前几天接到一个新任务,要求把以前部署在私有服务器上的项目,全都搬到云端去部署。之前的发布流程其实挺简单的,都是在本地打包好,然后通过文件传输把打好的jar包或者前端编译好的文件夹,直接替换到服务器上。挺传统也挺直接的。
但这次不一样了,老板希望上线流程能更自动化,得用Jenkins实现一键部署,减少人工操作,省时省力。说实话,对于我这开发来说,哪干过这活啊。都是已经做好的流水线直接用就行了,奈何人手不够用,直接让我上。
接下来,我们就一步步来摸索、学习一下,看看从私有服务器迁移到云端部署,到实现Jenkins一键发布,这其中会遇到哪些坑,哪些需要特别注意的地方。
另外要提醒的是,每家公司的基础架构环境和要求都不太一样,下面说的内容更多是给新手做个参考,帮助理解和入门,具体操作还是得结合自己公司的实际情况来调整。
名词解释
基础问题
首先我们先来搞清楚一些最基础的概念。
ACR,其实说白了就是一个私有的 Docker 镜像仓库。这个是某里云那边的叫法(Alibaba Cloud Registry),但其实每个云厂商都有类似的服务,比如腾讯云都有,只是名字不同而已。核心作用都是一样的,就是用来存储你打好的 Docker 镜像。
为什么要用私有仓库呢?因为你不可能把你们公司的服务包发布到 Docker Hub 这种公共仓库上去,那样既不安全,也不符合公司规范。所以我们会把自己的镜像推送到 ACR 这种私有仓库里,之后部署服务时就从这里拉取镜像。
再来说说 ACK,这也是阿里云的一个产品,全称是 Alibaba Cloud Kubernetes。它其实就是一个托管化的容器服务,换句话说,它帮你把 Kubernetes 集群搭建、管理那一整套繁琐的操作都封装好了。你只需要关注怎么把你的服务跑起来,而不用操心集群、节点、控制面这些底层的东西。
接下来我给大家讲一下 ACK 里面的一些基本概念和内容,帮你更好地理解它是怎么工作的。
首先,命名空间,你可以把它简单理解成"文件夹"这种东西。它的作用就是帮你更方便地管理你运行的 Docker 镜像和服务。就好比你电脑里的文件夹,把不同的东西分类放好,查找和维护起来也会更清晰明了。
然后是无状态节点和有状态节点,这两者的区别主要在于存储方面。无状态节点就是说它们不保存数据,节点被销毁了,数据也没了,重新启动就像全新的一样。反过来,有状态节点是支持数据持久化的,可以绑定存储,数据不会丢失。像我们平时做的微服务,大多数都是无状态的,因为它们可以随时销毁重建,不需要担心数据丢失。你也可以通过它们查看访问方式,比如服务的暴露和路由规则这些。
再说说容器组,你可以把它想象成一个服务的"集合"。一个服务通常会有多个副本节点,也就是多个相同的容器同时运行。容器组就是把这些副本集中管理的地方,你可以在这里看到每个副本节点的运行状态,还有它们的日志信息,方便你排查问题或者监控运行情况。
网络
服务(service)
他有好多种类型。他的目的是直接管理某个微服务的所有节点副本。
ClusterIP:只在当前集群的"虚拟网络"里生效,任何外部实体(不管是另一个集群、还是你办公室的笔记本)都访问不到。→ 相当于"房门只在屋里开"。
NodePort:把服务端口映射到"节点所在的那一层网络"。如果节点是私有网段(10.x/172.x/192.168.x),且没做额外打通 → 外部/另一个集群照样访问不到。如果节点是公网 IP,或两个集群的 VPC/局域网路由/对等连接已打通 → 外部/另一个集群就能通过 <节点IP>:NodePort 访问。→ 相当于"房门开到走廊,走廊能不能走到,取决于你俩在没在同一条走廊里"。
LoadBalancer:云厂商帮你额外申请一个公网负载均衡 IP(或内网 SLB + 公网绑定),无论节点本身有没有公网 IP,都会给你一个可直接在公网访问的地址。→ 相当于"直接在大楼门口给你挂一个独立门牌号,任何人都能按门铃"。
路由(Ingress)
同一个公网入口 IP + 端口,根据域名/路径把流量分到不同的后端 Service,这个没啥讲的,你就完全可以把他当成nginx来看就行。
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nacos3-ingress
