观前排雷:
本文所涉及领域,与IT技术工作者感兴趣领域大概率不重合,而且因为基本上是语言学上的科普与探索,不讲技术难点,没有典型案例,总之,内容散漫、行啰嗦漫,慎阅,慎阅。
如果这篇文章有幸被你点进,而且你也恰好有一些闲情逸致,那么欢迎阅读下文,和扒谱机我一起探索!
前情提要------
笔者从小被家长要求讲普通话,再加上后来多年外地求学,导致连家乡话都不会说。今年八月份,在某个拥挤的地铁上,我打开了知乎,开始学起了家乡话。
1 语言学科普
1.1 声调
在最前面科普一下,与汉语是声调语言 ,在英法德日韩等非声调语言中,语调通常不直接辨义 ,更多是表达情绪、语气(如疑问用升调,陈述用降调)。而声调在汉语中不仅是语音的高低起伏形式,更是区别不同词语含义的关键要素------ 即便声母、韵母完全相同,只要声调不同,就可能代表两个或多个意义完全不同的词。这是汉语(尤其是普通话及多数方言)区别于英语、日语等非声调语言的重要特征。
单个字的声调可以有很多------除了大家比较熟知的粤语有9声6调,周边的桂南平话、玉林白话等调值较多之外,闽、湘、赣、吴也有部分4调以上的方言。在普通话里,声调一共有4种(算上轻声是5种)。小学二年级(这回是真学过)都知道的,拼音的声调有一声、二声、三声和四声(称谓叫做"阴平"、"阳平"、"上声"和"去声"),最后一种是轻声,关于它的读音,很多人都有错误读成非轻声的习惯,比如玫瑰、葡萄、名字这些词的末尾字。除了"子"字在末尾,还有好多应该读成轻声的字,考过普通话的都知道,毕竟一用普通话读,就非常想把这个字的本音读出来,然后就完美地读错------
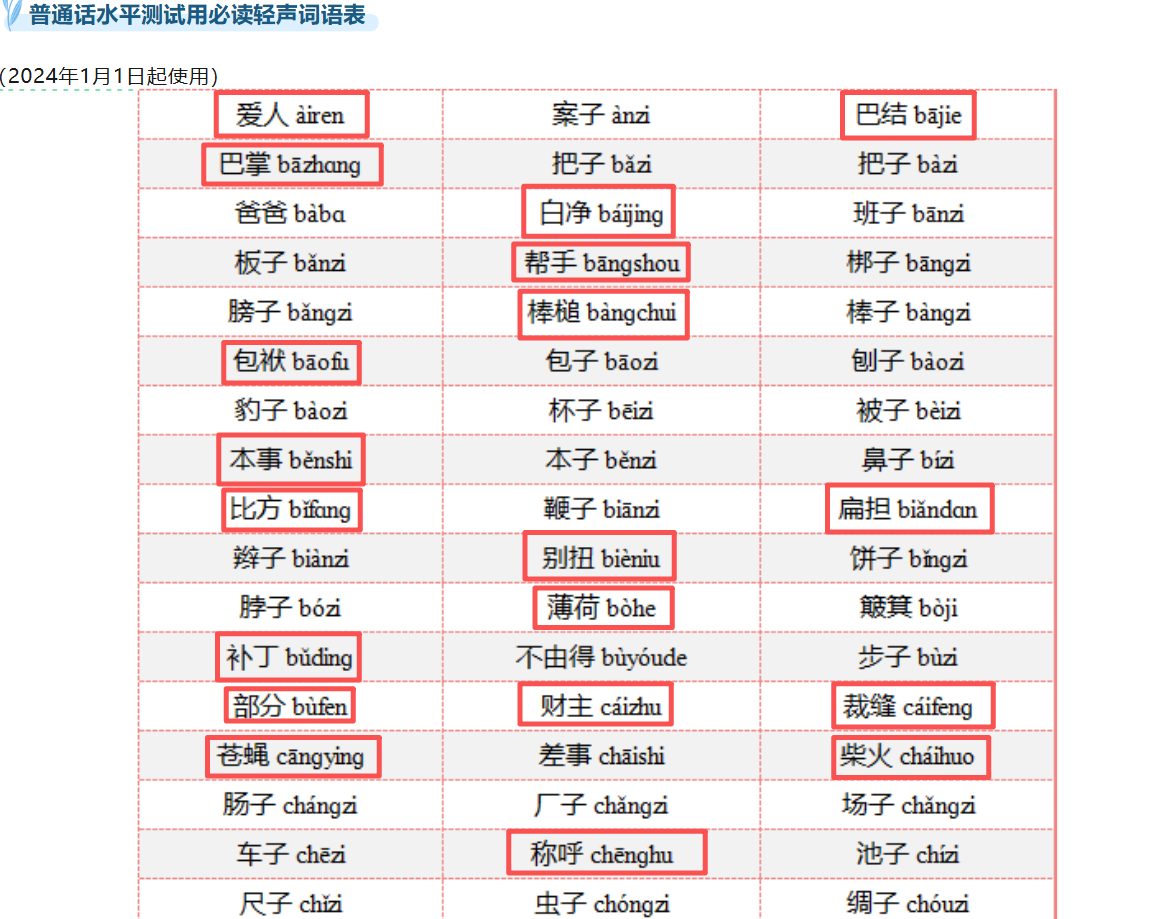 标红的是非"子"字结尾的尾字轻声读音词,图源 普通话水平测试用必读轻声词语表
标红的是非"子"字结尾的尾字轻声读音词,图源 普通话水平测试用必读轻声词语表
