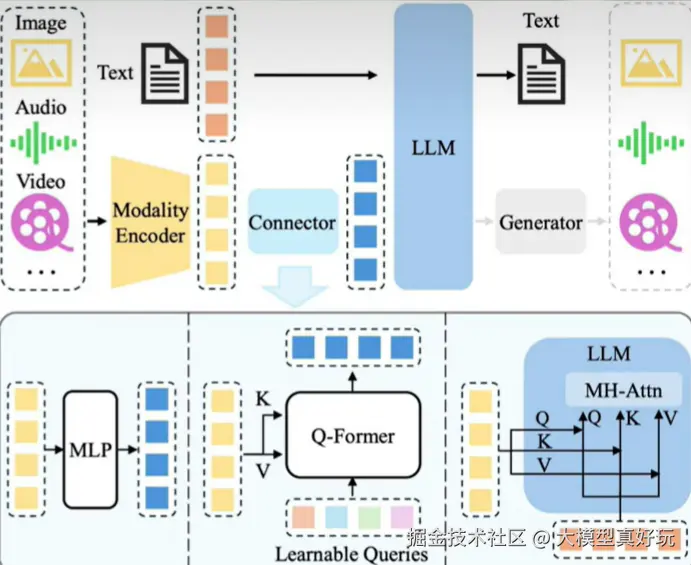
1.2 标准答案
多模态大模型微调最重要的方法,就是重训练投影层 。投影层就像是视觉世界和语言世界之间的"翻译官它决定了图像特征能不能顺利被语言模型理解。在预训练阶段,投影层通常是为了通用场景设计的,但在实际任务中,比如医疗影像诊断、图表解析或工业检测,这个翻译官往往"不太懂行"导致信息对齐不到位。因此多模态微调的最常见做法,就是冻结视觉编码器和语言模型,仅针对投影层做全量微调,让它学会在特定领域里更精准地翻译图像特征
但也要注意在某些场景下只训练投影层无法达到预期效果,通常做法是进一步对多模态大模型的语言模型进行微调。因此我们还可以继续补充回答:
除了重训练投影层,有的时候为了获得更好的效果,我们还可以借助LORA或者QLORA来微调多模态模型的语言模型部分参数,这样做的原因在于:投影层只负责"把图像翻译成文字',但它并不会改变语言模型的表达方式。如果下游任务要求模型生成专业化的语言,比如医学报告、金融分析或者学术风格的图文解读,仅靠重训练的投影层是不够的,还需要让语言模型自己重新学习如何说话。这时候我们就会在语言模型的关键层插入 LORA 模块,只更新极少量参数,让模型既能保持原有的通用能力,又能更好地适配特定领域的语言。
二、相关热点问题
2.1 在实际工程中,多模态微调的数据该如何准备?
答案: 多模态微调数据准备的核心是图文对齐。典型的数据形式是"图片+文字描述"的格式,比如图片里是一张图表,文本就应该是这张图片对应的文字描述。并且对于多模态微调来说,数据质量比数量更重要,高质量的小规模数据往往比低质量的大规模数据更有效。
2.2 多模态微调的典型应用场景有哪些?
答案: 常见场景包括:视觉问答(VOA)、图像文字理解、图表到文档解析、跨模态检索以及医学影像诊断报告生成等等。
2.3 为什么多模态微调比单模态难?
答案: 因为涉及到模态对齐问题。图像和文本的分布差异很大,训练时既要保证跨模态特征一致性,又要避免语言模型被"图像噪声"干扰,因此需要精细设计多步微调。
三、总结
本期分享系统介绍了如何进行大模型多模态微调这一面试热点问题,不同于语言模型的微调,多模态微调涉及到不同模态的格式对齐和多结构的训练统一,需要具备一定的回答技巧。同时扩展了3个热点问题,涵盖了多模态微调从数据到应用的全过程。总的来说,大模型多模态微调的问题按文中模板回答一定是加分项!小伙伴们阅读后感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。