namespace: common
labels:
app: nacos3
component: ingress
ingress-controller: nginx
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /nacos-demo(/|$)(.*)
pathType: ImplementationSpecific
backend:
service:
name: nacos3
port:
number: 8080当然并不是所有的路径分配都要写到一个Ingress里面,就像nginx我们也会把各个项目的配置文件分开一样,分开声明就可以。
配置管理
配置项
这个你是你Java项目的application配置文件。只不过可以单独配置,不过我们基本上都是使用Nacos进行管理,不用这个,用它的都是公共组件,比如xxljob这种的。
yaml
# 配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: xxl-job-config
namespace: common
labels:
app: xxl-job
version: "3.2.0"
data:
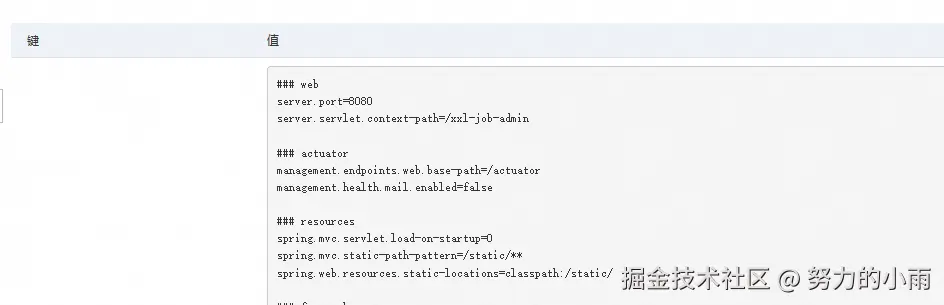
application.properties: |
### web
server.port=8080
server.servlet.context-path=/xxl-job-admin界面查看查看效果如图所示:
保密字典
我们一般会把数据库的密码啊,或者一些加密文件什么的,都放在这个地方。最常见的用途,比如你要从 ACR 拉取镜像,这时候就需要提前把账号和密码配置好。不太一样的是,这里的 Secret 类型不能用普通的 Opaque(如图)。
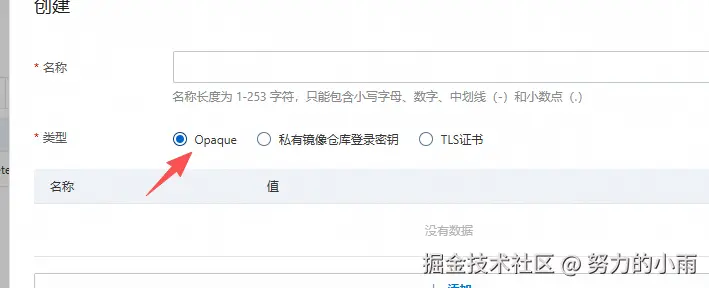
而是要用 kubernetes.io/dockerconfigjson 这个类型,专门用来存储镜像仓库的认证信息。
yaml
apiVersion: v1
data:
.dockerconfigjson: >-
eyJhdXRocyI6eyJiaG1jLWFjci1zY3JtLXJlZ2lzdHCSE1DLVNDUk0tVCIsInBhc3N3b3JkIjoiQmhtY3Njcm0jMDEiLCJhdXRoIjoiWVdOeVFFSklUVU10VTBOU1RTMVVPa0pvYldOelkzSnRJekF4In19fQ==
kind: Secret
metadata:
name: acr
namespace: wechat-apps
type: kubernetes.io/dockerconfigjsondockerconfigjson全是base64生成的,如果不知道初始数据是啥,可以自己在web界面弄完之后,复制出来看下。

存储
这块主要是说给每个服务分配存储空间的事情。之前用 Docker 的时候,操作特别简单,直接挂载一个目录就能用,没啥特别的,服务启动的时候指定个目录,数据就能存到那里。但到了云上环境或者 Kubernetes 里,就不太一样了,这里没法像 Docker 那样直接挂载目录。它们都要求我们先去申请存储资源,再把存储绑定到对应的服务上,不能直接用本地目录的方式。
你可以把它想象成写 Java 代码的过程:先写个类,然后 new 出一个对象,接着才给这个对象设置各种属性值。
存储类
这步就是先得有类。你具体要使用什么类型的磁盘,某里云上你都可以看到。你要是使用的话,必须声明才可以。
yaml
storageClassName: alicloud-disk-ssd这个是已经存在的资源,不用我们创建。当然我就不使用命令了,因为我也得先查,web界面操作如下:
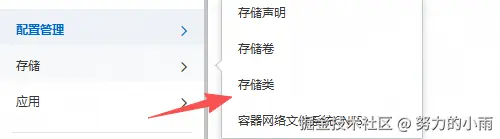
点击后,你就能看到各个类型了。
存储卷
这时候你要开始new对象了,先写明你要什么多大容量的磁盘。但具体给谁用,存储卷不知道。这只是一个属性值而已。
yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nacos3-data-dev
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: alicloud-disk-ssd
hostPath:
path: /mnt/nacos3-data/demo申请好后,会显示在界面上。

存储声明
这个就是设置属性值的时候了。直接给存储卷绑定上,这样整个流程就算完活了。
yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nacos3-pvc
namespace: common
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
volumeName: pv-nacos3-data-dev
storageClassName: alicloud-disk-ssd这个存储就可以给你的服务使用了。
yaml
volumes:
- name: nacos3-storage
persistentVolumeClaim:
claimName: nacos3-pvc
- name: nacos3-logs
persistentVolumeClaim:
claimName: nacos3-logs-pvc环境配置
首先,云上环境的开通会需要一点时间,这一块主要是由甲方来负责操作的。你不用太担心,后续他们会把所有相关的信息都整理好并提供给你。比如账号的登录信息、ACR(容器镜像服务)的账号和密码、ACK(容器服务)的秘钥信息等等。
另外,如果项目中用到了云上的数据库服务,也会一并提供数据库的连接信息。这些内容我们会统一整理到一个表格文档里,方便你后续查阅或复制粘贴使用,避免信息遗漏或重复沟通。
跳板机
接下来说说服务的部署流程,通常情况下,咱们的服务都会部署在内网环境里,也就是说不会直接给你一个公网地址让你访问。所以,你这边必须先申请开通一些防火墙规则,确保必要的网络能通畅。具体来说,主要涉及到以下几个关键点:
首先,要准备一台跳板机。跳板机的作用很简单,就是帮你直接操作云上的ACR(容器镜像仓库)和ACK(容器服务)。如果你对这些名词还不太熟悉,建议赶紧补一下相关知识,这样后续操作会顺利很多。除此之外,这台跳板机还得部署Jenkins,用来做自动化构建和部署的工作。
为了让跳板机能正常工作,必须提前把跳板机所在的网络和GitLab、ACR、ACK这些服务的网络打通。如果条件允许的话,还可以把Maven拉取的国内镜像仓库域名也一起放开,这样构建速度会快很多。如果没办法打通Maven镜像,那你就得手动把jar包上传到Maven私服,操作会麻烦一些。
至于为啥一定要申请跳板机,主要是因为云上的ACR和ACK管理界面操作起来比较繁琐,直接通过界面做一些批量操作或者复杂配置很不方便。有了跳板机,你可以直接通过命令行来执行各种操作,效率会高不少。当然,如果你比较喜欢折腾,也可以选择直接在云服务的Web界面用yaml文件格式来创建和管理资源,这两种方式都可以。
kubectl环境
跳板机需要的预置环境必须要有docker以及kubectl命令,如果没有必须临时开通外网权限自己安装,如果源代码编译你会遇到很多莫名其名的问题。远远超出开发的能力了。
紧接着你还需要配置下kubectl的环境,目的就是可以使用命令操作ack环境。如果你还没有就去下载一下。
然后跟着教程走就行。这部分没啥难度。
docker环境
docker需要提前登录到acr环境才可以正常打包项目并推送过去,不然ack是拉取不到镜像的。命令都会提示给你。acr的命名空间我用来隔离生产和测试环境了。需要提前创建好,不然直接推送到acr是会报错的。

所有的登录信息都会到镜像指南中提供给你,acr的登录账密开通人员也会提供给你。直接按照教程走即可。
Jenkins
接着就是部署jenkins了,因为我们网络基本的打通了。为了方便启动,我直接使用的docker容器启动了jenkins,compose文件如下:
yaml
# 定义Compose文件版本
version: '3'
# 定义服务
services:
# 定义名为jenkins的服务
jenkins:
# 指定服务使用的镜像
image: jenkins/jenkins:lts
# 自定义容器名称
container_name: jenkins-2.481
# 设置容器重启策略为始终重启
restart: always
# 给予容器特权权限,允许进行Docker-in-Docker操作
privileged: true
# 定义网络配置
networks:
- jenkins
# 设置容器环境变量
environment:
DOCKER_TLS_CERTDIR: /certs/client
# 定义数据卷映射
volumes:
- /data/jenkins/jenkins-data/certs:/certs/client:ro
# jenkins 数据目录
- /data/jenkins/jenkins-data:/var/jenkins_home
- /data/maven:/root/.m2
- /var/run/docker.sock:/var/run/docker.sock
- /usr/bin/docker:/usr/bin/docker
- ~/.docker:/root/.docker:ro
- /usr/local/bin/kubectl:/usr/local/bin/kubectl
- /data/npm-cache:/root/.npm
# 定义端口映射
ports:
- "8080:8080"
# 设置容器运行用户为root,以便有足够权限操作Docker
user: root
# 定义网络
networks:
jenkins:
# 指定网络驱动为桥接模式
driver: bridge这里我提前把mvn的仓库目录挂载出来了,还有前端编译的缓存包,以及kubectl命令,这样Jenkins就可以操作ack了。好的,接下来就是启动,启动后直接安装推荐的插件。能多安就别少安,毕竟我们只是开发。先确保可以正常跑流水线再说。这部分缺少的插件遇到报错我就安装了,忘记记录了,只要流水线在报错,你就去插件商店安装即可。或者自己手动上传。
账密配置
因为Jenkins需要操作git、acr、ack这些服务,所以账密及秘钥信息都需要提前在jenkins中配置好。如图所示:
进入后,然后点击页面的system,如图所示:
接着你就点击新增就好,如果是账密类型的,你就选择,Username with password,比如ack是配置信息,我直接创建的secret file。
这样基本就可以了。
项目相关
因为每个项目结构都不会有关于dockerfile或者deployment这种k8s文件在结构中,所以这种都是单独在一个项目中,然后复制出来给其他项目使用,gtilab创建好项目后,我这里直接创建一个自由风格项目。如图所示:
然后配置下git仓库地址即可,如图所示:
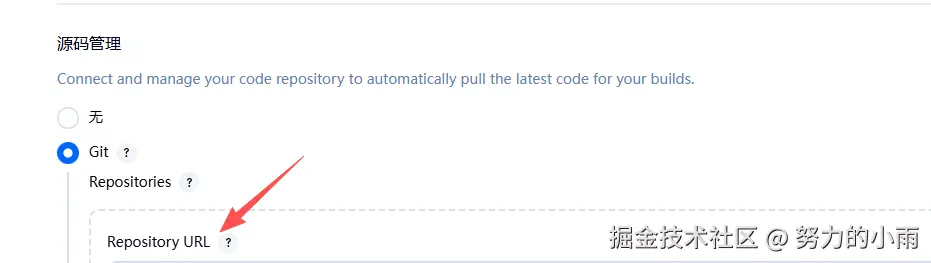
然后在配置下构建后的操作,如图所示:
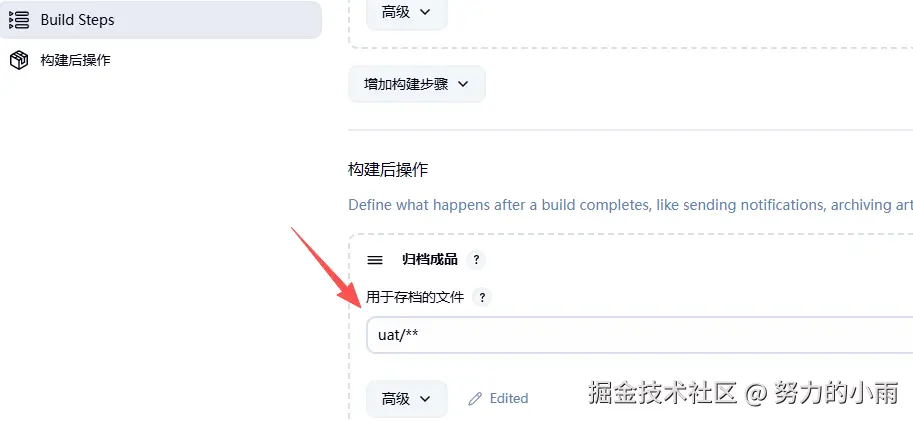
这里我将uat目录下的所有文件都归档到工作空间了。这样,你保存进行构建任务时,就会生成一个供其他所有任务使用的文件。如图所示:

剩下的项目就都是流水线项目了。我们直接创建一下。这里你可以使用git管理流水线也可以直接在脚本中写流水线都可以,为了快速验证我这里先用的脚本。
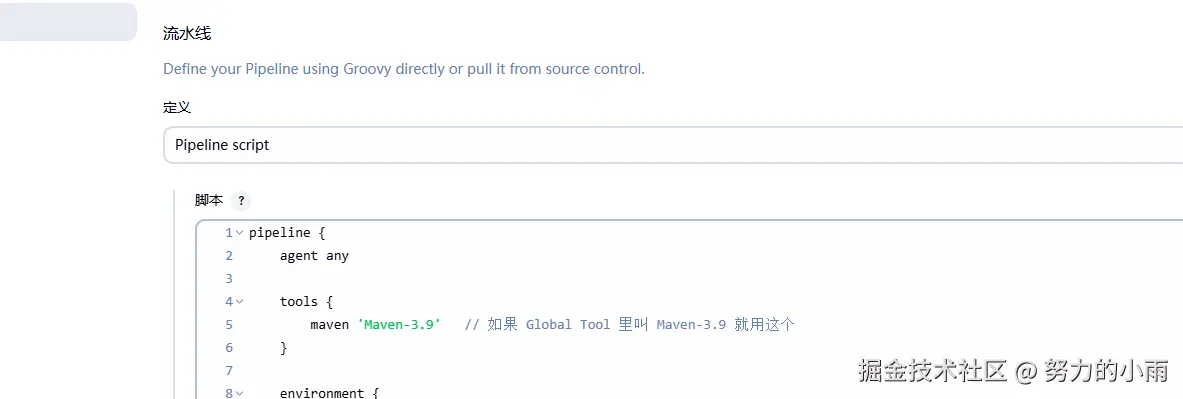
一个项目的脚本如下:
yaml
pipeline {
agent any
tools {
maven 'Maven-3.9' // 如果 Global Tool 里叫 Maven-3.9 就用这个
}
environment {
// 所有配置直接硬编码为测试环境
ACR_REGISTRY = '**cr.aliyuncs.com'
APP_NAME = '**'
ACR_NAMESPACE = '**' // 固定使用开发命名空间
// 凭证ID固定
GIT_CRED_ID = 'git'
ACR_CRED_ID = 'acr-credentials' // 需要您创建ACR登录凭证