1.2 调值
在这里我们看到了一个新概念------调值。它是将声调量化的表示方法,可以高效明确地表示调值。AI这么告诉我:
"5 度调值法" 是语言学中记录汉语声调的核心方法,由语言学家赵元任提出,它通过将声音的高低程度量化为 5 个等级(从低到高标记为 1、2、3、4、5),精准描述不同声调的 "高低起伏轨迹",让抽象的声调变得可观察、可记录。
1.3 变调
从普通话上,最容易体会到的变调现象来自上面说的轻声。
轻声的具体读音,其实是随着前面一个字改变的,网上的资料写道:
阴平、阳平、去声之后的轻声音节音高表现为下降,调值分别为2、3、1(举例:车子 房子 稻子); 上声之后的轻声音节音高表现为较高的平调或微升调,调值为4(举例:谷子)
当然,这种变调是不辨义的,只是人们习惯这样去读。基本上和英语的"连读"、"弱读"类似,怎样读都表达相同的意思,只不过变调读起来更加地道。当然要排除一些特殊情况,比如"老子zi"【我】和"老子zǐ"【李耳】(bushi)
曾经看过很多视频制作者们讲自己的家乡话(主要还是东北和华北的,南方差异还是有些大,大多是听不大懂的),甚至还有各种教学视频。比如说让我印象最深的是天津话,那位up主讲,每个词儿的变调方式,它还都不一样,嘛都学不明白。
照例询问了我的好朋友AI君,它的回答前面还是很中肯的,这里贴一下。
普通话与南北方方言的连读变调差异显著,核心差异体现在变调规则的 "系统性""复杂性" 和 "覆盖范围" 上:普通话的连读变调规则高度统一、简化(以 "上声变调""'一、不'变调" 为核心),而方言(尤其是南方方言)的变调规则更复杂,常与声调数量、音节组合长度(双字、三字、多字)、词性甚至语境强相关,部分北方方言则在普通话基础上保留了更多地域化变调特征。
从 "特征明显度" 来看,南方方言(如吴语、粤语、闽语)的连读变调普遍更突出------ 不仅变调规则复杂,且常伴随 "声调合并""调值大幅改变""多字组整体变调" 等现象,部分方言(如上海话)甚至无 "本调" 与 "变调" 的明确界限,连读时几乎所有音节都需变调。北方方言中,天津话、唐山话的连读变调也极具地域特色,规则虽不如南方方言复杂,但变调后的调值辨识度极高。
普通话的连读变调(规则最系统、简化)
普通话只有 4 个基本声调(阴平 55、阳平 35、上声 214、去声 51),连读变调仅集中在上声(ˇ) 和特殊字 "一、不" 上,其他声调(阴平、阳平、去声)组合时基本不变调。
++【1. 上声(214)的连读变调】++
上声是普通话唯一需要系统性变调的声调,核心规则可总结为 "遇上变阳平,遇非上变半上":
- 双字组:上声 + 上声→阳平 + 上声 (前一个上声变阳平 35)
例:
- 雨伞(yǔ sǎn)→ 实际读 "yú sǎn"(前 "雨" 从 214 变 35,后 "伞" 保持 214);
- 友好(yǒu hǎo)→ 实际读 "yóu hǎo"(前 "友" 从 214 变 35)。
- 双字组:上声 + 非上声(阴平 / 阳平 / 去声)→半上(21)+ 原调 (前一个上声变 "半上",调值缩短为 21,失去末尾的 "4")
例:
- 北京(běi jīng,上声 + 阴平)→ 实际读 "běi(21) jīng(55)";
- 河流(hé liú,阳平 + 上声)→ 后 "流" 是上声,前 "河" 是阳平(非上声),故 "流" 不变调,仍读 214;
- 土地(tǔ dì,上声 + 去声)→ 前 "土" 从 214 变 21,读 "tǔ(21) dì(51)"。
- 三字组:上声 + 上声 + 上声→阳平 + 阳平 + 上声
例:展览馆(zhǎn lǎn guǎn)→ 实际读 "zhán lán guǎn"(前两个上声均变阳平)。