KUBECONFIG_CRED_ID = 'ack-dev' // 固定使用测试环境的kubeconfig
// 代码库信息固定
GIT_URL = '**.git'
GIT_BRANCH = 'uat-cloud'
// Maven命令
MAVEN_PACKAGE_CMD = 'mvn clean package -Dmaven.test.skip=true'
// 最终镜像名称 (固定模式)
FULL_IMAGE_NAME = "${ACR_REGISTRY}/${ACR_NAMESPACE}/${APP_NAME}:latest"
}
stages {
stage('Checkout Code') {
steps {
echo "开始从 ${GIT_URL} 拉取分支 ${GIT_BRANCH}..."
git credentialsId: GIT_CRED_ID, url: GIT_URL, branch: GIT_BRANCH
}
}
stage('Maven Build') {
steps {
/* 2. 把私服 settings.xml 挂进来 */
withCredentials([file(credentialsId: 'maven-settings-nexus',
variable: 'MVN_SETTINGS')]) {
sh '''
mvn -s $MVN_SETTINGS clean package \
-Dmaven.test.skip=true
'''
}
}
}
stage('Copy Dockerfile') {
steps {
// 把共享 Job 产生的 Dockerfile 复制到当前工作区
copyArtifacts(
projectName: '**',
selector: lastSuccessful(),
target: 'docker-tmp'
)
sh 'cp docker-tmp/uat/docker/Dockerfile .'
}
}
stage('Build & Push Image') {
steps {
script {
// 构建并推送镜像
sh """
docker build -t ${FULL_IMAGE_NAME} \
--build-arg JAR_FILE=target/*.jar .
docker push ${FULL_IMAGE_NAME}
"""
}
}
}
stage('Deploy to ACK') {
steps {
script {
// 把共享 Job 产生的 Dockerfile 复制到当前工作区
copyArtifacts(
projectName: '**',
selector: lastSuccessful(),
target: 'docker-tmp'
)
sh 'cp docker-tmp/uat/k8s/**.yaml .'
// 使用测试环境的kubeconfig进行部署
withCredentials([file(
credentialsId: KUBECONFIG_CRED_ID,
variable: 'KUBECONFIG_FILE'
)]) {
// 更新镜像标签并部署
sh "kubectl --kubeconfig=${KUBECONFIG_FILE} apply -f **.yaml"
// 查看部署状态
sh "kubectl --kubeconfig=${KUBECONFIG_FILE} get pods -l app=${APP_NAME}"
}
}
}
}
}
post {
always {
cleanWs()
}
}
}小结
总的来说,这次从私有服务器迁移到云端部署,再到 Jenkins 一键发布,确实算是硬着头皮上阵,一路踩坑一路摸索。对我这种写 Java 的来说,平时很少接触这些云原生的东西,什么 ACK、ACR、跳板机、kubeconfig,一开始真的一脸懵。但一步步下来,其实逻辑都不复杂,关键是流程要理清、配置要记牢。希望这篇记录对和我一样"被抓壮丁"的开发同学有点帮助,别像我一样每次都从零开始瞎撞。环境不同、细节不同,但大方向差不多,照着搞肯定能跑起来。愿我们都能少踩点坑,早点下班!