++【2. "一、不" 的变调(特殊字变调,非系统性)】++"一" 本调是阴平(yī,55),"不" 本调是去声(bù,51),连读时根据后接声调变调:
- "一" 的变调 :后接去声→变阳平(35);后接阴平 / 阳平 / 上声→变去声(51)
例:
- 一个(yī gè,后接去声 "个")→ 读 "yí gè"(35+51);
- 一天(yī tiān,后接阴平 "天")→ 读 "yì tiān"(51+55);
- 一年(yī nián,后接阳平 "年")→ 读 "yì nián"(51+35)。
- "不" 的变调 :后接去声→变阳平(35);后接其他声调→不变调(仍读 51)
例:
- 不要(bù yào,后接去声 "要")→ 读 "bú yào"(35+51);
- 不好(bù hǎo,后接上声 "好")→ 仍读 "bù hǎo"(51+214)。
到后面讲唐山话的时候就......扫地变sào地,飞机→fěi机 我直接一脸懵逼。
还是看看知乎上讲的吧,这个读起来比较靠谱。
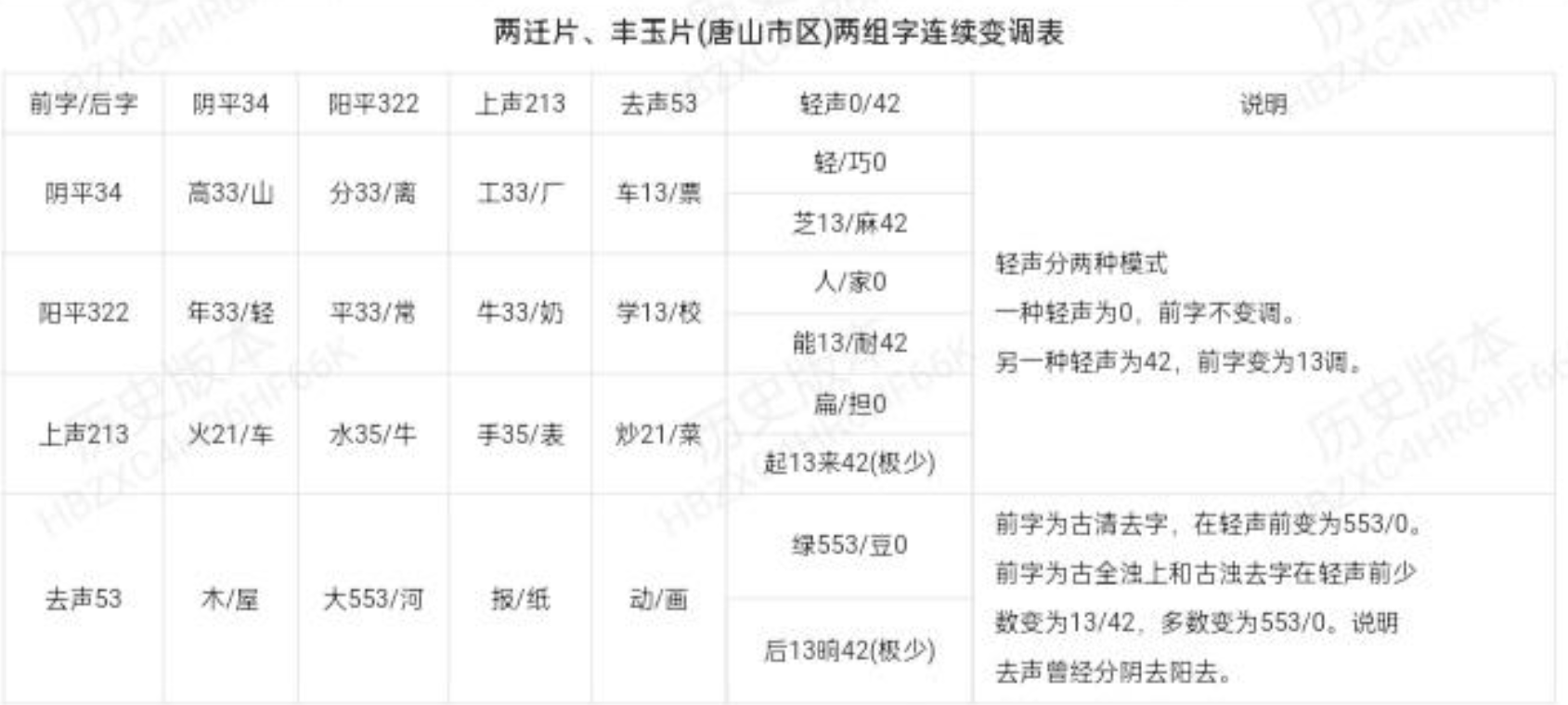
本两片的阴平、阳平后字是阴平阳平上声时,变33调,后字是去声时,变13调,在轻声前一部分不变调,轻声为0调,另一部分变13调,轻声是42调。
上声在阴平和去声前变21调,在阳平和上声前变35调,在轻声前多数不变调,轻声为0调,少数变13调,轻声是42调。
去声在阳平前变553调,在阴平、上声、去声前不变调,在轻声前变553调,轻声为0调,另有极少数全浊上声字和浊去字变13调,轻声是42调。说明:丰玉片的遵化和玉田由于距离北京较近,受北京官话影响较大,这两地的去声单字调值为51,后字轻声为0调时,前字不变调,为51调。
本片方言与芦汉片的最大区别是没有阳去调,但去声在轻声中会有极少数的全浊上声字和浊去字变13调,这与芦汉片的阳去来源相同,而这又与本片的其它去声轻声前变553有区别(主要是清去字),证明以前也是保留阴去和阳去的,在结合芦汉片的阴平和阳平在阴去前变13调与本片的阴平阳平在去声前变13调的规律可以推断是阳去合并到阴去中了。
还有不得不说这个方言地图画得太好了。
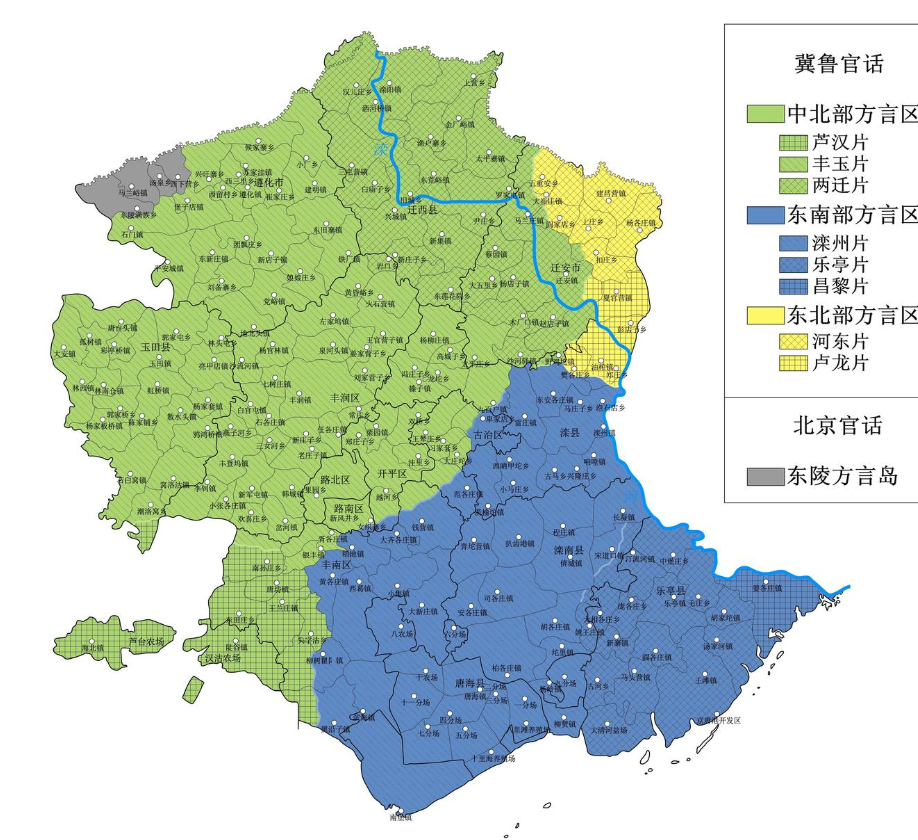 这是一个以大地震和打人事件著称的华北小城的方言分区图,图片来自 知乎
这是一个以大地震和打人事件著称的华北小城的方言分区图,图片来自 知乎
2 梦开始的地方
决定做这个微实验,是因为我看到了这张------知乎博主自测的方言调值图。
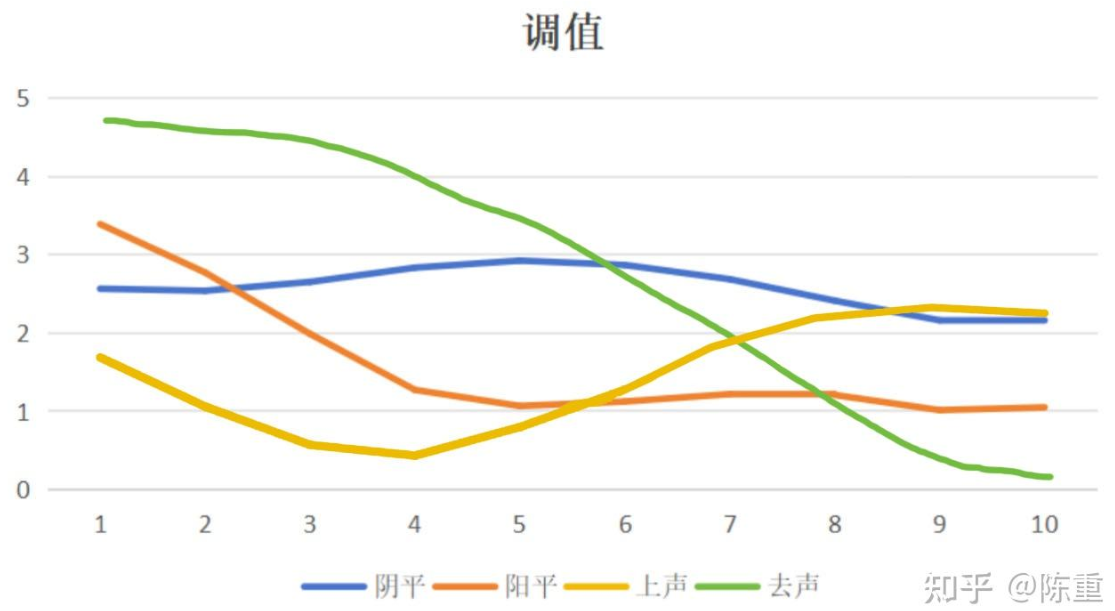 图片来自知乎
图片来自知乎  上图的朗读素材
上图的朗读素材
这种调值图,其他的论文里都有提过,比如------
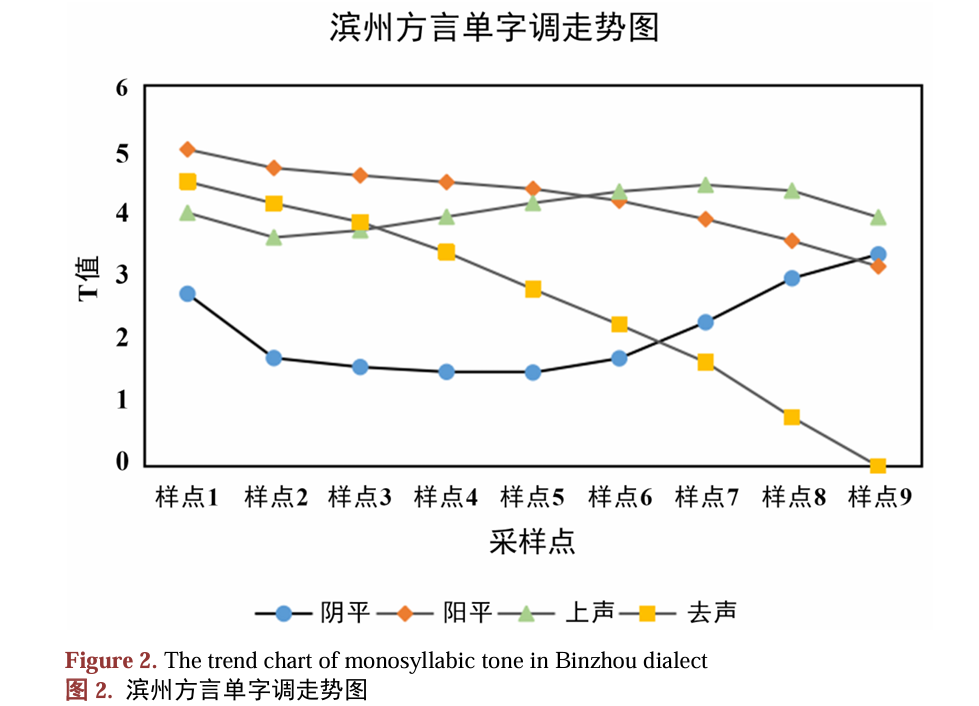 图片来自: 滨州方言单字调实验语音学研究
图片来自: 滨州方言单字调实验语音学研究
顾名思义,这种""单字调值图"一般是取单字录音的,但是鉴于很多情况下人们在方言中,基本不会单独去使用一个字,这种测试虽然能够极大简化方言调研成本,但在某种程度也存在一定误差。
语言的根本功能是 "交际",而交际依赖连贯的语流),而非孤立的单字。从语言学视角看,单字只是语言系统中 "最小音义结合体" 的抽象单位,一旦进入实际使用,必然受到前后语音、语法、语义的联动影响,因此连读变调是进一步分析的关键所在。
因此在连续语流中,考虑连读变调来进行方言的调值分析就显得尤为重要。
写到这里,怎么感觉正在出一道数学建模的题目......救命。
真是堪比一篇数学建模了。
3 实验数据采集
3.1 实验者
鉴于我本身也不怎么会说家乡话(大悲),这里考虑使用两个较为靠谱的素材进行分析,确保有较为充足的数据。
素材一:在去老家时,我使用手机录制了大约一小时的祖父母讲话音频。二老讲了一辈子丰玉片方言,绝对地道纯正。
素材二:98年唐钢春晚单口相声演员田树根先生《说方言》模仿的片段。田树根先生妙学唐山四大方言_哔哩哔哩_bilibili
(对标滨州方言采样的那篇论文里的:本次实验所选用的发音人为笔者本人,系自省式调查实验。笔者为滨州 本地人,在滨州生活二十多年,上大学前从未离开过滨州,脱离滨州生活环境的时间相对较短,讲地道 滨州话。另外,作者无语言表达或听力方面的障碍,能够准确流利地发音。本次录音,发音人只有一位, 为了尽量避免各种外界环境对发音人造成干扰,录音在连续时间段内完成。为保障录音样本的质量,在正式录音前对发音人 进行十分钟的录音培训和三十分钟的方音适应。正式录音时,发音人要用地道的滨州方言读例字,每个 例字读两遍,例字之间间隔两秒,实验最终选取效果较好的一例作为实验样本。如有错读或误读的音则需要进行重录,以此保证获取到高质量的录音数据。)
3.2 音质保证
环境略虽嘈杂,但经过降噪和人声提取后,调值能够得以保留。
(对标滨州方言采样的那篇论文里的:录音工具选用 Praat 4.2 汉化修改版录音软件,设备参数设定为采样频率 11025 赫兹、采样精度 16 位、单声道,录音文件保存格式为 "*.wav",以此保障录音样本质量符合实验要求。)
说实话,保存格式wav还是mp3其实对调值的损失其实可以忽略不计。
关于采样频率------
根据奈奎斯特采样定理 ,采样频率需至少是信号中 "最高频率成分" 的 2 倍,才能完整还原原始信号(避免频率混叠)。
人类语音的核心频率范围是:
- 男性声域:约 85-180Hz(基频),频谱最高能量集中在 5000Hz 以内;
- 女性 / 儿童声域:约 165-255Hz(基频),频谱最高能量集中在 6000Hz 以内。
早期语音研究(如 2000-2010 年)中,11025Hz 是非常常用的采样频率,尤其适合单字调、元音等基础声学分析;现在的录音技术基本使用上44100Hz,比如大部分手机的录音采样频率都是这样的。
当然,换一种说法来讲,本次实验核心是 "声调基频"(而非清辅音高频噪声),11025Hz 已能完全覆盖基频的频谱范围,无需追求更高采样率造成资源浪费。
关于采样精度,AI这么说:
"现在的采样精度" 没有绝对统一值,而是根据使用场景分为不同等级,核心分为 "专业领域" 和 "消费领域":
| 应用场景 | 主流采样精度 | 核心特点与用途 |
|---|---|---|
| 语音实验 / 普通录音 | 16 位 | 性价比最高,满足方言研究、日常语音记录、播客等需求,文件体积适中,兼容性强(所有软件都支持)。 |
| 专业音频制作(录音棚) | 24 位 | 动态范围达 144dB,能捕捉乐器 / 人声的细微音量变化(如歌手气息、乐器泛音),后期混音空间更大,是音乐制作、影视配音的标准。 |
| 高端专业领域(母带处理) | 32 位浮点 | 动态范围理论上无限(实际超 150dB),用于音频母带制作(最终音乐成品的优化),避免后期处理时信号失真,普通场景无需使用。 |
| 消费级设备(手机 / 耳机) | 16 位为主,部分支持 24 位 | 手机录音、在线音乐(如 Spotify、网易云)默认 16 位,因 24 位文件体积大(是 16 位的 1.5 倍),且普通用户的听觉系统难以分辨 16 位与 24 位的差异。 |
总之,这么看下来,一部智能手机的录音已经能够完美胜任了。
4 数据预处理
当我把上面说的【素材一】从手机转到了电脑上------
拿到了这1个多G的音频数据,感到了深深的无助与无从下手。
Praat也用不熟,于是打算让AI写一个程序自动帮忙划分音节,所以这个实验就搁置在这里了......
(未完待续)